[DCAI] 2. Label Errors and Confident Learning

Confident Learning으로 데이터셋 라벨 오류 탐지 및 정정하기
머신러닝 분야에서 CIFAR, MNIST, ImageNet, IMDB와 같은 데이터셋을 사용해 본 적이 있다면, class 라벨이 모두 정확하다고 가정했을 것
→ 그러나 ImageNet에만도 10만 개 이상의 라벨 오류가 존재
Confident Learning
- cleanlab 패키지로 오픈소스화되어 있다
- 대부분의 분류 데이터셋에서 라벨 오류를 식별하고, 라벨 노이즈를 특성화(characterize)하며, 노이즈가 있는 라벨로도 자동으로 학습할 수 있게 해준다

2012 ILSVRC ImageNet 훈련 세트에서 Confident Learning을 사용하여 식별한 상위 32개의 라벨 이슈. 라벨 오류(label errors)는 빨간색 박스로 표시되었고, 온톨로지 문제(ontological issues)는 녹색, 다중 라벨 이미지(multi-label image)는 파란색으로 표시되었다
위 그림은 Confident Learning을 사용하여 2012 ILSVRC ImageNet 훈련 세트에서 발견된 라벨 오류의 예시다. 해석을 용이하게 하기 위해, CL을 사용하여 ImageNet에서 발견된 라벨 이슈를 세 가지 범주로 분류했다:
1. 다중 라벨 이미지(Multi-label images, 파란색): 이미지에 하나 이상의 라벨이 존재하는 경우
2. 온톨로지 문제(Ontological issues, 녹색): 맞는 라벨이긴 하지만 적합하지는 않은 경우
- ‘is-a’ 관계: 특정 객체가 지나치게 일반화되어 더 일반적인 객체로 잘못 라벨링된 경우
(예: 'bathtub(욕조)'가 ‘tub’으로 라벨링됨)- ‘has-a’ 관계: 객체의 일부분만에 집중하여 객체를 일반화하지 못한채로 혼동하여 잘못 라벨링된 경우
(예: 'oscilloscope(오실로스코프)'가 ‘CRT screen(CRT 화면)’으로 라벨링됨)이런 온톨로지 문제는 데이터셋에서 클래스 간의 관계를 정확히 이해하고 적용하지 않으면 발생할 수 있으며, 데이터셋에는 적어도 하나의 클래스가 올바르게 라벨링되어야 한다는 것이 핵심
- 라벨 오류(Label errors, 빨간색): 주어진 클래스 라벨보다 예제에 더 적합한 클래스가 데이터셋에 존재하는 경우
Confident Learning을 사용하면, 해당 데이터셋에 적합한 어떤 모델이든 사용하여 어떤 데이터셋에서도 라벨 오류를 찾을 수 있다. 아래는 일반적인 데이터셋에서의 다른 실제 예시들이다.

Confident Learning을 사용하여 다양한 데이터 모달리티와 모델에 대해 Amazon Reviews MNIST, Quickdraw 데이터셋에서 식별된 레이블 오류의 예시
Confident Learning이란?
Confident Learning(CL)은 다음을 위해 지도 학습(supervised learning)과 약한 지도 학습(weak-supervision) 내에서 등장한 하위 분야이다:
- 라벨 노이즈 특성화(characterize label noise): 라벨 오류의 분포와 특성을 이해
- 라벨 오류 찾기(find label errors): 데이터셋에서 잘못된 라벨을 식별
- 노이즈가 있는 라벨로 학습(learn with noisy labels): 라벨 오류를 고려하여 모델을 학습
- 온톨로지 문제 발견(find ontological issues): 클래스 간의 계층 구조나 의미적 관계에서 발생하는 문제를 식별
CL은 노이즈가 있는 데이터를 제거(pruning)하는 것을 원칙으로 다음을 따른다:
-
노이즈가 있는 데이터를 제거(pruning):
주의) 노이즈가 섞인 데이터 제거에 초점을 맞추고 있으며, 라벨 오류를 수정하거나 손실 함수를 수정하지 않는다 -
노이즈 비율을 추정하기 위해 카운팅(counting):
주의) 훈련 전에 모델이 예측 확률을 기반으로 노이즈가 있는 데이터 포인트를 카운팅하여, 미리 노이즈 비율을 추정하고 학습을 시작한다. 즉, 모델이 훈련 과정에서 노이즈 비율을 점진적으로 학습하여 모델 가중치와 노이즈를 동시에 조정하지 않는다 -
신뢰도를 기반으로 예시에 순위(rank)를 매김:
주의) 예시에 순위를 매겨 훈련하는 방식으로 노이즈 문제를 처리하며, 정확한 확률에 따라 각 데이터 포인트에 가중치를 부여하지 않는다 -
결합 분포 추정:
Angluin과 Laird의 분류 노이즈 프로세스의 가정을 기반으로 CL을 일반화할 수 있다. 노이즈가 있는 라벨(주어진 라벨)과 손상되지 않은 라벨(알 수 없는 라벨) 간의 결합 분포(joint distribution)를 직접적으로 추정한다
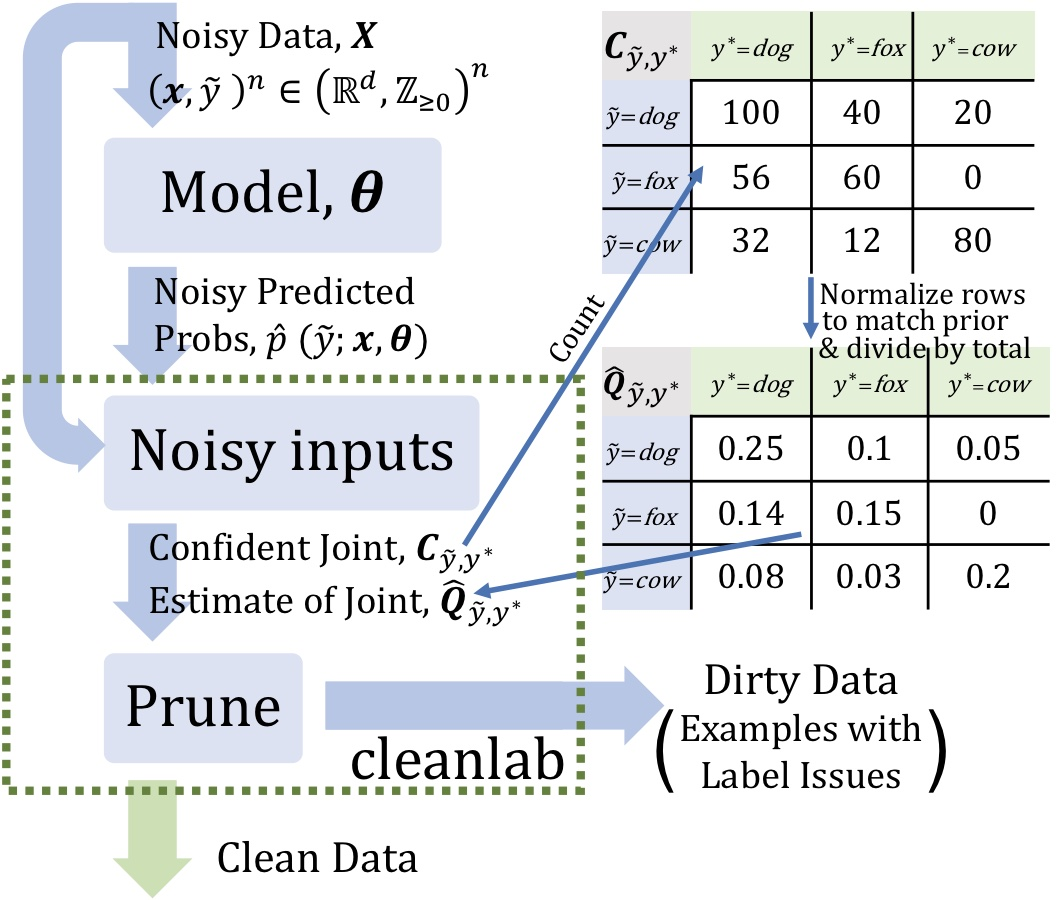
Confident Learning 프로세스와 노이즈가 있는 라벨(주어진 라벨)과 손상되지 않은 라벨(알 수 없는 라벨) 간의 결합 분포(joint distribution) 예시. 여기서 는 관찰된 노이즈 라벨, 는 잠재적인 손상되지 않은 라벨
위 그림에서 볼 수 있듯이, CL은 두 가지 입력이 필요하다:
- out-of-sample predicted probabilities: 예제 수 클래스 수 크기의 행렬
- 노이즈가 있는 라벨(noisy labels): 예제 수 길이의 벡터
약한 지도 학습(weak supervision)을 위해, CL은 세 단계로 구성된다:
- 노이즈가 있는 라벨과 손상되지 않은 라벨(알 수 없는 라벨) 간의 결합 분포(joint distribution)를 추정하여 클래스 조건부 라벨 노이즈를 완전히 특성화한다(fully characterize class-conditional label noise)
- 라벨 이슈가 있는 노이즈 예제를 찾고 제거한다
- 라벨 오류가 제거된 데이터로 학습하고, 추정된 잠재 사전 분포(estimated latent prior)로 예제에 가중치를 다시 부여(re-weightning)한다
Confident Learning의 이점
대부분의 머신러닝 접근법과 달리, Confident Learning은 하이퍼파라미터가 필요하지 않다. 우리는 교차검증(cross-validation)을 사용하여 out-of-sample 예측 확률을 얻는다. CL의 다른 여러 이점은 다음과 같다:
- 노이즈가 있는 라벨과 참 라벨 간의 결합 분포를 직접 추정
- 다중 클래스 데이터셋에서 작동
- 라벨 오류를 찾아낸다 (오류는 가장 가능성 높은 것부터 낮은 것까지 정렬)
- 반복적이지 않다 (예: ImageNet의 훈련 라벨 오류를 찾는 데 3분 소요)
- 이론적으로 합당하다 (현실적인 조건에서 라벨 오류를 정확하게 찾고 결합 분포를 일관되게 추정)
- 무작위로 균일한 라벨 노이즈를 가정하지 않는다 (실제에서는 종종 비현실적)
- 예측 확률과 노이즈가 있는 라벨만 필요 (어떤 모델이든 사용할 수 있음)
- 참 라벨(손상되지 않은 라벨)이 필요하지 않다
- 다중 라벨 데이터셋으로 자연스럽게 확장
- 라벨 오류를 특성화, 발견 및 학습하기 위한 Python 패키지인 cleanlab이 무료로 오픈 소스화되어있다
Confident Learning의 원칙
CL은 노이즈가 있는 라벨을 다루는 문헌에서 개발된 원칙을 기반으로 한다:
- Prune(제거): Natarajan et al. (2013); van Rooyen et al. (2015); Patrini et al. (2017)의 예시를 따라, 반복적인 re-labeling의 수렴 문제를 피하기 위해 loss-reweighting을 통한 soft-pruning을 사용하여 라벨 오류를 탐색한다
- Count(카운팅): loss-reweighting으로 학습된 모델 가중치의 오차의 전파(error-propagation)를 피하기 위해 깨끗한 데이터(clean data)로 학습한다 (Natarajan et al., 2017). 이는 Forman (2005, 2008); Lipton et al. (2018)에서의 작업을 일반화한다
- Rank(순위화): 정규화되지 않은 확률(unnormalized probabilities)이나 SVM 결정 경계 거리(SVM decision boundary distances)를 사용하여 어떤 예제를 훈련에 사용할지 순위화한다. 이는 PageRank (Page et al., 1997)에서 잘 알려진 robustness findings과 MentorNet (Jiang et al., 2018)의 curriculum learning 아이디어를 기반으로 한다.
Confident Learning의 이론적 발견
CL 알고리즘, 이론 및 증명의 전체 내용을 다루려면 본 논문을 읽어보길 권장한다. 주요 아이디어를 요약하면:
이론적으로, CL이 라벨 오류를 정확하게 찾고, 노이즈가 있는 라벨과 참 라벨의 결합 분포를 일관되게 추정하는 현실적인 조건을 보여준다 (Theorem 2: General Per-Example Robustness). 이 조건은 각 예제와 각 클래스에 대한 예측 확률의 오류를 허용한다
Confident Learning은 어떻게 작동하는가?
CL이 어떻게 작동하는지 이해하려면, 개, 여우, 소의 이미지가 있는 데이터셋이 있다고 가정해보자. CL은 노이즈가 있는 라벨과 참 라벨의 결합 분포(아래 그림의 오른쪽에 있는 행렬)를 추정함으로써 작동한다
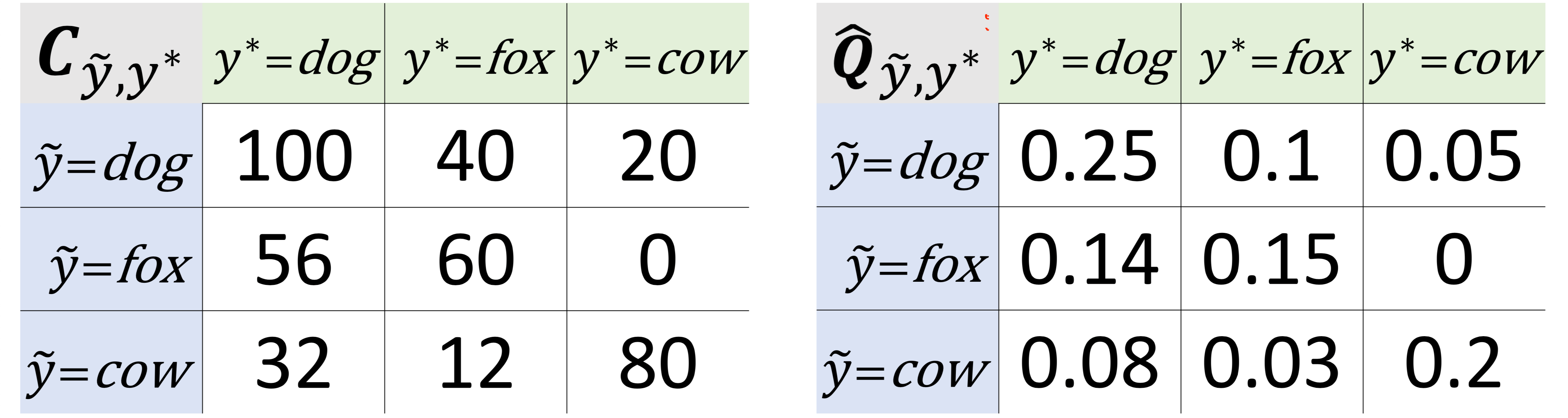
왼쪽: Confident Counting 예제. 이는 결합 분포의 정규화되지 않은 추정치
오른쪽: 세 개의 클래스를 가진 데이터셋에 대한 노이즈가 있는 레이블과 참 레이블의 결합 분포 예시
예제를 계속해서 살펴보면, CL은 class dog에 속할 확률이 높은 dog 라벨의 이미지 100장을 카운팅한다(위 그림의 왼쪽 행렬). 또한, class dog에 속할 확률이 높은 fox 라벨의 이미지 56장과 cow 라벨의 이미지 32장을 카운팅한다
수학적으로 호기심이 있는 사람들을 위해, 이 카운팅 프로세스는 다음과 같은 형태를 취한다:
여기서:
- : 노이즈가 있는(관찰된) 라벨
- : 참 라벨(관찰할 수 없음)
- : 노이즈가 있는 라벨 로 레이블된 예제 중에서, 참 라벨이 라고 확신(confident)하는 예제의 수
- : 모델 를 사용하여 예제 가 class 에 속할 확률의 예측치
- : 클래스 에 대한 임곗값(threshold)
CL의 중심 아이디어는 예측 확률이 클래스별 임곗값보다 클 때, 해당 예제가 실제로 그 클래스에 속한다고 확신(confident)하고 카운팅한다는 것이다. 각 클래스의 임곗값은 해당 클래스의 예제에서의 예측 확률의 평균이다. 이러한 임곗값 설정은 PU Learning (Elkan & Noto, 2008)에서의 well-known robustness results를 다중 클래스 약한 지도 학습(multi-class weak supervision)으로 일반화한다
라벨 오류를 찾기 위한 라벨 노이즈의 결합 분포 사용
위 그림의 오른쪽 행렬( 행렬)에서, 라벨 이슈를 추정하기 위해 다음을 수행한다:
- 결합 분포 행렬에 예제 수를 곱한다. 데이터셋에 100개의 예제가 있다고 가정하자. 따라서 위 그림( 행렬)에 따르면, 실제로는 여우 이미지인데 dog로 레이블된 이미지가 10장 있다
- clss fox에 속할 확률이 가장 높은 dog 레이블의 이미지 10장을 라벨 이슈로 표시한다
- 행렬의 비대각선 항목에 대해 이 과정을 반복한다
참고: 이는 논문에서 사용된 방법을 단순화한 것이지만, 핵심을 담고 있다.
Confident Learning의 실제 응용
노이즈가 있는 라벨로 학습할 때 SOTA(State-Of-The-Art)를 평균적으로 10% 이상, 그리고 노이즈가 많고 데이터가 희소한 환경에서는 30% 이상 성능 향상을 보여준다
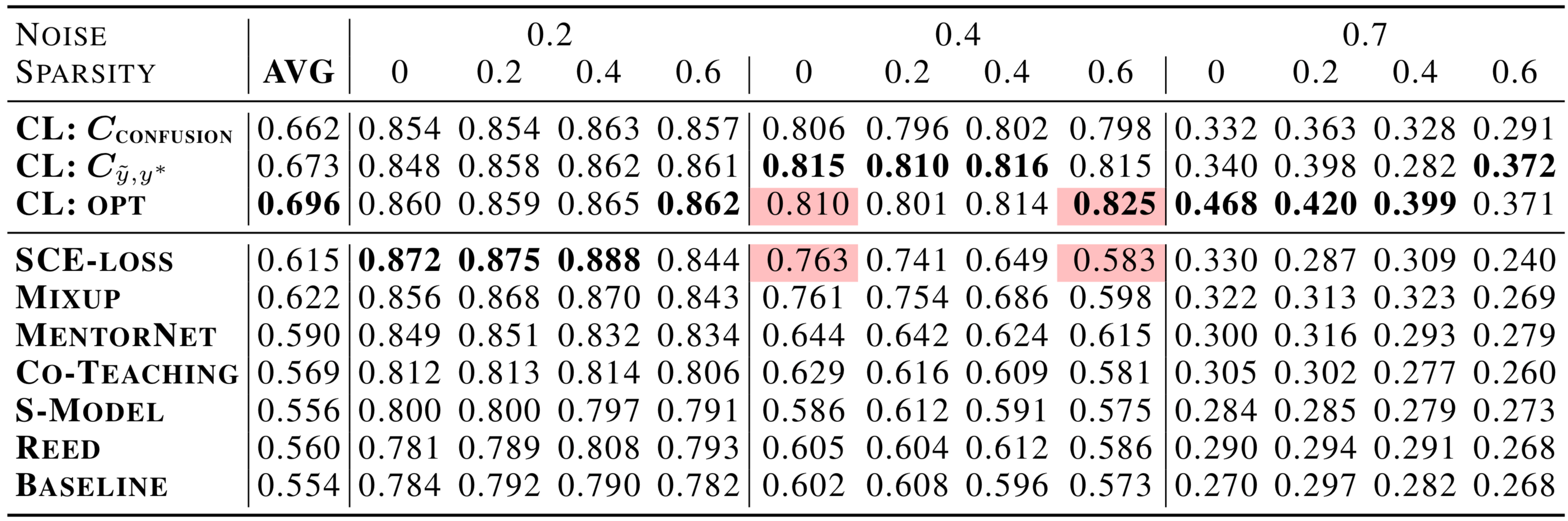
위 표는 CIFAR-10에서 노이즈가 있는 레이블로 다중 클래스 학습을 위한 최신 방법들과 CL의 성능을 비교한 것이다.
높은 희소성(high sparsity, 다음 단락에서 설명)과 40%, 70%의 라벨 노이즈에서, CL은 Google의 MentorNet, Co-Teaching, Facebook Research의 Mix-up을 30% 이상 능가한다. Confident Learning 이전에는 이 벤치마크에서의 개선은 몇 퍼센트 포인트 정도로 상당히 작았다.
희소성(sparsity)은 에서 0의 비율을 나타내며, ImageNet과 같은 실제 데이터셋에서는 한 class가 다른 class로 잘못 라벨링될 가능성이 낮다는 개념을 내포한다(예: ). 위 표에서 강조 표시된 셀에서 볼 수 있듯이, CL은 Mixup, MentorNet, SCE-loss, Co-Teaching과 같은 최신 방법에 비해 희소성에 대한 견고성이 크게 향상되었다. 이러한 견고성은 노이즈가 있는 라벨과 참 라벨의 결합 분포 를 직접 모델링함으로써 얻어진다
Confident Learning으로 정제된 ImageNet으로 ResNet 테스트 정확도 향상
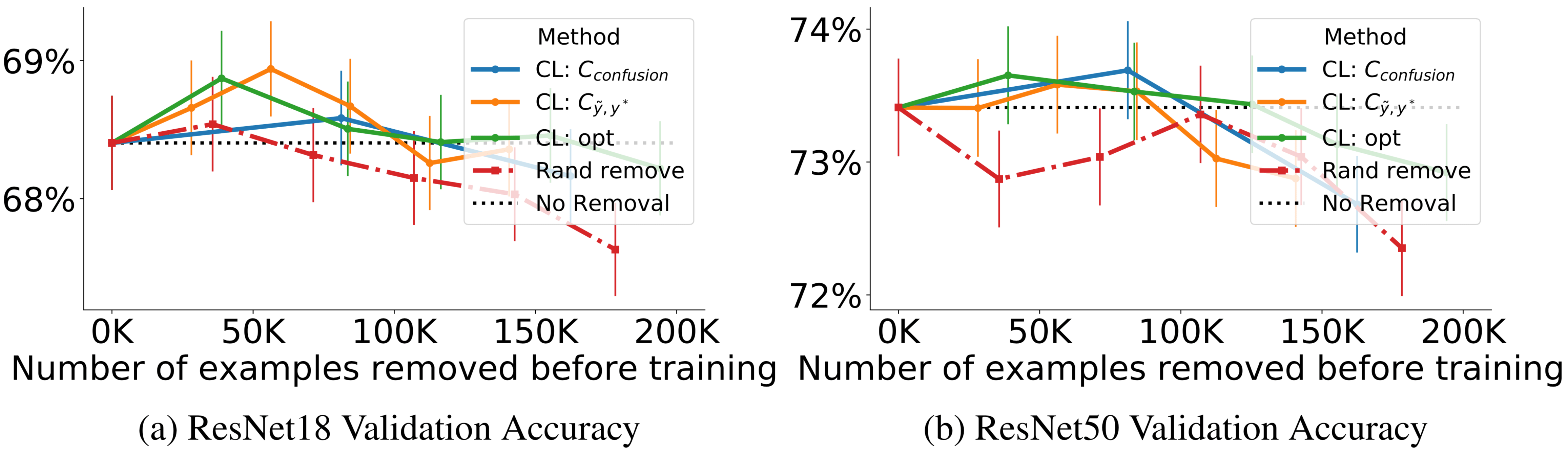
위 그림에서 각 방법에 대한 선의 각 점은 왼쪽에서 오른쪽으로 제거된 레이블 오류의 비율(20%, 40%, …, 100%)에 따른 정확도를 나타낸다
검은 점선은 모든 예제를 사용하여 훈련할 때의 정확도를 나타낸다. Confident Learning을 사용하여 정제된 ImageNet 훈련 세트로 훈련할 때, 100,000개 미만의 훈련 예제가 제거되었을 때 ResNet 검증 정확도가 향상됨을 관찰할 수 있다. 100,000개 이상의 훈련 예제가 제거되면, 빨간색 점선으로 표시된 무작위 제거에 비해 CL을 사용한 상대적인 개선을 볼 수 있다.
추가된 레이블 노이즈가 있는 CIFAR에서의 레이블 노이즈의 좋은 특성화

위 그림은 CIFAR에 40%의 라벨 노이즈를 추가한 후 CL이 레이블 노이즈의 결합 분포를 추정한 결과를 보여준다.
(a)는 실제 결합 분포(true distribution), (b)는 CL의 추정치(CL estimate), (c)는 두 행렬의 절대적인 차이(the low error of the absolute difference of every entry in the matrix)를 나타낸다. 각 요소는 확률에 100을 곱한 값이다. CL의 추정치가 실제 분포와 얼마나 가까운지, 그리고 행렬의 각 항목에서의 오차가 얼마나 작은지 관찰할 수 있다.
ImageNet에서의 온톨로지(클래스 명명) 문제의 자동 발견

CL이 온톨로지 문제를 발견하는 과정
- Confident Learning(CL)은 라벨 노이즈의 결합 분포(joint distribution)를 직접 추정해서, 데이터셋에 있는 클래스들 간의 온톨로지 문제를 자동으로 찾아낸다.
- 이런 온톨로지 문제는 주로 라벨링 오류나 클래스 간 관계에서 발생하는데, CL을 통해 잘못된 라벨과 정확한 라벨을 명확히 구분할 수 있다.
ImageNet 데이터셋에서의 라벨 노이즈 추정
- 위 표는 CL(Confident Learning)을 사용해서 ImageNet 데이터셋에서 라벨 노이즈와 실제 라벨 간의 차이를 분석한 결과를 보여준다.
- ImageNet은 단일 클래스(single-class) 데이터셋으로, 각 이미지에는 하나의 라벨만 부여되어 있다.
- CL은 이 데이터셋에서 잘못된 라벨(노이즈)과 정확한 라벨 간의 차이를 찾아낸다.
- 오프 대각선 값(off-diagonals)은 잘못된 라벨과 정확한 라벨이 서로 다를 때 나타나는 값이다. 이 값들을 통해 CL은 라벨링 오류가 발생한 지점을 정확히 찾아낼 수 있다.
특정 사례
- 7번째 행 - maillot: 동음이의어 문제
- 'maillot'라는 단어가 서로 다른 두 개의 클래스를 나타내는 문제. 동일한 이름이 서로 다른 두 클래스로 사용되어 혼동을 일으킴.
- 1번째 행 - projectile vs. missile: 잘못된 명칭 문제 (misnomer)
- 'projectile'과 'missile'은 다른 개념이지만, 데이터셋에서 잘못된 명칭이 사용되어 혼동이 발생한 문제. 두 개념이 명확히 구분되어야 함.
- 2번째 행 - bathtub vs. tub: 'is-a' 관계 오류
- 'bathtub(욕조)'는 'tub(통)'의 하위 개념인데, 더 구체적인 개념이 일반적인 개념으로 잘못 라벨링된 문제.
- 9번째 행 - corn vs. ear: 다의어 문제
- 'corn'과 'ear'는 한 단어가 여러 가지 의미로 사용될 수 있는데, 이를 구분하지 않고 혼동해서 라벨링된 문제.
- 'corn'과 'ear'는 한 단어가 여러 가지 의미로 사용될 수 있는데, 이를 구분하지 않고 혼동해서 라벨링된 문제.
Resources
- 이 강의는 논문 “Confident Learning: Estimating Uncertainty in Dataset Labels” (JAIR 2021)를 개괄한다
- 또한 논문 “Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks” (NeurIPS 2021)를 다룬다
- 이 방법을 ML에서 가장 많이 인용되는 10개의 테스트 세트에 적용한 결과는 labelerrors.com에서 확인할 수 있다
- cleanlab 패키지는 데이터셋을 개선하여 ML 모델을 향상시키는 데이터 중심 AI 패키지로, 노이즈가 있는 라벨(labels), 이상치(outliers), 여러 사람이 라벨링한 데이터를 사용한 훈련 등을 지원한다. 자세한 내용은 cleanlab 문서를 참조. cleanlab과 confidentlearning-reproduce 레포지토리는 CL 논문의 결과를 재현한다
References
- Lecture (ver.2024): https://dcai.csail.mit.edu/2024
- Lab: Label Errors (ipynb)
- Lecture (ver.2023): https://dcai.csail.mit.edu/2023
- Lab Session (ver.2023): https://github.com/dcai-course
- P.S. 본 포스팅 작성에는 OpenAI의 GPT-4o와 o1-preview가 활용되었습니다
