[Spark] 클라우드
📁 클라우드
- 관리가 훨씬 쉽고, 보안이 뛰어나며, 가용성이 좋음
- 스파크를 쓸 때는 여러 대의 컴퓨터를 사용하는데, 보통 클라우드의 서버를 빌림

📁 클라우드 3대장
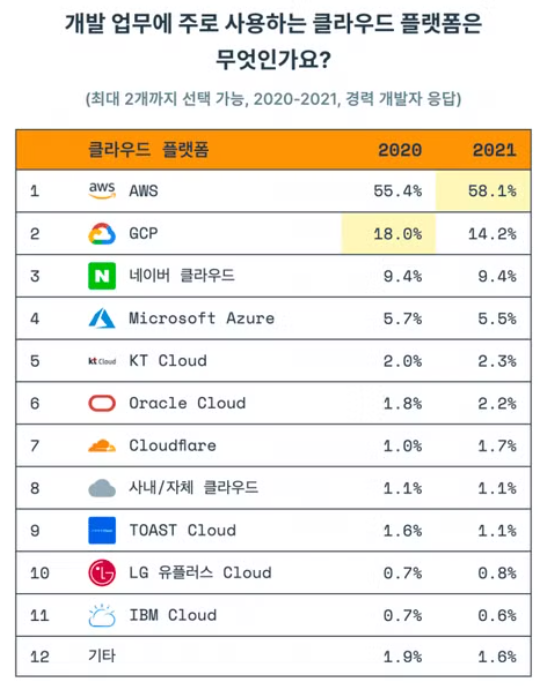
AWS: 지금까지 시장을 지배해왔고, 앞으로도 그럴 가능성이 높음- 한 번 시장을 지배한 이후로, 모든 것의 기준이 되었음
GCP:Bigquery원툴일 수 있지만, 그 원툴이 너무 강력Azure : 편하지만, 비쌈- 그 외 여러 가지 이유(지원, 투자, 계열사 등)로 기타 클라우드를 사용하는 경우도 많음
📁 스토리지
- AWS를 이용하게 되면 기본적으로 대부분의 파일(데이터)를 S3에 보관
- 내 컴퓨터에 보관하는 것보다 안전하며, 임의의 팀원이 접근할 수 있음
- 그 데이터를 다시 데이터베이스에 연결하여 사용할 수도 있음
- 스파크는 S3에서 직접 읽을 수도, DB를 통해 읽을 수도 있음
- 비용에 주의하면 좋음
📌 Amazon S3란?
- Amazon S3는 업계 최고의 확장성, 데이터 가용성 및 보안과 성능을 제공하는 객체 스토리지 서비스
- 데이터 레이크, 웹사이트, 클라우드 네이티브 애플리케이션, 백업, 아카이브, 기계학습 및 분석과 같은 다양한 사용 사례에 대한 원하는 양의 데이터를 저장하고 보호
- Amazon S3는 99.999999999(9가 11개)의 내구성을 제공하도록 설계되었으며, 전세계 수백만 고객을 위해 데이터를 저장함
📁 엔진

- 쉽게 말해 컴퓨터를 빌리는 것
- 단일 기기를 빌릴 수도 있고, 여러 대를 빌려쓸 수도 있음
- 접속은 보통 ssh를 이용하고, vscode를 이용하면 좀 더 편리할 수 있음
📁 데이터베이스
- 데이터 공유 : 데이터베이스는 여러 사용자가 동시에 접근하여 데이터를 공유할 수 있음
- 데이터 보호 : 데이터베이스는 데이터를 보호하기 위해 다양한 보안 기능을 제공
- 데이터 검색 : 데이터베이스는 데이터를 쉽게 검색할 수 있도록 인덱싱 기능을 제공
- 데이터 백업과 복원 : 데이터베이스는 데이터를 백업하고 복원하는 기능을 제공하여 데이터 손실을 방지 → 이를 통해 중요한 데이터를 안전하게 보호할 수 있음
- 수십가지 데이터베이스가 있는데, 서로 다른 세 가지 유형 확인
RDS: 관계형 데이터베이스- postgres와 mysql 등 다양한 옵션이 있는데, 보통 엔지니어가 결정한 걸 따르면 됨
- 대동소이하며, 위에서 언급한 인덱싱을 잘 활용하면 좋음
- 항상 서버가 떠 있어야 하며, 그렇기 때문에 그 비용이 나감
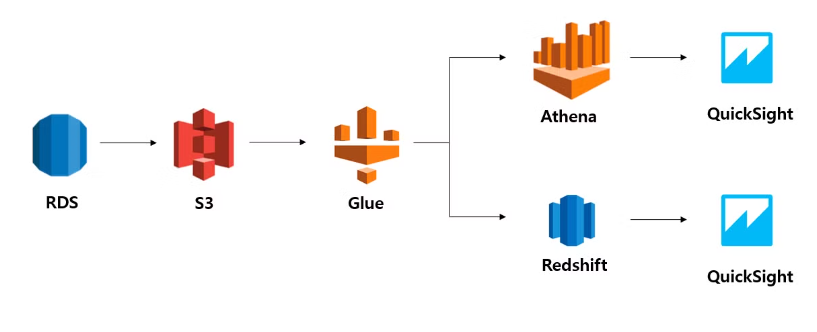
Athena: S3에 있는 데이터를 직접 간편하게 분석할 수 있는 대화형 쿼리 서비스- 보통 S3에 있는 데이터와 연동
- Serverless라고 하여, 쿼리를 운용할 때만 잠시 기기를 빌려 연산한 뒤 다시 반납
- 따라서 비용이 저렴한 것이 보통
- 바로 Spark와 연동할 수도 있음
Redshift: 빠르고 강력한 데이터 웨어하우징- 구동을 위해서는 클러스터(여러 대의 컴퓨터)를 구성하여 운영하여야 함(비쌈)
- 복잡한 연산에 조금 더 효율적
- 역시, Spark와 연동할 수 있음
📁 아키텍쳐 예시
📁 EMR
- 페타바이트급 데이터 처리, 대화식 분석 및 기계 학습을 위한 빅 데이터 솔루션
- AWS에서 Spark를 사용하면, 보통 EMR을 이용

원하는 바를 이루고 싶은 사람입니다.