군집화
하나 이상의 특징을 바탕으로 유사한 샘플을 하나의 그룹으로 묶는 작업을 말한다.
- 샘플들을 소수의 군집으로 묶어 각 군집의 특성을 파악하여 데이터의 특성을 이해하기 위함.
- 군집 특성을 바탕으로 각 군집에 속하는 샘플들에 대한 세부화된 의사결정 수행.
거리와 유사도
샘플들을 하나의 군집으로 묶기 위해서 '거리' 혹은 '유사도'가 필요.
거리/유사도 척도는 수치형 변수에 대해서 정의되어 있으므로 '숫자'로 바꿔주는 작업이 있어야 한다.
-
범주형 변수의 숫자화(더미) : 범주형 변수가 특정 값을 취하는지 여부를 나타내는 더미 변수 생성 방법.
pandas.get_dummies를 사용하여 생성할 수 있으며, '문자' 타입만 사용가능하기에 숫자로 표현되어 있는 범주 변수(날짜, 코드 등)라면 데이터 타입을 'str'로 변경하여 사용.
인자 :
data - 더미화를 수행할 DataFrame 혹은 Series.
drop_first - 첫 번째 더미 변수 제거 할지 여부(3개의 변수가 있다면 2개만 알아도 나머지 1개의 변수는 알 수 있기에) -
유클리디안 거리 : 두 변수 사이의 거리(백터 간 거리)
-
맨하탄 거리 : 정수형 데이터(ex. 리커트 척도, 설문 조사의 단계)에 적합한 거리 척도로 수직/수평으로만 이동한 거리의 합으로 정의.
-
코사인 유사도 : 변수값의 스케일을 고려하지 않고 방향 유사도를 측정하는 상황(ex. 추천 시스템)에 주로 사용.
-
매칭 유사도 : '이진형 데이터'에 적합한 유사도 척도로 전체 특징 중 '일치하는 비율'을 고려하여 사용.
-
자카드 유사도 : '이진형 데이터'에 적합한 유사도 척도로 둘 중 '하나'라도 '1을 가지는 특징' 중 '일치하는 비율'을 고려하여 사용하며 희소한 이진형 데이터에 적합한 유사도 척도.(ex. 상품 구매 데이터-한정품, 고급 스포츠카 등)
k-평균(K-Means) 군집화
(1)k개(군집의 개수)의 임의 중심점을 설정하고 (2)모든 샘플에 대해서 중심에서 가장 가까운 샘플들을 할당 시킨 후 (3) 할당된 샘플들의 중심점을 업데이트한다. 업데이트를 하면 중심점이 바뀌게 되어 (1), (2), (3)을 다시 반복한다. 그리고 (1), (2), (3)을 더 이상 중심점에 변화가 없을 때까지 진행한다.
장점
계층적 군집화에 비해 계산량이 적으며 군집 개수 설정에 제약이 없다.
단점
같은 데이터를 가지고 군집화를 하더라도 임의의 중심점을 가지고 시작을 하기에 군집화 결과가 다르게 나타날 수 있다.(임의성 존재)
데이터 분포가 특이하거나 군집별 밀도 차이가 존재하면 성능이 좋지 않다.
중심점을 설정해야 하기에 유클리디안 거리만 사용해야 한다.
중심점이 업데이트마다 계속 달라져서 수렴되지 않거나 매우 오래 걸리는 경우 발생할 수 있다.
sklearn.cluster.KMeans 사용
sklearn.cluster.KMeans주요인자:
- n_cluster: 군집 개수
- max_iter: 최대 이터레이션 횟수(중심점이 수렴되지 않는 경우를 고려하여)
주요 메서드:
- fix(X): 데이터 X에 대한 군집화 모델 학습
- fit_predict(X): 데이터 X에 대한 군집화 모델 학습 및 라벨 반환
주요 속성:
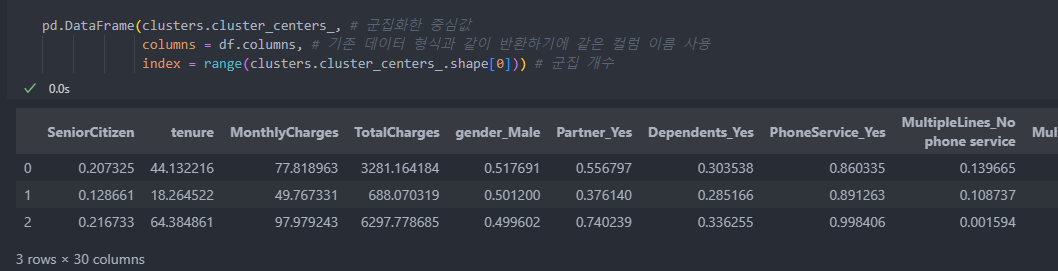
- labels_: 학습한 데이터에 있는 샘플들이 속한 군집 정보(ndarray 형식)
- clustercenters: 학습한 데이터에 있는 샘들들이 속한 군집 중심점(ndarray 형식) 데이터
customer ID별 특성을 정리해놓은 데이터를 가지고 사이킷런 라이브러리를 활용하여 군집화를 진행해보자.
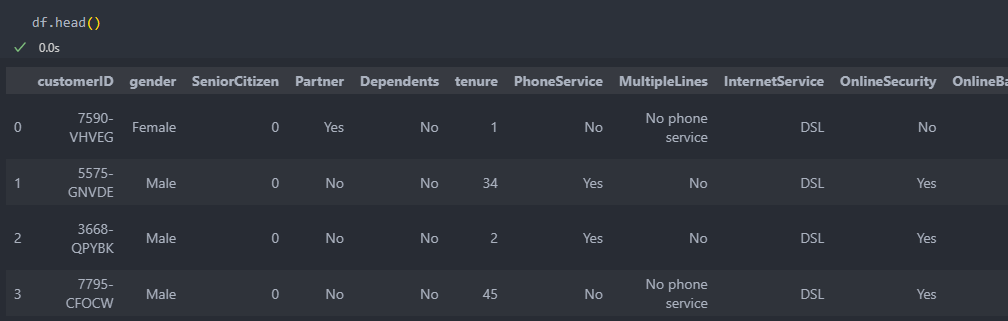
customer ID는 특성이 아니기에 index로 바꾼 후, 수치형이아닌 데이터를 '더미화'한다.
pandas 모듈 get_dummies 사용하여 데이터를 더미화하면, 숫자인 데이터는 그대로 두고 'str'형 데이터들을 '더미화'되어 columns으로 생성된다.
pandas.get_dummies(data, drop_first=True)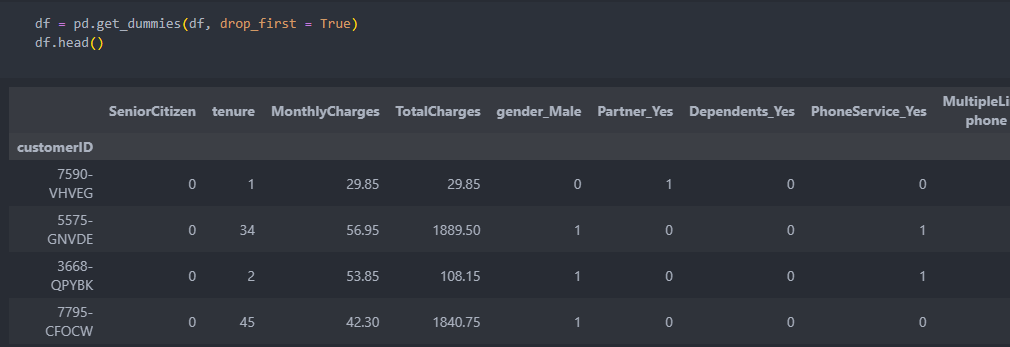
군집화를 진행해보자.
from sklearn.cluster import KMeans
clusters = KMeans(n_clusters = 3).fit(df) # 3개의 군집으로 나누어 학습 진행.학습을 진행한 결과를 확인해보자.
베스트셀러 도서 구매 데이터로 다시 군집화를 해보자.
군집화를 진행하면 같은 책들을 구매한 고객별로 군집화가 된다면, 같은 군집에 있는 고객들에게 책 추천시스템을 사용할 수 있을 것이다.
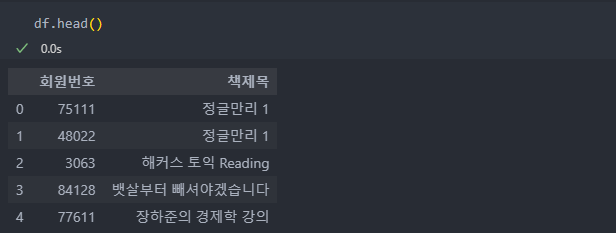
그리고 판다스 crosstab을 사용하여 책을 구매하였다면 매칭이 되어 구매 수로 구매하지 않은 책은 '0'으로 데이터를 반환한다.
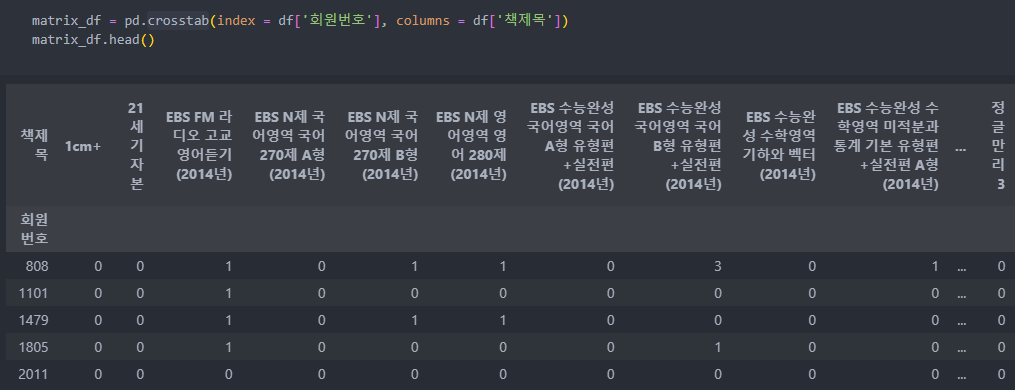
crosstab 데이터를 가지고 군집화를 실행해보자.
from sklearn.cluster import KMeans
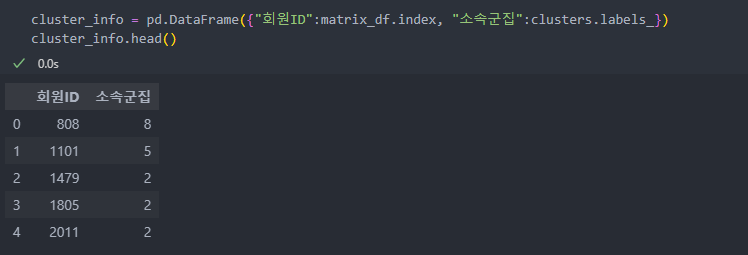
clusters = KMeans(n_clusters = 3).fit(df)학습한 데이터를 활용하여 ID별로 어느 군집에 속해있는지 데이터 프레임으로 확인해보자.
index별로 군집화된 label이 생생되었기에 아래와 같이 데이터 프레임으로 생성한다.
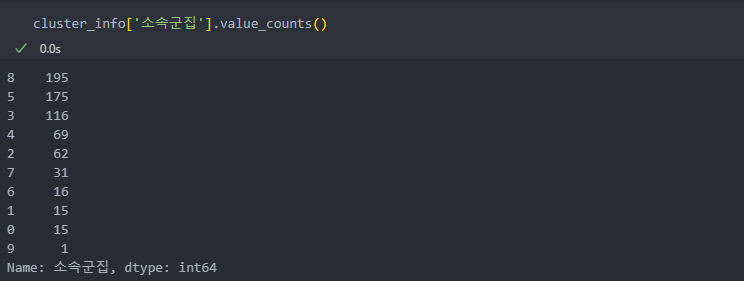
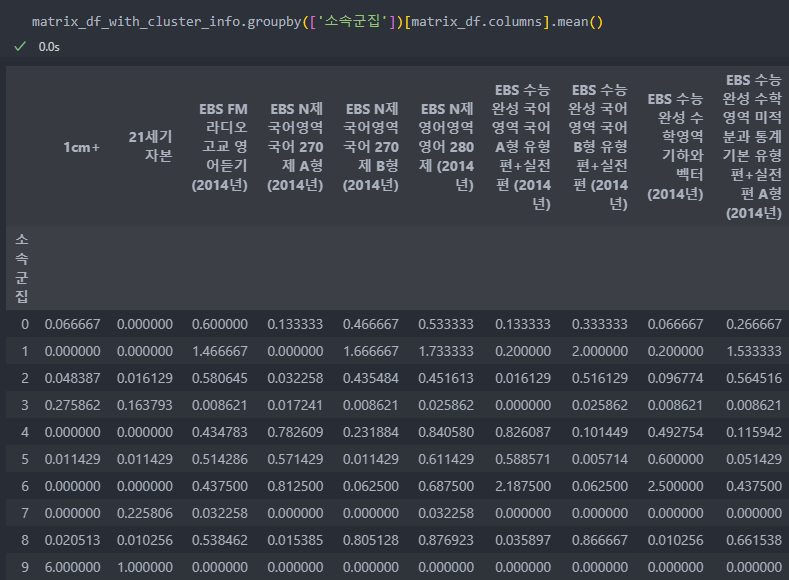
그리고 10개로 나눈 군집별 데이터의 수를 확인해보면 데이터의 크기가 제각각으로 불균형이 보인다.
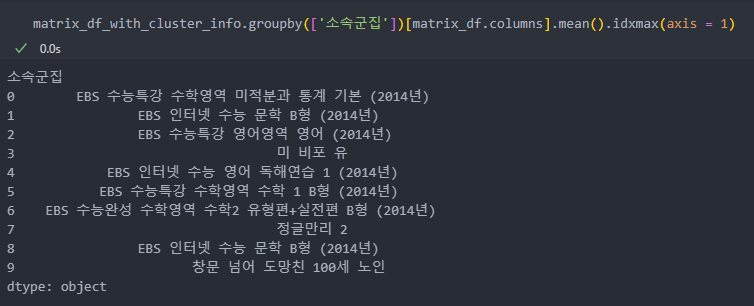
기존의 데이터에 군집화된 라벨을 merge하여 군집화별로 groupby를 진행한다.
idxmax : 'axis=0 인덱스, axis=1 컬럼'으로 가장 높은 값을 가지는 인덱스(행) 이름 혹은 컬럼(열) 이름을 반환한다.(max vs argmax)
이것을 이용하여 axis를 1로 하여 군집별로 가장 많이 구매한 책이 무엇인지 확인해보자.