
데이터가 나누어 저장된 경우
- 지도 학습의 경우 feature와 label이 하나의 통합된 데이터 집합으로 되어 있어야 한다.
- 데이터가 큰 경우 대부분 두 개 이상으로 나눠져 있어 통합해야 하는 전처리를 수행해야 한다.
ex) 센서, 로그, 거래 데이터 등(ID, 날짜, 시간, 지역 등에 따라 분할되어 있음)
파일 자체가 나뉘어 저장된 경우(ex. 날짜/시간별 파일)
pandas.concat([df1, df2, ...])
주요인자:
- ignore_index : True - 새로운 인덱스를 순서대로 할당, False - 기존 인덱스 사용
- axis : 0 - 행 단위로 병함, 1 - 열 단위로 병합
날짜별 데이터들이 나누어져 있는 데이터중 일부이다.
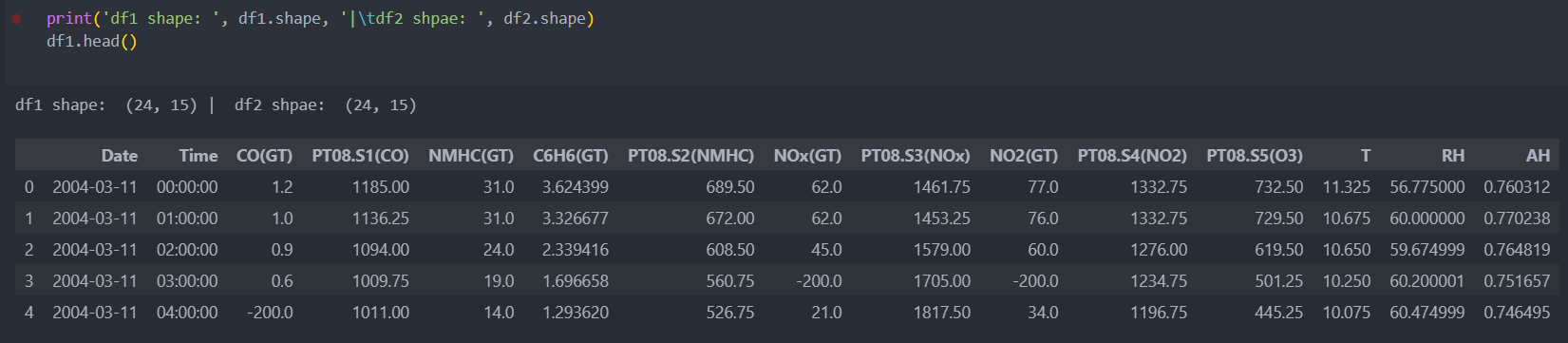
일부가 아니라 모든 파일을 가져와서 데이터를 통합해보자.
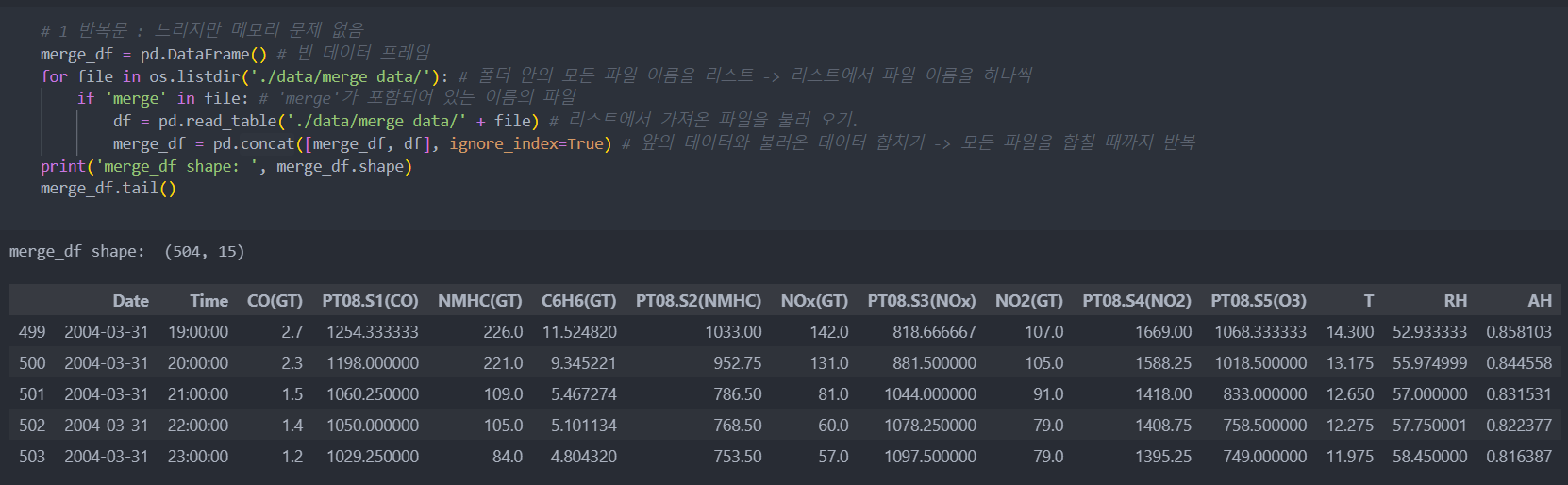
os 모듈의 listdir(경로)는 해당 경로의 파일 폴더 안의 모든 파일의 이름을 리스트로 반환해준다.
이것을 이용하여 파일 이름들을 리스트에 담아 하나씩 불러와서 기존의 데이터와 합칠 것이다.
- for문 사용
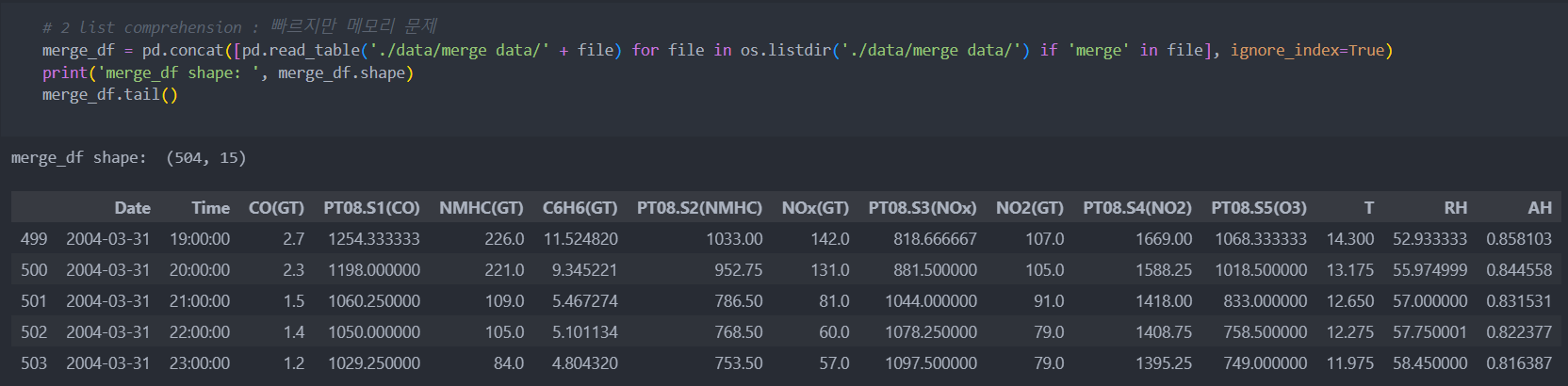
- list comprehension 사용
'key' 변수를 기준으로 나뉘어 저장된 경우(ex. SQL)
'key' 변수 역할을 할 수 있는 컬럼을 확인하고, 레코드의 단위를 명확히 해야 한다.
pandas.merge(df1, df2, 인자...)
주요인자:
- left : 데이터 프레임 1
- right : 데이터 프레임 2
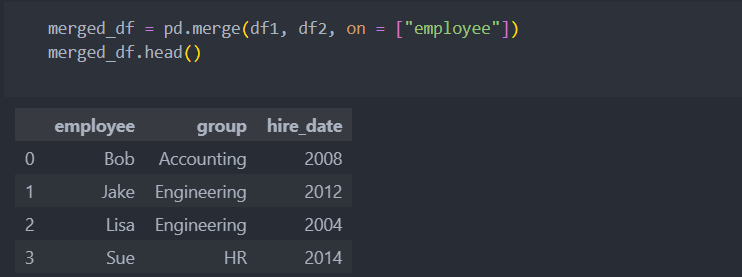
- on: 통합 기준 key 변수(입력하지 않으면 이름이 같은 변수를 key로 자동 설정)
- left_on : 데이터 프레임 1의 key 변수
- rigth_on : 데이터 프레임 2의 key 변수
- left_index : 데이터 프레임 1의 인덱스를 key 변수로 사용할 지 여부(T/F)
- right_index : 데이터 프레임 2의 인덱스를 key 변수로 사용할 지 여부(T/F)
다음 데이터를 합쳐보자.
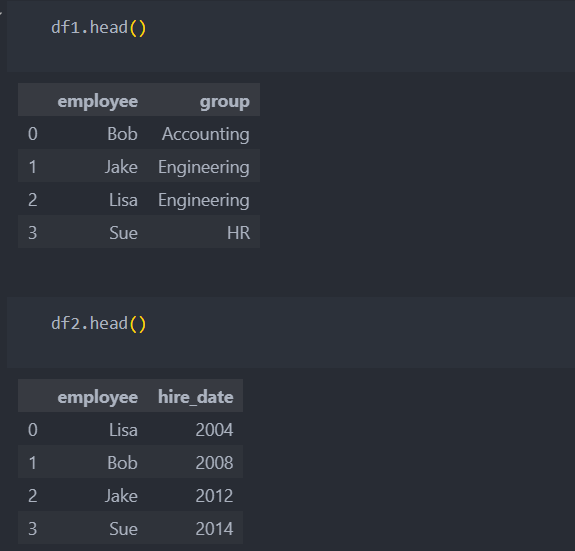
'on'을 명시하지 않은 경우
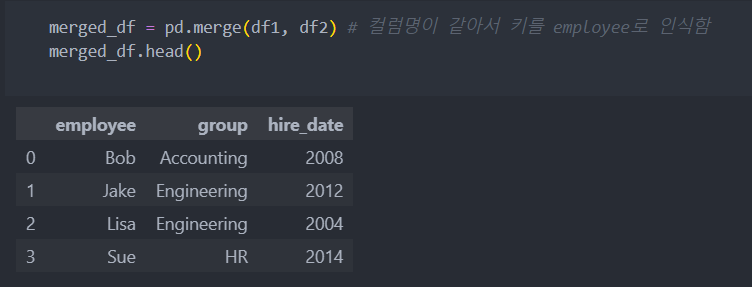
'on'을 명시한 경우
다음의 두 데이터도 합쳐보자.
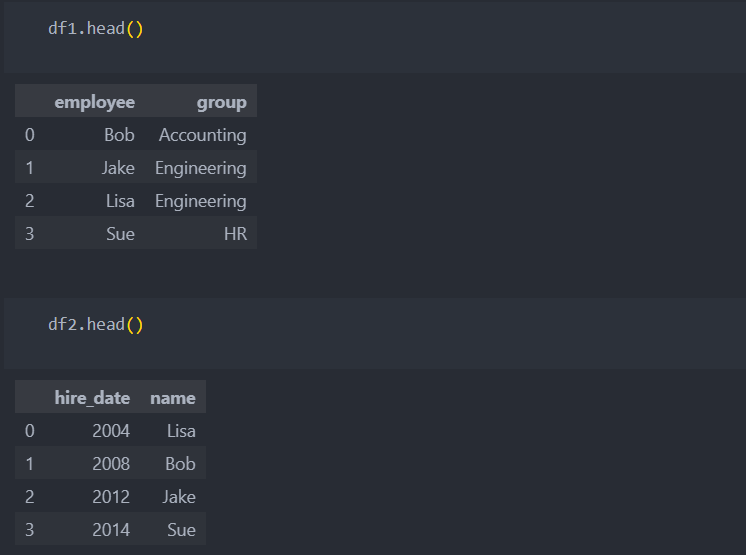
left_on/rigth_on 사용
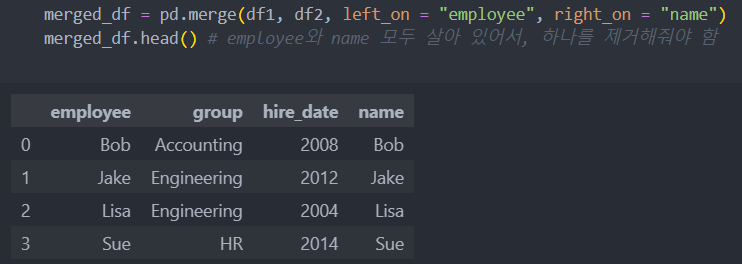
인덱스가 key가 되는 경우(reset_index()를 사용할 수도)
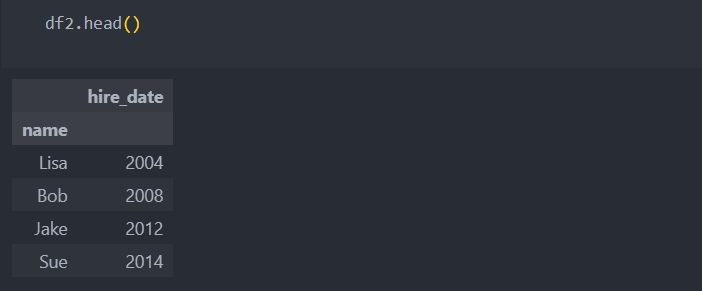
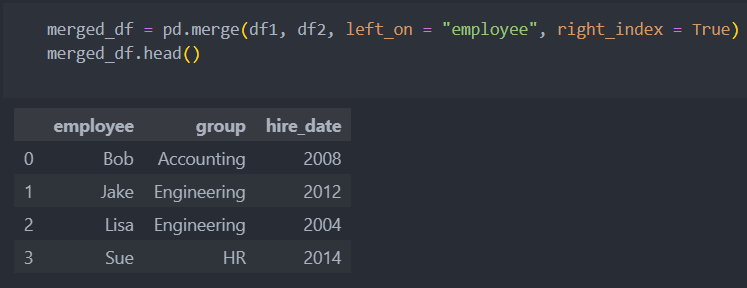
인덱스명으로 합쳐야 할 경우

데이터 굽는 타자기