연관규칙
'A가 발생하면 B도 발생'라는 형태의 규칙으로 '트랜잭션 데이터'를 탐색하는데 사용.
트랜잭션 데이터는 트랜잭션에서 수집한 정보를 말하는 것으로, 거래가 진행된 시간, 발생한 장소, 구매한 항목의 기준 소매 가격, 사용된 지불 방법, 할인(있는 경우), 거래와 관련된 기타 수량 및 품질이 기록.
사례. 월마트에서 영수증 데이터를 분석하여 '맥주'를 사는 젊은 애기 아빠는 '기저귀'도 같이 사는 것을 발견하고 맥주를 기저귀 옆에 진열하여 매출 향상.
- A: 부모 아이템 집합
- B: 자식 아이템 집합
- A와 B는 공집합이 아니어야 하며 A와 B의 교집합은 공집합을 만족해야 한다.
- 트랜잭션 데이터에서 의미있는 연관규칙을 효율적으로 탐색하는 작업.
연관규칙 평가 척도
지지도와 신뢰도가 있는데, 둘 다 높은 높은 연관규칙을 좋은 규칙이라 판단.
지지도(support)
아이템 집합이 전체 트랜잭션 데이터에서 발생한 비율
- S(A->B) = N(A,B) / n
N(A,B):트랜잭션 데이터에서 A와 B가 동시에 출현한 횟수.
n: 트랜잭션 데이터 크기
신뢰도(confidence)
부모 아이템 집합이 등장한 트랜잭션 데이터에서 자식 아이템 집합이 발생한 비율
-
C(A->B) = N(A,B) / N(A)
N(A,B):트랜잭션 데이터에서 A와 B가 동시에 출현한 횟수.
N(A): 트랜잭션 데이터에서 A의 출현 횟수 -
ex)
1: 빵, 우유
2: 맥주, 땅콩
3: 빵
4: 빵, 맥주, 땅콩
5: 빵, 우유
S(빵->우유) = 2/5
C(빵->우유) = 2/4
지지도 Apriori
- S(A->B)가 최소 지지도(사용자 설정)이상이면, 이 규칙은 빈발하다고 판단.
- 어떤 아이템의 집합이 빈발하면, 이 아이템의 부분집합도 빈발한다.
ex) S(빵 -> 우유)가 빈발하면 빵도 빈발하고 우유도 빈발한다. - '빵->우유'가 빈발하지 않다면 '빵->우유->초코렛'도 빈발하지 않기에 탐색할 필요가 없게 된다.
- 후보 규칙 생성: 모든 최대 빈발 아이템 집합을 찾은 후, 후보 규칙을 모두 생성.
ex) {빵, 우유}가 빈발한데, {빵, 우유, 초콜렛}, {빵, 우유, 아이스크림}이 빌발하지 않다면, {빵, 우유}를 최대 빈발 아이템 집합이라고 함. 그리고 {빵, 우유} 중 어느 것을 부모로 둘지 모든 가능성의 집합을 생성 가능한 후보.
신뢰도 Apriori
'동일한' 아이템 집합으로 생성된 규칙 x1->y1, x2->y2에 대해서 x1이 x2의 부분 집합이라면 x1의 빈발 횟수가 더 많기에 N(x1,y1)/N(x1)의 신뢰도가 더 낮다.
즉, {A,B} -> {C,D}가 최소 신뢰도 이하라면 {A,B}의 부분 집합인 {A}->..., {B}->...는 탐색할 필요가 없다. 왜냐하면 부분 집합인 {A}, {B}의 빈발 횟수가 더 많아서 신뢰도가 더 낮기 때문이다.
mlxtend
연관규칙을 탐색하는 두 단계로 진행.
from mlxtend.frequent_patterns import apriori, association_rules
#1
apriori(one_hot_df, min_support = 0.003) # one_hot_df: 원-핫 인코더 형태, min_support:최소 지지도
- one_hot_df: 원-핫 인코더 형태
- min_support:최소 지지도
#2
association_rules(frequent_item_df, metric = 'confidence', min_threshold = 0.1) # frequent_item_df
- frequent_item_df: frequent dataset에서 찾은 연관 규칙을 데이터 프레임 형태로 변환
- metric: 연관규칙을 필터링 하기 위한 유용성 척도
- min_threshold: 지정한 metric의 최소 기준치연관규칙 탐색
마켓 장바구니 데이터를 통해서 연관규칙 탐색을 살펴보자.
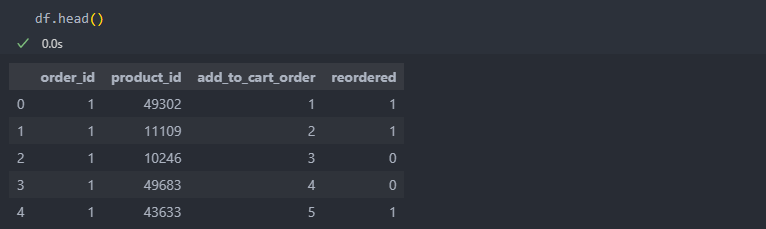
order_id별로 groupby로 묶어서 product_id의 구매 데이터를 원-핫 인코딩으로 만들어야 한다. apriori의 data는 원-핫 인코딩 방식으로 입력 데이터를 받기 때문이다.
131209개의 order_id별 구매품목을 리스트 형태로 만든 후,
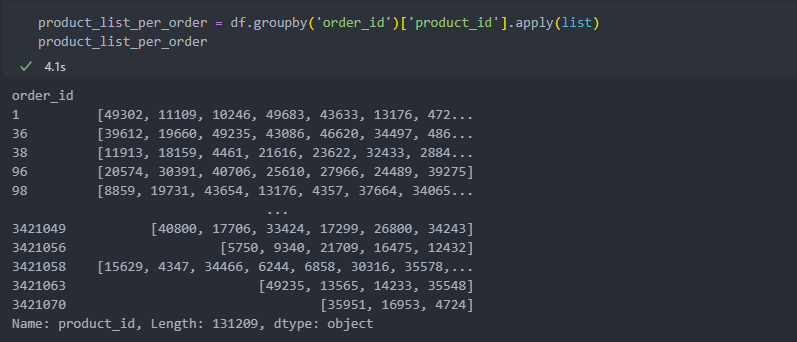
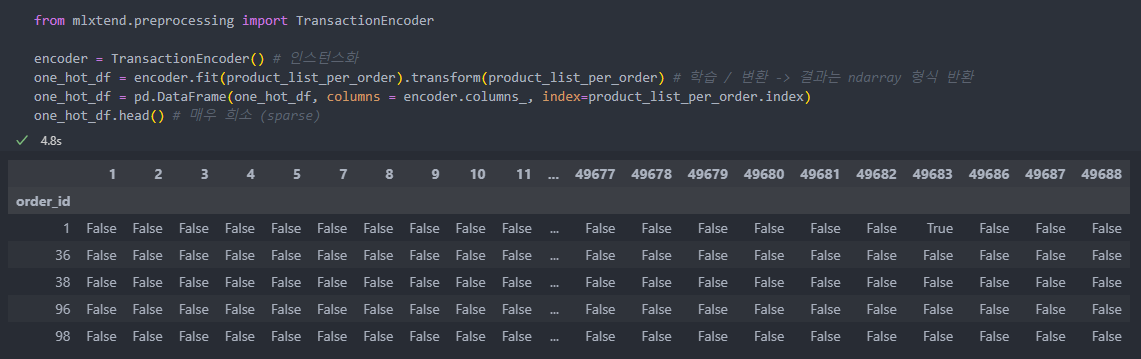
from mlxtend.preprocessing import TransactionEncoderTransactionEncoder() 사용하여 학습 및 변환한다.
그리고 변환한 것을 id별 구매품목을 데이터 프레임 형식으로 생성한다.
from mlxtend.frequent_patterns import *
# 빈발 패턴
frequent_item_df = apriori(one_hot_df, min_support = 0.003) # apriori로 빈발 아이템 집합 / 0.3% 이상 구매한 상품만 대상으로 함
# 연관규칙
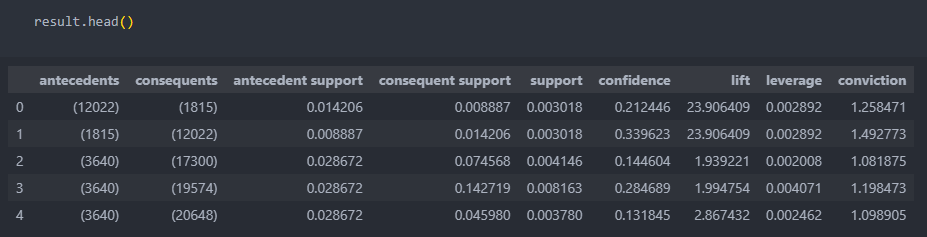
result = association_rules(frequent_item_df, metric = 'confidence', min_threshold = 0.1) # 연관규칙 탐색결과를 확인해 보자.
첫번째 행을 보면, 'antecedents'의 아이템을 구입했을 때 'consequents'의 아이템을 구매한 규칙의 지지도(support)는 0.3%이고 신뢰도(confidence)는 21%정도 된다고 해석할 수 있다.