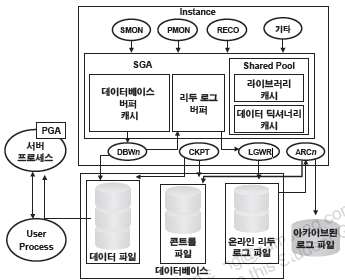
오라클 전체 구조
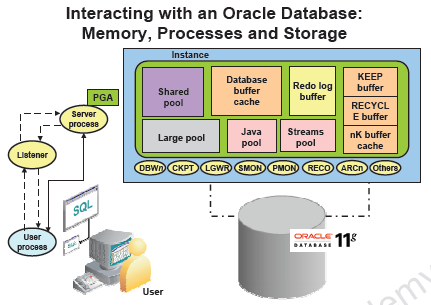
Oracle Server : 메모리와 디스크에 생성되는 구조
-
인스턴스 : 메모리 부분에 생성되는 구조
-
SGA : Shared pool, 버퍼 캐쉬, 리두로그 버퍼로 이루어짐. 실제 작업들이 수행되는 공간
-
백그라운드 프로세스
-
-
데이터베이스: 디스크 부분에 생성되는 구조
-
데이터 파일 : 데이터 저장
-
컨트롤 파일 : DB 전체의 관리정보 저장
-
리두로그 파일 : 장애복구시에 사용되는 파일
-
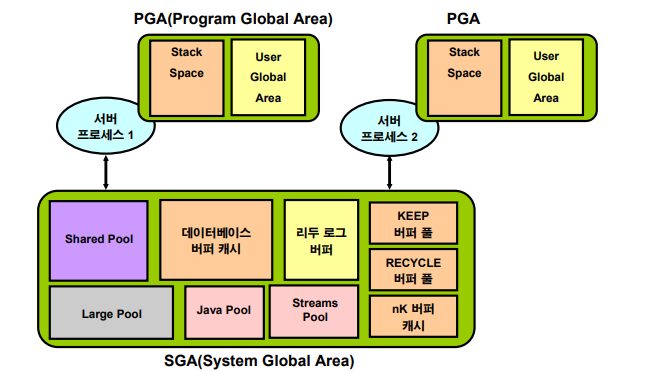
SGA(System Global Area): 오라클 프로세서들이 공유해서 사용하는 공유 메모리 영역
PGA(Program or Private Global Area): 서버 프로세서가 개별적으로 사용하는 메모리 영역✅ 클라이언트(유저프로세서)가 sql을 날렸을 때
SGA(공유 메모리 영역)에서 emp테이블 먼저 찾는다. PGA는 개별메모리 영역이다. 누군가 emp테이블을 select 했었다면 데이터베이스 버퍼 캐시에 올라와있을것이다.
정렬작업은PGA에서 한다. 그래서 가장 마지막에 한다!
Shared pool
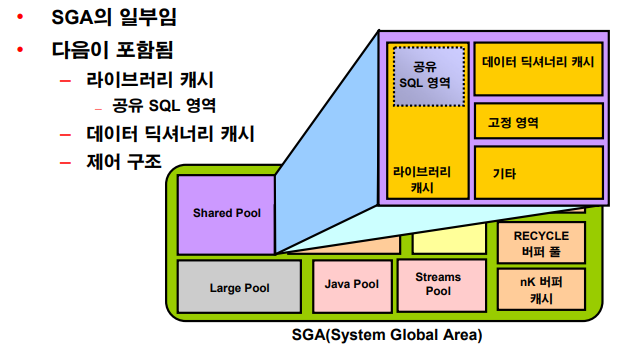
💡 parsing을 최소화 하기 위한 메모리 영역
파싱은 메모리 사용이 많고 cpu를 많이 사용하는 비싼 작업이다. 그래서 shared pool에 올리고 재사용한다. 재사용을 하면 다시 파싱하지 않는다.
같은 sql을 날려야 파싱을 하지 않고 재사용 되는데, 여기서 같은 sql이라는 것은
1. 대소문자 구분
2. 들여쓰기, 띄여쓰기 구분
3. 리터럴SQL도 다른 sql로 구분
soft parsing: 똑같은 sql이 메모리에 있어서 파싱 과정을 생략hard parsing: 똑같은 sql이 메모리에 없어서 파싱하는 것
데이터 베이스 버퍼 캐시
💡 data file에서 읽어들인 데이터 블럭이 올라오는 메모리 영역
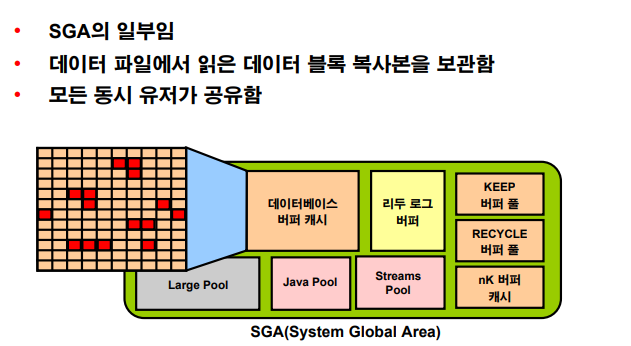
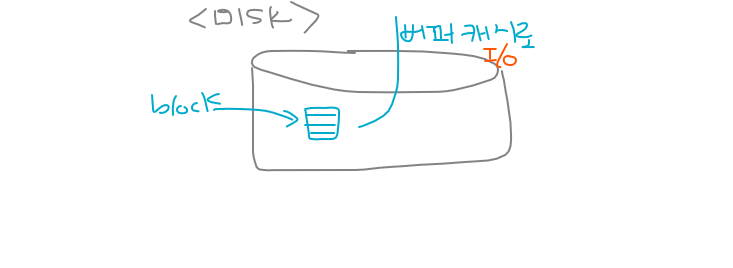
1. 검색하려는 데이터를 처음에는 db buffer cache에서 찾습니다.
2. buffer cache에 없으면 data file에서 찾습니다.
3. 찾은 데이터의 행과 주변행들을 같이 모아서 block으로 메모리에 올린다. (disk i/o)
4. 메모리의 buffer cache에 복사본을 올려놓고 user process에게 fetch.⭐ 주변 행들은 또다시 유저에 의해 select될 확률이 높은 행들이기 때문에 주변 행들까지 다 같이 포함해서 블럭 단위로 올라간다.
✔️ select문의 단계 3가지
1. parsing (shared pool)
2. execute (db buffer cache)
3. fetch
- db buffer cache도 한정된 메모리 영역이기 때문에 효율적으로 사용해야하는데, 이 메모리 영역을 효율적으로 사용하기 위한 알고리즘이 있다.
LRU(Least Recent Used) 알고리즘
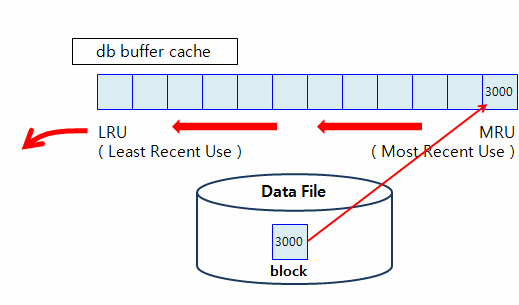
✅ 자주 액세스 하는 중요한 테이블은 index scan을 하던, full table scan을 하던 MRU 쪽으로 올리게끔 테이블 설계를 해야한다. (물리적 설계)
- cache table 만들기
- cache힌트 사용
리두 로그 버퍼
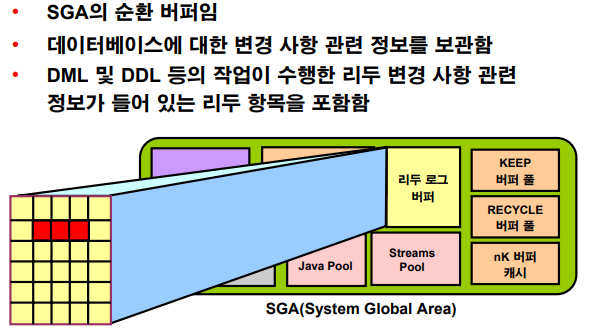
💡 리두 로그 버퍼는 데이터베이스에 대한 변경 사항 관련 정보가 포함된 SGA의 순환 버퍼. 리두 항목은 DML, DDL 또는 내부 작업에 의해 데이터베이스에
수행된 변경 사항을 재생성(또는 리두)하는 데 필요한 정보를 포함합니다.
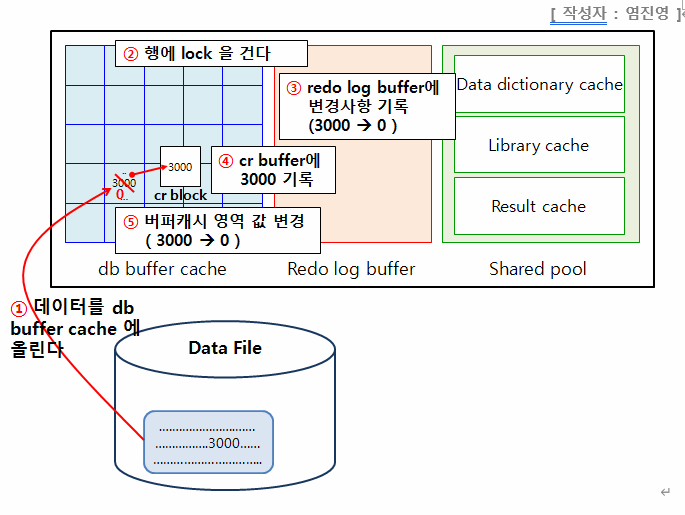
⭐ update문의 처리과정
1. parsing : 문법검사, 의미검사를 합니다. select 문장과 같습니다.
2. execute (순서대로)
- 데이터를 db 버퍼 캐시에 올립니다
- 업데이트 하려는 해당 행에 lock을 겁니다
- redo log buffer 에 변경사항을 기롭합니다
- cr buffer에 3000을 기록합니다
- 버퍼 캐시 영역 값을 변경(3000->0)
Large Pool
💡 1. 병렬처리 SQL을 수행할 때 작업하는 메모리 영역입니다.
💡 2. 백업과 복구를 RMAN 이라는 오라클 툴을 이용해서 명령어로 편하게 할 수 있습니다. 이 RMAN이 수행될 때 사용되는 메모리 영역이 large pool.
(백업과 복구를 빠르게 수행하고 싶다면 성능을 위해서 large pool을 늘리고 작업하면 됩니다.)
Java pool
💡 오라클은 sql뿐만 아니라 JAVA코드도 컴파일해서 실행할 수 있다. JAVA 코드를 컴파일하고 관련된 데이터를 올리는 메모리 영역이 자바풀 입니다. 사이즈가 자동조절되는 메모리 영역이므로 아주 큰 자바 코드가 컴파일 될 때 사이즈가 자동으로 할당되고 늘어납니다.
