
데이터가 나누어 저장된 경우
- 지도 학습의 경우 feature와 label이 하나의 통합된 데이터 집합으로 되어 있어야 한다.
- 데이터가 큰 경우 대부분 두 개 이상으로 나눠져 있어 통합해야 하는 전처리를 수행해야 한다.
ex) 센서, 로그, 거래 데이터 등(ID, 날짜, 시간, 지역 등에 따라 분할되어 있음)
참조 데이터가 필요한 경우의 병합
도로명 주소/지번 주소, 회원명/회원번호 등 일정한 패턴이 없이 포맷이 다른 경우에는 컬럼 값을 참조 데이터를 이용하여 변경
통합에 필요한 컬럼의 데이터들을 바꿔야 할 경우.(지번 주소 -> 도로명 주소 등)
데이터 포멧이 다른 두 데이터를 참조 데이터를 바탕으로 통합해보자.
먼저 포멧이 다른 두 데이터는 다음과 같고 df1은 2020년도 df2는 2011년도 자료다.
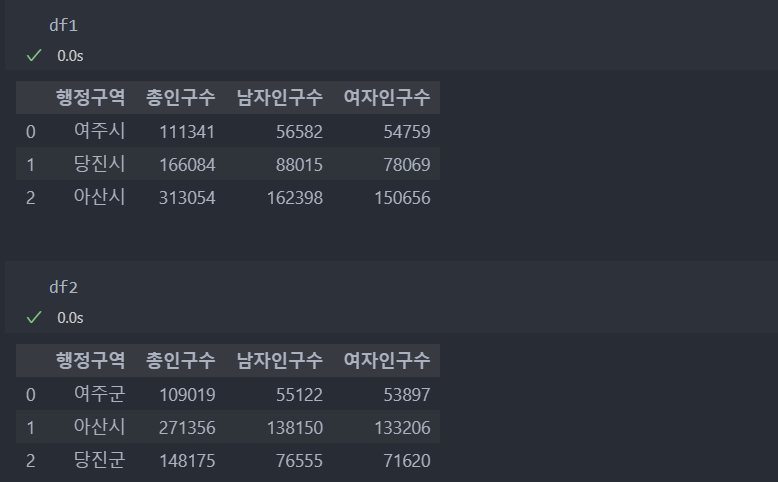
df2 자료는 '군'에서 '시'로 승급되기 이전의 자료로 통합하기 전에 전처리를 해야 한다.
Series.to_dict()
- Series의 index를 'key'로 data를 'value'로 1:1 매칭하여 dict()자료형으로 변환할 때 사용.
'승격전' 컬럼을 인덱스로 설정하고 '승격후'의 값을 가져와서 dict()자료형으로 변환한 것을 참조하여 2011년과 2020년 자료를 합칠 것이다.


to_dict()를 이용하여 df2의 '행정구역'의 데이터를 replace()를 사용하여 바꿀 것이다.
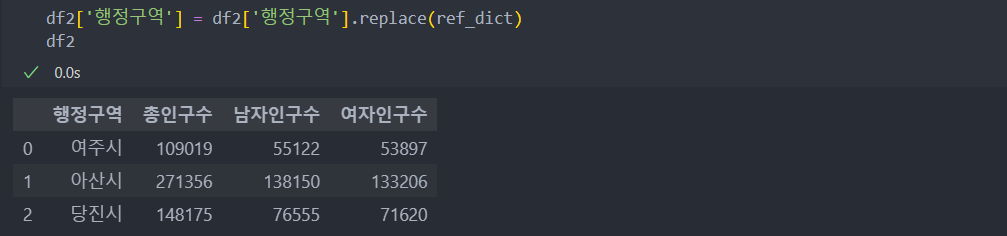
두 데이터의 '행정구역' 순서가 다르고, 두 데이터의 컬럼명이 같아서 그대로 합칠 수는 없다.
그래서 '행정구역' 컬럼을 set_index()를 사용하여 인덱스로 변환하고, 두 데이터의 인구수 부분에 add_prefix()를 사용하여 년도를 붙여 구분할 수 있도록 한다.
- add_prefix('text') : '컬럼명' -> 'text 컬럼명'과 같이 컬럼 명을 바꿔준다.(add_suffix('text') : 컬럼명 뒤에 'text'가 붙는다)
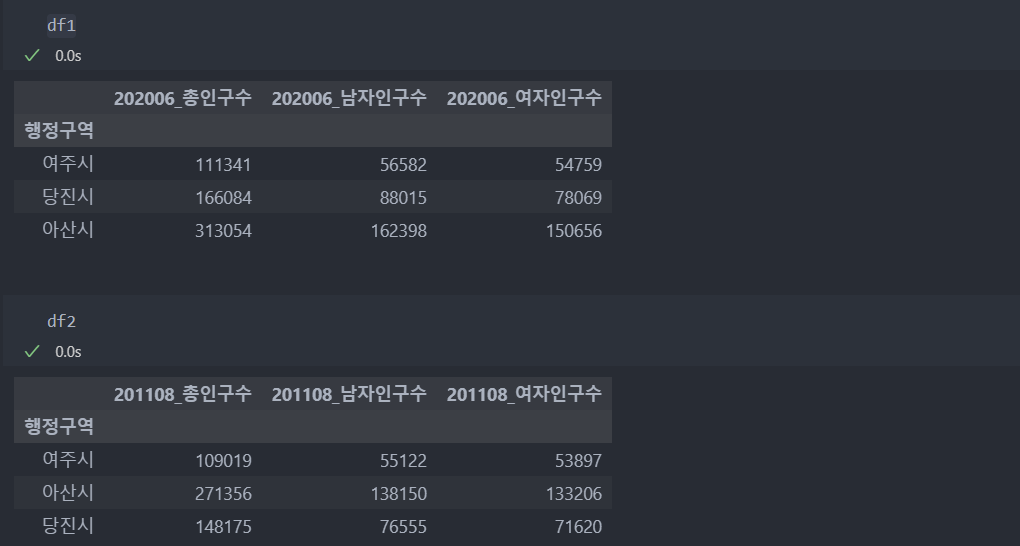
# df1과 df2에 있는 변수명이 모두 같으므로, 변수명을 수정해야 함
df1.set_index("행정구역", inplace = True) # 행정 구역 변수명은 바꾸지 않기 위해, 인덱스로 설정
df2.set_index("행정구역", inplace = True) # 행정 구역 변수명은 바꾸지 않기 위해, 인덱스로 설정
df1 = df1.add_prefix("202006_")
df2 = df2.add_prefix("201108_")변환 후 데이터는 인덱스 순서는 다르지만,
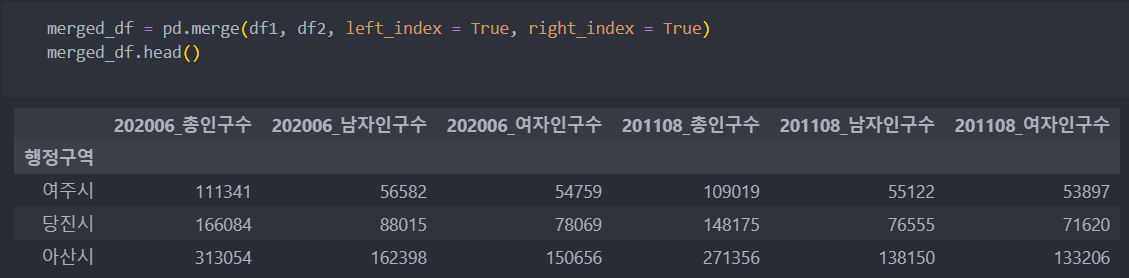
'index명'을 기준으로 merge()를 하게 되면 '같은 index명'을 기준으로 통합이 된다.

데이터 굽는 타자기