
변수 분포 문제
일반화된 모델을 학습하는데 어려움이 있는 분포를 가지는 변수가 있어, 일반화된 모델을 학습하지 못하는 문제 발생.
문제 정의
변수 범위에서 많이 벗어난 아주 작은 값이나 아주 큰 값으로, 일반화된 모델을 생성하는데 악영향을 끼치는 값으로 이상치를 포함하는 레코드를 제거하는 방법
이상치 제거(IQR 활용)
IQR 규칙
IQR = Q3(3사분위수) - Q1(1사분위수)
Q1 - IQR * 1.5보다 작거나 Q3 + IQR * 1.5보다 큰 경우 '이상치'라 판단.
- 변수별로 IQR 규칙을 만족하지 않는 샘플들을 판단하여 삭제
- 직관적이고 사용이 간편
- IQR 단점
-단일 변수만으로 판단하기 어려움(ex. 단일 데이터는 이상치가 아니지만 x, y의 관계에서 이상치가 될 수 있는 경우)
-이상치가 많이 나오는 경우 발생.
numpy.quantile(=numpy.percentile)
Array의 q번째 quantile을 구하는 함수
주요인자
- a: input array(list, ndarray, array...)
- q: quantile(0과 1 사이) / percentile(0과 100 사이)
실습
다음과 같은 데이터를 살펴보자.
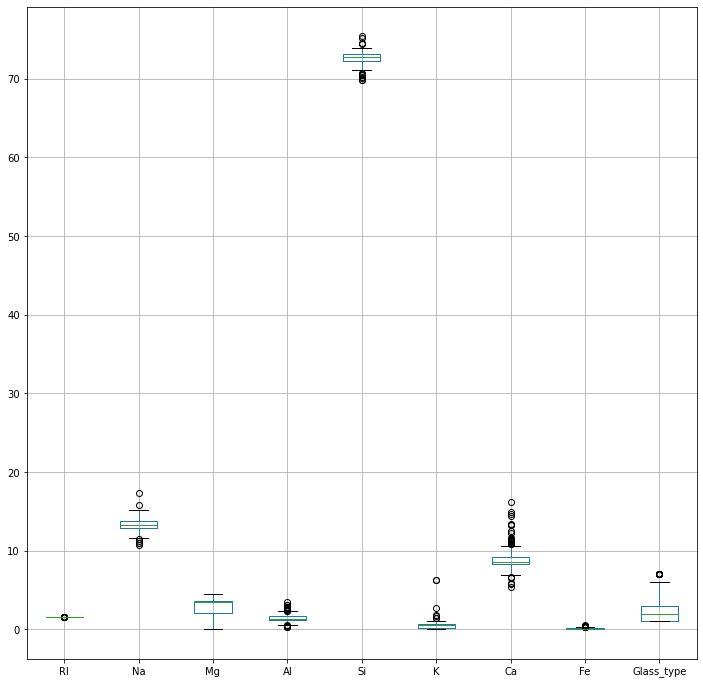
먼저 각 특징(컬럼)별 박스 플롯으로 각각의 IQR을 살펴보자.
각 특징별 스캐일이 달라서 명확하게 보이지는 않는다.
먼저 data와 라벨을 분리하고 학습 데이터와 평가 데이터를 분리한다.
# 특징과 라벨 분리
X = df.drop(['Glass_type'], axis = 1)
Y = df['Glass_type']
# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)이제 각 특징별 이상치를 가려내는 함수를 작성해보자.
import numpy as np
def IQR_rule(val_list): # 한 특징에 포함된 값 (열 벡터)
# IQR 계산
Q1 = np.quantile(val_list, 0.25)
Q3 = np.quantile(val_list, 0.75)
IQR = Q3 - Q1
# IQR rule을 위배하지 않는 bool list 계산 (True: 이상치 X, False: 이상치 O)
not_outlier_condition = (Q3 + 1.5 * IQR > val_list) & (Q1 - 1.5 * IQR < val_list) # min outliers < True < max outliers
return not_outlier_conditionIQR을 적용한 후 DataFrame로 만들면 다음과 같다.
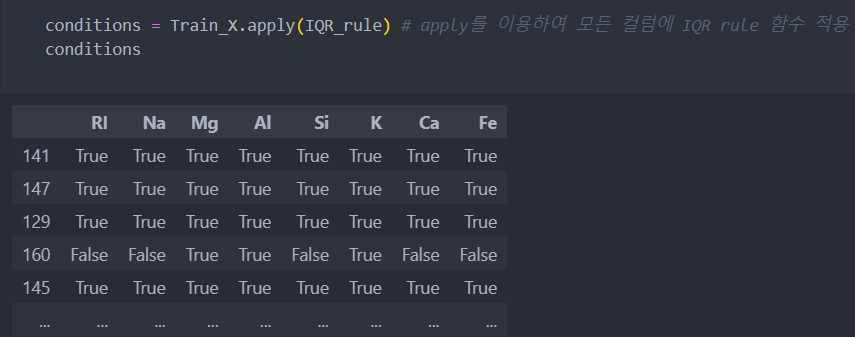
이제 데이터가 모두 True인 (행 기준) 데이터만 가져오도록 한다.
# 하나라도 IQR 규칙을 위반하는 요소를 갖는 레코드를 제거하기 위한 규칙
total_condition = conditions.sum(axis = 1) == len(Train_X.columns) # conditions.sum()을 행으로 더해('True = 1') 컬럼의 길이와 같으면 True를 다르면 False를 행 순서대로 반환
# 이상치 제거
Train_X = Train_X.loc[total_condition] # True인 행만 이상치 제거 '전' data의 shape

이상치 제거 '후' data shape
이상치로 보았을 때 이상치가 30%로 너무 높아 보인다.
그래서 일반적으로는 이상치의 기준을 IQR에 1.5를 곱하지만 더 큰 수를 사용하여 이상치를 줄이는 방법도 있다.


데이터 굽는 타자기