[DCAI] Special Topic 1. Growing or Compressing Datasets

데이터셋의 확장과 압축
머신러닝 시스템을 구축할 때, 인간이 주석을 다는 지도 학습 데이터는 라벨링 과정이 시간 소모적이고 비용이 많이 든다. 이 강의에서는 현대 머신러닝 시스템을 만들 때 라벨링 부담을 줄이고 어떤 예제를 라벨링할지 더 신중하게 선택하는 방법에 대해 집중적으로 다룬다. 구체적으로 다음과 같은 접근법을 살펴본다:
- 액티브 러닝(active learning): 데이터를 지능적으로 선택하여 데이터셋을 확장하는 방법
- 코어셋 선택(core-set selection): 대표적인 부분집합(subset)으로 데이터셋을 압축하는 방법
이 글에서는 주로 분류 작업을 다루지만, 여기서 설명하는 원칙은 회귀, 이미지 세분화, 엔티티 인식 등 다른 지도 학습 작업과 일부 비지도 학습 작업(예: 요약)에도 적용 가능하다.
액티브 러닝(Active Learning)
액티브 러닝의 주요 목표는 모델 성능을 가장 크게 향상시킬 수 있는 데이터 샘플을 선택하여 라벨링하는 것이다. 즉, 모델이 현재 학습하지 못한 중요한 정보가 포함된 데이터를 선별적으로 라벨링하여, 라벨링해야 할 데이터 양을 크게 줄이면서도 모델 성능을 극대화할 수 있다.
액티브 러닝의 작동 원리
액티브 러닝에서 우리는 다음과 같은 구조를 사용하여 라벨링할 데이터를 선택한다:
- 입력 : 이미지, 텍스트 등 데이터 포인트 자체
- 특징 값(feature value): 입력 데이터의 속성
(예: 이미지의 픽셀 값, 텍스트의 단어 벡터 등)- 모델 : 신경망 분류기 또는 기타 지도 학습 모델
- 모델 출력 : 입력 데이터 에 대한 예측 결과(예: 클래스 확률)
예를 들어, 이미지 분류 작업에서 데이터 포인트 는 이미지, 특징 값은 픽셀 강도, 모델 는 신경망 분류기(neural network classifier)가 될 수 있다. 모델 출력은 입력 이미지가 각 클래스에 속할 확률 벡터 로 주어진다.
액티브 러닝은 반복적인 과정으로, 현재까지 라벨링된 데이터로 훈련된 모델 의 출력을 바탕으로 다음에 어떤 데이터를 라벨링할지 결정한다. 이를 통해 선택적으로 라벨링된 데이터로 모델을 재학습하면서, 점진적으로 성능을 향상시킨다.
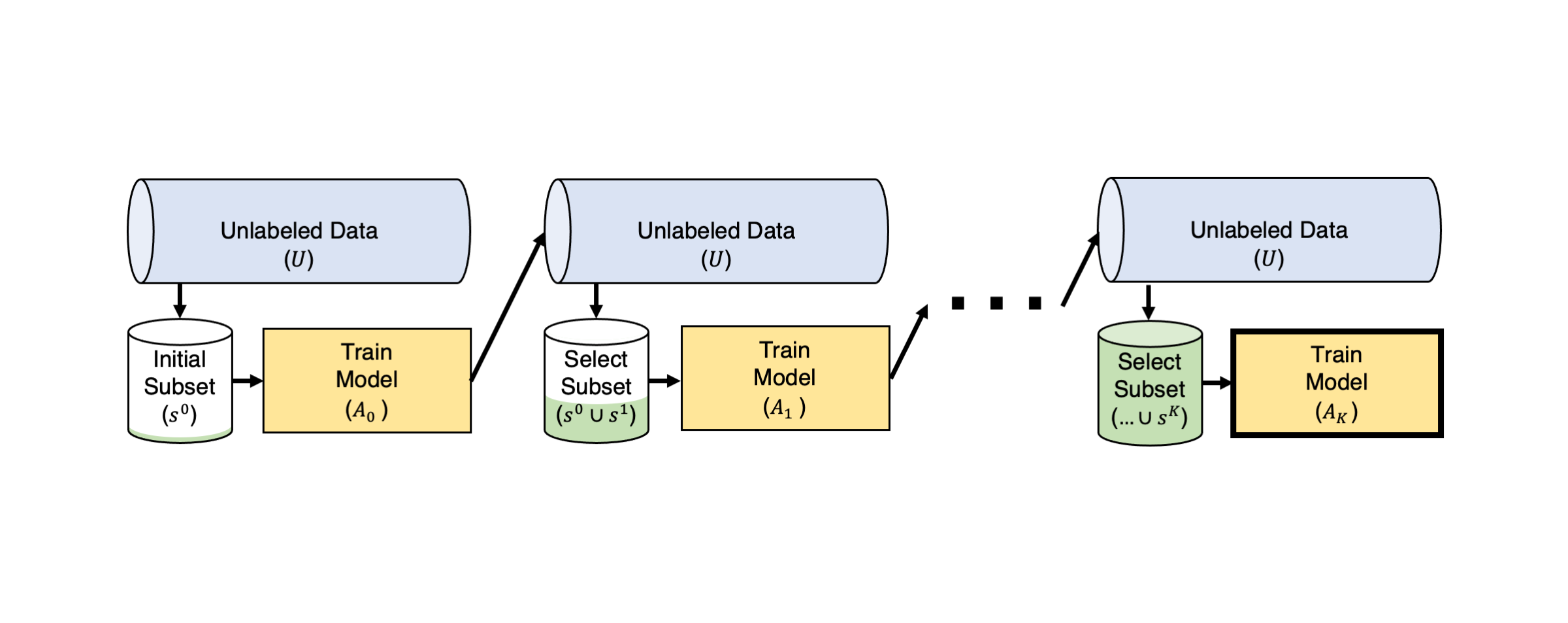
풀 기반 액티브 러닝의 절차
풀(pool) 기반 액티브 러닝에서는 라벨링되지 않은 데이터 풀 가 존재하며, 라벨링은 여러 라운드 에 걸쳐 반복된다. 각 라운드는 다음 단계를 따른다:
- 모델 출력 계산: 이전 라운드에서 라벨링된 데이터를 사용해 모델 를 훈련하고, 이 모델을 이용해 라벨링되지 않은 데이터 의 예제 에 대해 예측 확률 를 계산한다.
- 획득 함수 적용: 모델 출력과 획득 함수(acquisition function) 를 사용하여 각 예제 의 중요도를 평가한다. 획득 함수는 이 데이터를 라벨링하는 것이 모델의 성능을 얼마나 향상시킬지 추정한다.
- 라벨링: 액티브 러닝 알고리즘이 제안한 가장 높은 중요도를 가진 데이터 포인트를 선택하여 실제로 라벨을 붙이고, 이를 새로운 훈련 데이터셋 에 추가한다. 라벨이 붙은 데이터는 에서 제거된다.
- 모델 재학습: 확장된 데이터셋 을 사용해 학습하고 새로운 모델 을 얻는다. 필요할 경우, 이 과정을 반복한다.
불확실성 샘플링 (Uncertainty Sampling)
액티브 러닝에서 자주 사용되는 방법 중 하나는 불확실성 샘플링(uncertainty sampling)이다. 이는 모델이 가장 불확실한 예제를 선택하여 라벨링하는 방법이다. 예를 들어, 분류 작업에서 모델이 각 클래스에 대해 예측하는 확률 벡터 를 출력할 때, 이 예측의 엔트로피를 사용하여 모델의 불확실성을 측정할 수 있다:
엔트로피가 클수록 모델이 해당 예제에 대해 불확실하다는 것을 의미하며, 이러한 예제를 라벨링하는 것이 모델 성능에 더 큰 영향을 미칠 가능성이 높다.
이 획득 함수 는 모델이 현재 가장 불확실하게 예측하는 라벨이 없는 예제에 대해 큰 값을 가진다. 이는 모델이 해당 예제에 대해 무엇을 예측해야 할지 확신이 부족함을 나타내며, 이러한 예제를 라벨링하는 것이 모델 성능을 개선하는 데 더 큰 도움이 될 수 있다. 즉, 불확실성이 큰 예제를 선택함으로써, 모델이 기존 훈련 데이터로부터 학습하지 못한 중요한 정보를 새롭게 학습할 기회를 제공하는 것이다.
액티브 러닝은 보통 사전에 정해진 라벨링 예산이 소진될 때까지 또는 모델이 원하는 정확도 수준에 도달할 때까지 반복적으로 수행된다. 이때 모델 성능은 별도로 확보한 검증 세트에서 평가하여 진척 상황을 확인한다.
패시브 vs 액티브 러닝(Passive vs Active Learning)
액티브 러닝의 가치를 명확히 보여주는 간단한 1차원 예제를 통해 패시브 러닝과 비교할 수 있다. 패시브 러닝(passive learning)은 각 라운드마다 어떤 데이터를 라벨링할지 무작위로 선택하는 방법으로, 모델이 데이터를 선택할 때 정보적 중요성을 고려하지 않는다.
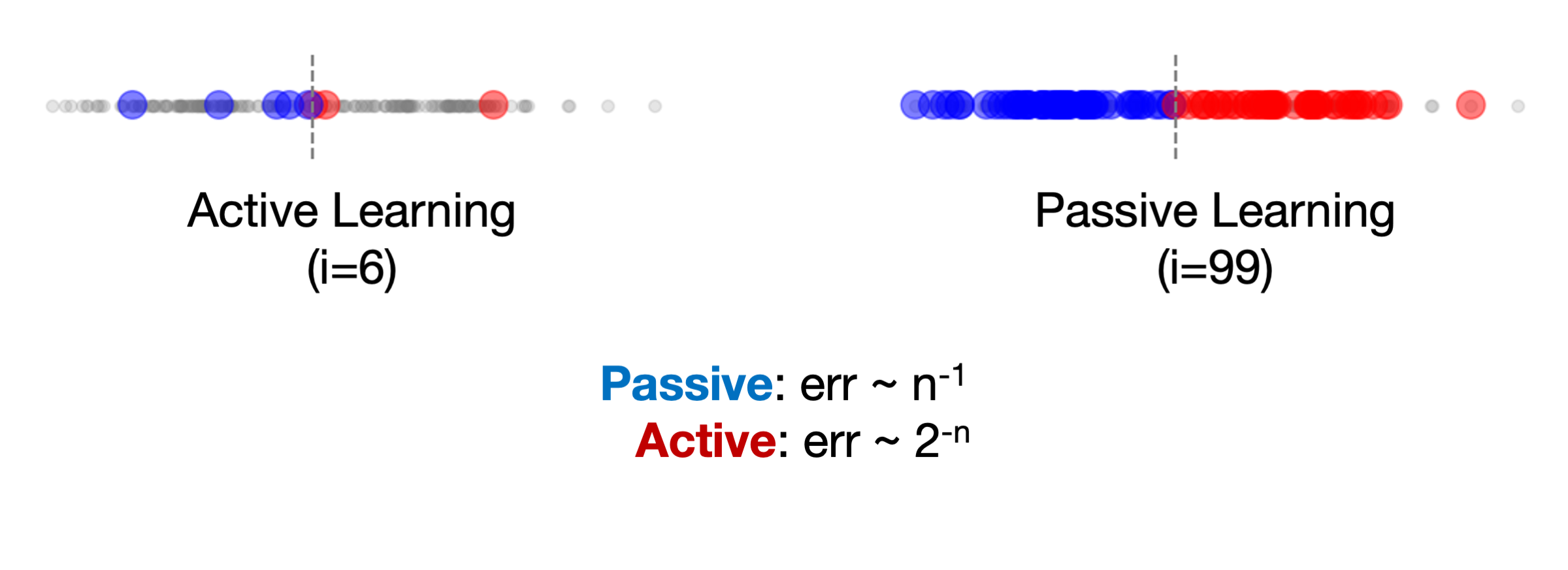
액티브 러닝에서는 모델이 빠르게 결정 경계(회색 점선)에 도달하기 위해 중요한 데이터를 선택한다. 이 예제에서, 액티브 러닝은 약 6번의 반복으로 결정 경계에 도달한다. 반면, 패시브 러닝(또는 무작위 샘플링)은 무작위로 데이터를 선택하므로, 경계 근처의 중요한 예제를 얻는 데 시간이 더 오래 걸린다. 이로 인해 패시브 러닝은 비슷한 성능을 얻기 위해 약 100번의 반복이 필요하다.
이론적으로도 액티브 러닝은 데이터 효율성 면에서 패시브 러닝보다 훨씬 뛰어나다. 액티브 러닝은 주어진 데이터 양 에서 목표 모델의 오류율에 도달하기까지 필요한 데이터 양을 기하급수적으로 줄일 수 있다. 액티브 러닝은 데이터 수가 일 때 오류율이 으로 감소하지만, 패시브 러닝은 로 더 천천히 수렴한다.
실전 도전 과제 1: 대형 모델(Big Models)
이론적으로 액티브 러닝이 매우 효율적인 방법이라는 점은 분명하지만, 실제로 적용할 때는 몇 가지 어려움이 따른다. 특히, 이미지나 텍스트와 같은 복잡한 데이터에 사용되는 현대의 머신러닝 모델은 매우 크고, 파라미터 수가 수백만 개에 이르는 경우가 많다. 이러한 모델을 매번 새로 수집한 라벨로 훈련하는 것은 계산 비용이 많이 들며, 매우 비효율적일 수 있다.
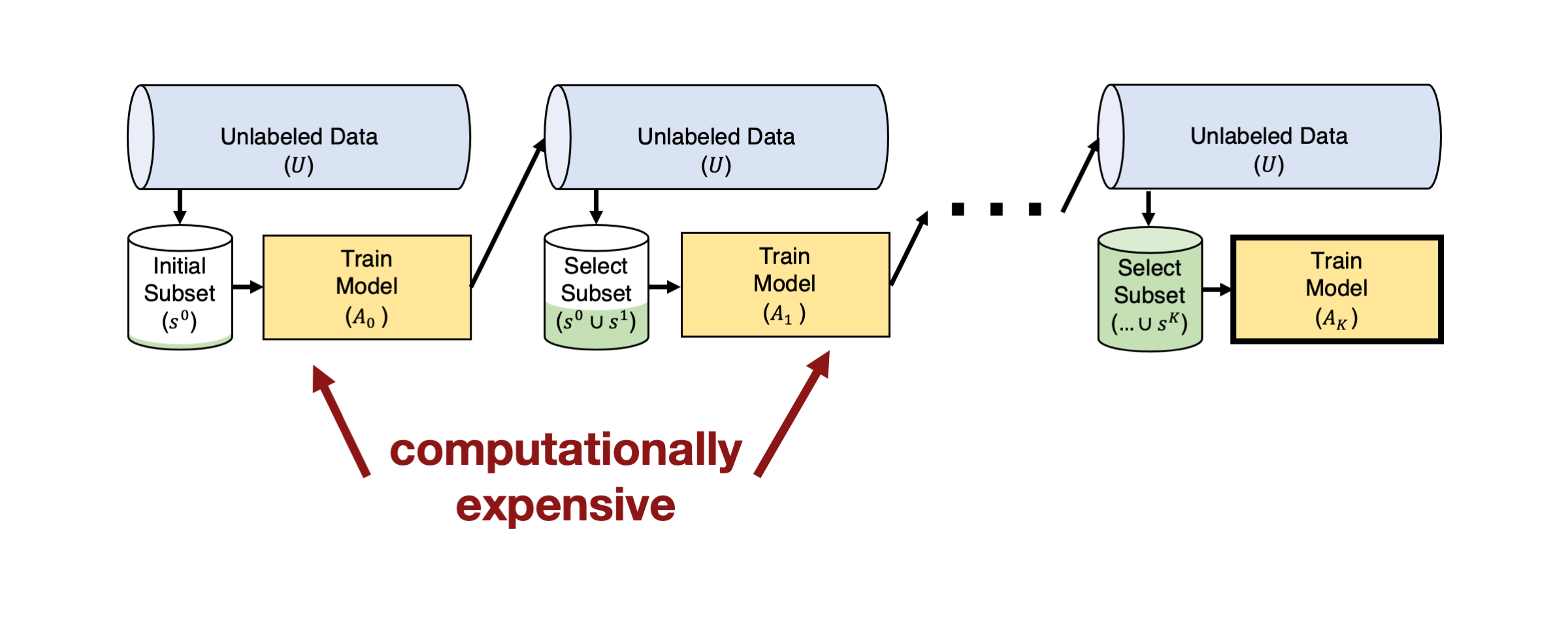
이 문제를 해결하기 위해 배치 액티브 러닝(Batch Active Learning)을 사용할 수 있다. 이는 각 라운드에서 단일 예제가 아니라, 여러 예제를 한 번에 선택하여 라벨링하는 방식이다. 배치를 구성하는 방법으로는, 앞서 설명한 획득 함수(acquisition function) 를 사용하여 라벨링되지 않은 예제 중 상위 개의 예제를 선택하는 방법이 있다.

Figure from From Theories to Queries: Active Learning in Practice by Burr Settles
하지만, 단순히 값이 높은 예제만을 선택할 경우, 선택된 데이터들이 서로 유사할 가능성이 크다. 이는 배치 내의 데이터들이 모델을 충분히 학습시키는 데 다양성이 부족할 수 있다는 문제를 야기할 수 있다. 즉, 유사한 데이터를 여러 개 라벨링하면 학습 효과가 제한적일 수 있다.
이를 방지하기 위해 greedy k-centers 알고리즘과 같은 방식을 사용한다. 이 알고리즘은 라벨링되지 않은 풀에서 정보 가치가 높은 동시에 다양한 데이터를 선택하여, 전체 데이터셋을 잘 대표할 수 있는 작은 부분집합을 찾는다. 이 방법은 라벨링되지 않은 데이터 포인트 중 기존 라벨링된 예제들과 최대 거리가 최소화되도록 최적의 예제를 선택하는 것을 목표로 한다.
실전 도전 과제 2: 빅데이터(Big Data)
현대의 머신러닝 환경에서는 대규모 데이터셋을 다루는 경우가 많다. 이러한 데이터셋은 수백만에서 수십억 개의 라벨링되지 않은 예제를 포함할 수 있으며, 이 데이터를 모두 평가하는 것은 매우 비효율적이다. 액티브 러닝은 전역적으로 라벨링할 최적의 예제를 검색하므로, 데이터 크기에 따라 계산 비용이 선형 또는 이차적으로 증가하게 된다. 이는 웹 스케일의 데이터셋에서는 실질적으로 사용할 수 없게 만든다.
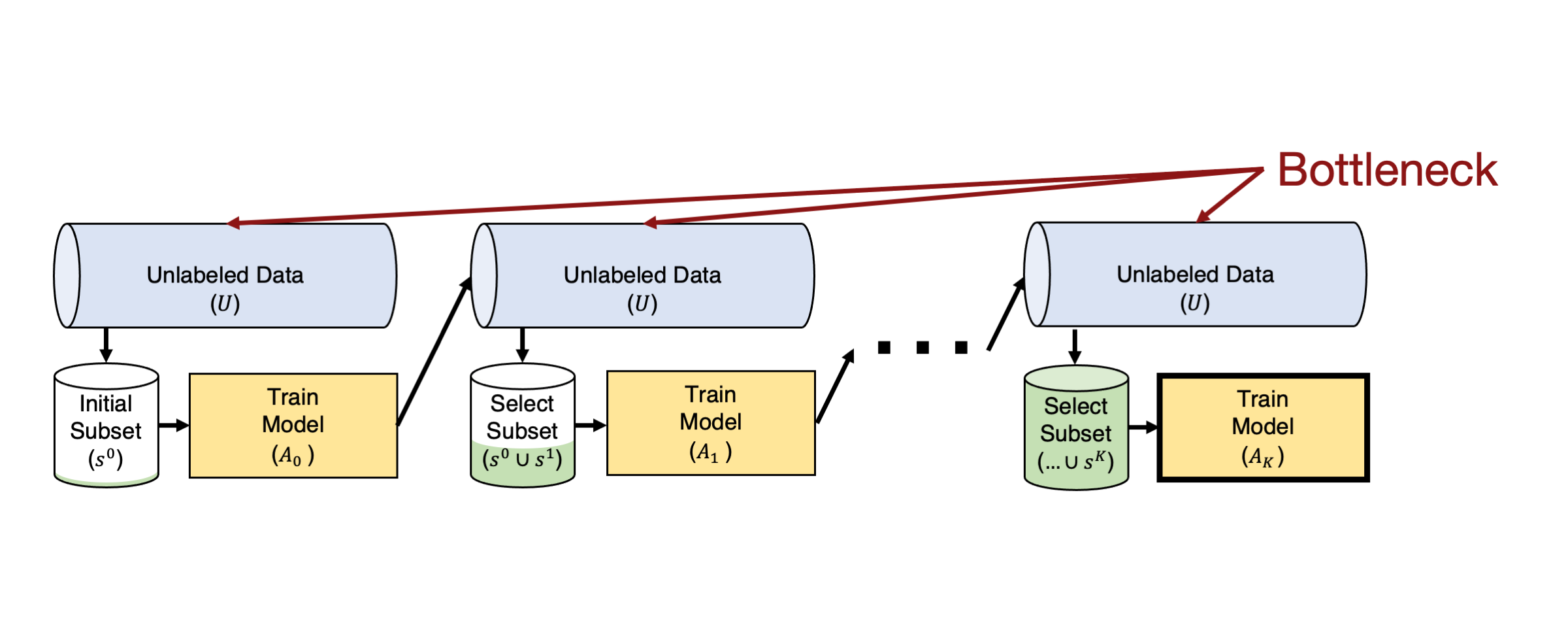
이 문제를 해결하기 위한 한 가지 방법은 라벨링되지 않은 풀 중 일부만을 평가하는 것이다. 실제로 많은 클래스는 전체 데이터의 작은 부분만 차지하므로, 모든 데이터를 평가하는 대신 사전 훈련된 모델의 잠재 표현(latent representation)을 활용하여 데이터를 클러스터링할 수 있다. 이렇게 함으로써, 현재 라벨링된 예제들과 가장 유사한 예제들을 우선적으로 선택하여 평가할 수 있다.
이 접근법의 대표적인 예로는 유사성 검색(SEALS, Similarity Search for Efficient Active Learning and Search of Rare Concepts) 알고리즘이 있다. SEALS는 각 라운드에서 현재 라벨링된 예제들과 가장 가까운 이웃(nearest neighbor)을 찾는 방식으로, 전체 데이터셋을 모두 검색하지 않고도 효율적으로 라벨링할 예제를 선택할 수 있다.
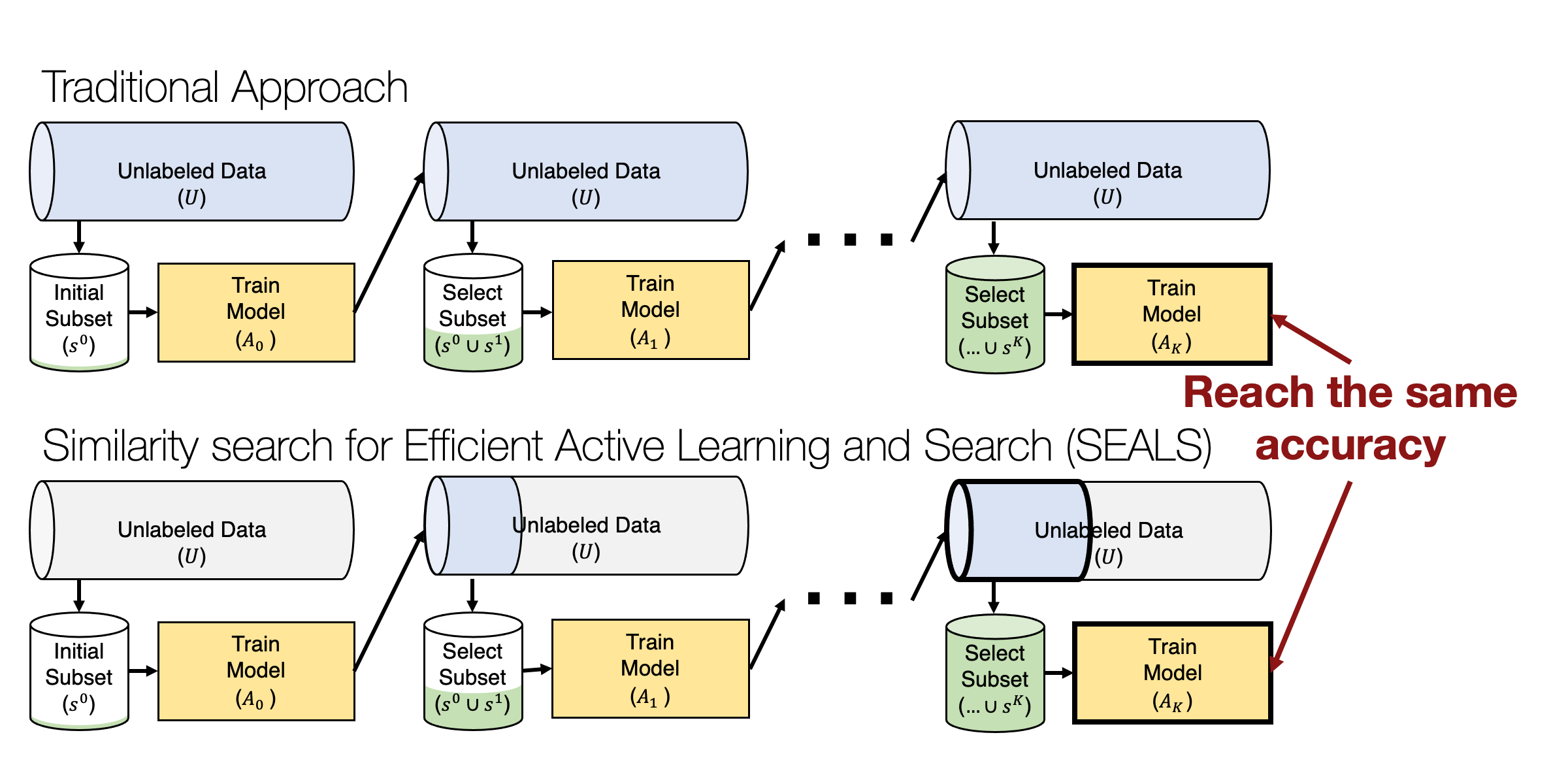
라벨링된 각 예제에 대해 가장 가까운 라벨링되지 않은 예제를 찾는 과정은 서브리니어 검색 시간(sublinear retrieval time)을 가진다. 이는 수백만 또는 수십억 개의 예제가 있는 데이터셋에서도 서브초(sub-second) 지연 시간으로 처리될 수 있다 (Johnson et al., 2019). 이 방식은 데이터 크기에 따라 선형적으로 확장되지 않으며, 데이터 크기가 커지더라도 효율적으로 검색할 수 있다.
코어셋 선택(Core-set selection)
라벨링된 데이터가 너무 많을 때, 모든 데이터를 처리하는 것은 시간과 자원이 많이 소모될 수 있다. 특히, BERT, SimCLR, DINO와 같은 자기 지도 학습(self-supervised learning) 방법들은 매우 많은 양의 데이터를 생성할 수 있다. 그러나 이러한 데이터를 모두 처리할 필요는 없으며, 중복된 데이터를 제거하고 핵심적인 데이터만으로도 충분한 성능을 얻을 수 있다. 코어셋 선택은 이러한 문제를 해결하기 위한 효과적인 방법이다.
코어셋 선택의 목표
- 대표적인 데이터 부분집합을 찾아 전체 데이터셋을 사용한 것과 유사한 성능을 달성하는 것
- 학습 시간과 자원 절약: 더 적은 데이터로 비슷한 성능을 유지함으로써 계산 비용을 줄일 수 있다.
코어셋 선택의 어려움
- 기존의 코어셋 선택 방법은 특정 모델에 의존하는 경향이 있으며, 딥러닝 모델에 잘 적용되지 않는다.
- 특히, greedy k-centers 접근법은 타겟 모델에 의존하기 때문에 코어셋 선택을 위해 모델을 훈련하는 것은 비효율적일 수 있다.
- 코어셋 선택을 수행하기 위해 모델을 훈련하는 것은 데이터를 줄여서 얻을 수 있는 훈련 시간 개선을 상쇄하여 목적을 상실하게 될 수 있기 때문이다
프록시를 통한 선택 (Selection via Proxy)
다행히도 코어셋 선택 과정에서 타겟 모델 대신 더 작은 프록시 모델(proxy model)을 사용하여 중요한 데이터를 선택할 수 있다. 타겟 모델보다 가벼운 프록시 모델(작은 신경망)을 사용하여 학습 시간을 줄이면서도 유효한 데이터를 선택할 수 있다.
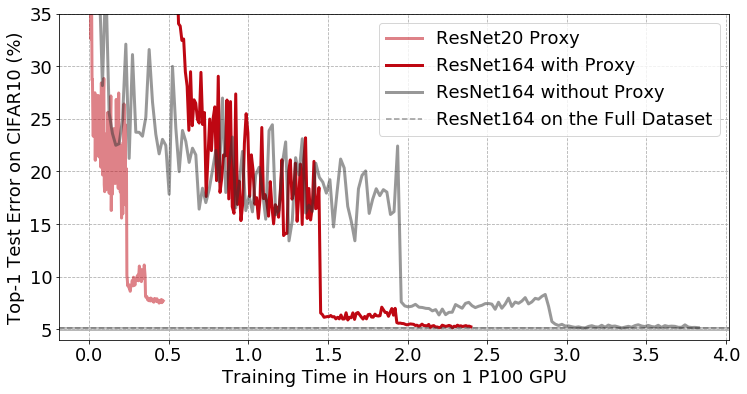
CIFAR10 데이터셋에서 프리액티베이션(pre-activation)을 적용한 ResNet164 CNN classifier의 학습곡선을 보여준다. 프록시를 통한 데이터 선택이 적용된 경우와 적용되지 않은 경우를 비교한 결과이다. 연한 빨간색 선은 더 작은 ResNet20 네트워크인 프록시 모델을 훈련한 결과를 나타낸다. 진한 빨간색 선은 프록시 모델이 선택한 이미지 부분집합을 사용해 타겟 모델(ResNet164)을 훈련한 결과를 나타낸다. 프록시 모델을 사용하여 전체 데이터의 50%를 제거했음에도 불구하고, ResNet164의 최종 정확도에는 영향을 미치지 않았다. 그 결과, end-to-end 학습시간이 3시간 49분에서 2시간 23분으로 줄었다.
References
- Lecture (ver.2024): https://dcai.csail.mit.edu/2024
- Lecture (ver.2023): https://dcai.csail.mit.edu/2023
- Lab Session (ver.2023): https://github.com/dcai-course
- P.S. 본 포스팅 작성에는 OpenAI의 GPT-4o와 o1-preview가 활용되었습니다
