
문제 정의
고객 로그 데이터를 바탕으로 이탈한 고객과 이탈하지 않은 고객이 보이는 주요 행동 패턴 탐색
참고 : 빈발 시퀀스 탐색
- 이탈 고객과 비이탈 고객 분리
- 이탈 고객과 비이탈 고객 데이터 내 주요 행동 패턴 추출
- 주요 행동 패턴의 등장 비율 비교
고객 여정 데이터가 있고
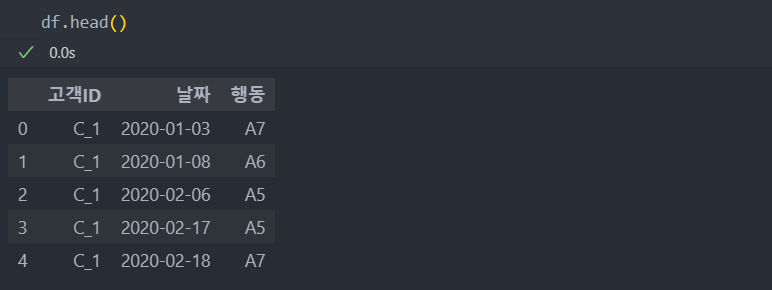
행동의 종류는 다음과 같은 데이터를 가지고 분석을 해보자.

순서에 따른 행동의 시퀀스 데이터이기에 순서가 중요하다.
날짜를 기준으로 정렬을 한다.
1. 이탈 고객과 비이탈 고객 분리
이탈한 고객과 비이탈한 고객의 행동 패턴을 파악하기 위해 먼저 두 고객을 분리한다.
'이탈' 행동을 한 고객과 아닌 고객으로 분리시킨 후,
'이탈' 고객들의 행동 데이터와 '비이탈' 고객들의 행동 데이터를 각각 만든다.
#1 이탈/비이탈 고객 ID 찾기
churn_ID = df.loc[df['행동'] == '이탈', '고객ID'].unique()
not_churn_ID = df.loc[~df['고객ID'].isin(churn_ID), '고객ID'].unique()
#2 이탈/비이탈 고객별 데이터 분리
churn_df = df.loc[df['고객ID'].isin(churn_ID)]
not_churn_df = df.loc[df['고객ID'].isin(not_churn_ID)]그리고 고객별 행동 순서(시퀀스)를 생성한다.
# 고객별 시퀀스 생성
churn_action_sequence = churn_df.groupby(['고객ID'])['행동'].apply(np.array)
not_churn_action_sequence = not_churn_df.groupby(['고객ID'])['행동'].apply(np.array)2. 이탈 고객과 비이탈 고객 데이터 내 주요 행동 패턴 추출
순서를 고려한 항목 집합으로부터 규칙 생성을 지원하는 라이브러리가 없기에 직접 함수를 만들어야 한다.
1. 특정 항목 집합에서 특정 패턴이 발생했는지 윈도우 내 크기 'L'에 따른 T/F 여부를 반환해주는 함수
from itertools import product # 조합의 모든 경우의 수
# 특정 record에 특정 pattern이 발생했는지 여부.
def contain_pattern(record, pattern, L): #
output = False # 미발생으로 초기화
if set(record) & set(pattern) != set(pattern): # pattern에 포함된 모든 아이템 집합이 record에 포함된 아이템 집합에 속하지 않으면
return False
else:
# 패턴에 속한 개별 아이템에 대한 위치를 미리 구하기
pattern_index_list = [np.where(record == item)[0] for item in pattern]
## 가능한 모든 조합에서 위치 간 거리가 L이하면 True를 반환 예시
# record = [A, B, C, A, C, C], pattern = [A, B], L = 1
# A의 위치: [0, 3], B의 위치: [1]
# 가능한 모든 조합: [0, 1], [3, 1]
# 가능한 모든 조합의 거리 차이: [1 - 0, 1 - 3] 중에 0번째 요소는 만족하므로 True
for pattern_index in product(*pattern_index_list):
distance = np.array(pattern_index)[1:] - np.array(pattern_index)[:-1] # 패턴 뒤의 값 - 앞의 값 = 거리
if sum((distance <= L) & (distance > 0)) == (len(pattern_index) - 1): # distance는 L보다는 작거나 같아야 하고 / 거리는 음수가 아니어야 하고 최소 0보다는 커야 한다.
output = True
break
return output2. 1번 T/F 반환하는 함수를 통해 최대빈발하는 시퀀스 아이템을 찾는 함수
def find_maximum_frequent_sequence_item(item_set, sequence_data, min_support = 0.01, L = 1):
queue = [] # 탐색할 대상을 넣을
maximum_frequent_sequence_item = [] # 최대빈발패턴을 담을 리스트
# 유니크한 아이템 집합에 대해, min_support가 넘는 아이템들만 queue에 추가시킴
for item in item_set: # 방문 페이지
occurence = sequence_data.apply(contain_pattern, pattern = [item], L = L).sum() # sequence_data: 고객 ID별 방문 페이지 ndarray / [item] 각 시퀀스 -> 시퀀스가 몇 번 등장했는지 횟수 반환
if occurence / len(sequence_data) >= min_support: # min_support : 시퀀스의 등장 비율(기준=1%)
queue.append([item])
while queue:
current_pattern = queue.pop()
check_maximum_frequent = True # 모든 자식 집합이 min_support를 넘기지 않으면 True를 유지
for item in item_set:
occurence = sequence_data.apply(contain_pattern, pattern = current_pattern + [item], L = L).sum() # current_pattern에 item을 추가하였을 때 최대빈발패턴의 여부 확인하기 위한
if occurence / len(sequence_data) >= min_support: # min_support를 넘는 패턴을 queue에 추가 / 추가하였을 때 여전히 min_support보다 높은 값을 가지는 최대빈발패턴이라면 item을 추가하기 전의 occurence는 최대빈발패턴이 아니게 된다.
check_maximum_frequent = False
queue.append(current_pattern + [item]) # 기존의 패턴을 'pop'하였기에 제외시키고, 기존 패턴에 item을 추가하여 'append'시킨다. / 계속 item을 추가하여 최종 최대빈발패턴이 나올 때까지 while문을 동작시킨다.
if check_maximum_frequent and len(current_pattern) > 1: # 기존의 패턴이 최대빈발패턴 이라면 / 패턴의 길이가 단 하나의 아이템이라면 패턴이라고 보기 어렵다.
maximum_frequent_sequence_item.append(current_pattern) # 'pop'으로 꺼낸 패턴이 최종적으로 최대빈발패턴이라면 maximum_frequent_sequence_item 'append'한다.
return maximum_frequent_sequence_item3. 2번 함수에서 반환하는 최대빈발패턴 시퀀스 아이템을 통해 시퀀스의 빈발패턴을 찾는 함수
def generate_association_rules(maximum_frequent_sequence_item, sequence_data, min_support = 0.01, min_confidence = 0.5, L = 1):
# 결과 초기화
result = {"부모":[], "자식":[], "지지도":[], "신뢰도":[]} # DataFrame 형식으로 만들기 쉽다.
for sequence_item in maximum_frequent_sequence_item:
# A -> B에서 A, B를 모두 포함하는 가짓 수 co_occurence 계산
co_occurence = sequence_data.apply(contain_pattern, pattern = sequence_item, L = L).sum()
support = co_occurence / len(sequence_data) # 지지도
if co_occurence > min_support: # co_occurence가 최소 지지도보다 높은 것들만
for i in range(len(sequence_item)-1, 0, -1): # 한 아이템 집합에 대해, 부모의 크기를 1씩 줄여나가는 방식으로 부모와 자식 설정
antecedent = sequence_item[:i] # i 앞의 아이템 = 부모 집합
consequent = sequence_item[i:] # i 뒤의 아이템 = 자식 집합
antecedent_occurence = sequence_data.apply(contain_pattern, pattern = antecedent, L = L).sum() # 부모 집합의 발생 비율만
confidence = co_occurence / antecedent_occurence # 신뢰도
if confidence > min_confidence: # 최소 신뢰도보다 높다면
result['부모'].append(antecedent)
result['자식'].append(consequent)
result['지지도'].append(support)
result['신뢰도'].append(confidence)
return pd.DataFrame(result)이 함수를 바탕으로 행동 패턴을 추출해보자.
#1 비이탈 고객 행동 패턴 찾기
maximum_frequent_sequence_item = find_maximum_frequent_sequence_item(action_set, not_churn_action_sequence, min_support = 0.1, L = 1)
not_churn_rules = generate_association_rules(maximum_frequent_sequence_item, not_churn_action_sequence, min_support = 0.1, min_confidence = 0.1, L = 1)
#2 이탈 고객 행동 패턴 찾기
maximum_frequent_sequence_item = find_maximum_frequent_sequence_item(action_set, churn_action_sequence, min_support = 0.1, L = 1)
churn_rules = generate_association_rules(maximum_frequent_sequence_item, churn_action_sequence, min_support = 0.1, min_confidence = 0.1, L = 1)이탈 고객 행동 패턴
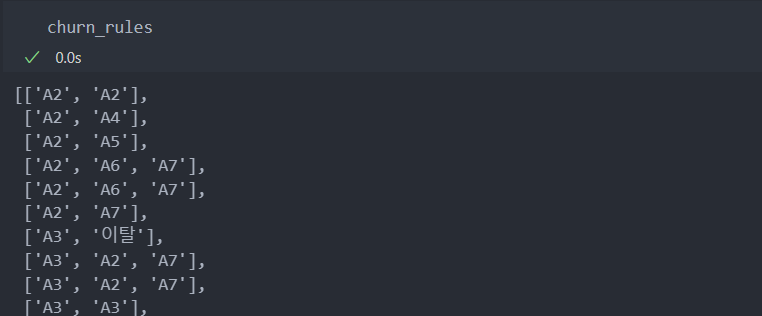
비이탈 고객 행동 패턴
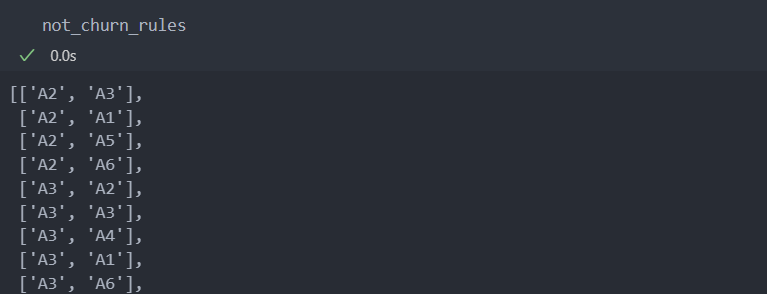
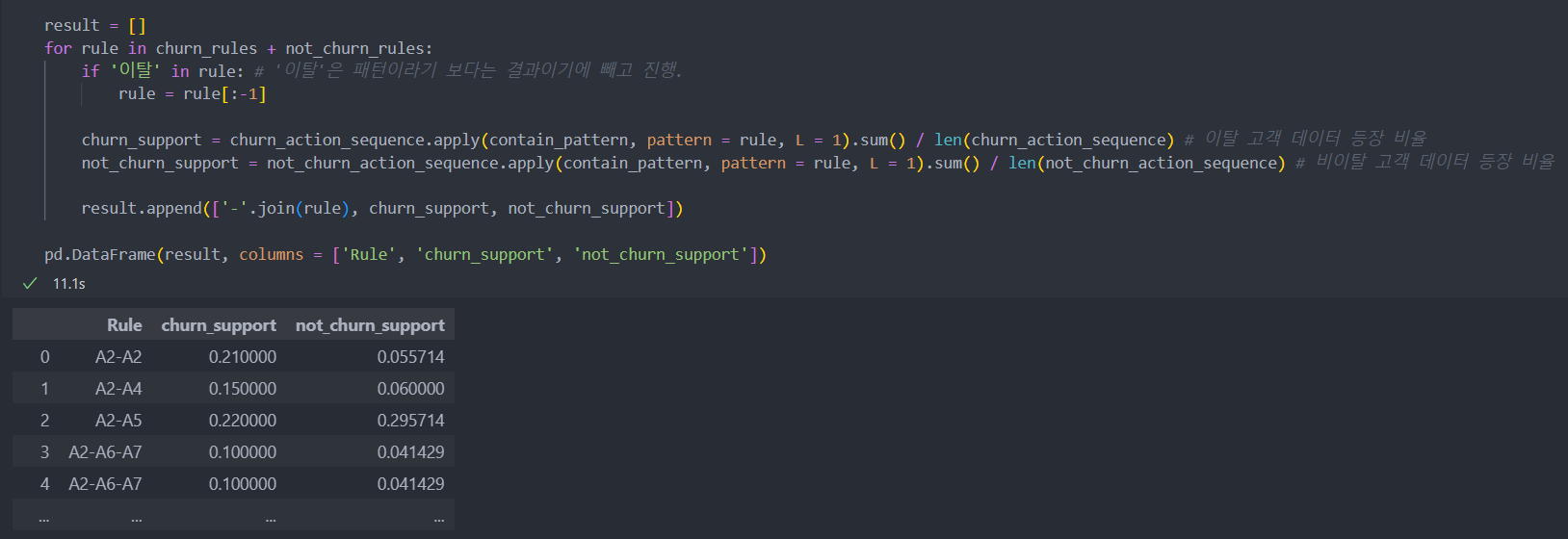
3. 주요 행동 패턴의 등장 비율 비교
이탈/비이탈 고객들의 행동 패턴의 지지도 비율 확인

데이터 굽는 타자기