Object Det 8강 : Advanced Object Detection 2
Further Development in 1 Stage Detectors
1. YOLO v4
-
하나의 GPU에서 학습 가능한 빠르고 정확한 Obcet detector
-
BOF, BOS 기법들의 조합 사용
Bag of Freebies : inference 비용 늘리지 않고 정확도 향상
Bag of Specials : inference 비용 조금 높이지만 정확도 크게 향상
BOF
1) Data Augmentation
-
CutMix
-
CutOut
-
MixUp
2) Semantic Distribuion Bias
배경 정보 등 라벨 불균형 해결
3) Label Smoothing
4) Bounindng Box Regression
-
기존의 MSE는 거리가 일정하더라도 IoU가 다를 수 있어 IoU 기반의 loss를 제안
-
GIoU(Generalized-IoU) : Bbox와 GT를 모두 포함하는 최소 크기의 box를 활용하는 IoU를 이용해 loss 계산
-
GIoU의 단점을 보완한 DIoU, CIoU 도 존재
BOS
1) enhance receptive field
-
Feature map의 receptive field를 키워서 검출 성능을 높이는 방법
-
SPP(Spatial Pyramid Polling)
-
ASPP(Atrous SPP)
-
RFB(Receptive Field Block)
2) Attention Module
-
global attention을 활용해 얼마나 중요한지 context 판단
-
SE(Squeeze-and-Excitation) : channel attention
-
CBAM(Convolutional Block Attention Module) : channel attention + spatial attention
3) Feature Integration
-
Feature map을 통합하기 위한 방법
-
FPN(Feature Pyramid Network)
-
SFPM(Scale-wise Feature
Aggregation Module) -
ASFF(Adaptively Spatial Feature
Fusion) -
BiFPN
4) Activation Function
-
Swish / Mish : 약간의 음수 허용해 ReLU의 zero bound보다 gradient 흐름에 좋은 영향(모든 구간에서 미분 가능)
-
Leaky ReLU
-
Parametirc ReLU
-
ReLU6
5) Post-processing method
-
NMS
-
Soft NMS
-
DIoU NMS
Others
Regularization method
DropOut, DropPath, Spatial DropOut, DropBlock
Normalization
Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter
Response Normalization (FRN), Cross-Iteration Batch Normalization (CBN)
Skip-connections
Residual connections, Weighted residual connections, Multi-input weighted
residual connections, Cross stage partial connections (CSP)
Cosine annealing scheduler
Architecture

Cross Stage Partial Network (CSPNet)
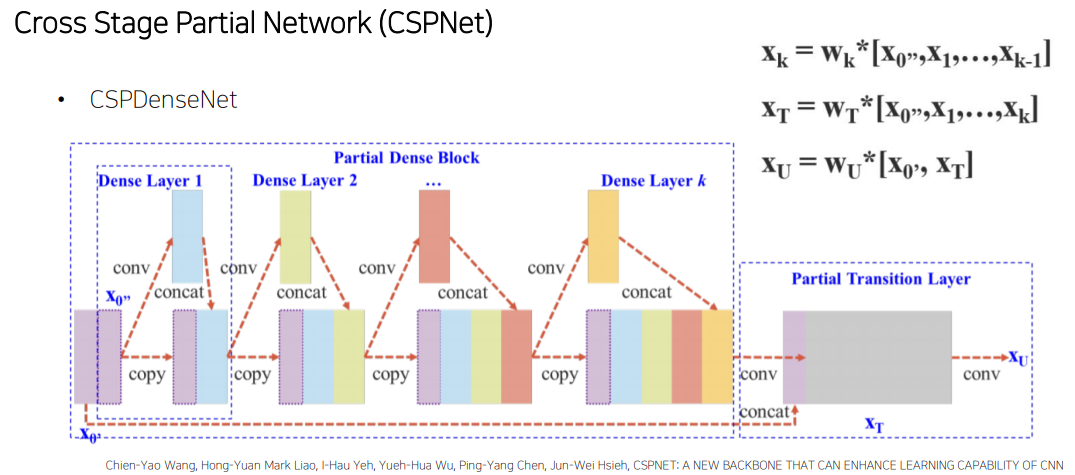
-
첫 feature map의 절반은 마지막에 그대로 concat해줌
-
기존 DenseNet의 문제점인 가중치 업데이트 시 gradient 정보의 재사용 문제(정보 과다) 해결
New Data Augmentation methods

-
Mosaic
-
Self-Adversarial Training(SAT)
눈에 보이지 않는 노이즈를 추가해 오작동 유발해 robust한 학습 가능
Modification
-
modified SAM(Spatial Attention Module)
spatial wise attention -> point-wise attention -
modified PAN(Path Aggregation Network
)
add -> concat -
Cross mini-Batch Normalization (CmBN)
batch를 accumulate해서 적은 batch size일 때의 normalization 시 성능 하락 막음
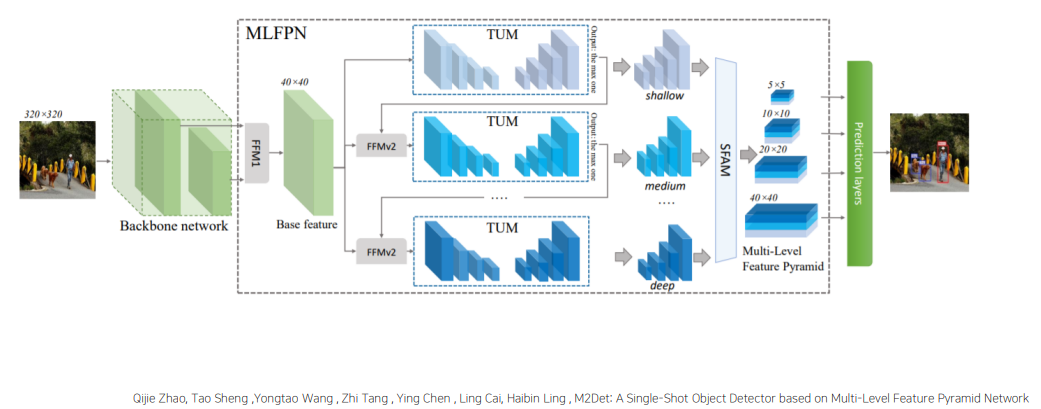
2. M2Det
-
기존의 detection에서는 물체의 스케일을 고려하기 위해 주로 FPN 사용
-
but, classification용 backbone은 single-level layer이기 때문에 multi-level 고려 못함
-
간단한 외형을 위한 low-level / 복잡한 외형을 위한 high-level layer 모두 필요
-
M2Det : 기존의 SSD에서 Multi-level, multi-scale feature pyramid(MLFPN)을 추가하기 때문에 SSD의 Extra Conv 사용 X
-
Soft-NMS 사용
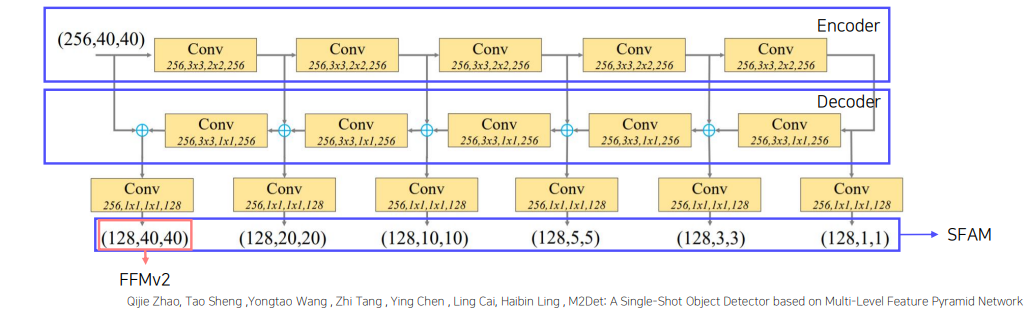
Architecture
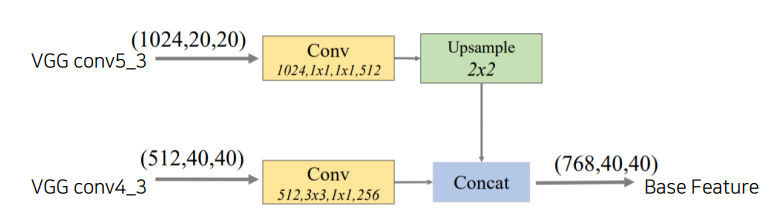
FFM(Feature Fusion Module)
-
FFMv1 : 서로 다른 scale의 두 feature map을 concat semantic 정보를 풍부하게 함 - Upsample로 크기 맞추고 1x1 Conv로 채널 절반씩 줄여 concat함
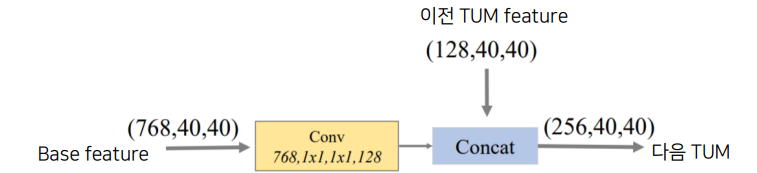
-
FFMv2 : FFMv1을 통과한 Base feature와 이전 TUM 출력 중 가장 큰 feature을 concat하고 다음 TUM 입력으로 사용
TUM(Thinned U-shape Module)
-
Encoder-Decoder 구조
-
Decoder의 출력은 현재 level에서의 multi-scale features
SFAM(Scale-wise Feature Aggregation Module)
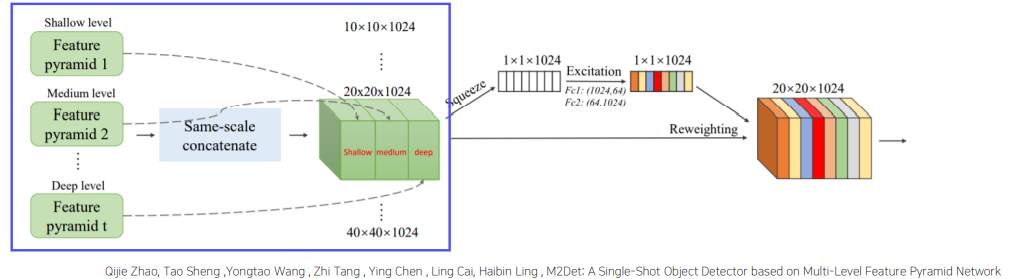
-
TUMs에서 생성된 multi-level multi-scale을 합치는 과정
-
각 level 별로 동일한 크기를 가진 feature들끼리 연결하기 때문에 각각의 scale의 feature들은 multi-level 정보를 포함
-
이후 SE block으로 channel-wise attention
3. CornerNet
-
기존의 detector들은 Anchor Box를 활용
-
이때 box 수가 많기 때문에 class imbalance 문제 발생
-
또한, 그리드 당 anchor box 개수나 사이즈, 비율 등 하이퍼 파라미터를 고려해야하기도 함
-
CornerNet : Anchor-free 1 stage detector(top-left/bottom-right 이용)
Architecture
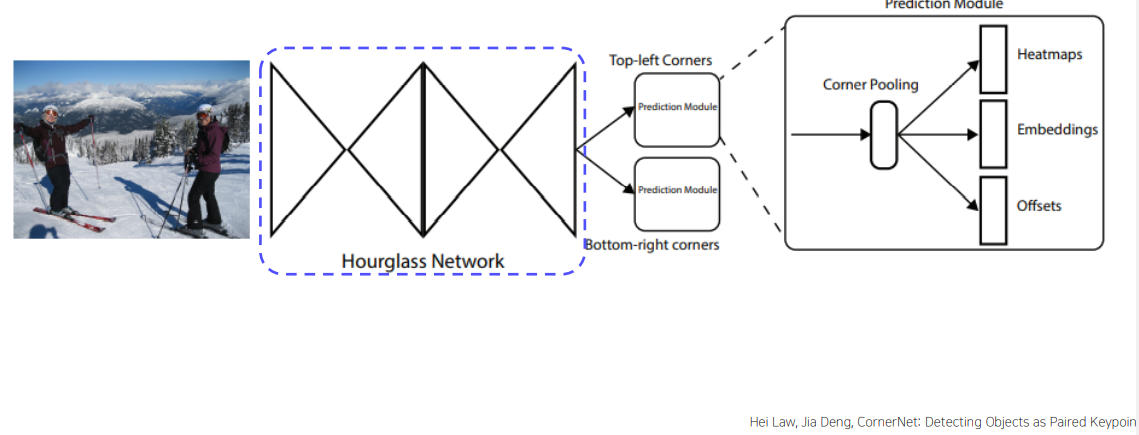
Hourglass
- Human pose estimation task에서 사용하는 모델
- Global, local 정보 모두 추출 가능
- Encoder-Decoder 구조
Encoder : Feature extraction
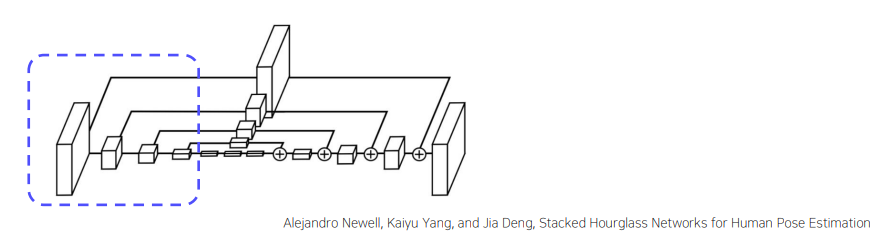
-
conv layer + maxpool로 feature 추출
-
스케일 감소엔 maxpooling 대신 stride 2를 사용
Decoder : Reconstruc
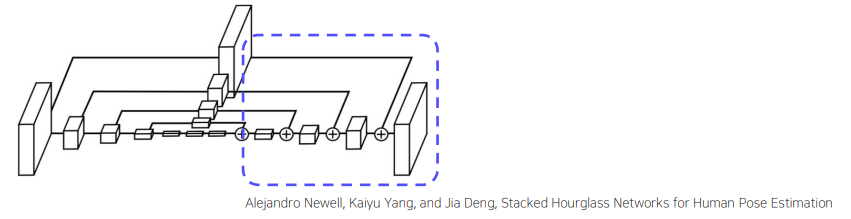
-
Encoder에서 스케일 별로 추출한 feature 조합
-
Upsampling에서 Nearest Neighborhood Sampling 사용
-
feature reconstruct에서 element-wise addition 사용
Prediction Module
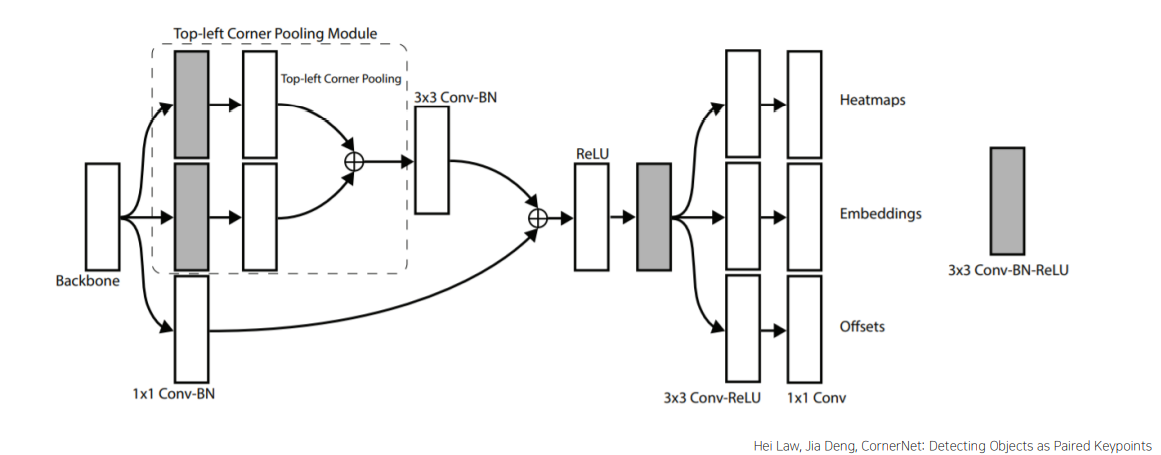
top-left/bottom-right을 별도의 모듈에서 예측
1) Heatmaps
HxWxC로 구성되어 각 클래스에 해당하는 corner의 위치를 binary mask로 처리
positive location 반지름과의 거리에 따라 negative location들의 페널티 부여
이때 반지름의 크기는 물체의 크기에 따라 결정
Focal loss의 변형 loss 사용해 정답에 근접한 예측값은 낮은 loss 부여
2) embeddings
코너 쌍의 embedding 값의 차이(거리)가 작으면 같은 물체에 대한 bounding box라고 판단
3) offsets
conv 연산 시 floting point loss 발생
Heatmap에서 원본 이미지로 mapping 시 차이 발생
=> offset을 이용해 예측 위치 미세 조정(Smooth L1 loss)
Corner pooling
물체의 코너라고 딱히 특징적인 부분이 있는 건 아님
Coner pooling : Hourglass에서 나온 feature map을 가로, 세로로 이동하면서 max 값으로채워버린 후 더하여 output을 만듦
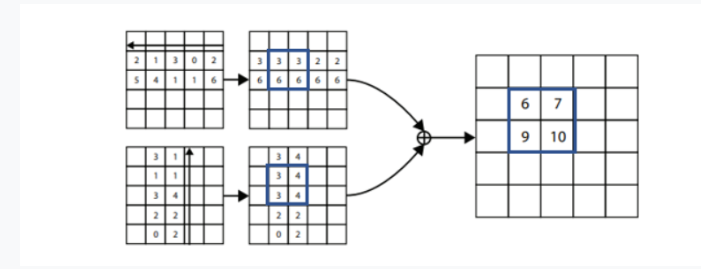
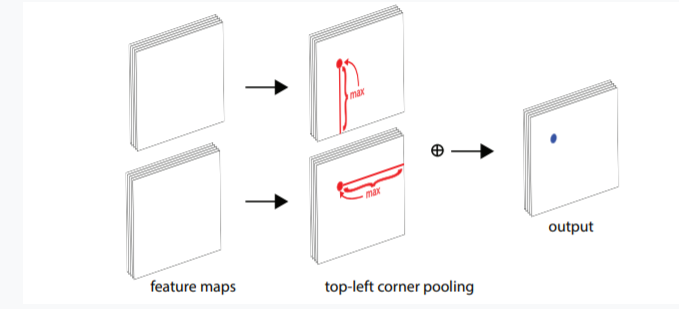
사진/참고 : https://velog.io/@to2915ny/CornerNet
Other anchor-free models
Center Net
-
Keypoint heatmap을 통해 중심점(center)예측
-
Center사용하여 단 하나의 anchor box생성
-
Keypoints grouping 과정이 필요 없어 시간 단축
-
NMS 과정 x


FCOS
-
중심점으로부터 바운딩 박스의 경계까지의 거리 예측
-
FPN을 통해 multi-level 예측


