3. JpaRepository

해당 내용은 어떻게 위와 같이 ...Repository라는 이름을 가진 인터페이스를 하나 만들고 JpaRepository 라는 인터페이스를 상속받게만 하면 save() 같은 메소드를 호출하고 데이터를 DB를 통해 조작할 수 있게 되는지에 대한 내용이다.
- JpaRepository는 여러 다른 인터페이스와 CrudRepository를 상속받는다.
save() 메소드나 findBy..() 메소드등은 CrudRepository 인터페이스에서 가져온 것이다. 결국 인터페이스들의 상속에 상속을 통해서 부모 인터페이스들의 모든 기능을 내가 생성한 인터페이스의 기능으로 받은 것이다.
근데 중요한 점은 인터페이스이기 때문에 기능의 껍데기인 추상메소드들만 존재할 뿐 어떻게 작동하는지는 정한 적이 없다.
그럼에도 불구하고 기능들을 사용가능한 이유는 스프링이 해당 인터페이스를 프록시 객체로 구현하고 실제로 필요한 메소드들이 구현되어 있는 구현체인 SimpleJpaRepository를 프록시 객체를 통해 내부적으로 불러내기 때문이다.
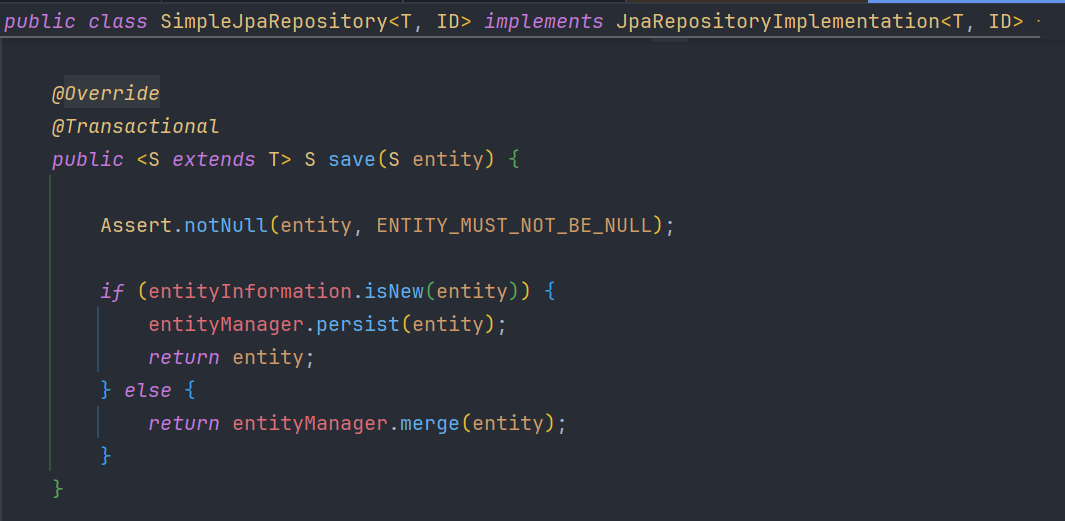
자바는 객체 단위로 프로그램이 실행된다. 그러려면 객체로 존재해야 기능을 사용할 수 있다는 것인데, 우리가 만든 인터페이스를 실행하기 위해서 스프링이 프록시라고 하는 가짜 객체로 구현해서 우선 껍데기를 씌운 다음, 내부적으로 위와 같은 SimpleJpaRepository을 호출해서 save() 메소드와 같이 내부에 구현되어 있는 메소드를 사용할 수 있게 만드는 것이다.
4. N+1 문제
사실 이 문제는 너무 흔한 이슈이기 때문에 짧게 다루자면
- JPA의 기본값인 지연 로딩, 즉 필요할 때만 데이터를 가져오는 부분에 의해 발생하는 부작용이다.
1 (처음 조회): findAll()로 게시글 10개를 가져온다. (쿼리 1번)
+
N (지연 로딩 발생): 게시글마다 작성자 이름을 출력하려고 post.getUser().getName()을 호출한다.
-> 첫 조회 때 작성자를 안 가져왔으므로, 루프를 돌 때마다 게시글 개수(N)만큼 작성자를 찾는 쿼리가 추가로 나간다. 쿼리 1번으로 끝날 일이 1 + N번으로 늘어나는 것이다.
하지만 지연 로딩은 메모리와 성능을 아끼기 위한 아주 좋은 기술이다.
이 문제를 해결하기 위한 방법에는 보편적으로 3가지가 있는데,
- @EntityGraph
JPA에게 해당 조회에서 특정 조회를 함께 시키는 방법이다. 따로 쿼리를 작성하지 않고 사용이 가능하다. - fetch join
쿼리를 통해 한 번에 조인해서 가져오는 방식이다. - DTO Projection
애초에 엔티티를 가져오는 것이 아니라, 필요한 값만 골라서 조회하는 방식이다.
차이를 설명하자면, 다른 설정없이 쓰면 기본적으로 @EntityGraphs는 Left Join을 통해 데이터를 가져오고 fetch join의 경우 Inner Join을 통해 데이터를 가져온다. 물론 설정에 따라 조인 방식은 변경할 수 있고 그 외로는 코드의 간편함, 세부적인 쿼리 조작의 면에서 차이가 있다.
DTO Projection의 경우는 응답용 값만 딱 필요한 경우에는 가장 효율적일 수 있으나 그 외의 값들은 가져올 수 없기 때문에 특정한 상황에 사용하는 것이 좋다.
그 외로도 초기화 되지 않은 대상을 설정한 사이즈만큼만 가져오고 더 필요할 때 다시 사이즈만큼 조회하는 batch fetching도 하나의 방법이 될 수 있다.
5. 원자성 보장
원자성(Atomicity)은 하나의 작업이 “전부 성공하거나, 전부 실패해야 한다”는 성질이다.
예를 들어 재고 차감 로직이 있다고 하자.
상품 재고 조회 -> 재고가 1개 이상인지 확인 -> 재고 차감 ->주문 생성
이 네 단계는 논리적으로 하나의 작업이다. 그런데 실제 실행은 여러 단계로 나뉘기 때문에, 중간에 다른 요청이 끼어들 수 있다. 바로 이 지점에서 원자성 문제가 발생한다.
이를 해결하기 위해 보편적으로 3가지 방법이 존재한다.
-
낙관적 락 (Optimistic Lock)
말 그대로 낙관적으로 보고 충돌이 없을 거라고 가정한 것이다. 따라서 락을 거는 방식이 아니라, 특정 버전을 기록해놓고 커밋할 때 내가 읽었던 버전이랑 현재 버전이 다르면 충돌로 판단하고 예외를 던지는 방식이다. -
비관적 락 (Pessimistic Lock)
낙관적 락과는 다르게 충돌이 날 거라고 미리 가정을 하고 미리 DB에 락을 걸어버리는 것이다. 쓰기/읽기 락을 걸 수 있는데,
PESSIMISTIC_READ → 내가 읽는 동안 다른 트랜잭션이 수정 못함
PESSIMISTIC_WRITE → 내가 읽는 동안 다른 트랜잭션이 읽기/수정 모두 못함
낙관적 락의 경우 락을 실제로 잡지 않아서 성능은 좋지만 충돌 시 재시도 로직을 직접 짜야하는 단점이 있고, 비관적 락의 경우 락을 실제로 잡기 때문에 정합성은 확실하지만 대기가 생겨서 성능이 낮아지는 단점이 존재한다.
- 조건부 Update
애플리케이션 단을 거치는게 아니라 DB에 바로 조건을 걸고 수정하는 것이다. 아래와 같이 쿼리 자체를 조건을 걸고 발생시켜서 원자성을 보장하는 방법이다.
update product
set stock = stock - 1
where product_id = 1
and stock >= 1;
이외에도 분산 락, 큐 기반 처리 등이 존재하지만 이들은 대규모 서비스에서 주로 사용되는 방식으로 고려된다.
