
데이터가 나누어 저장된 경우
- 지도 학습의 경우 feature와 label이 하나의 통합된 데이터 집합으로 되어 있어야 한다.
- 데이터가 큰 경우 대부분 두 개 이상으로 나눠져 있어 통합해야 하는 전처리를 수행해야 한다.
ex) 센서, 로그, 거래 데이터 등(ID, 날짜, 시간, 지역 등에 따라 분할되어 있음)
중복 데이터 통합
1:N 병합인 경우에 사용되며 거래 데이터 및 로그 데이터와 병합하는 경우에 사용(ex. 고객 ID별 구매 금액)
중복 레코드를 포함하는 데이터를 요약한 후 병합
DataFrame.groupby()
조건부 통계량(조건에 따른 대상의 통계량) 계산
주요 인자:
- by : 조건 변수(컬럼명) / (by=df['고객ID'] or df['고객ID'] / 'by=' 생략 가능)
- as_index(default=True) : 조건 변수를 인덱스로 쓸 것인지 여부(T/F)
- 조건 변수는 다중 변수도 가능
고객의 정보와 구매 금액 데이터를 합치려고 하는데, 한 고객이 여러번 구매했을 가능성을 염두해 두고 진행해야 한다.
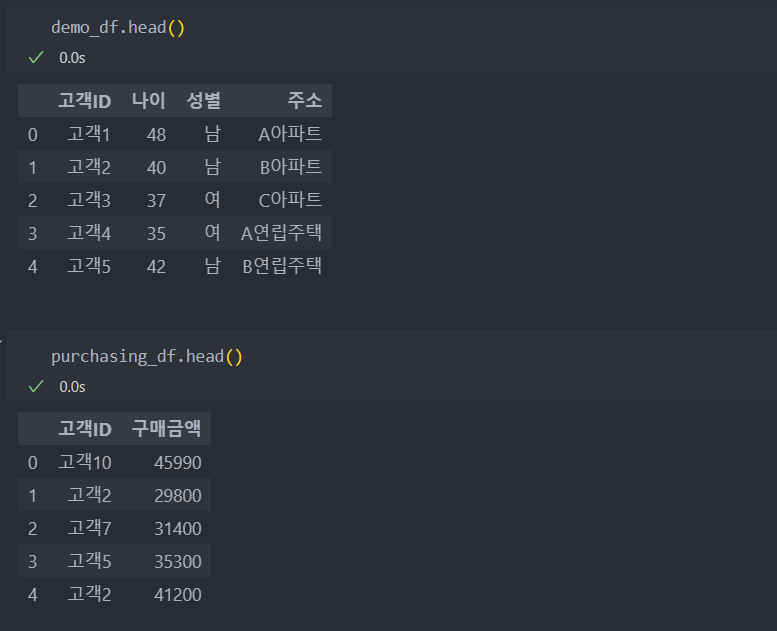
groupby()를 이용하여 고객ID별 구매 금액을 모두 합친다.
groupby(default : as_index=True)는 반환을 Series로 반환을 하며 그 name은 '구매금액'이다.
이를 고객 정보에 붙이기 위해 rename으로 '구매금액합계'라고 이름을 바꾼다.(실제로 구매금액의 합계)
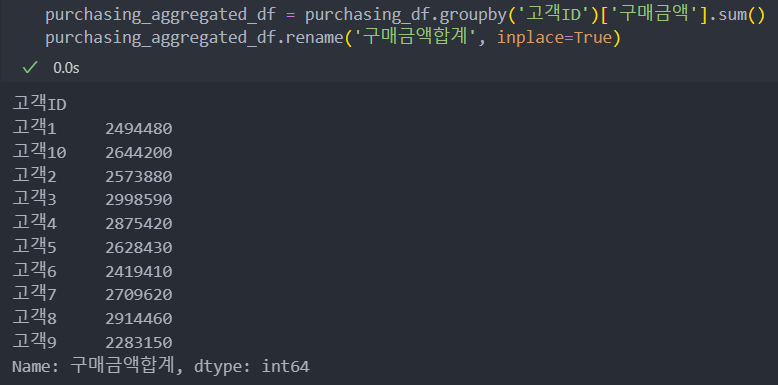
merge는 DataFrame와 Series도 병합이 가능하다.
아래와 같이 공통된 key인 '고객 ID'를 기준으로 병합한다.(left:컬럼, right:인덱스)
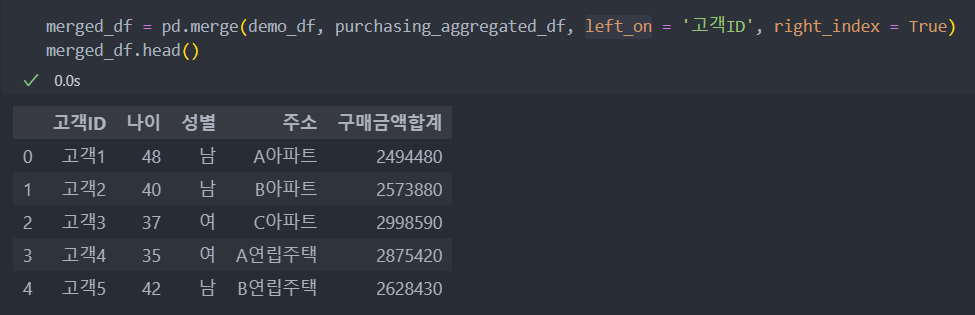
to_dict()를 사용하면 replace()로 '하나'의 컬럼을 붙일 때 유용하다.
- to_dict : Series의 인덱스를 'key'로 data를 'value'로 하는 dict() 자료형으로 변환한다.
- replace(dict()자료형) : 'key'에 해당하는 데이터를 'value'로 데이터를 교체한다.

데이터 굽는 타자기