
1. open 사용
opne(경로+파일 이름)
딥러닝에서 coco.json파일을 통해 데이터의 '경로/파일 이름'으로 지정하거나 수정할 때 자주 쓰인다. 또한 텍스트 파일 안의 내용을 읽거나 쓰기 위해 자주 사용된다.
열려는 파일의 경로와 파일 이름을 입력하여 읽어 온다.

r'path'
윈도우에서는 경로 지정 시 \(역슬레쉬)를 사용하는 등 운영체제별로 파일 경로를 지정할 때 헷갈리거나 오류가 일어날 수 있다. 이 때 'r'을 사용하면 단순한 'raw string'임을 컴퓨터에 알려줘서 데이터를 불러올 때 오류없이 쉽게 불러올 수 있다.

read(), readline()
read()는 해당 데이터를 모두 읽어올 때 사용한다.
모두 읽어오기에 띄어쓰기 까지 하나의 string으로 인식하고 행으로 데이터가 입력되어 있다면 '\n'(줄바꾸기)까지 불러 온다.

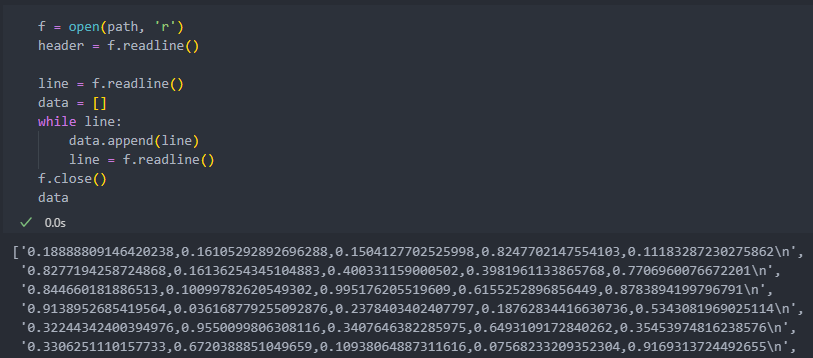
readline()은 줄바꾸기를 기준으로 한행 씩 읽어 온다.
줄바꾸기 기준으로 리스트에 담아 불러오고 싶다면 마지막 행까지 while문을 이용하여 불러온다.
readline()를 한 번 호출할 때마다 다음 행으로 넘어가서 불러온다.
close(), with open
모두 읽어왔다면 open한 데이터를 닫아주어야 한다.
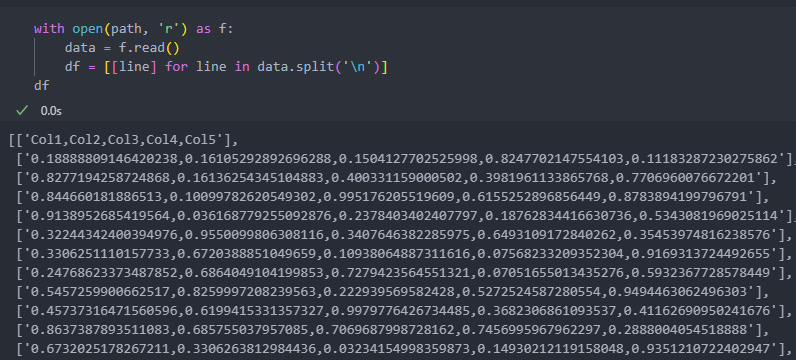
위의 경우처럼 일일이 닫아주는 것이 번거로울 땐, 아래와 같이 with 구문을 사용하자.
as f 파일을 'f'라는 이름으로 불러오겠다는 것이다.
아래는 모든 데이터를 불러와서 '\n(줄 바꾸기)'를 기준으로 분리하여 리스트에 하나씩 담는 경우다.
2. pandas의 read 사용
import pandas as pd
앞으로 pd라는 이름으로 pandas를 사용하겠다.
판다스의 경로를 지정할 때에도 'r'을 쓰면 운영체제에 상관 없이 편하게 불러올 수 있다. 그런데 파이썬이 버전이 업데이트 되면서 r을 쓰지 않아도 잘 불러오는 것 같다.
csv 파일은 pd.read_csv(경로), excel 파일은 read_excel(경로) 등 여러가지 데이터를 불러올 수 있다.
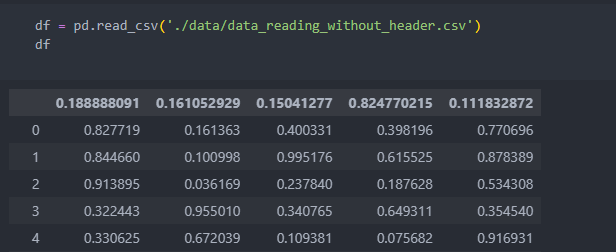
header
데이터를 불러올 때 제일 데이터의 가장 위의 행이 columns으로 자동 지정이 된다.
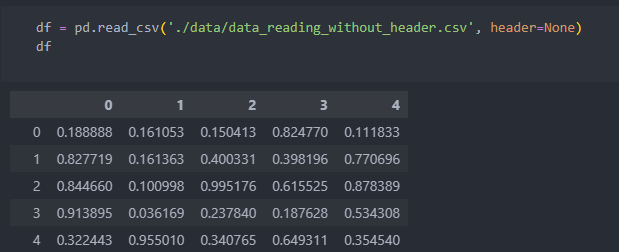
그래서 'header=None'으로 지정하여 columns 데이터가 없는 경우 데이터를 columns으로 불러오지 않도록 한다. 그러면 columns는 자동으로 sep 기준 자연수 0부터 숫자를 메겨서 가져온다.
index/columns 이름 바꾸기
불러온 데이터의 인덱스나 컬럼명을 바꾸고자 한다.
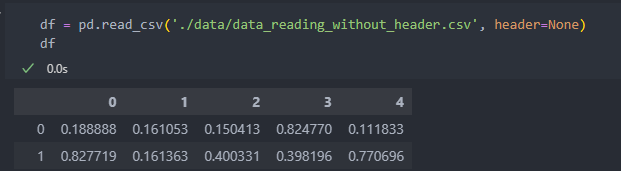
컬럼이 숫자로 되어 있는 것을 바꿔보자.
데이터.columns 는 컬럼명을 보여주는데, 여기에 모든 컬럼명의 길이만큼 모두 바꾸면 된다.
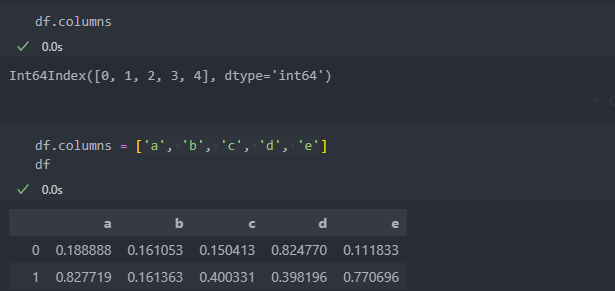
모든 컬럼명이 아니라 일부 컬럼명을 바꾸려면 rename({'기존':'변경', '기존2':'변경2'})함수를 써서 dict()형으로 넣어주면 된다.
axis = 0은 인덱스명의 행을, axis = 1 컬럼명의 행을 나타낸다.
그리고 rename()은 뷰를 반환하기에, 변수를 지정하여 받거나 inplace=True를 사용하여 변경한다.
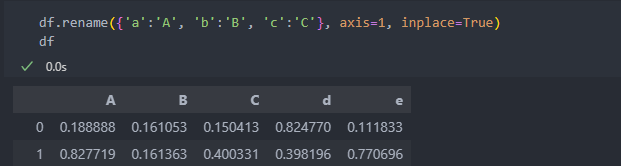
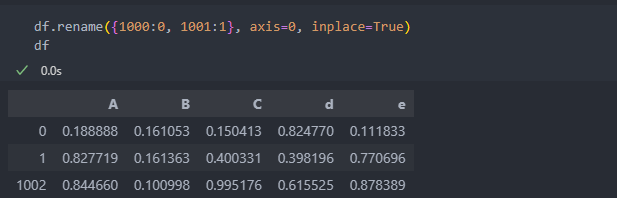
데이터의 길이는 총 1000이다.
0부터 시작하는데 인덱스의 시작을 1000으로 하려고 한다.
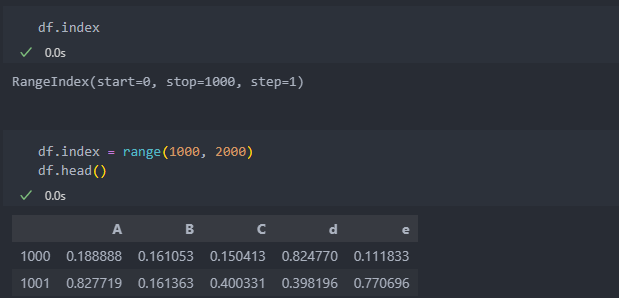
인덱스도 개별적으로 수정이 가능하다.
슬라이싱
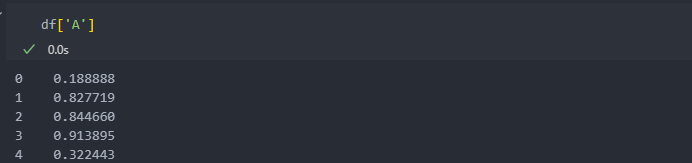
하나의 커럼을 인덱싱 할 때,
array 형식으로 불러오거나
DataFrame 형식으로 불러 올 수 있다.(리스트로 불러오기)
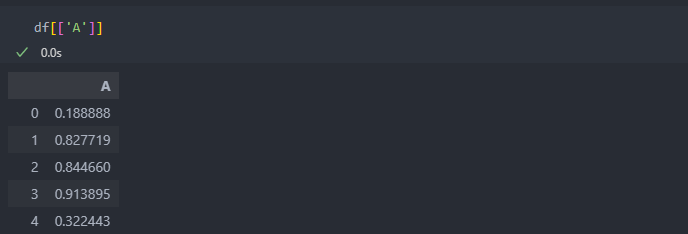
array 형식은 2개 이상은 불러올 수 없다.
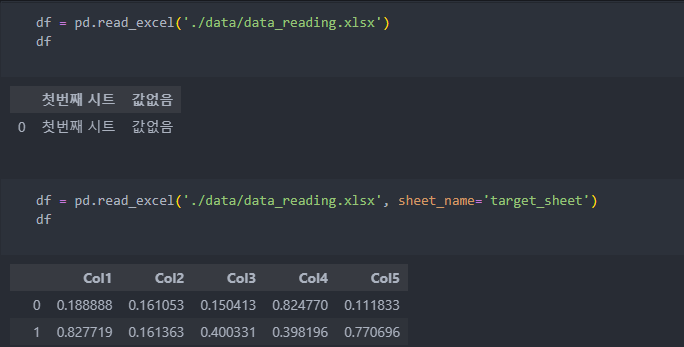
excel 파일
엑셀 파일은 sheet로 나누어져 있어서 첫 번째 시트에 정보가 없을 수도 있으니 잘 보고 불러오도록 한다.
'sheet_name'인자로 지정해서 불러오면 된다.
한 엑셀 파일에 여러 시트로 나누어져 있다면 iterator 방법으로 불러오면 되는데, list comprehension을 다룰 때 다시 보도록 하겠다.
