
Python 언어로 소스 코드 에디터를 사용하여 코드를 작성하여 MySQL을 실행할 수 있다.
여러 소스 코드 에디터 중에서 VSCode를 사용한다.
Python 사용
VSCode를 실행시켜서 .ipynb(노트북 파일)을 생성한다.
mysql과 연동하기 위해 connector를 설치해야 한다.
pip install mysql-connector-pythonconnector
connector를 불러온다.
import mysql.connector접속 코드
local 접속
'con'이란 변수로 현재 local의 MySQL에 접속한다.
con = mysql.connector.connect(
host = 'localhost',
user = 'root',
password = '********'
)
# database에 바로 접속
con = mysql.connector.connect(
host = 'localhost',
user = 'root',
password = '********',
database = 'project'
)AWS RDS 등 클라우드 연결
con = mysql.connector.connect(
host = 'amazon_data_name_ID.rds.amazonaws.com',
port = '3306',
password = 'admin',
database = '*********'
)local 또는 AWS 접속하여 사용이 끝났다면 접속을 종료하도록 한다.
con.close()Query 실행
노트북 파일에서 쿼리를 실행하기 위해서 connection을 맺은 다음,
connection을 통해서 cursor()를 생성한다.
mycursor = con.cursor()Execute
cursor를 생상한 후 쿼리를 실행할 수 있는데,
execute를 통해서 쿼리를 입력할 수 있게 된다.
먼저 mysql과 연결을 한다.
con = mysql.connector.connect(
host = 'localhost',
user = 'root',
password = '******',
database = 'preject'
)
mycursor = con.cursor()확인을 위해 터미널/cmd로 mysql에 접속하여 확인을 해보자.
현제 database preject의 table들이다.
mysql> show tables;
+-------------------+
| Tables_in_project |
+-------------------+
| celeb |
| person |
| test01 |
| test02 |
+-------------------+
4 rows in set (0.01 sec)sql_file이라는 table을 노트북 파일로 쿼리를 생성해보자.
쿼리문은 따옴표로 묶어 주어야 한다.
mycursor.execute('create table sql_file (id int, filename varchar(16))')table이 생성되었는지 확인해보자.
mysql> desc sql_file;
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| filename | varchar(16) | YES | | NULL | |
+----------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)쿼리문이 끝났으면 연결을 종료하도록 한다.
con.close()sql_file를 삭제하는 것도 진행해보자.
con = mysql.connector.connect(
host = 'localhost',
user = 'root',
password = '******',
database = 'preject'
)
mycursor = con.cursor()
mycursor.execute('drop table sql_file')
con.close()mysql 확인하면 삭제가 된 것을 확인할 수 있다.
mysql> show tables;
+-------------------+
| Tables_in_project |
+-------------------+
| celeb |
| person |
| test01 |
| test02 |
+-------------------+
4 rows in set (0.00 sec).sql file로 실행
test03.sql file을 아래와 같이 생성한다.
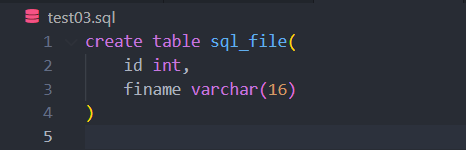
con = mysql.connector.connect(
host = 'localhost',
user = 'root',
password = '******',
database = 'preject'
)
cur = con.cursor()
sql = open('test03.sql').read() # test03에 있는 쿼리문을 sql에 변수로 지정
cur.execute(sql)
con.close()sql 쿼리
sql
'create table sql_file(\n id int, \n finame varchar(16)\n)\n'.sql file로 복수 쿼리 실행
.sql file안에 하나의 쿼리문 이상이 있을 때에는 옵션을 주어야 실행이 가능하다.
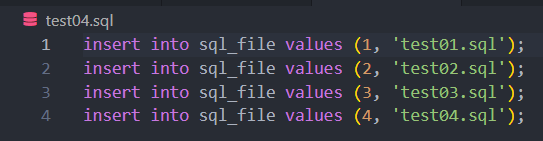
cur = con.cursor()
sql = open('test04.sql').read()
cur.execute(sql)
# 비어 있다.
mysql> select * from sql_file;
Empty set (0.00 sec)multi=True
Execute의 multi는 기본값이 False이므로 True로 설정하여 복수 쿼리문도 진행할 수 있도록 한다.
commit
table에 데이터는 쿼리를 실행한 후 commit()을 실행해야 적용이 된다.
반복문으로 데이터를 입력 시,
commit()을 활용하여 반복문이 실행될 때마다 적용 또는 모든 반복문이 끝나고 적용하는 것으로 활용할 수 있다.
con = mysql.connector.connect(
host = 'localhost',
user = 'root',
password = '******',
database = 'preject'
)
cur = con.cursor(buffered=True)
sql = open('test04.sql').read()
for q in cur.execute(sql, multi=True): # multi를 주어서 쿼리만큼 반복문 진행
if q.with_rows:
print(q.fetchall()) # fetchall은 밑에서 확인
else:
print(q.statement)
con.commit() # 데이터를 입력할 때에는 commit으로 적용시켜야 한다. commit은 반복문을 진행하며 한 번에 해도 되고
con.close()
---
insert into sql_file values (1, 'test01.sql')
insert into sql_file values (2, 'test02.sql')
insert into sql_file values (3, 'test03.sql')
insert into sql_file values (4, 'test04.sql')mysql 결과 확인
mysql> select * from sql_file;
+------+------------+
| id | finame |
+------+------------+
| 1 | test01.sql |
| 2 | test02.sql |
| 3 | test03.sql |
| 4 | test04.sql |
+------+------------+
4 rows in set (0.00 sec)Fetch All
위에서 쿼리 실행한 다음에 결과값이 있다면 fetchall을 통해서 확인할 수 있다.
그래서 위에 'insert into sql_file values (1, 'test01.sql')'실행문이 출력이 된 것이다.
조회를 할 때에는 조회한 결과를 fetchall을 통해서 조회 결과값을 받아올 수 있다.
con = mysql.connector.connect(
host = 'localhost',
user = 'root',
password = '******',
database = 'preject'
)
cur = con.cursor()
cur.execute('select * from celeb')
result = cur.fetchall() # 쿼리문 조회의 결과를 fetchall()을 통해 result 변수에 담는다.
for i in result:
print(i)
---
(1, '아이유', datetime.date(1993, 5, 16), 29, 'F', '가수, 텔런트', 'EDAM엔터테이먼트')
(2, '이미주', datetime.date(1994, 9, 23), 28, 'F', '가수', '울림엔터테이먼트')
(3, '송강', datetime.date(1994, 4, 23), 28, 'M', '텔런트', '나무엑터스')
(4, '강동원', datetime.date(1981, 1, 18), 41, 'M', '영화배우, 텔런트', 'YG엔터테이먼트')
(5, '유재석', datetime.date(1972, 8, 14), 50, 'M', 'MC, 개그맨', '안테나')
(6, '차승원', datetime.date(1970, 6, 7), 48, 'M', '영화배우, 모델', 'YG엔터테이먼트')
(7, '이수현', datetime.date(1999, 5, 4), 23, 'F', '가수', 'YG엔터테이먼트')조회한 데이터를 확인한 후,
DataFrame로 바꿔서 데이터 EDA 및 전처리 등을 수행할 수 있다.
df = pd.DataFrame(result, columns=('id', 'name', 'birthday', 'age', 'sex', 'job', 'agency'))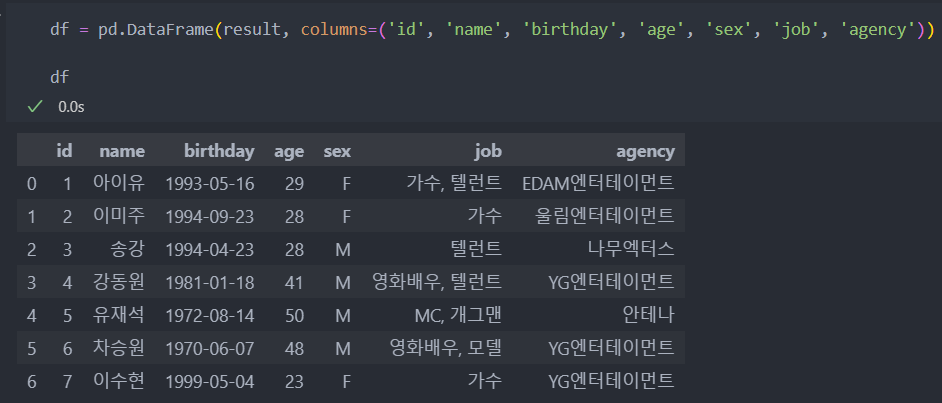
buffered
지금은 7행의 데이터로 적은 양이지만,
데이터가 매우 많은 경우에는 버퍼링이 생겨서 제대로 불러오지 못하는 경우가 발생한다.
이때 cursor()를 생성할 때 buffered = True 옵션을 설정하여 진행하도록 한다.
# 기본값으로 항상 옵션을 넣어 두자.
cur = con.cursor(buffered = True).csv을 database table로
먼저 csv file을 판다스를 사용하여 불러온다.
df = pd.read_csv('../../police_station.csv', header=None, index_col=0)
df.reset_index(inplace=True)
df.rename(columns={0:'경찰서', 1:'주소'}, inplace=True)
mysql과 연결하여 해당 데이터를 table로 입력해보자.
con = mysql.connector.connect( # 연결
host = 'localhost',
user = 'root',
password = '******',
database = 'preject'
)
# table 생성
cur = con.cursor(buffered=True) # cursor 생성 / buffered : 현재는 조회를 하는 것이 아니기에 없어도 되지만 조회를 할 것이기에 미리 적용
cur.execute('create table police_station (station varchar(16), address varchar(128))') # table 생성 쿼리 실행
# table에 데이터 입력
sql = 'insert into police_station values (%s, %s)' # 쿼리 기본 작성
for i, row in df.iterrows():
cur.execute(sql, tuple(row)) # 'tuple'형태로 %s, %s에 순서대로 쿼리를 입력(s:string)
con.commit() # 입력한 쿼리를 적용
# table 데이터 조회
cur.execute('select * from police_station')
result = cur.fetchall() # 조회한 데이터를 변수에 담기
df = pd.DataFrame(result, columns=('경찰서', '주소')) # 데이터프레임으로 작성제대로 입력이 되었고 정상적으로 다시 데이터를 조회한 것을 확인할 수 있다.
mysql에서도 확인해보자.
mysql> desc police_station;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| station | varchar(16) | YES | | NULL | |
| address | varchar(128) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
mysql> select * from police_station;
+--------------------------+----------------------------------------------------------------------------------+
| station | address |
+--------------------------+----------------------------------------------------------------------------------+
| 서울특별시경찰청 | 서울시 종로구 사직로8길 31 |
| 서울중부경찰서 | 서울특별시 중구 수표로 27 |
| 서울종로경찰서 | 서울특별시 종로구 율곡로 46 |
| 서울남대문경찰서 | 서울특별시 중구 한강대로 410 |
31 rows