[DCAI] Special Topic 2. Interpretability in Data-Centric ML

Introduction to Interpretable ML
해석 가능성(Interpretability)이란 머신러닝 모델의 결정 과정이나 원리를 인간이 이해할 수 있는 정도를 의미한다. 이는 모델의 성능만큼 중요한 요소로, 여러 가지 이유로 필수적이다.
해석 가능성이 중요한 이유
- 모델 디버깅 및 검증: 모델의 성능을 개선하고, 실제 환경에서 올바르게 작동하는지 확인하는 데 필수적
- 잘못된 결정 검토: 배포 후 발생하는 잘못된 결정의 원인을 분석하고 수정하기 위해 필요
- 사용성 개선: 의사 결정자가 모델을 더 쉽게 이해하고 사용할 수 있도록 하기 위함
왜 해석 가능한 특징(interpretable features)에 주목해야 하는가?
다음은 캘리포니아 주택 데이터셋(California Housing Dataset)을 사용하여 주택 가격을 예측하는 예시이다. 이 데이터셋은 각 행이 캘리포니아의 특정 블록에 있는 주택들을 나타내며, 목표는 주택들의 중간 가격(median house price)을 예측하는 것이다.
아래 이미지는 이 목표를 위해 훈련된 결정 트리 모델(decision tree model)을 시각화한 것이다. 일반적으로 결정 트리는 매우 해석 가능한 모델로 여겨지는데, 그 이유는 예/아니오 형태의 질문을 통해 의사결정 경로를 직관적으로 이해할 수 있기 때문이다. 하지만 이 시각화는 주택 가격에 대한 모델의 예측 방식을 충분히 설명해줄까?
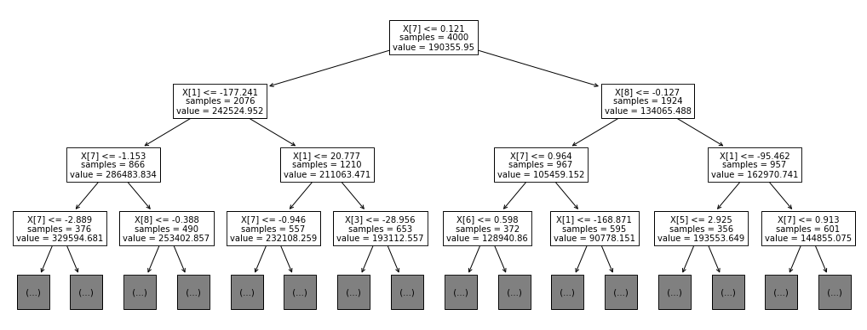
위의 결정 트리 시각화는 원래 특징 집합에 주성분 분석(PCA, principal component analysis)을 적용한 후 생성된 특징들을 사용한다. PCA는 차원 축소 기법으로, 모델의 일반화 능력을 향상시킬 수 있지만, 특징들의 해석 가능성을 크게 감소시킨다.
다음으로, 캘리포니아 주택 데이터셋을 사용한 모델의 특징 중요도(feature importance)를 비교하는 두 개의 이미지를 살펴보자. 첫 번째 모델은 자동 생성된 특징들로 훈련되었고, 두 번째 모델은 데이터셋의 기본 특징을 사용한 것이다. 두 모델의 성능은 비슷하며, 성능 지표는 로 나타난다. 그러나 두 번째 모델이 훨씬 더 해석 가능성이 높은 설명을 제공한다.
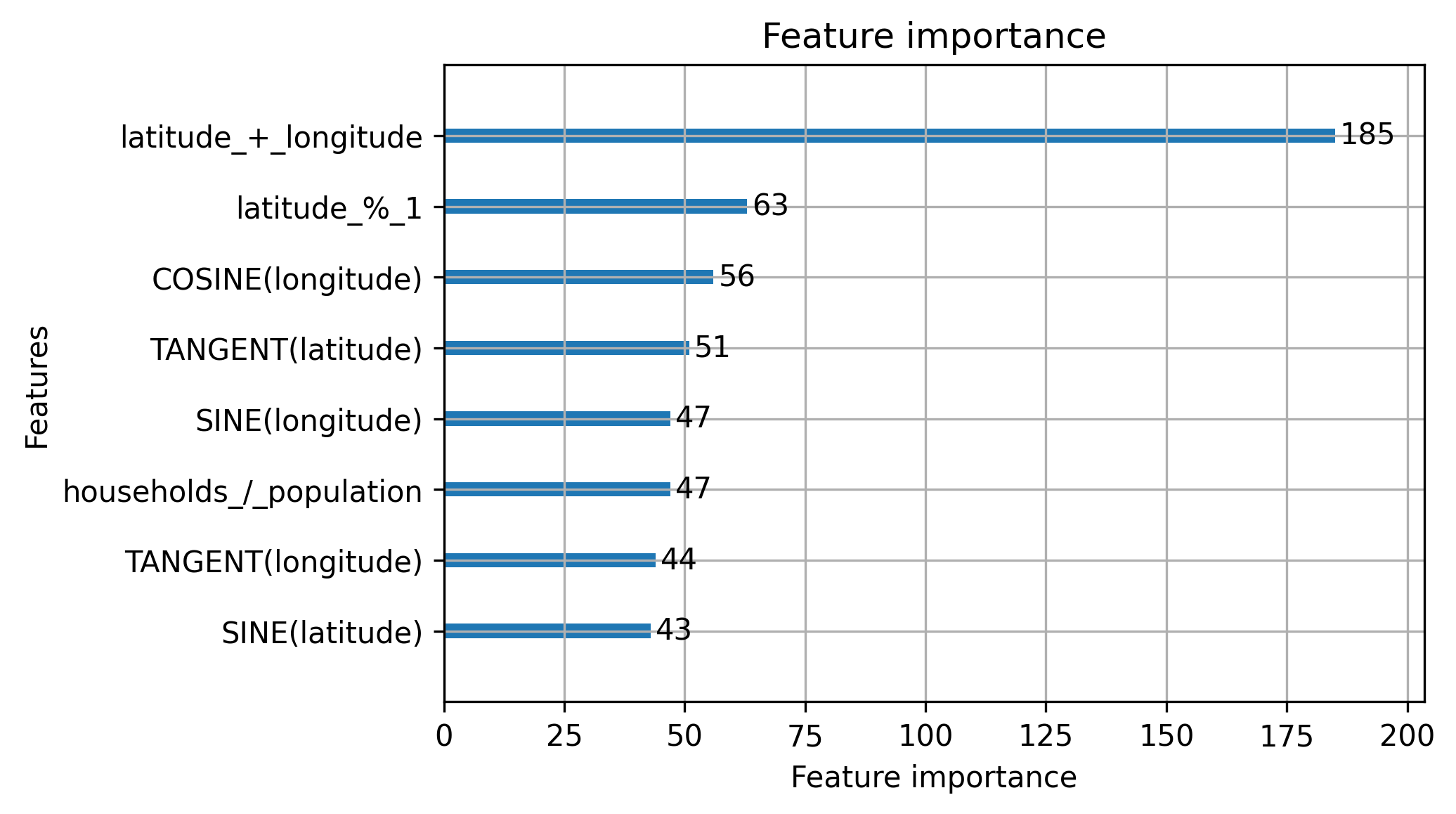
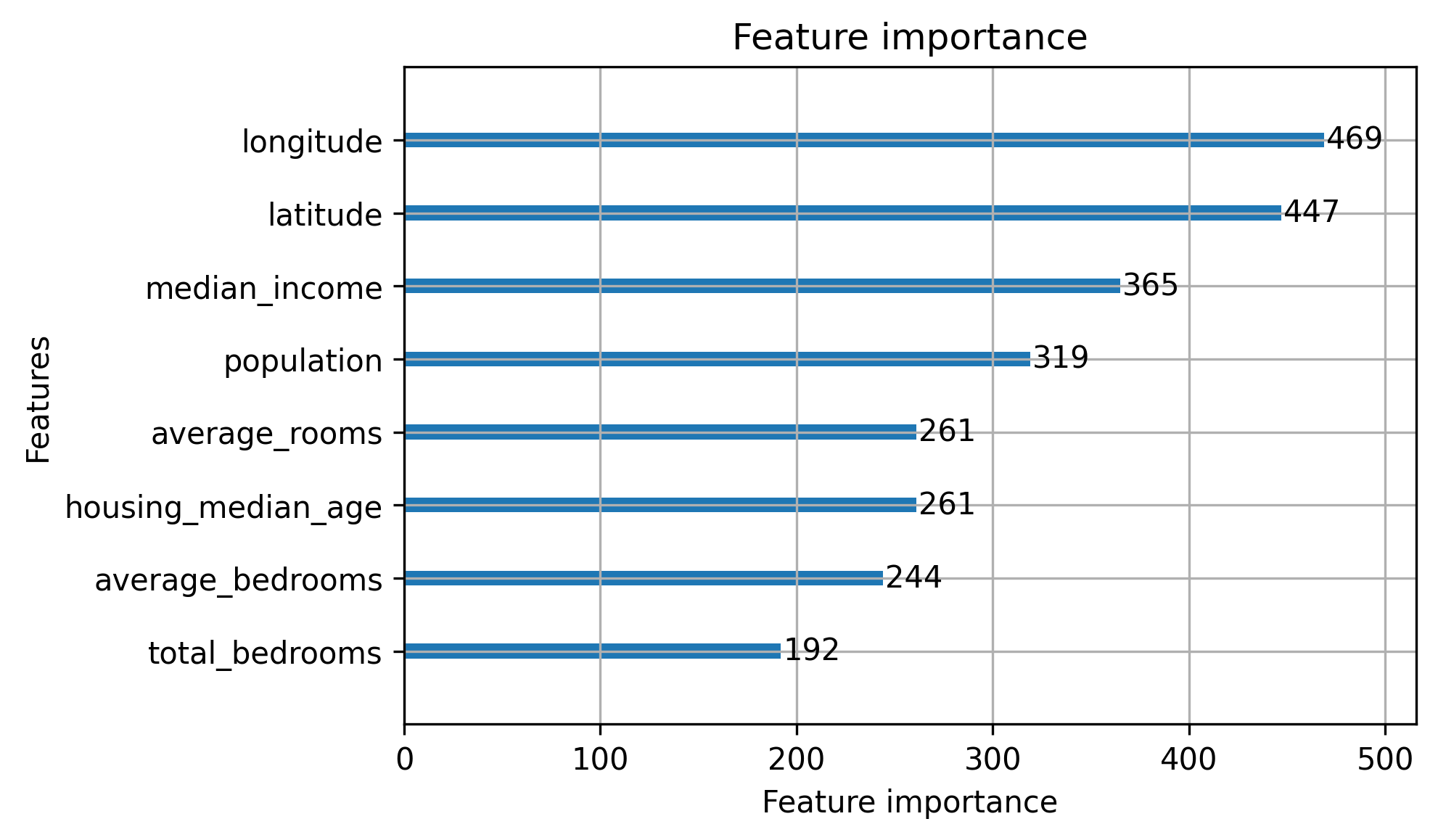
성능과 해석 가능성(Performance and Interpretability)
흔히 '성능/해석 가능성 트레이드오프'라는 개념을 들어본 적이 있을 것이다. 이는 해석 가능성을 높이기 위해 특징들을 수정하면 모델의 성능이 떨어질 수 있다는 생각이다. 이론적으로 이는 타당한 가정인데, 특징 공간에 더 많은 제약을 추가하면 모델의 표현력이 줄어들어 성능이 저하될 수 있기 때문이다.
그러나 현실적으로는 무한한 자원이나 데이터를 사용하지 못하기 때문에 모든 가능한 데이터 구성을 실험할 수 없다. 실제 사례에서는 특징과 모델에 해석 가능성을 추가하는 것이 다음과 같은 이점으로 이어지는 경우가 많다:
- 더 효율적인 훈련: 해석 가능한 특징은 모델이 목표와 관련된 중요한 정보만 학습하도록 유도한다.
- 더 나은 일반화: 해석 가능한 모델은 불필요한 복잡성을 줄여 일반화 성능을 높일 수 있다.
- 적은 적대적 예제(adversarial examples): 해석 가능한 모델은 적대적 예제에 대해 더 강건한 경향이 있다 (Rudin, 2018; Ilyas et al., 2019).
즉, 해석 가능한 특징을 사용하면 모델이 우리가 목표와 관련이 있다고 알고 있는 정보를 학습하게 하여, 모델이 우연한 상관관계(spurious correlations)를 학습할 가능성을 줄여준다.
만약 성능과 해석 가능성 간의 트레이드오프를 경험하게 된다면, 이는 해당 도메인에서 성능과 해석 가능성 중 어느 것이 더 중요한지를 고려해야 함을 의미한다. 이 상대적 중요성은 각 도메인과 문제에 따라 달라질 수 있다.
해석 가능한 특징이란 무엇인가?
해석 가능한 특징은 사용자가 이해하고 해석하기 쉬운 특징을 의미한다. 그러나 이는 단순히 이해하기 쉽다는 것 이상의 의미를 내포하고 있으며, 특정 도메인과 사용자에 따라 그 중요성과 정의가 달라질 수 있다.
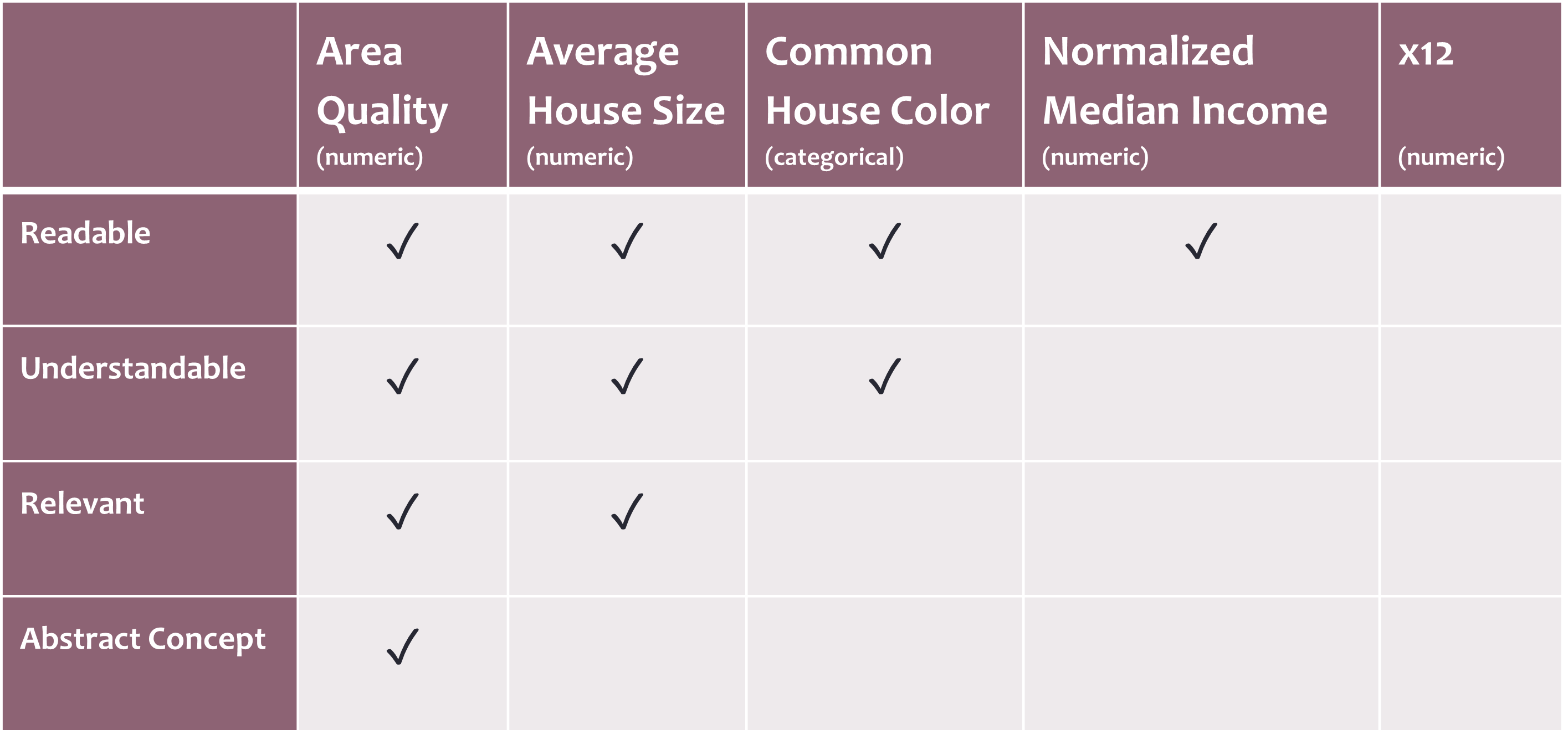
특징의 해석 가능성을 높이는 몇 가지 핵심 속성은 다음과 같다(Zytek et al., 2022):
- 가독성(Readability): 사용자가 해당 특징이 무엇을 의미하는지 쉽게 이해할 수 있는가? 예를 들어, X1과 같은 코드명보다는 자연어 설명으로 대체하는 것이 가독성을 높인다.
- 이해 가능성(Understandability): 사용자가 해당 값에 대해 직관적으로 생각할 수 있는가? 표준화된 값보다는 실제 세계에서 사용하는 값이 더 이해하기 쉽다. 예를 들어, $50,000의 수입을 생각하는 것이 0.67과 같은 정규화된 지표를 이해하는 것보다 직관적이다.
- 의미/관련성(Meaningfulness/Relevancy): 사용자가 중요한 정보라고 인식하는 특징을 모델이 사용하고 있는가? 이런 특징은 사용자가 모델을 더 신뢰하고 사용할 가능성을 높인다.
- 추상적 개념(Abstract Concepts): 경우에 따라, 특정 정보를 소화하기 쉬운 추상적 개념으로 압축하는 것이 유용할 수 있다. 예를 들어, '지역에 대한 상세 정보'를 "주변 환경의 질"이라는 단일 지표로 결합할 수 있다. 하지만 이는 중요한 정보를 숨길 위험도 있다.
아래 표는 특징들과 그 속성들의 예시를 보여준다.
해석 가능한 특징을 얻는 방법
특성 엔지니어링(Feature engineering)은 모델이 없더라도 해석 가능한 모델을 구축하기 위한 첫 번째 단계이다(Hong et al., 2020).
해석 가능한 특성을 생성하는 주요 접근법은 다음 세 가지로 나뉜다:
- 사용자 참여: 특성 생성 과정에 사용자를 포함시키는 방법.
- 설명 변환: 데이터 변환과 별개로 설명을 변환하여 해석 가능한 설명을 만드는 방법.
- 자동화된 해석 가능 특성 생성: 해석 가능성을 고려하는 자동화된 특성 생성 알고리즘을 사용하는 방법.
사용자의 포함(Including the User)
디자인 작업에서 사용자는 반복적인 피드백을 통해 개선을 이루는 방식으로 자주 포함된다. 이러한 반복적 디자인 프로세스(iterative design process)는 특성 엔지니어링(feature engineering)에도 적용될 수 있다. 즉, 특성 엔지니어링 과정의 모든 단계에 사용자를 참여시키고, 그들의 피드백에 따라 수정하는 방식이다.
특성 엔지니어링에 사용자를 효과적으로 포함시키기 위한 여러 방법이 존재하는데, 그중 하나가 협업적 특성 엔지니어링(collaborative feature engineering) 시스템이다. 이 시스템은 여러 사용자가 특성 생성 과정에서 손쉽게 협력할 수 있도록 돕는다. 여기서는 두 가지 대표적인 시스템인 Flock과 Ballet을 소개한다.
Flock: 사용자 참여를 통한 자연어 설명 기반 특성 생성
Flock은 사람들이 비교와 대조를 통해 중요한 특성을 더 쉽게 강조할 수 있도록 설계된 시스템이다. 이 시스템은 다음과 같은 과정을 통해 사용자로부터 얻은 설명을 바탕으로 해석 가능한 특성을 생성한다:
- 비교 예시 제시: 사용자에게 서로 다른 두 예시를 제시하고, 각 예시를 분류하도록 요청한다.
- 분류 이유 설명: 사용자는 자신이 왜 그렇게 분류했는지를 자연어로 설명한다.
- 설명 구문화 및 클러스터링: 설명에서 접속사(예: 그리고/또는)와 구두점을 기준으로 구문을 분할한 후, 이를 클러스터링하여 주요 구문을 추출한다.
- 대표 질문 생성: 클러스터링된 구문을 바탕으로, 각 클러스터를 대표하는 질문을 작성하도록 사용자에게 요청한다.
예를 들어, 스타일이 유사한 두 예술가 모네(Monet)와 시슬리(Sisley)의 그림을 구분하는 작업을 생각해보자.
-
그림 제시: 모네와 시슬리의 그림을 한 장씩 사용자에게 보여주고, 누가 그린 것인지 추정하도록 한다.

-
분류 및 설명 요청: 사용자에게 분류 선택 이유를 자연어로 설명하도록 요청한다.
The first painting is probably a Monet because it has lilies in it, and looks like Monet’s style. The second probably isn’t Monet because Monet doesn’t normally put people in his paintings.
첫 번째 그림은 아마도 모네의 작품일 것입니다. 왜냐하면 수련이 있고, 모네의 스타일처럼 보이기 때문입니다. 두 번째 그림은 아마도 모네의 작품이 아닐 것입니다. 왜냐하면 모네는 보통 그의 그림에 사람들을 그리지 않기 때문입니다.
- 설명 분할 및 클러스터링: 접속사(그리고/또는)와 마침표(punctuation)에서 설명을 분할하고, 결과 구문을 클러스터링한다.
The first painting is probably a Monet because it has lilies in it
첫 번째 그림은 아마도 모네의 작품일 것입니다. 왜냐하면 수련이 있기 때문입니다.
It has flowers
꽃이 있다.
The painting includes lilies
그림에 수련이 있다.
There are flowers and lilies in the painting
그림에 꽃과 수련이 있다.
- 대표 질문 생성: 사용자들에게 클러스터를 보여주고, 해당 클러스터를 대표하는 단일 질문을 작성하도록 요청한다.
Does the painting have flowers/lilies in it?
그림에 꽃/수련이 있습니까?
이러한 질문들은 사용자가 직접 제공한 정보를 바탕으로 하기 때문에 매우 해석 가능한 군중 생성 특징을 만들어낸다.
Flock 시스템이 생성한 이러한 특징들은 raw data를 사용하는 것, 기계가 생성한 특징을 사용하는 것, 그리고 인간의 분류만을 사용하는 것과 비교했을 때 성능을 향상시키는 결과를 보였다.
Ballet (Smith et al., 2020)
Ballet은 협업적 특성 엔지니어링 시스템으로, 사용자가 특성 엔지니어링 작업에만 집중할 수 있도록 대부분의 머신러닝 훈련 파이프라인을 추상화한다. Ballet을 활용하면 사용자는 데이터셋에서 특성을 생성하기 위해 필요한 최소한의 파이썬 코드를 작성할 수 있으며, 이렇게 생성된 특성은 특성 엔지니어링 파이프라인에 통합되어 평가된다. 이 과정을 통해 보다 쉽게 특성을 생성하고 검증할 수 있는 환경을 제공한다.
설명 변환(Explanation Transforms)
모델이 해석 가능하지 않은 변환을 요구하는 경우(예: 표준화, 원-핫 인코딩, 결측치 대치)에도 해석 가능한 설명을 유지할 수 있는 방법이 있다. Pyreal은 이러한 해석 불가능한 변환을 처리한 후, 설명 자체에 후처리 변환을 적용하여 해석 가능성을 복구하는 도구이다.
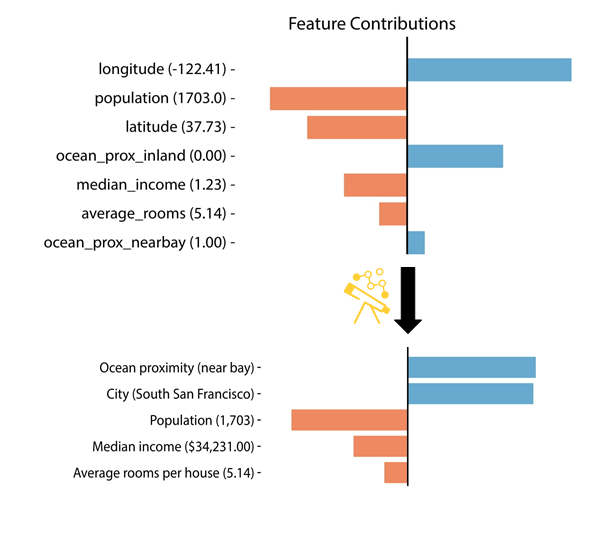
Pyreal은 데이터 변환 후 자동으로 "원상 복구"하여 설명의 해석 가능성을 향상시키는 추가 변환을 적용한다. 예를 들어, 아래 이미지는 Pyreal을 통해 변환 전후의 설명을 비교한 것이다.
- 변환 전: 원-핫 인코딩된 ocean proximity와 표준화된 median income 등의 특징들이 해석하기 어려운 상태.
- 변환 후: ocean proximity는 단일 범주형 특징으로 결합되고, median income은 역표준화되어 실제 값으로 변환되며, 위도/경도 좌표는 특정 도시 이름으로 변환되어 훨씬 더 해석 가능한 형태가 된다.
이러한 변환 과정을 통해 설명을 직관적이고 이해하기 쉬운 방식으로 변환할 수 있다.
해석 가능한 특징 생성(Interpretable Feature Generation)
일부 자동화된 특성 엔지니어링 알고리즘은 특히 해석 가능한 특성을 생성하는 데 중점을 둔다. 이러한 알고리즘은 주로 대조적(contrastive) 정보를 기반으로 하여, 클래스 간의 차이를 명확히 구분하거나, 분석하기 더 쉬운 부분집합으로 특성 수를 줄이는 데 목적을 둔다.
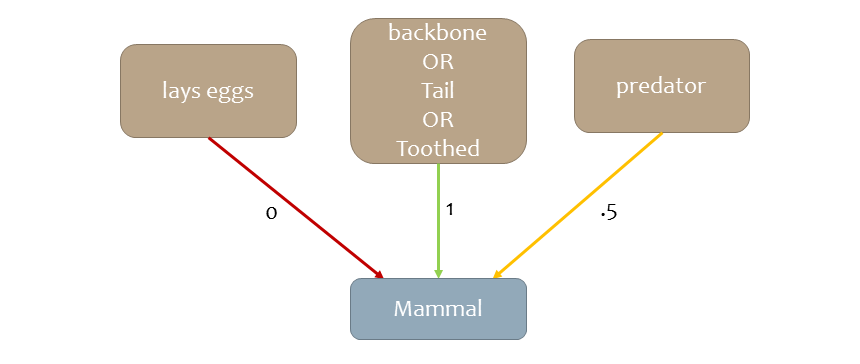
그 중 하나의 예시가 Mind the Gap (MTG) 알고리즘이다(Kim et al., 2015). MTG는 부울(Boolean) 특성 집합을 더 작고 해석 가능한 부분집합으로 축소하는 것을 목표로 한다.
MTG 알고리즘: 부울 특징 집합 축소
MTG 알고리즘은 다음과 같은 단계로 작동한다:
- 특성 그룹 생성: 여러 특성을 무작위로 그룹화한 후, 이를 "AND" 또는 "OR" 연산자로 결합하여 하나 이상의 특성을 포함하는 특성 그룹을 생성한다.
- 갭(gap) 계산: 각 특성 그룹에 대해, 참(True)과 거짓(False) 인스턴스 사이의 갭(gap)을 계산한다. 이는 특성 그룹이 클래스 간 구분을 얼마나 잘 해내는지를 나타내는 중요한 지표이다.
- 최대 갭 선택: 갭이 가장 큰 특성 그룹을 선택하고, 이를 계속 반복하여 클래스를 최대한 분리할 수 있는 작은 특성 집합을 찾아낸다.
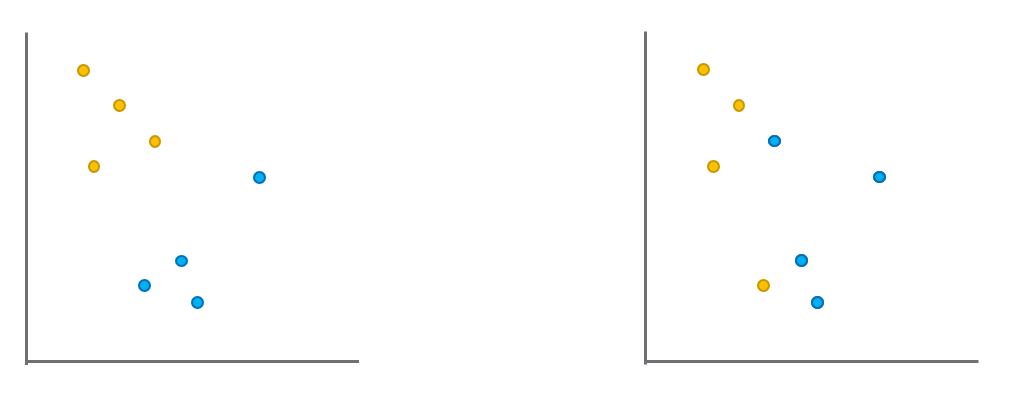
아래 이미지는 특성 그룹 간 갭을 시각적으로 보여준다. 노란색과 파란색 점은 각각 참과 거짓 인스턴스를 나타낸다. 왼쪽 특성 그룹의 갭이 오른쪽 특성 그룹보다 더 크기 때문에, 왼쪽 특성 그룹이 선택된다.
이 과정을 반복함으로써, MTG 알고리즘은 클래스 간 차이를 극대화하는 해석 가능한 작은 특성 집합을 생성한다.
다음은 MTG를 사용하여 생성할 수 있는 특성 그룹의 예시이다. 이 예시에서 각 그룹의 특정 값은 "포유류"와 같은 클래스를 설명할 수 있는 중요한 특성으로 작동한다. 이러한 특성 그룹은 클래스 간 차이를 잘 드러내면서도 해석 가능한 형태로 구성된다.
Conclusion
이 강의의 핵심 내용을 요약하면 다음과 같다:
- 머신러닝에서 해석 가능성이 중요한 경우, 특성의 해석 가능성 또한 매우 중요하다.
- 해석 가능한 특성은 사용자가 이해하고 의미 있게 받아들일 수 있을 때 더욱 효과적이다. 하지만 다른 사용자들은 각기 다른 요구와 관점을 가질 수 있다는 점을 염두에 두어야 한다.
- 해석 가능한 특성을 생성하기 위해서는 사용자(이상적으로는 최종 사용자)를 특성 생성 과정에 포함시키는 것이 중요하다. 또한, 설명 변환을 적용하거나 해석 가능성을 고려한 자동화된 알고리즘을 사용하여 특성을 생성할 수 있다.
References
- Lecture (ver.2024): https://dcai.csail.mit.edu/2024
- Lecture (ver.2023): https://dcai.csail.mit.edu/2023
- Lab Session (ver.2023): https://github.com/dcai-course
- P.S. 본 포스팅 작성에는 OpenAI의 GPT-4o와 o1-preview가 활용되었습니다
