Object Det 7강 : Advanced Object Detection 1 - Further Development in 2 stage Detectors
1. Cascade RCNN
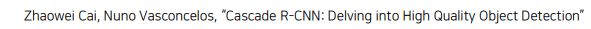
-
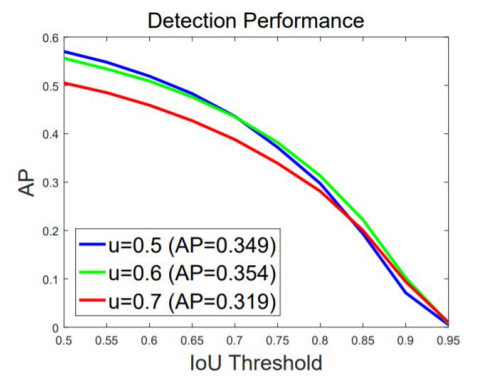
학습되는 IoU threshold에 따라 대응 가능한 IoU 박스가 다름
-
즉, IoU threshold를 높게 잡아야 high quality detection 수행 가능
-
but, 높은 기준에 따라 성능 하락 우려
-
-> Cascade RCNN
-
Iterative BBox at inference는 bbox pooling을 반복 수행하여 마지막 결과를 사용
-
Integral Loss는 IoU threshold가 다른 Classifier들을 사용해 confience score의 평균치를 사용
-
Cascade R-CNN = Iterative BBox at inference + Integral Loss
-
즉, IoU threshold가 다른 RoI head를 cascade로 쌓아 성능 향상
2. Deformable Convolutional Networks(DCN)
-
기존의 Conv 연산은 이미지가 정면에서 촬용되었다고 가정
-
즉, gemoetric transformations에서 한계 존재


-
기존에는 geometric augmentation이나 geometric invariant feature engineering으로 이 문제를 해결하려 했음


-
하지만, 사람이 geometric 정보를 먼저 파악하고 휴리스틱하게 augmentation이나 operation을 넣어줘야한다는 단점 존재
-
DCN은 일정한 패턴이 아니라 offset을 학습시켜 위치를 유동적으로 변화시켜서 확장, 회전 등의 패턴 변화를 담음
-
한 점 𝑃0 에 대해 convolution 과 deformable convolution layer을 거쳐 ∆𝑃𝑛 만큼 더해줌으로써 deformable 하게 만들어줌.
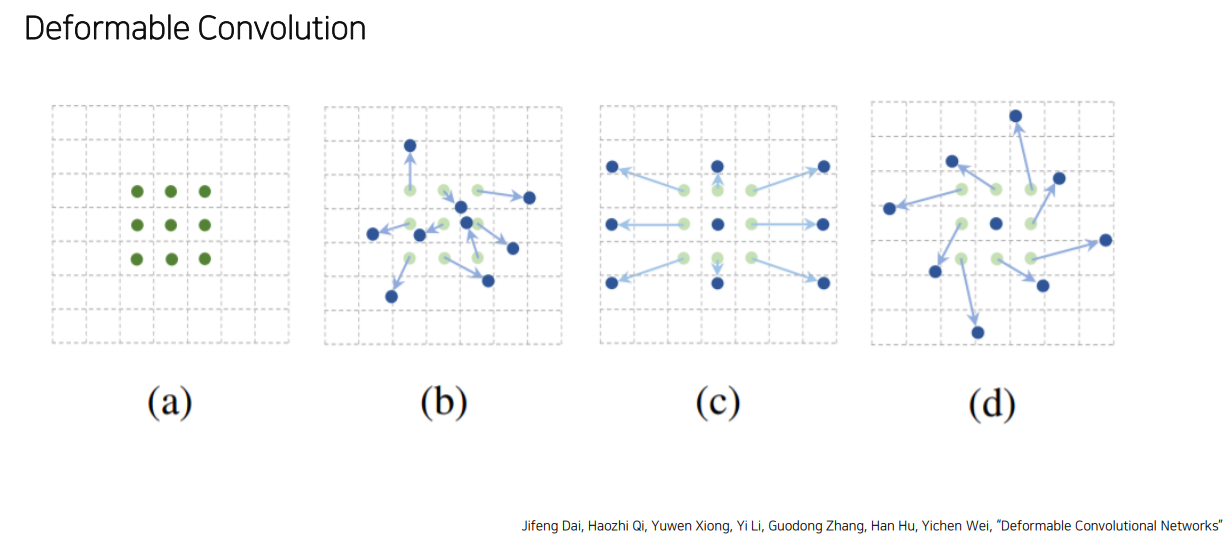
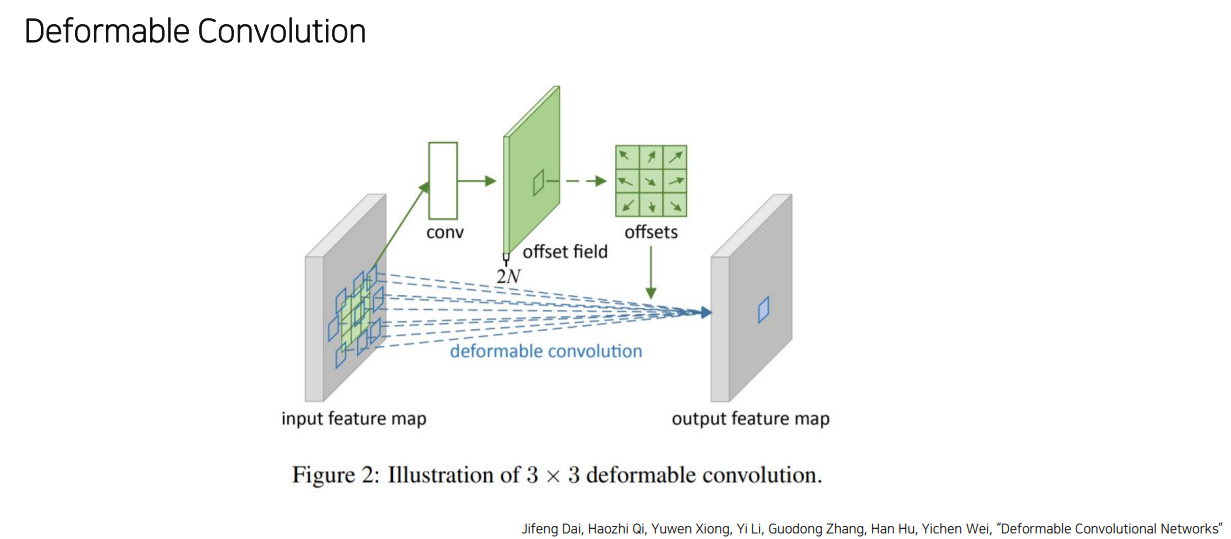

- 주로 object detection, segmentation에서
좋은 효과를 보임

3. Transformer
3-1. Vision Transformer (ViT)
- for classification
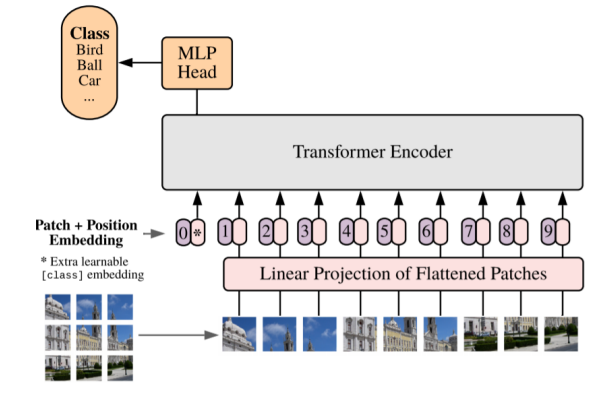
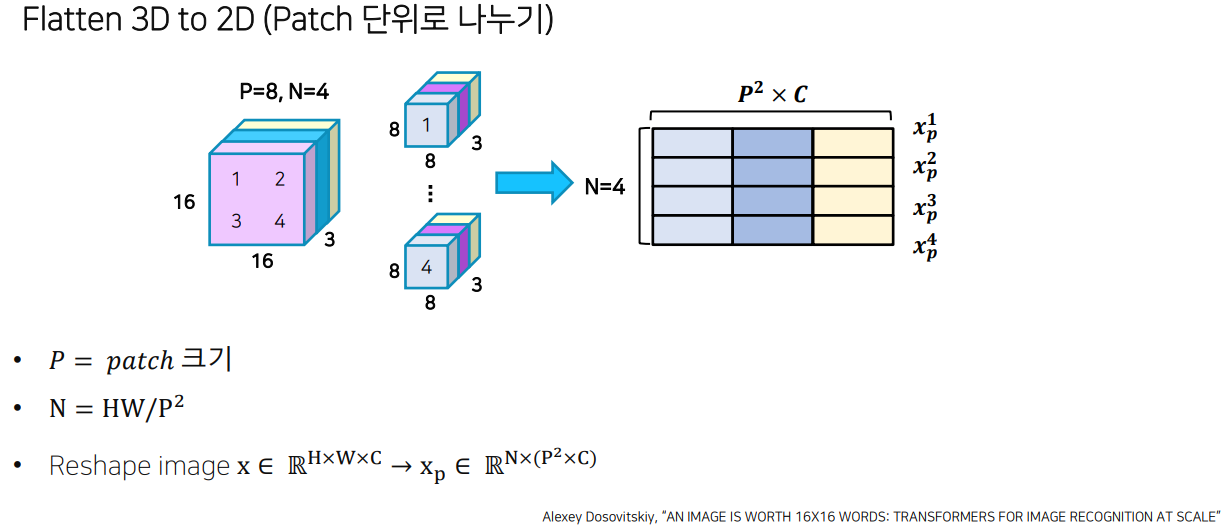
1) Flatten 3D to 2D (Patch 단위로 나누기)
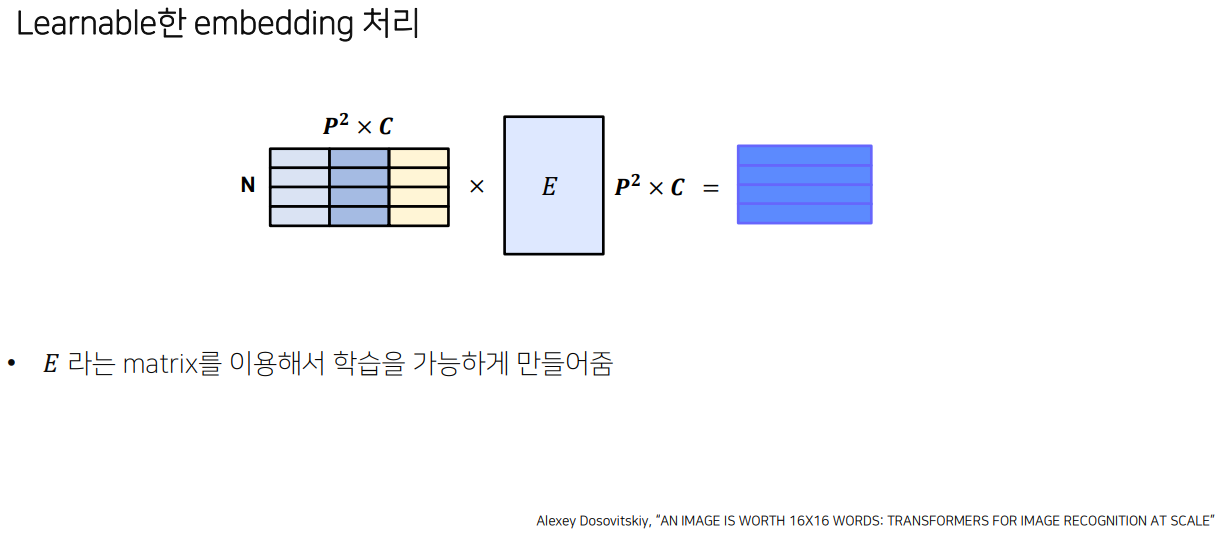
2) Learnable한 embedding 처리
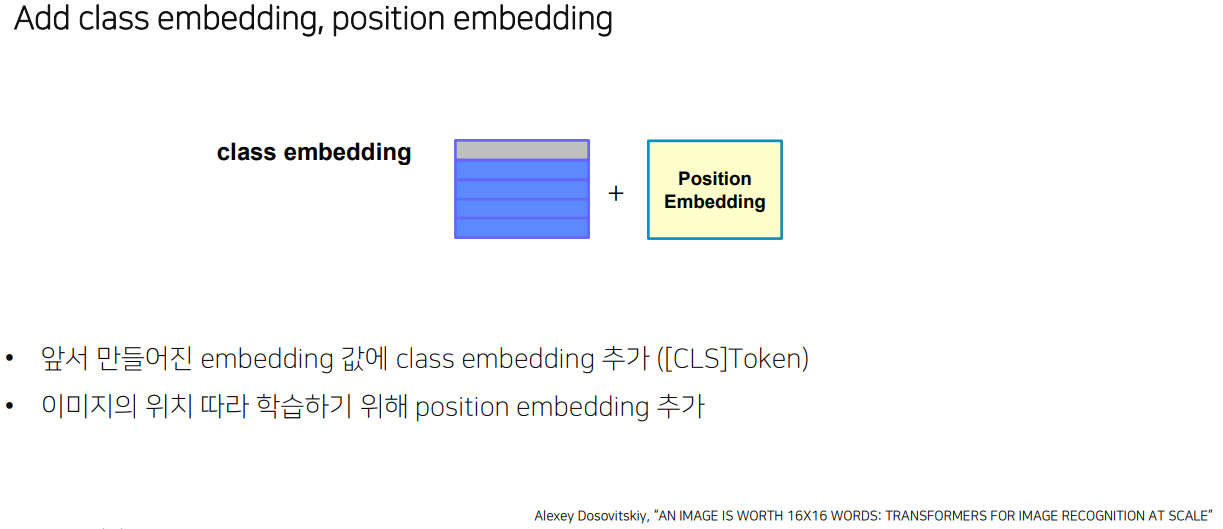
3) Add class embedding, position embedding
4) Transformer
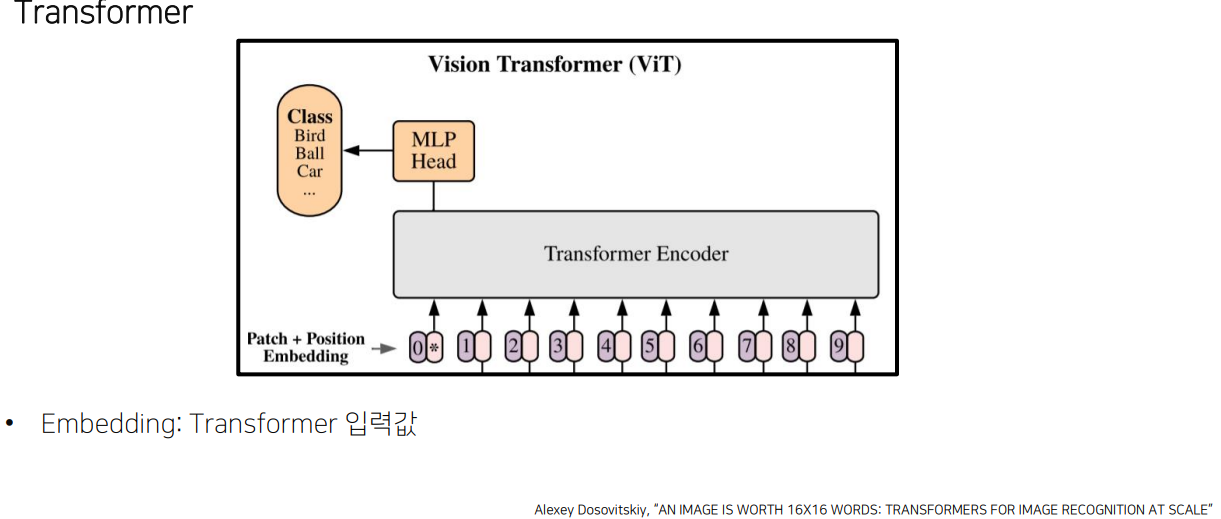
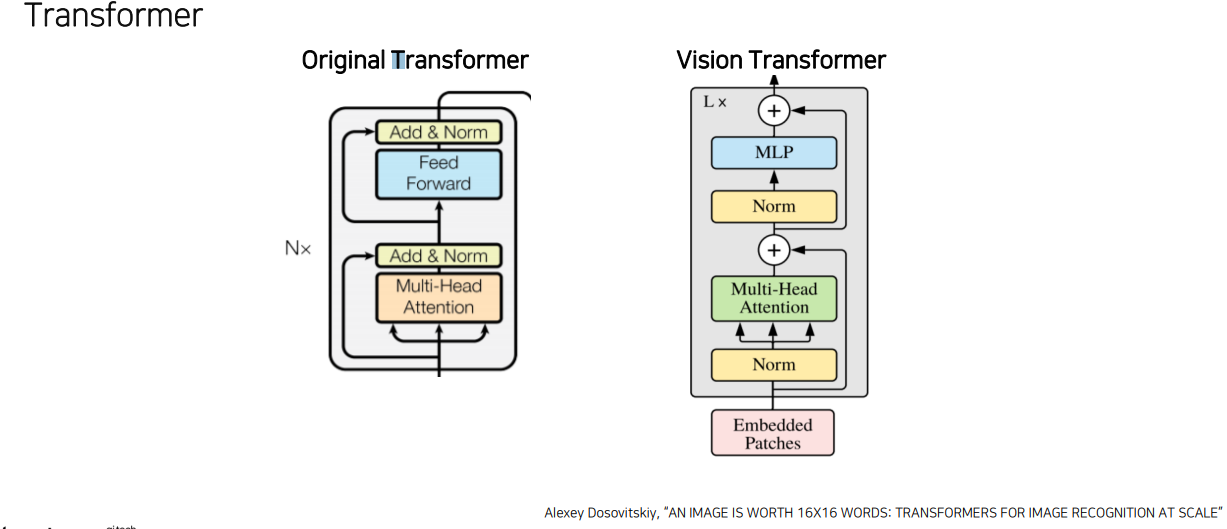
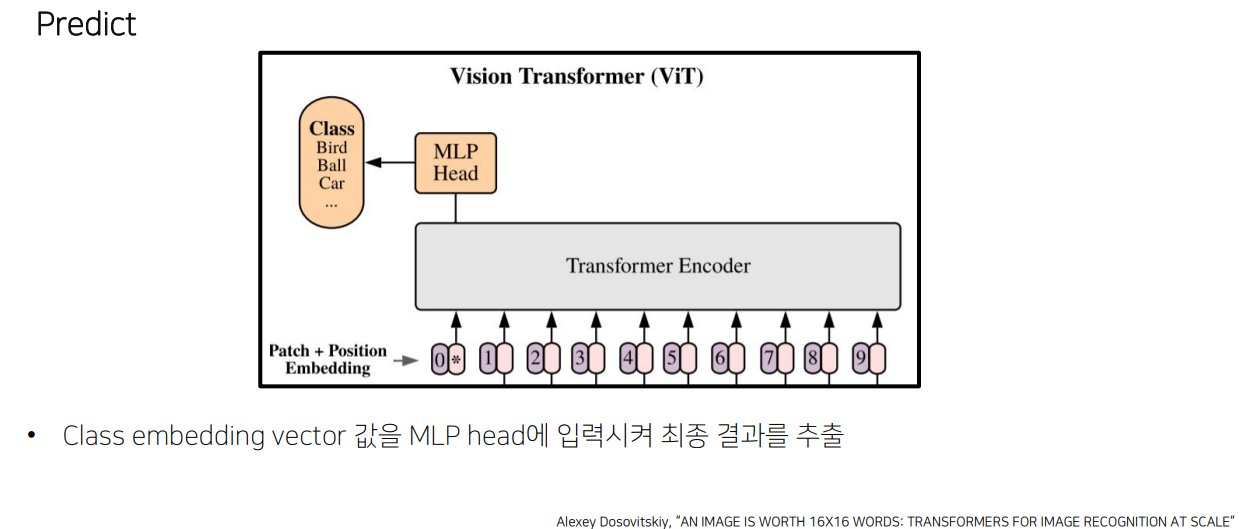
5) Predict
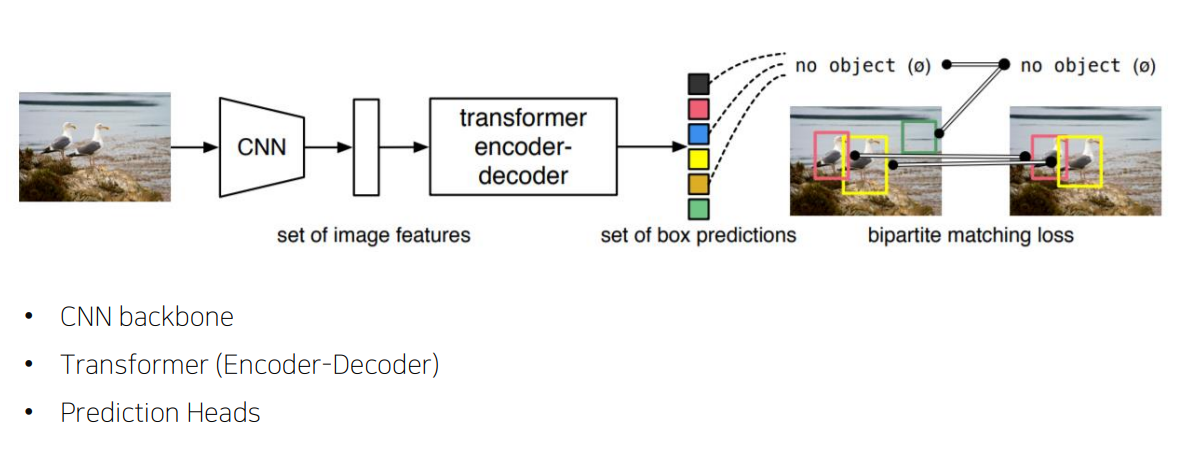
3.2 DETR(End-to-End Object Detection with Trnasformer)
contributions
1) object detection에 처음으로 transformer 사용
2) 기존의 Object Detection의 hand-crafted post process 단계를 transformer를 이용해 없앰(e.g., NMS)
Architecture
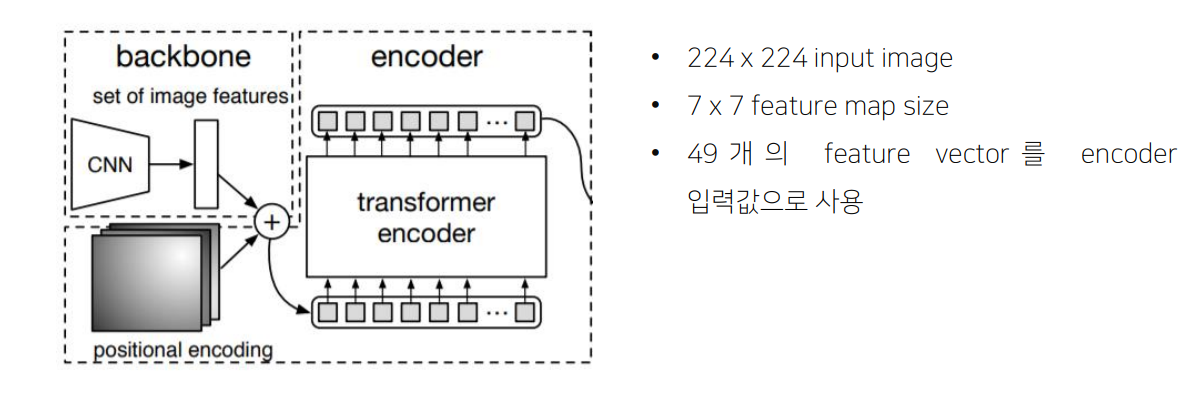
-
많은 연산량이 필요하기 때문에 highest level feature map만 사용( 하락)
-
Flatten 2D
-
Positonal embedding
-
Encoder
Encoder
Decoder
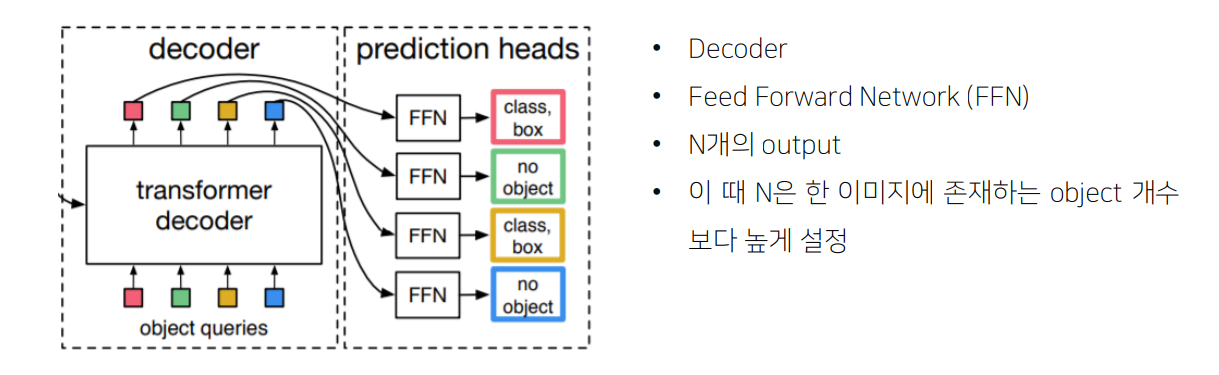
Train
-
Output box의 수인 N이 groundtruth의 box 개수보다 클 경우(더 많은 박스를 예측한 경우), 부족한 object 개수만큼 no object로 padding 처리
-
즉, prediction과 groundtruth가 N:N으로 매핑되어 NMS 같은 post-process가 필요 x
3.3 Swin Transformer
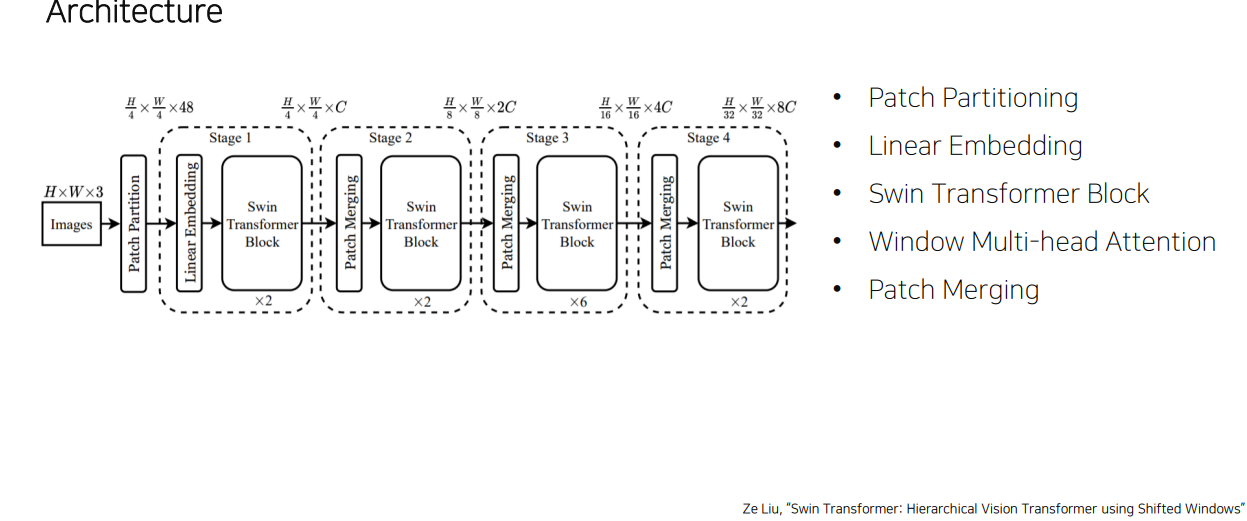
shortcomings of ViT
1) 많은 학습량 요구
2) 연산 비용 큼
3) 일반적인 backbone으로 사용하기 어려움
=> CNN과 유사한 구조로 설계하고, window라는 개념을 활용해 cost 줄임
Patch Partioning
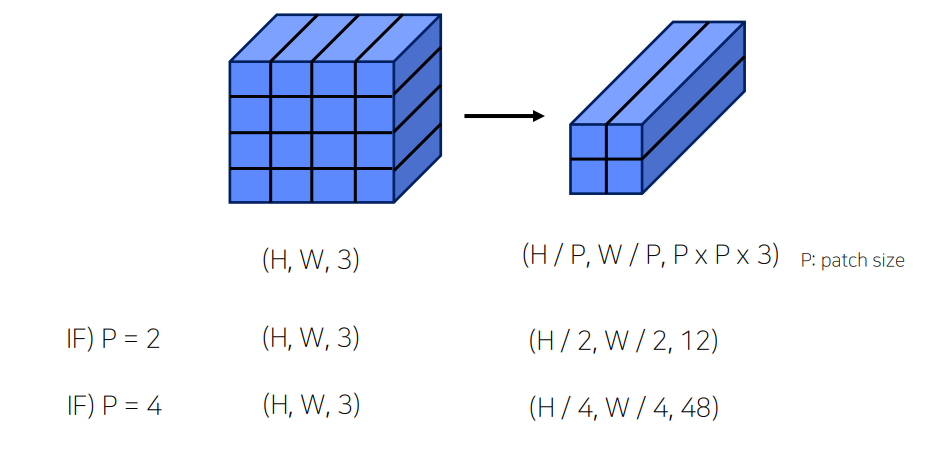
- 이미지를 패치로 나눔
Linear Embedding
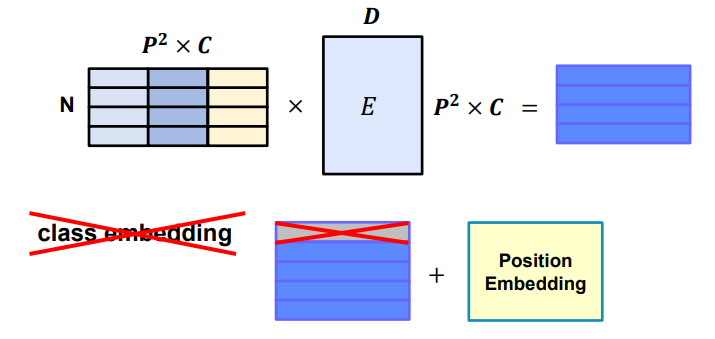
- ViT와 동일하지만 class embedding 제거
Swin Transformer Block
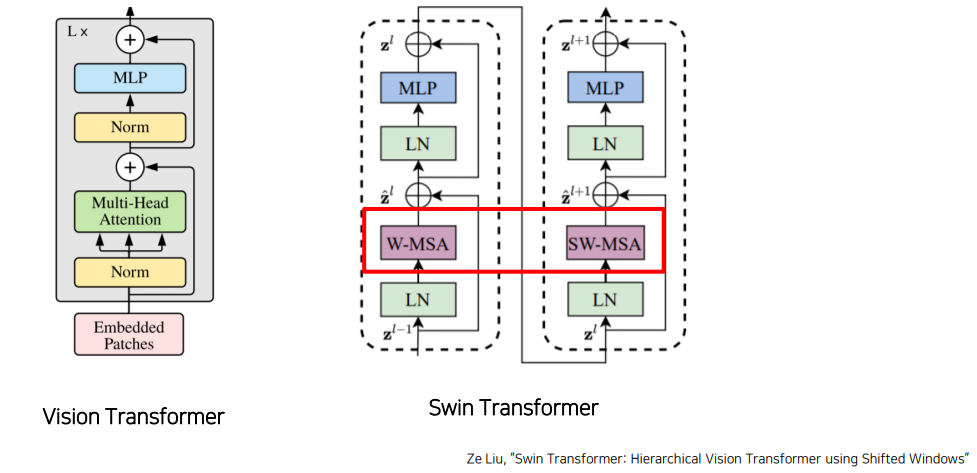
Window Multi-Head Attention

-
window 단위로 embedding을 나눠 해당 window의 embedding에 대해서만 transformer 연산 수행
-
window 크기에 따라 연산량을 조절할 수 있지만 receptive field 제한한다는 단점 존재
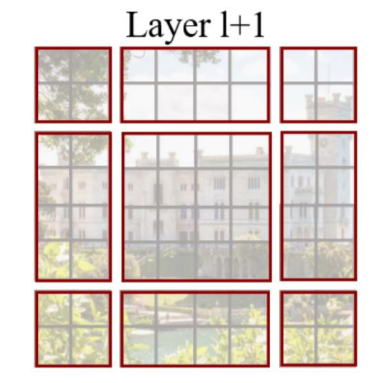
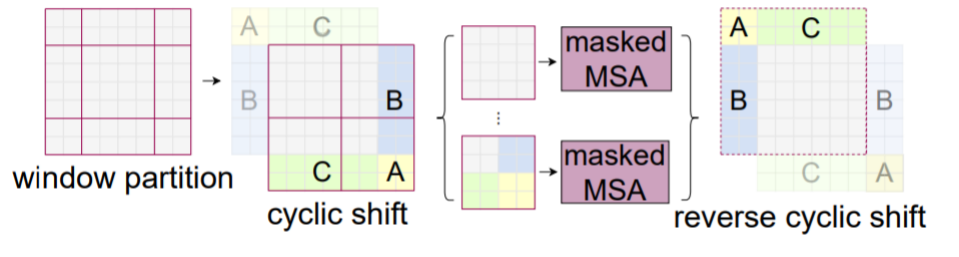
Shifted Window Multi-Head Attention
-
window를 이동시켜 receptive field를 조절
-
window size보다 작은 남는 윈도우 조각들을 모두 윈도우 사이즈로 패딩처리하는 것이 아니라 cyclic shift 기법으로 모아 연산량을 줄임
-
이때 사실은 서로 다른 윈도우이므로 마스킹 처리함
-
처리 이후 cyclic shift 연산을 되돌림
(참고자료 : https://pajamacoder.tistory.com/18)
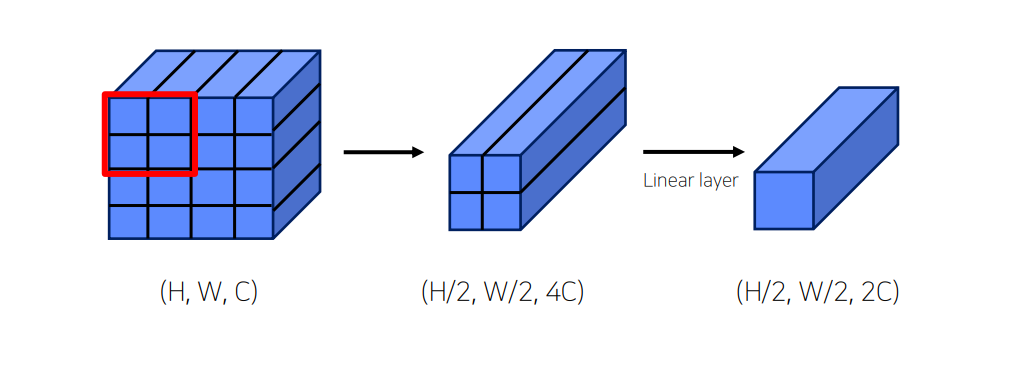
Patch Merging
-
Patch Partitioning처럼 patch size를 줄이고 channel을 늘림
-
Linear layer 사용
Conclusion
-
적은 Data에도 학습이 잘 이루어짐
-
Window 단위를 이용하여 computation cost를 대폭 줄임
-
CNN과 비슷한 구조로 Object Detection, Segmentation 등의 backbone으로 general하게 활용
