
Object Detection
Object Detection은 영상에서 객체를 찾아내고, 해당 객체의 위치와 크기를 식별하는 하나의 컴퓨터 비전 분야이다.
즉, 영상에서 여러 개의 객체를 감지하고, 분류하는 Task를 수행하는 것이다.
Object Detection vs Image Classification
Object Detection은 Image Classification과 달리 객체가 존재하는 위치를 찾아내는 Task가 추가되어 있다.
일반적으로 해당 객체에 Bounding Box를 표시하여 객체의 위치를 나타낸다. (아래 사진에서의 초록색 박스)
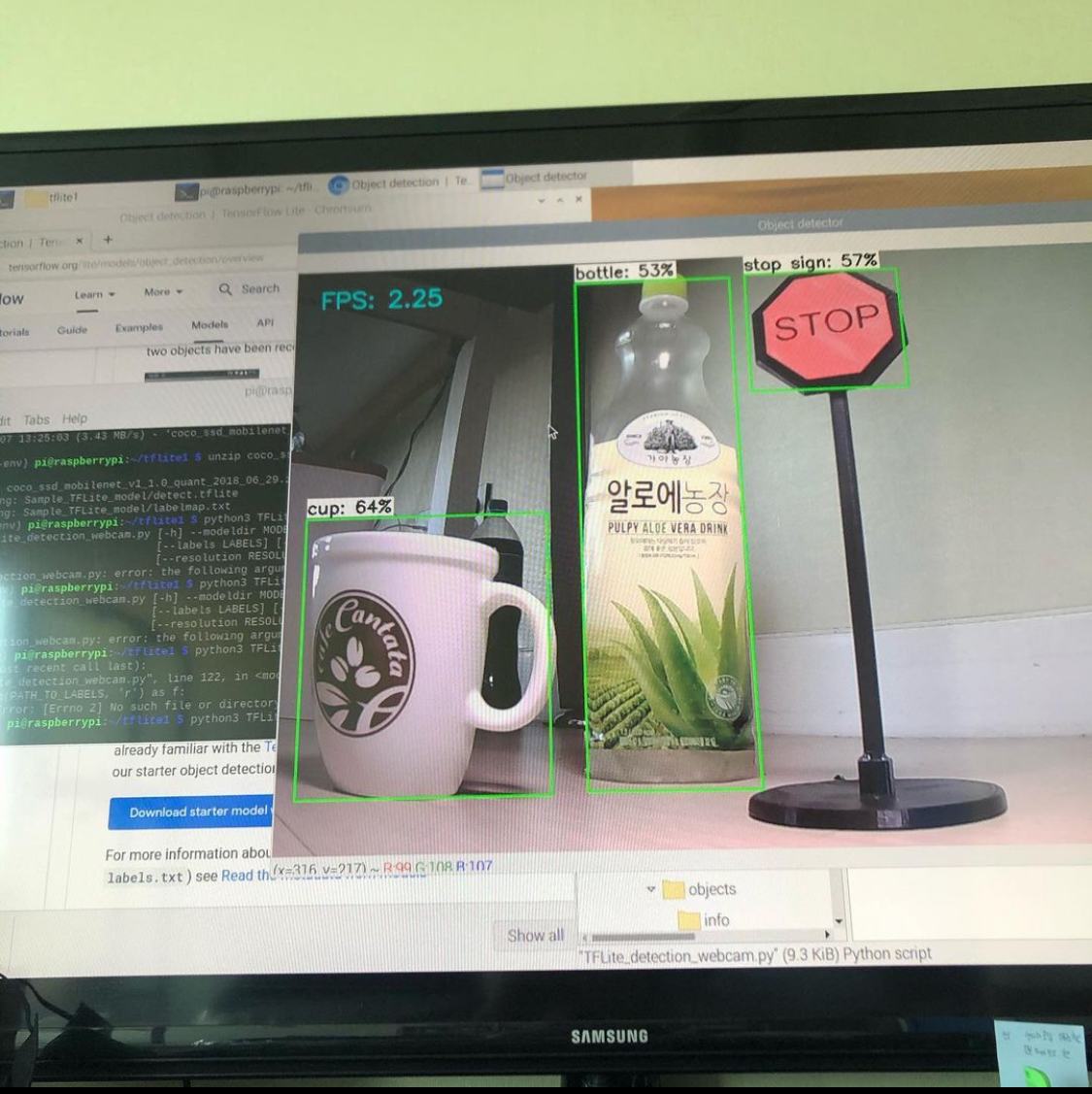 2021.01.07. TFLite Object Detection Starter Model
2021.01.07. TFLite Object Detection Starter Model
Classification & Localization
Object Detection은 크게 Classification과 Localization 두 가지 작업으로 나눌 수 있다.
Classifacation(객체 분류)은 영상에서 객체가 무엇인지 판단하는 Task이다.
이미지 내에 개, 고양이, 자동차 등의 객체가 존재한다면, 해당 객체가 어떤 카테고리에 속하는지 판단하는 Task인 것이다.
Localization(객체 위치 식별)은 영상에서 객체의 위치를 찾아내는 Task이다.
이미지 내에서 각 객체가 어디에 있는지 위치를 찾아 Bounding Box를 생성하는 Task인 것이다. Bounding Box는 객체의 위치와 크기를 식별할 수 있도록 하며, 일반적으로 사각형 형태를 사용한다.
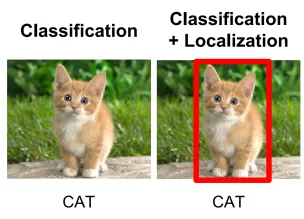
Object Detection은 위의 Classification과 Localization 두 가지 Task를 결합하여 영상에서 객체의 위치와 클래스를 동시에 식별할 수 있는 것이다. 영상 내에서 여러 객체를 동시에 감지하고, 각 객체 클래스와 Bounding Box 를 출력하는 것이다.
딥러닝 기반 객체 검출 모델에서는 일반적으로 Classification과 Localization을 동시에 학습시킨다. Faster R-CNN과 같은 모델은 Classification과 Localization을 위해 Region Proposal Network, RPN을 사용한다. RPN은 영상 내에서 객체의 Bounding Box 후보군을 생성하고, 후보군이 어떤 객체인지 분류하고, 정확한 Bounding Box를 예측한다.
이러한 딥러닝 모델의 학습을 위해서는, 대량의 Labeling된 데이터가 필요하다. Object Detection은 일반적으로 Supervised Learning, 지도 학습을 사용하기 때문이다. Object Detection 모델의 Labeling된 데이터에는 영상 내 존재하는 객체의 클래스와 Bounding Box 정보가 함께 포함되어 있어야 한다. 이 정보를 통해 모델은 Classification과 Localization을 함께 학습할 수 있다.
Intersection over Union, IoU
IoU는 Object Detection에서 사용되는 성능 평가 지표 중 하나로, 객체의 Bounding Box가 얼마나 정확한 지를 측정하는 데 사용된다. IoU는 모델이 예측한 Bounding Box와 실제 Bounding Box의 겹치는 영역의 크기를 결합 영역의 크기로 나눈 값으로,
와 같은 수식으로 표현할 수 있다. IoU 값은 0과 1 사이의 값으로, 1에 가까울 수록 Bounding Box가 정확하다는 것을 의미한다.

Object Detection 모델에서는 IoU를 사용하여 모델이 예측한 Bounding Box와 실제 Bounding Box의 경계 상자가 얼마나 일치하는지 측정한다. 일반적으로, IoU 값이 Threshold 보다 크면 올바르게 예측한 것으로 간주한다.
IoU는 Object Detection에서 가장 널리 사용되는 평가 지표 중 하나이며, IoU를 최적화하기 위해 (모델 성능을 높이기 위해) 모델 학습에 사용되는 손실 함수 중 하나인 Smooth L1 Loss와 함께 사용된다.
1-Stage Object Detector & 2-Stage Object Detector
1-Stage Object Detector와 2-Stage Object Detector는 Object Detection 모델에서 주로 사용되는 접근 방식이다.
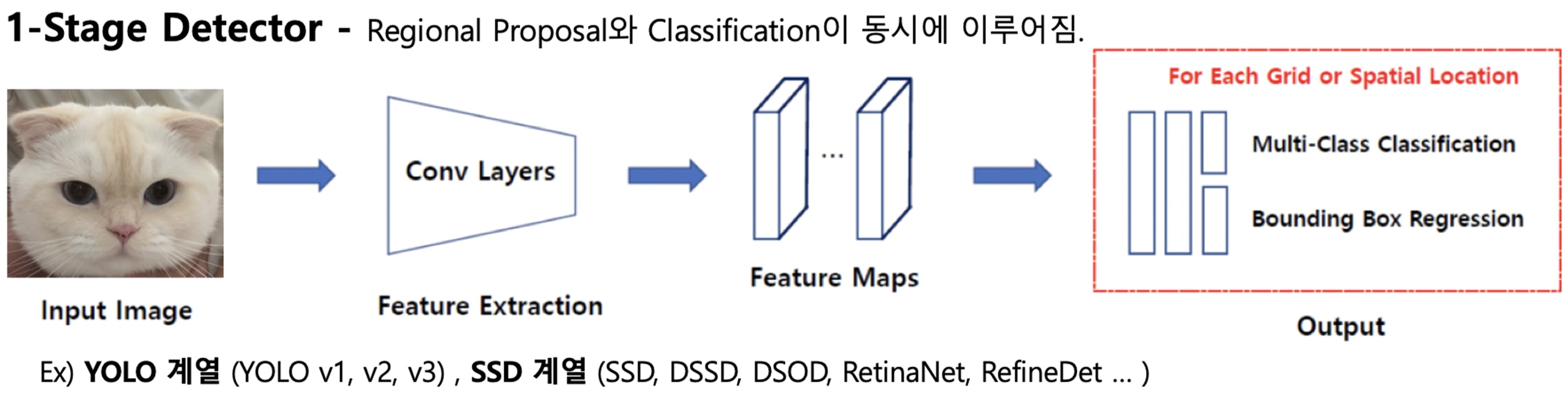
1-Stage Object Detector는 이름 처럼 한 가지의 단계로 구성된 접근 방식이다.
입력 영상에서 바로 객체의 위치와 클래스를 예측하는 방식으로, 빠른 속도와 낮은 컴퓨팅 자원을 필요로 한다는 이점이 있다. 하지만, 상대적으로 낮은 정확도와 불안전성을 가질 수 있다는 단점도 존재한다.
YOLO, SSD (Single Shot Detector), RetinaNet 등이 1-Stage Object Detector에 해당하는 대표적인 예시이다.
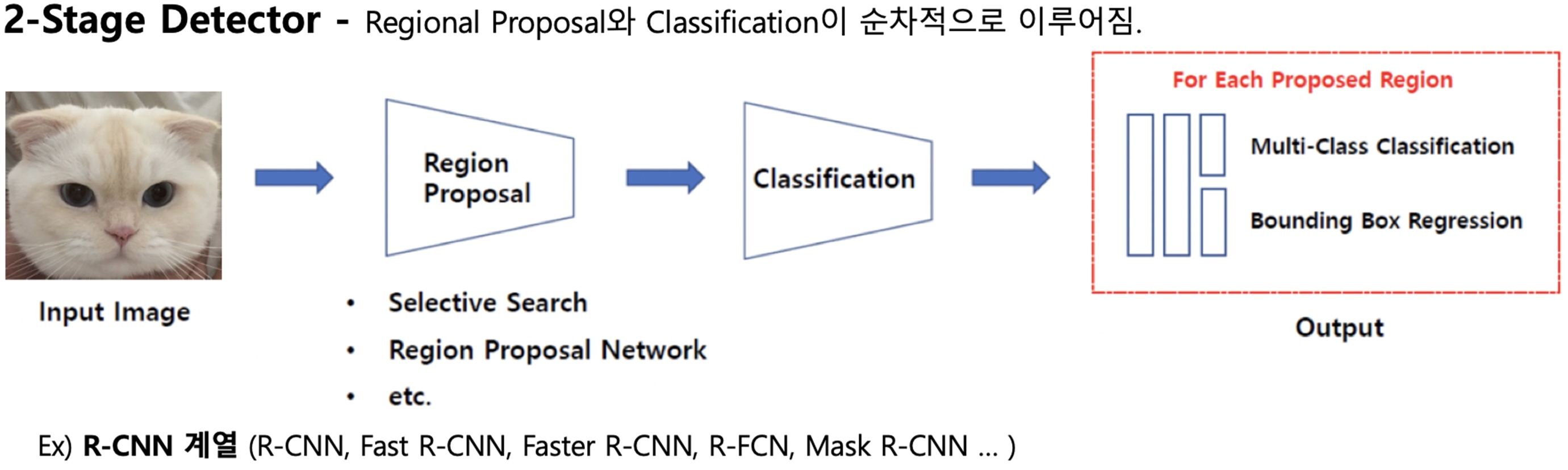
2-Stage Object Detector는 두 가지 단계로 구성된 접근 방식이다.
첫 번째 단계에서는 입력 영상에서 주요한 객체 후보를 선택하고, 두 번째 단계에서는 선택된 객체 후보들에 대해 객체의 위치와 클래스를 정확하게 예측한다.
이러한 모델들은 높은 정확도와 안정성을 가지고 있지만, 상대적으로 느린 속도와 높은 컴퓨팅 자원이 필요하다는 단점이 있다.
Faster R-CNN, Mask R-CNN, Cascade R-CNN 등이 2-Stage Object Detector에 해당하는 대표적인 예시이다.
1-Stage Object Detector와 2-Stage Object Detector는 각각의 장단점이 있으므로, 실제로 Object Detection Task에서는 사용하고자 하는 데이터, 컴퓨팅 자원, 요구하는 정확도 등 다양한 요소를 고려하여 모델을 선택하는 것이 적절하다.
