가설 검정
수집된 데이터를 바탕으로 모집단의 특성의 가설에 대한 통계적 유의성을 검정하는 일련의 과정
- 수집된 데이터는 대부분 샘플이며(모집단의 부분집합) 모집단 전체를 알 수 없는 경우가 대부분
- 통계적 유의성 : 수집된 데이터가 확률적으로 의미가 있는 경우
- 단계 : 영 가설(귀무가설) & 대립 가설 설정 -> 검정 통계량 설정 -> 기각역 설정 -> 검정통계량 계산 -> 의사 결정
영 가설(귀무 가설)과 대립 가설
- 영 가설 : 특정 데이터가 없으면 '참'으로 추정(ex. 무죄 추정의 원칙)
- 대립 가설 : 특정 데이터가 없으면 '거짓'으로 추정하며 관심 대상인 가설
p-value
영 가설이 '참'이라고 가정할 때 얻은 결과와 다른 결과가 관측될 확률로, 그 값이 작을 수록 영 가설을 기각(보통 p < 0.05)할 근거가 됨
영 가설이 '참'일 때 기대할 수 있는 데이터의 분포가 클 수록 p-value 커지고, 작다면 '거짓'일 확률이 커진다.
영 가설이 '거짓'이라고 대립 가설이 '참'인 것은 아니다.
- ex) 영 가설: 한국 남성의 키 평균은 160이다. 영 가설에서 데이터의 실 분포는 175라면(p<0.05) 영 가설 기각
일원분산분석
셋 이상의 그룹 간 차이가 존재하는지 확인하기 위한 가설 검정.
독립 변수가 1개인데 그룹이 여러개일 경우에 진행.
ex) 대리점 A, B, C의 일별 판매량 차이
선행 조건
- 독립성 : 모든 그룹은 서로 독립적이어야 한다.
- 정규성 : 모든 그룹은 정규성을 띄어야 한다.(비모수일 경우 Kruskal-Wallis H Test 수행)
- 등분산성 : 모든 그룹의 데이터의 분산의 수준이 같아야 함.(비모수일 경우 Kruskal-Wallis H Test 수행)
사후 분석(Tukey HSD test) : 일원분산분석 후 영 가설이 기각이 되었다면(그룹 간 차이가 있어다면) 어느 그룹에서 차이가 있는지 확인
검정
일자별 대리점들의 판매 수량 데이터를 가지고 확인하고 박스 플롯을 그려보자.
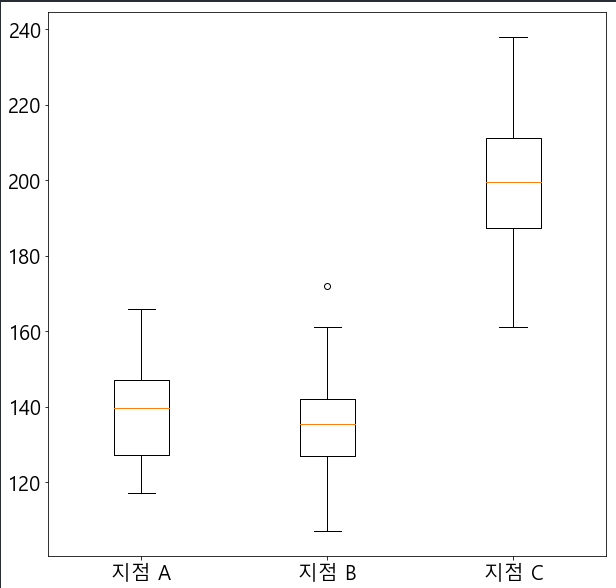
먼저 지점별로 3개의 그룹을 만들고 데이터의 그룹들이 정규성을 띄는지 확인한다.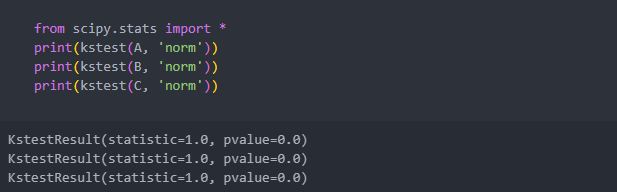
p-value가 0.05 미만이므로 정규성을 나타낸다.
그리고 일원분산분석을 아래와 같이 진행한 결과 p-value가 '0'에 수렴하는 것으로 보아 세 그룹의 평균에는 유의미한 차이가 존재한다.

단순히 유의미한 차이가 있다는 것만 확인이 되고, 어느 그룹이 다른 그룹과 다른지 확인하기 위해서는 사후 분석을 해봐야 한다.
statsmodels의 pairwise_tukeyhsd을 통해서 사후 분석을 할 수 있다.
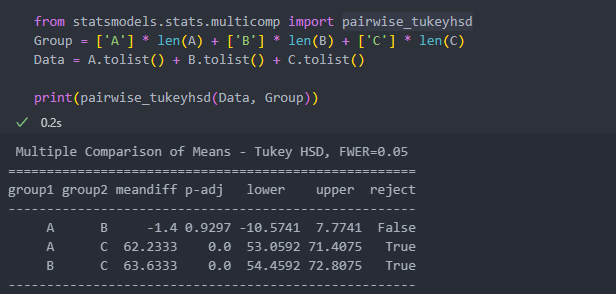
from statsmodels.stats.multicomp import pairwise_tukeyhsd인자는 pairwise_tukeyhsd(데이터, 데이터가 속한 그룹)으로 만드는데, 데이터와 데이터가 속한 그룹은 1:1 대응을 위해서 아래와 같이 'Group'과 'Data'로 생성한 후 인자로 넣어준다.
- group1, group2 : 순서대로 비교할 모든 그룹 조합.
- meandiff : 그룹간 평균 차이.
- reject : False는 유의한 차이가 '없음'을, True는 유의한 차이가 '있음'을 나타냄.
'A-B'는 유의한 차이가 존재하지 않고 'A-C, B-C'는 유의한 차이가 있음을 알 수 있다.
또한 'meandiff'의 차이가 'A-B'는 1.4인데 반해 'C'와는 60이상 차이가 나는 것을 확인할 수 있다.
결국 'C'그룹이 다른 두 그룹과 차이를 보임을 알 수 있다.