
You Only Look Once : Unified, Real-Time Object Detection
YOLO, "You Only Look Once", '한 번만 보고 바로 처리를 한다'는 장점을 가진 Object Detection 모델이다.
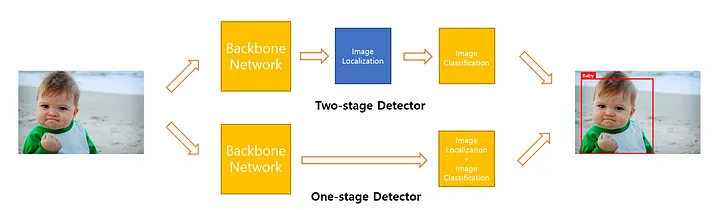
Object Detection 모델은 두 가지 방식이 존재한다.
하나는 Image Classification과 Localization이 별도로 존재하는 Two-Stage Detector 방식, 다른 하나는 두 과정을 별도로 구분하지 않는 One-Stage Detector 방식이다.
Two-Stage Detector는 예측 성능이 뛰어난 반면, 속도가 느리다는 단점이 있다. Two-Stage Detector 방식의 대표적인 모델로 Faster R-CNN이 있는데, 실행 속도가 10FPS 미만이라고 한다.
반면 YOLO는 One-Stage Detection 방식을 사용하는데, Two-Stage Detector 방식을 사용하는 모델보다 속도가 빠르면서도, 성능이 크게 떨어지지 않는다는 장점을 가지고 있다.
YOLO의 장점
- 기존 Object Detection 모델에 비해 간단한 구조로, 학습과 예측의 속도가 빠르다.
- 모든 학습 과정이 이미지 전체에서 일어나기 때문에 단일 대상의 특징뿐 아니라 이미지 전체의 맥락을 학습하게 된다.
- 대상의 일반적인 특징을 학습하기 때문에 다른 영역으로의 확장에서도 뛰어난 성능을 보인다.
YOLO가 One-Stage Detector 방식을 사용하기 때문에 얻을 수 있는 장점들로,
Two-Stage Detector인 R-CNN 계열의 모델들은 Sliding Window, Region Proposal 방식으로 이미지의 일부분을 가지고 객체를 탐지한다. 그렇기 때문에 이미지의 배경 부분이 객체와 비슷할 경우, 종종 잘못된 예측 결과를 갖는 오류가 있다.
하지만 YOLO는 이미지 전체에서 학습이 일어나기 때문에, 객체의 특징 뿐 아니라 객체가 포함된 주변 배경까지 학습하게 되어, YOLO는 Faster R-CNN에 비해 Background를 False Positive로 판단하는 빈도가 수준이라고 한다.
또한 YOLO는 이미지 전체를 학습하는 과정에서 Generalizable 한 Representation을 학습한다. 일반화 가능한 특징을 학습하므로, 실제 이미지에 대해 학습하여 실제가 아닌 미술 작품으로 테스트한 경우 DPM, R-CNN에 비해 YOLO가 월등히 높은 성능을 보였다고 한다. 하나의 도메인에 국한되지 않고 새로운 이미지 도메인에서도 비교적 높은 성능으로 적용할 수 있는 것이다.
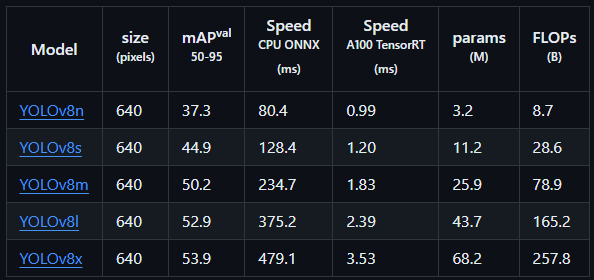
YOLO 공식 문서에 나와 있는 자료로, 빠른 속도와 높은 mAP (성능) 을 확인할 수 있다.
YOLO의 구조

- 이미지를 SxS 그리드로 분할한다.
- 이미지 전체를 신경망에 넣고, 특징 추출을 진행하여 Prediction Tensor를 생성한다.
- Prediction Tensor는 그리드 별 Bounding Box 정보, 신뢰 점수, 클래스 확률을 포함
- 그리드 별 예측 정보를 바탕으로 Bounding Box를 조정하고, Classification 작업을 수행한다.
- 각각의 Grid Cell은 B개의 Bounding Box 및 각 Bounding Box에 대한 Confidence-Score를 가짐
- - 각각의 Grid-Cell은 C개의 Conditional Class Probablity를 가짐
- 각각의 Bounding Box는 x, y 좌표, w, h, confidence를 가짐
- x1,x2,y1,y2를 가지는 다른 모델들과 달리 (x, y) 좌표가 Bounding Box의 중심점을 의미하며, x, y 좌표에 더해 w, h값을 가지고 전체 Bounding Box 영역을 찾을 수 있다.
- 각각의 Grid Cell은 B개의 Bounding Box 및 각 Bounding Box에 대한 Confidence-Score를 가짐
