
하나 이상의 데이터를 합쳐보자.
1. merge
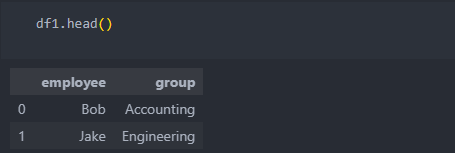
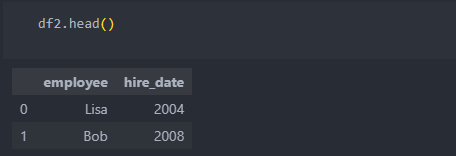
두 개의 데이터를 합칠 때, 중복되어 key가 되는 컬럼이 있을 때 사용한다.
기본적으로 python은 키가 될 수 있는 컬럼을 자동으로 찾아서 합치며, 옆으로 이어 붙일 때 자주 사용된다.
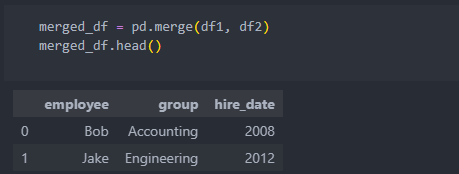
on, left_on, right_on
자동으로 하게 되면 오류가 나거나 원하는 컬럼명을 기준으로 나뉘지 않을 수 있으니 직접 지정하는 습관이 좋다.
'on'은 위와 같이 컬럼명이 같을 때, 그 컬럼을 기준으로 합칠 때 쓴다.
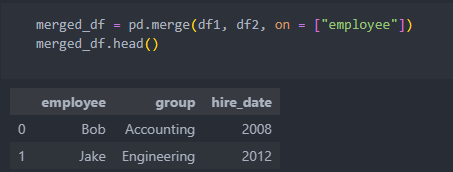
'left/right_on'은 합칠 수 있는 컬럼은 존재하나 컬렴명이 다를 때 사용한다.
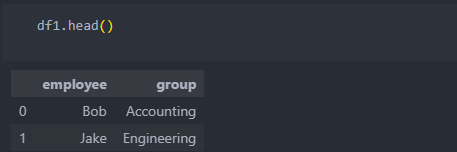
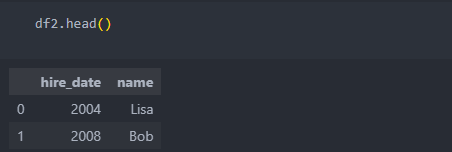
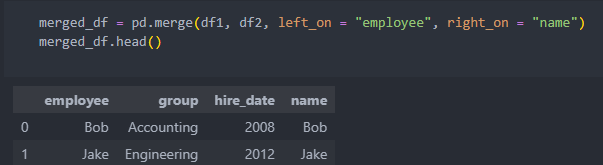
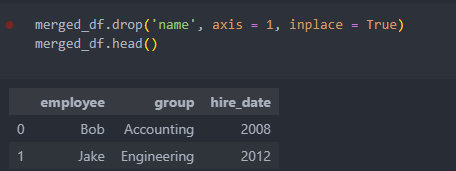
컬럼명이 다르면 합치고 나서도 각각의 컬럼명이 살아 있어서 하나의 컬럼을 삭제하여 사용한다.
axis = 1 은 아래 행방향이며 0은 옆 열방향이다.
2. concat
merge와 달리 아래로 합칠 때 자주 사용되며,
merge는 두 개의 데이터만 합칠 수 있었지만 concat는 여러 개의 데이터도 한 번에 합칠 수 있다.
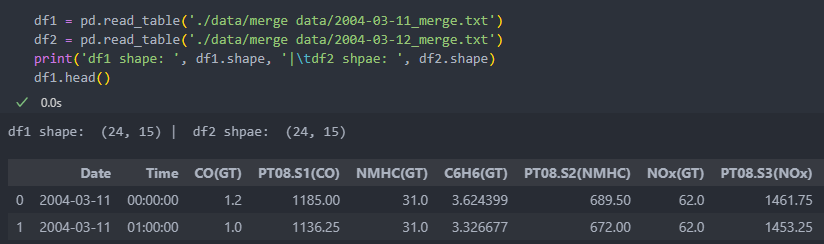
두 개의 데이터의 shape를 보며 합쳐보자.
txt 파일 24행 15열 데이터 2개를 read_table로 불러 와서 리스트 안에서 합친다.
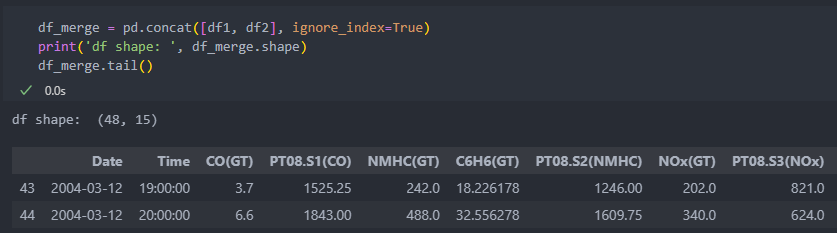
'ignore_index=True'는 합칠 때 인덱스의 번호를 0부터 재설정 할 것인지 정하는 것이다.
True로 설정하여 0부터 인덱스를 재설정 하였다. False라면 기존 데이터의 인덱스 번호를 그대로 가져온다.
3. 여러 데이터를 불러와 합칠 때
날짜만 다른 동류의 여러 데이터를 불러 와야 할 때가 있다.
반복문 혹은 list comprehension으로 불러와 합칠 수 있는다.
반복문의 방식은 느리지만 메모리에 문제가 없다. 왜냐하면 불러와 데이터를 담을 변수가 계속 초기화 되기 때문이다.
list comprehension 방식은 빠르지만 모든 데이터 각각이 다 불러와지기에 메모리 용량을 많이 차지하게 된다.
개별 데이터들
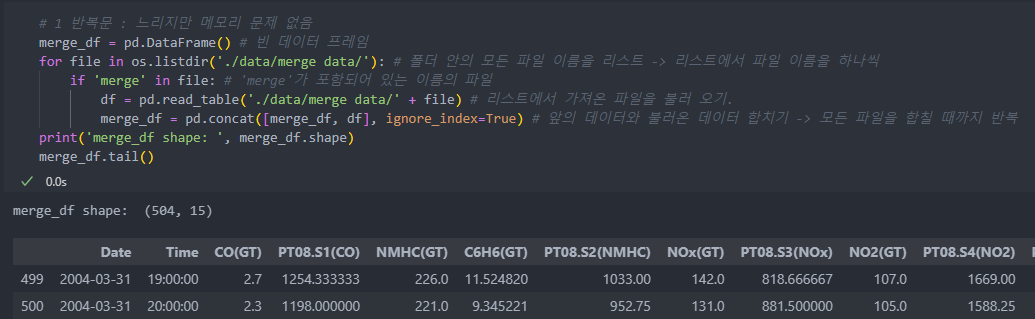
os 모듈의 listdir은 경로 상의 폴더 안 모든 데이터 이름을 리스트에 담아서 반환한다. 이것을 이용하여 파일을 하나씩 모두 불러와서 합친다.
반복문
빈 DataFrame를 생성하여 해당 데이터가 모두 불러올 때까지 더하는 씩이다.
불러올 때를 생각하여, 저장할 때 동류의 파일이라면 공통의 이름을 하나 지정하여 저장하면 쉽게 불러올 수 있다.
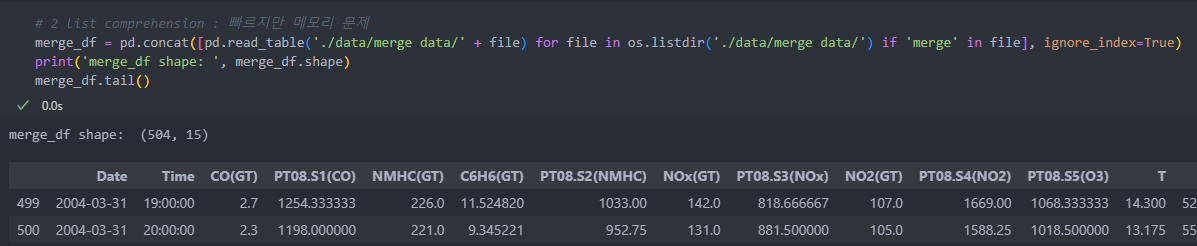
list comprehension
하나씩 불러와 합치는데 합쳐진 데이터와 불러온 데이터 모두가 살아 있어서 메모리를 많이 차지한다.
엑셀 파일
한 엑셀 파일 안에 여러개의 sheet를 불러올 때도 반복문과 list comprehension 방법으로 불러온다.
기존에는 'xlrd'를 사용하였지만 파이썬이 3.9이상 버전에서는 호환성의 문제가 있다. 그래서 openpyxl을 쓰도록 하자.
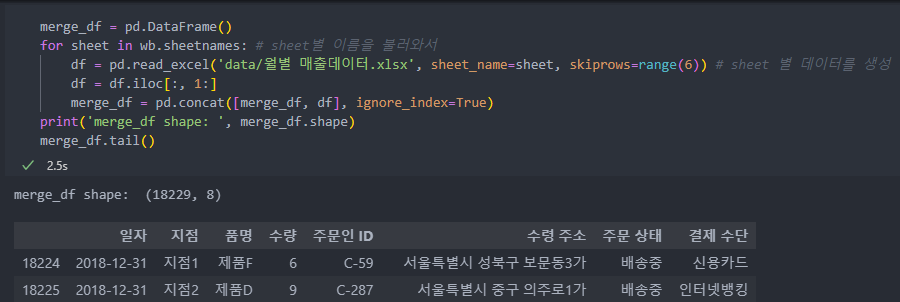
openpyxl.load_workbook(경로+파일 이름)을 통해서 sheet의 이름을 순서대로 가져오고, 순서대로 가져온 이름을 이용하여 데이터를 불러와서 합친다.

반복문
방법은 개별 데이터들을 합칠 때와 같다.
skiporws인자가 하나 추가 되었는데, 엑셀 파일의 정보 부분이 7번째 줄부터 시작되어 6번째까지는 가져오지 않겠다는 것이다.
또한 2번째 열부터 정보가 시작되기에 iloc를 통해서 정보가 있는 부분만 가져오도록 한다.
list comprehension
반복문과 동일하다.

