
pivot_table(피벗테이블)은 하나 이상의 컬럼을 로우나 컬럼에 지정하여 데이터를 정렬할 수 있도록 해준다.
pivot_table은 기본적으로 그룹 연산을 하기때문에 결과값은 연산이 가능한 컬럼을 보여준다.
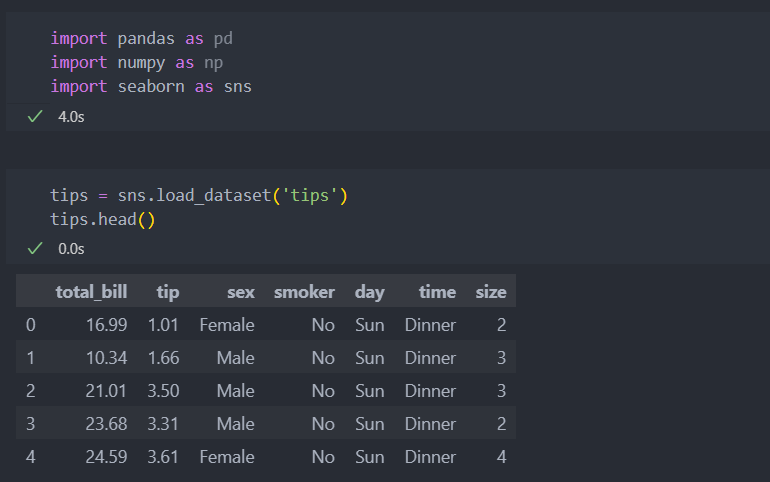
먼저 seaborn에서 제공하는 tips로 pivot_table를 보자.
pivot_table의 옵션을 설정
index
데이터의 컬럼명을 입력하여 index(로우)로 그룹으로 묶어준다. 아래와 같이 연산이 안 되는 day, time은 보여주지 않는다.
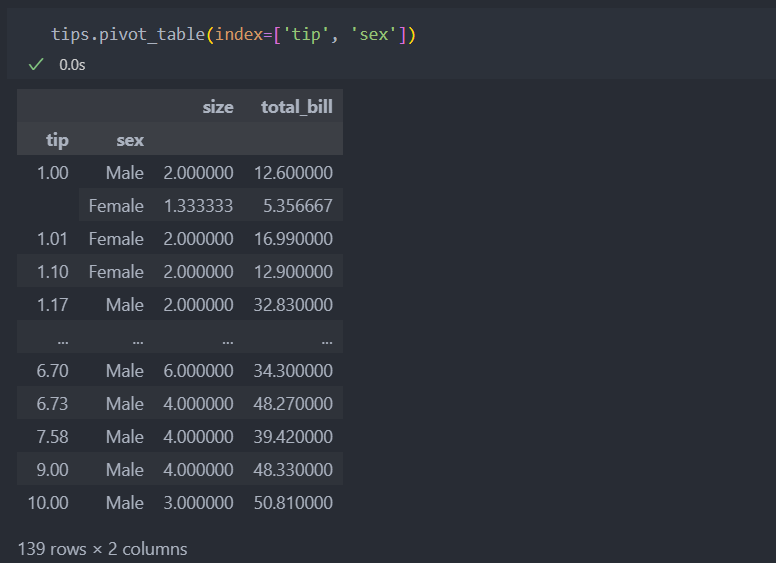
집계하여 결과값을 보여줄 때 기본값은 평균을 보여준다. 이것은 aggfunc를 통해서 변경할 수 있다.
aggfunc(default='mean')
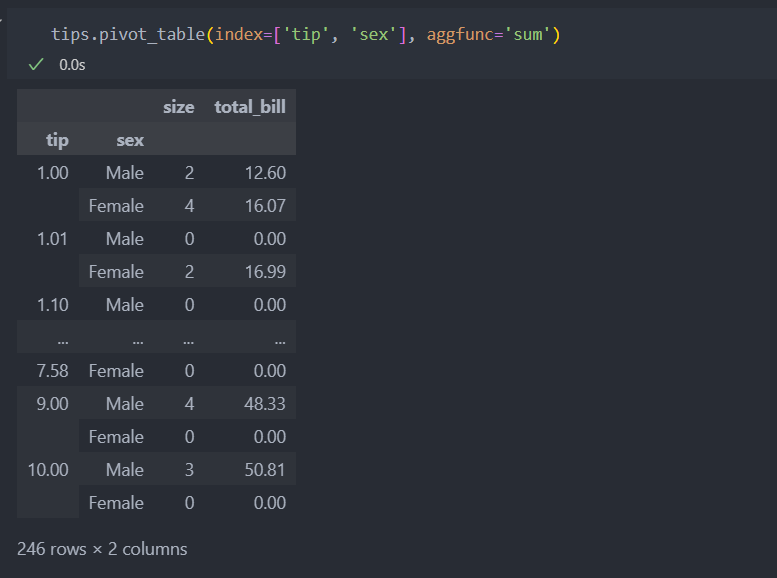
평균이 아닌 합계('sum')를 인자값으로 주면 합계를 보여준다.
time, day는 연산이 가능하지 않지만 count로 수는 셀 수 있기에 인자로 'count'를 던져주면 값을 반환한다.
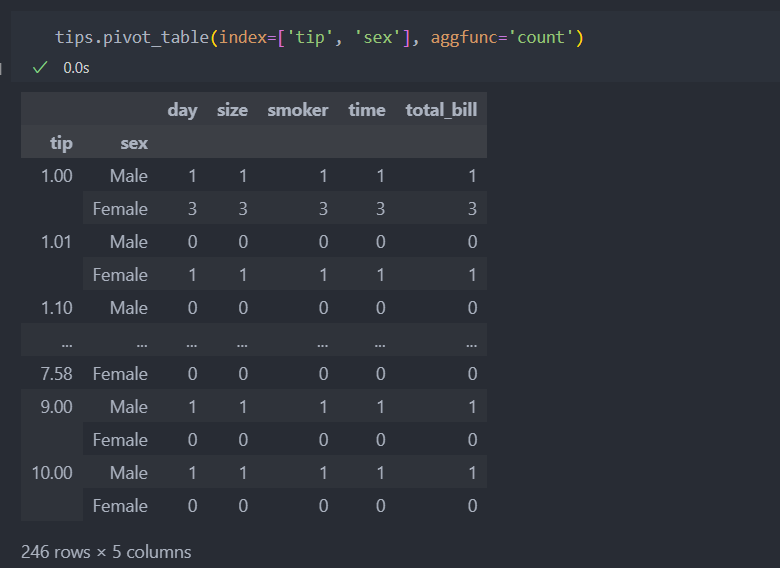
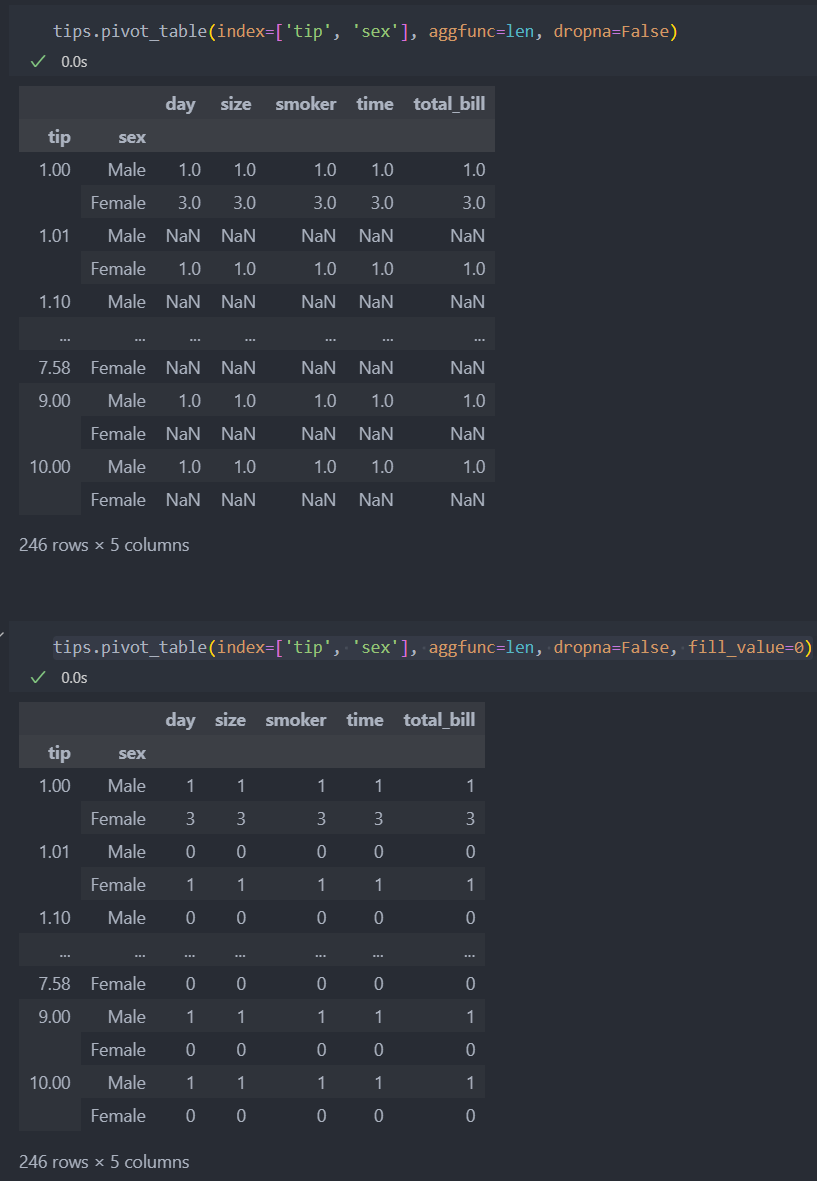
데이터에는 NaN값도 있어 count를 할 때 NaN값은 값을 0으로 반환한다. 이 때 NaN 값이 아닌 값을 반환받으려면 len을 인자로 주면 된다.
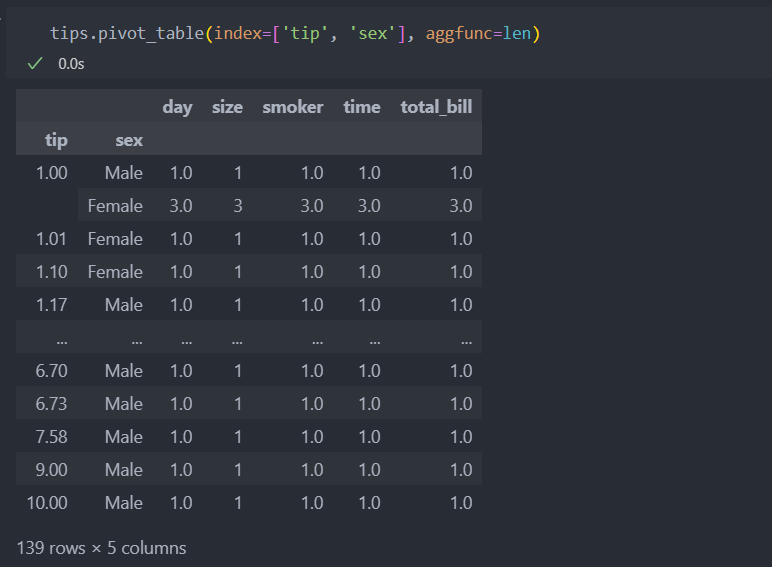
기본적으로 판다스는 연산을 시행할 때 NaN값은 제외하고 연산을 진행하기에 NaN값을 보여주지 않는다. 하지만 NaN값을 포함하여 보고 싶을 때에는 인자로 dropna(모든 항목이 NaN값일 때만) 인자로 조절할 수 있다.
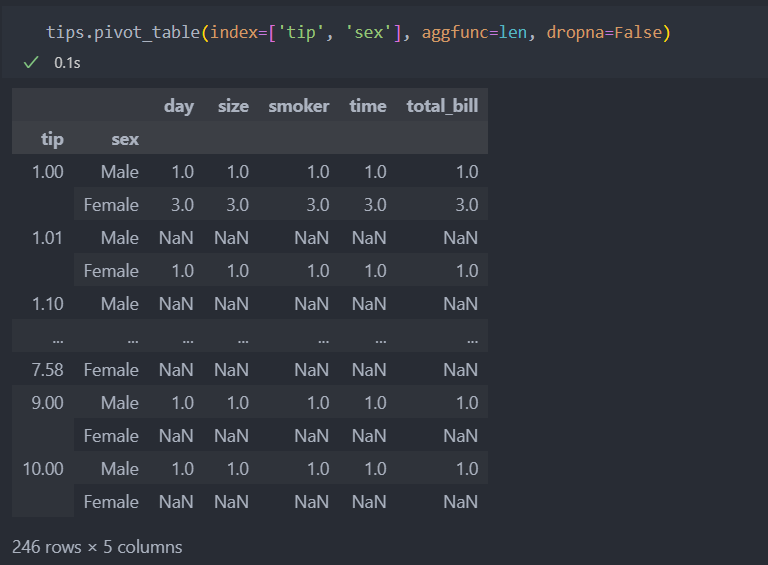
dropna(default=True)
NaN값은 보여주지 않는 것이 기본값이지만 False를 주어 NaN값을 확인할 수 있다.
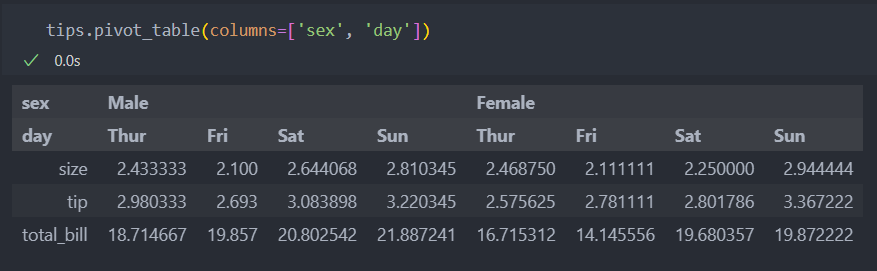
columns
컬럼을 지정하여 그룹으로 데이터를 묶어 보여줄 수 있다.
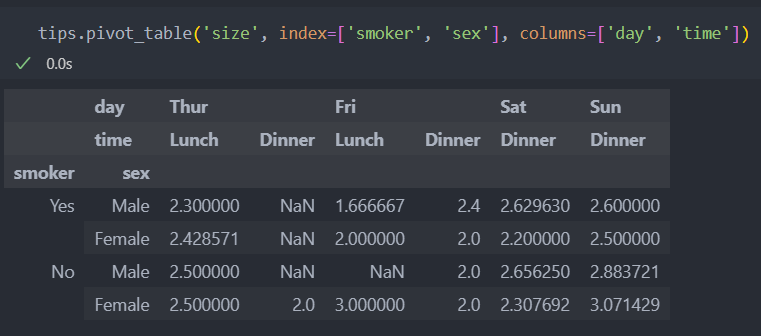
아니면 원하는 값만 집계하고 싶다면 인자로 데이터를 설정하고 로우와 컬럼을 설정하면 된다.
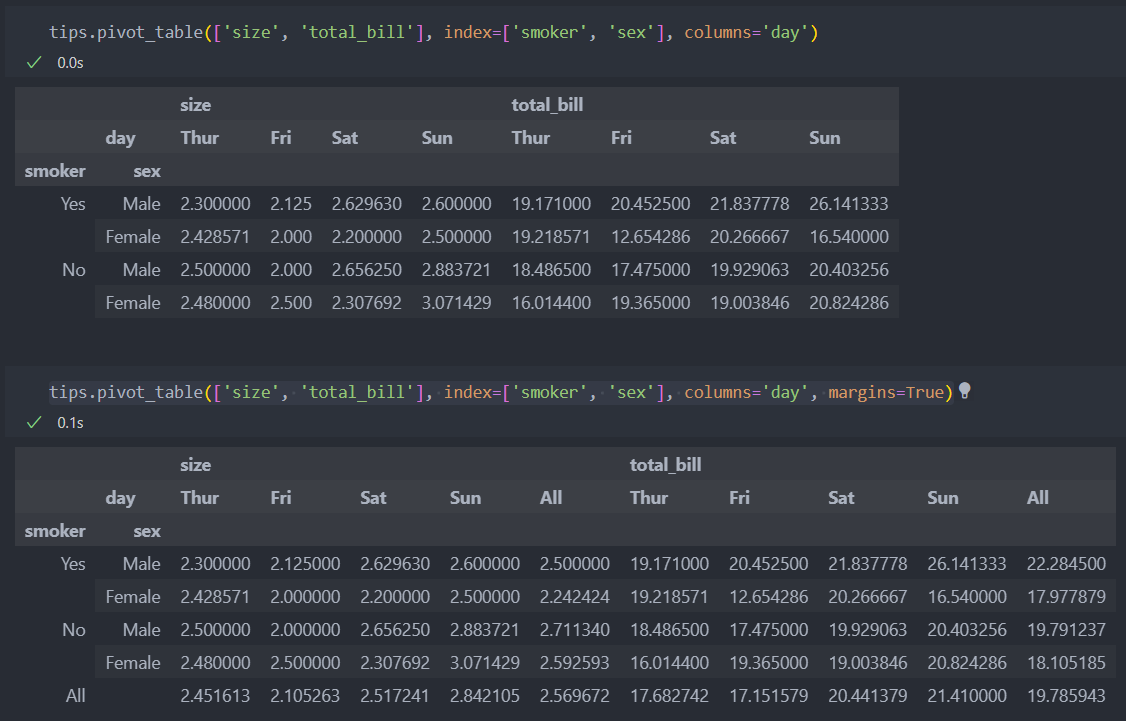
margins
주간합계를 나타낼 수 있도록 로우와 컬럼에 추가할 수 있다.
fill_value
결측치 값을 원하는 값으로 교체할 수 있다.
기타
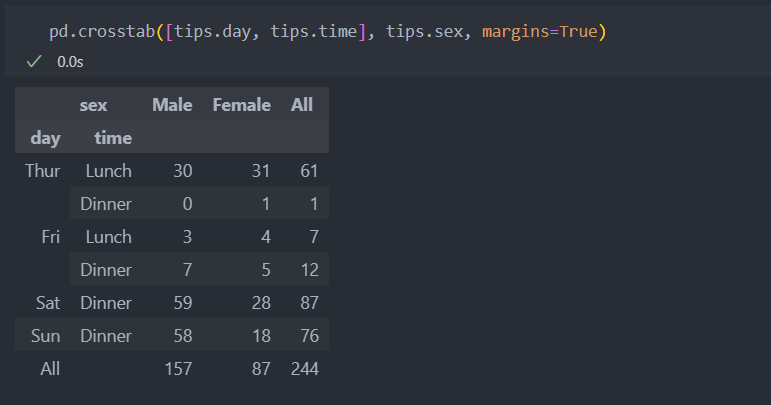
빈도수를 단순히 확인하려면 pandas.crosstab으로 간단히 확인할 수 있다.
요일별 남자손님과 여자손님의 수를 보려면.

https://blog.naver.com/sanzo213/224109460947
안녕하세요, 사실 제가 데이터를 가로<->세로로 바꿈에 있어서 사용하기 편한 reshape_wide, reshape_long 함수를 만들었습니다. 특히 세로로 데이터를 바꿀 때 melt를 쓰니 wide_to_long을 쓰니 문법이 다다르고 일관되지 않고 불편해서(저에게 있어선 공수가 엄청 들었습니다..) 만들어봤습니다.
한번 확인해보시고 사용해 보시면 감사할 거 같아요ㅎ