
데이터가 나누어 저장된 경우
- 지도 학습의 경우 feature와 label이 하나의 통합된 데이터 집합으로 되어 있어야 한다.
- 데이터가 큰 경우 대부분 두 개 이상으로 나눠져 있어 통합해야 하는 전처리를 수행해야 한다.
ex) 센서, 로그, 거래 데이터 등(ID, 날짜, 시간, 지역 등에 따라 분할되어 있음)
거리 기반 병합이 필요한 경우
지역이 포함되는 문제에서 주소나 위치 변수 등을 기준으로 거리가 가까운 레코드 및 관련 통계치를 통합해야 하는 경우.
- 각 데이터에 포함된 '레코드 간 거리'를 나타내는 거리 행렬 생성
- 거리 행렬의 행 혹은 열 기준 최소 값을 가지는 인덱스를 바탕으로 이웃 탐색
- 이웃을 기존 데이터에 통합
scipy.spatial.distance.cdist
두 개의 행렬을 바탕으로 거리 행렬을 반환하는 함수
주요인자
- XA : 거리 행렬 계산 대상인 행렬로, 함수 출력의 '행'에 해당
- XB : 거리 행렬 계산 대상인 행렬로, 함수 출력의 '열'에 해당
- metric : 거리 척도('cityblock'(맨하탄), 'correlation', 'cosine', 'euclidean', 'jaccard', 'matching' 등)
ndarray.argsort
작은 값부터 순서대로 데이터의 위치(인덱스)를 반환하는 함수로, 이웃을 찾는데 주로 활용
주요인자
- axis(행렬일 경우) : 0이면 열별 위치, 1이면 행별 위치를 반환
라이브러리 haversine
위도/경도로 거리를 구하는 라이브러리로 '거리'를 반환한다.
- haversine(A위치, B위치, unit='km') # unit : 거리 단위
지하철 위치와 아파트 주소와 매매 금액의 데이터를 확인해보자.
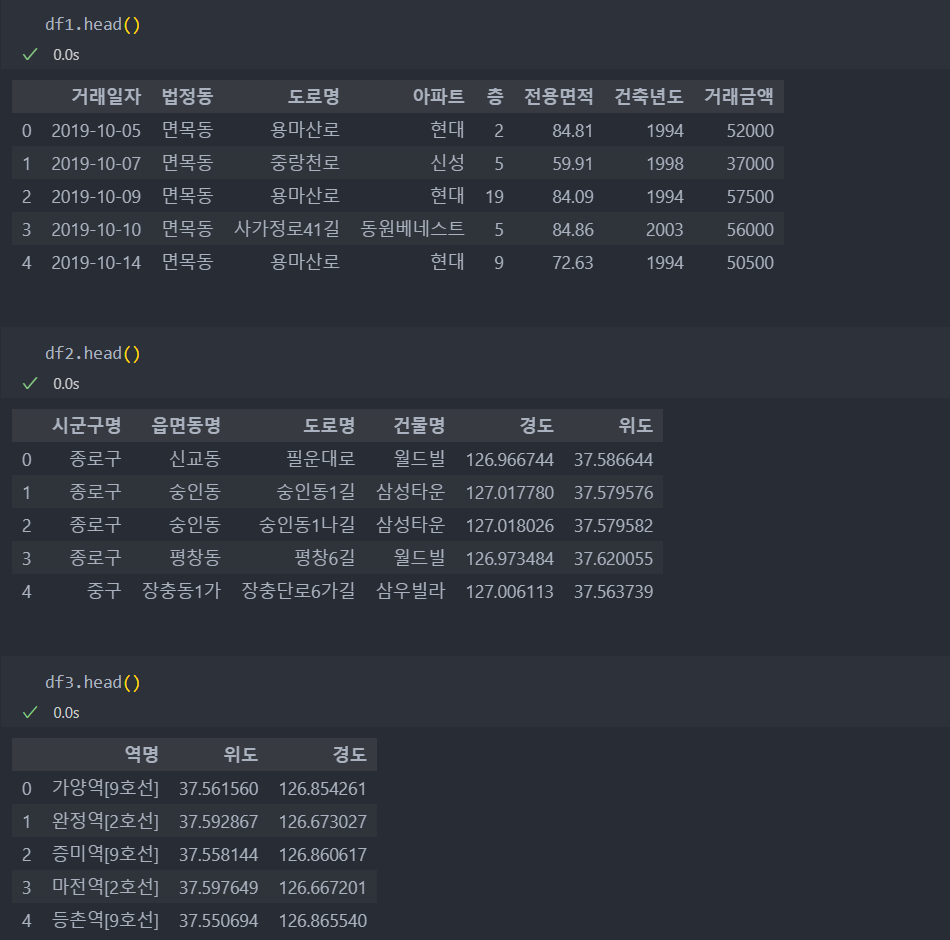
먼저 아파트 정보 df1, df2를 merge하여 하나의 데이터 프레임으로 만든다.
key는 다중 입력이 가능하다.
df = pd.merge(df1, df2,left_on = ['법정동', '도로명', '아파트'], right_on = ['읍면동명', '도로명', '건물명'])그리고 거리를 계산하기 위한 위도/경도 데이터를 새로운 변수에 생성한다.
이 데이터를 바탕으로 df 정보에 가장 가까운 지하철 역과 거리 정보를 merge할 것이다.
# 거리 행렬 생성을 위한 컬럼(위도/경도) 추출 / haversine를 이용하여 거리를 구할 예정
df_location = df[['경도', '위도']]
df3_location = df3[['경도', '위도']]scipy의 cdist와 haversine를 사용하여 '아파트의 위도/경도'와 '지하철 역의 위도/경도' 사이의 모든 거리를 구하고
# 거리 행렬 생성
from scipy.spatial.distance import cdist
from haversine import haversine
# 각 아파트와 각 역 사이의 모든 거리 행렬 생성
# df_location 변수를 앞에 둔 이유는 df에 새로운 컬럼을 생성하기 위해 dist_mat의 행을 df의 행과 맞추기 위해
dist_mat = cdist(df_location, df3_location, metric = haversine)
각 아파트별 가장 가까운 지하철 역 거리 '인덱스 번호'를 argsort()를 사용하여 가져온다.
close_subway_index = dist_mat.argsort()[:, 0] # axis = 0이제 가장 가까운 역과 그 거리를 합칠 것이다.
변수 'dist_mat'와 'close_subway_index'의 인덱스는 cdist로 데이터를 생성할 때 df의 인덱스와 일치하는 것을 이용하여,
아파트 위도/경도에서 가장 가까운 지하철 역 인덱스에 해당하는 '역명'과
아파트 위도/경도에서 가장 가까운 지하철 역 '거리'를 추가로 합친다.


데이터 굽는 타자기