시계열 데이터
각 요소가(시간, 값) 형태로 구성된 데이터로, A의 발생시간 후에 B가 발생한 것을 분석하는 것으로 반드시 시간 및 순서를 고려해야 한다.
엄밀히 말해 시계열 데이터도 시퀀스 데이터에 속하지만,
시계열 데이터의 인덱스는 시간이고 값은 연속형이 주를 이루며 시퀀스 데이터의 인덱스는 순서이고 값은 범주형이 주를 이룬다.
- 시계열 패턴은 모양, 변화에 의한 패턴과 값에 의한 패턴이 있다.
SAX : 시계열 -> 시퀀스
시계열 데이터는 연속형이라는 특징때문에 패턴을 찾으려면 '이산화'가 필요하다.
SAX(symbolic aggregate approximation)을 사용하여 시계열 데이터를 효과적으로 이산화한다.
- 순서 : 윈도우 분할(x축:데이터 분할(윈도우 크기만큼), y축:데이터 크기(윈도우로 분할된 데이터 대표값) -> 윈도우별 대표값 계산 -> 알파벳 시퀀스로 변환
탐색
데이터 보기
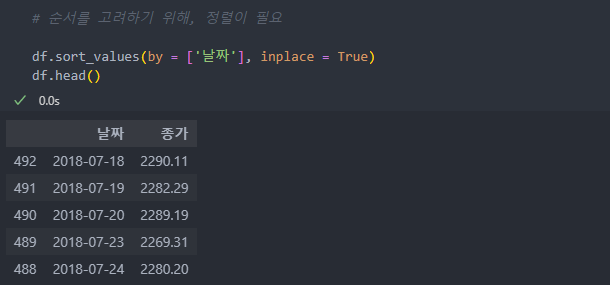
날짜별 코스피 지수 시계열 데이터로 빈발 시계열 탐색을 해보자.
먼저 시간 순서에 따라서 데이터를 정렬해준다.
SAX 적용
윈도우 크기로 분할한 데이터의 평균값 구하기
def segmentation(x, w, a): # x: time series sample, w: window size, a: alphabet size
window_mean = x[:w*int(len(x)/w)].reshape(w, -1).mean(axis = 1) # w 등분으로 데이터를 나누기, 즉 윈도우 크기만큼 데이터 나누어 그 윈도우 크기별 평균값 구하기
if len(x) % w != 0:
window_mean = np.hstack([window_mean, x[w*int(len(x)/w):].mean()]) # 남겨진 부분은 그 부분만 평균해서 window_mean에 추가 / hstack : 행 추가(w로 나눈 나머지 데이터를 추가하는 것)
return window_mean # 윈도우별 평균값 반환윈도우별 대표값 계산하기
def find_break_points(wmv, a): # wmv: window mean vector
break_points = [np.quantile(wmv, (i+1)/a) for i in range(a)] # a 크기만큼 구간을 분할하 -> 후에 분할한 구간 중 어느 구간에 대표값이 존재하는지 파악
return break_points # 분할된 구간을 나누는 지점(구간을 나누는 기준점)각 윈도우별 대표값을 알파벳 시퀀스로 변환
def conversion_window(wv, break_points): # wv: window mean vector
alphabet_sequence = []
for e in wv:
alphabet = 65 # 65 = 'A'
for bp in break_points: # break_points의 크기는 오름차순으로 정렬(quantile)되어 있는
if e < bp: # 구간을 나누는 지점보다 대표값이 작은 경우 -> 대표값이 입력되어 어느 구간의 포인트에 있는지 확인하고 그 구간을 알파벳으로 정의 -> 대표값은 알파벳으로 구간 정의된다.
alphabet_sequence.append(chr(alphabet))
break
else:
alphabet += 1
return alphabet_sequence # 평균값을 구간별로 나눈 알파벳으로 변환된 데이터 반환이제 코스피 종가 데이터의 값을 가져와서 윈도우 크기만큼, 즉 전체 데이터를 100개만큼 분할하여 그 분할한 평균값을 구해보자.
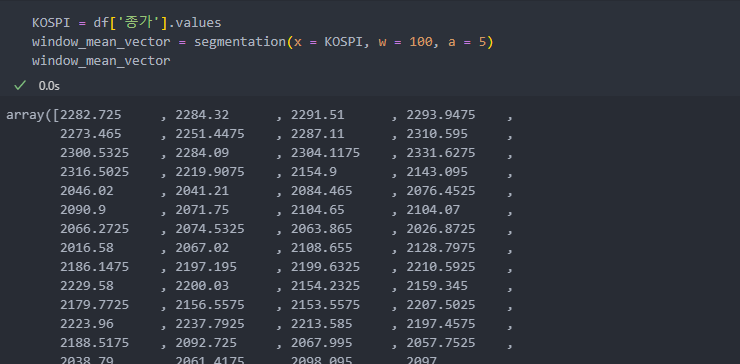
윈도우별 대표값을 찾기 위한 기준점(break point)을 5개로 하여 그 기준점을 찾고,

평균값이 어느 구간에 있는지 확인하여 평균값을 알파벳(대표값이 위치하는 구간)으로 변환한다.(대표값(시계열) -> 알파벳(시퀀스))
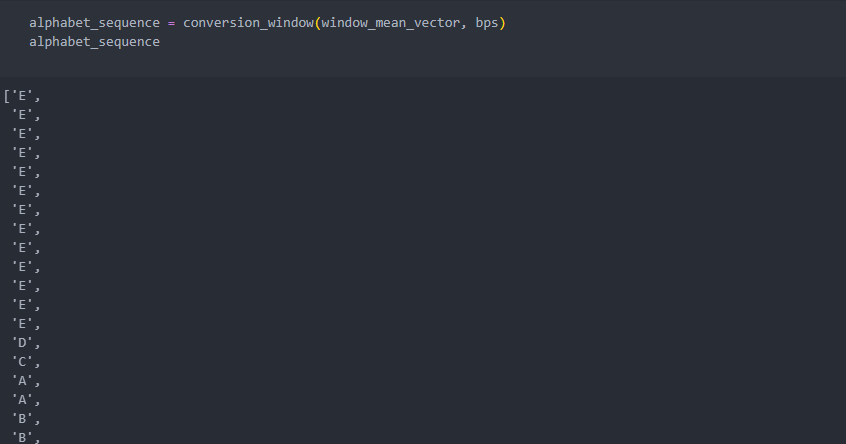
시퀀스로 교체한 데이터는 순서에 따른 데이터이므로 순서를 위해 하나로 묶어준다.

패턴 찾기
순서를 고려한 항목 집합으로부터 규칙 생성을 지원하는 라이브러리가 없기에 직접 함수를 만들어야 한다.
참고 : 시퀀스 패턴 찾기
1. 최대빈발패턴 아이템을 찾는 함수
def find_maximum_frequent_sequence_item(item_set, sequence_data, min_support = 0.01, L = 1):
queue = []
maximum_frequent_sequence_item = []
# 유니크한 아이템 집합에 대해, min_support가 넘는 아이템들만 queue에 추가시킴
for item in item_set:
# 문자열이므로 단순히 count method로 구현 가능
occurence = sequence_data.count(item)
if occurence / (sequence_data.count('-') + 1) >= min_support:
queue.append(item)
while queue:
current_pattern = queue.pop() # 맨 마지막 값 빼기
check_maximum_frequent = True # 모든 자식 집합이 min_support를 넘기지 않으면 True를 유지
for item in item_set:
occurence = sequence_data.count(current_pattern + '-' + item)
if occurence / (sequence_data.count('-') + 1) >= min_support: # min_support를 넘는 패턴을 queue에 추가
check_maximum_frequent = False
queue.append(current_pattern + '-' + item)
if check_maximum_frequent:
maximum_frequent_sequence_item.append(current_pattern)
return maximum_frequent_sequence_item2. 최대빈발패턴 시퀀스 아이템을 통해 시퀀스의 빈발패턴을 찾는 함수
def generate_association_rules(maximum_frequent_sequence_item, sequence_data, min_support = 0.01, min_confidence = 0.5, L = 1):
# 결과 초기화
result = {"부모":[], "자식":[], "지지도":[], "신뢰도":[]}
for sequence_item in maximum_frequent_sequence_item:
# A -> B에서 A, B를 모두 포함하는 가짓 수 co_occurence 계산
co_occurence = sequence_data.count(sequence_item)
support = co_occurence / (sequence_data.count('-') + 1)
if co_occurence > min_support:
for i in range(sequence_item.count('-') -1, 0, -1): # 한 아이템 집합에 대해, 부모의 크기를 1씩 줄여나가는 방식으로 부모와 자식 설정
antecedent = '-'.join(sequence_item.split('-')[:i])
consequent = '-'.join(sequence_item.split('-')[i:])
antecedent_occurence = sequence_data.count(antecedent)
confidence = co_occurence / antecedent_occurence
if confidence > min_confidence:
result['부모'].append(antecedent)
result['자식'].append(consequent)
result['지지도'].append(support)
result['신뢰도'].append(confidence)
return pd.DataFrame(result)두 함수를 사용하여 최대빈발패턴 아이템을 찾고 시퀀스의 빈발패턴을 확인해보자.
#1
maximum_frequent_sequence_item = find_maximum_frequent_sequence_item([chr(65 + i) for i in range(5)], alphabet_sequence, min_support = 0.02, L = 1)
#2
result = generate_association_rules(maximum_frequent_sequence_item, alphabet_sequence, min_support = 0.02, min_confidence = 0.1, L = 1)
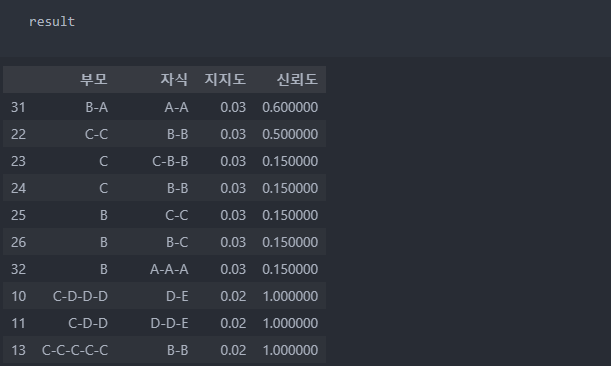
result = result.sort_values(by = ['지지도', '신뢰도'], ascending = False)결과를 확인해보자.
지지도와 신뢰도가 높은 순서대로 보았을 때, 가장 처음의 '부모'(B-A)가 발생한 후에 '자식'(A-A)이 발생하는 지지도는 3%이며 신뢰도는 60%라는 것을 확인할 수 있다.