[Spark] 파일 유형
📁 File format
- 다양한 파일 유형이 있는데, 크게 시간적 비용과 공간적 비용으로 장단점을 비교
- 시간적 비용: 읽고 쓰는데 걸리는 시간
- 파일 유형에 따라 수십배까지 차이가 남
- 공간적 비용: 저장된 파일의 크기를 가리킴
- 마찬가지로 파일 유형에 따라 수십배까지 차이가 남
- 좀 더 나아가, 입/출력 시에 필요한 메모리도 굉장히 중요
📁 csv, txt
- 가장 흔한 포맷으로, 개발이나 분석 직군이 아닌 사람도 많이 다룸
- CSV는 Comma-separated values의 약자로, 콤마로 구분된 정형 데이터를 가리킴
- Comma(
,) 대신 Tab(\t)과 같은 다른 구분자seperator를 사용할 수도 있음 - 데이터 안에 구분자가 들어있는 경우, 방어할 수는 있지만 깨질 위험이 있음
- Comma(
- 가장 느리고, 무거워서 소규모 데이터가 아니면 부적절
- 내부적으로는 encoding(utf-8, cp949 등)에 따라 다르게 저장됨
📁 json
-
csv, txt와 크게 다르지는 않음
-
단, 저장된 자료를 python의 dictionary와 같은 형식으로 강제하며, 이를 JSON Object라 함
- ex)
{”키”:”값”}/{KEY : Value} - dict와 같은 것은 아님 / 파이썬의 dict를 json으로 변환하여 사용할 수 있으며, 이를 dump한다고 함
*좀 더 자세히 들어가면 byte serialize를 이해해야겠지만, 여기서는 생략
- ex)
-
여러 JSON Object를 JSON Array에 담을 수 있음
-
비교적 개발자의 선호도가 높으며, 비교적 대용량의 데이터도 JSON으로 관리하는 경우가 많음
- API 통신도, 보통 JSON 형식으로 함
- 하지만 여전히 무거워서 대용량 데이터를 다루는데는 불편
-
txt와 마찬가지로 encoidng방법에 따라 다르게 저장되는데, utf-8을 사용하는 것이 일반적
📁 Pickle
-
하나의 컴퓨터로 개인용 프로젝트에서 데이터를 관리할 때 편리한 데이터 형식
- 버전과 운영체제에 대한 의존Dependency이 있기 때문에 협업할 때 데이터를 주고 받으면 작동하지 않을 위험이 있음
-
위의 유형(csv, json)보다 2~30% 정도 용량이 가벼움
- read/write 속도가 수십배 이상 빠름
📁 Parquet
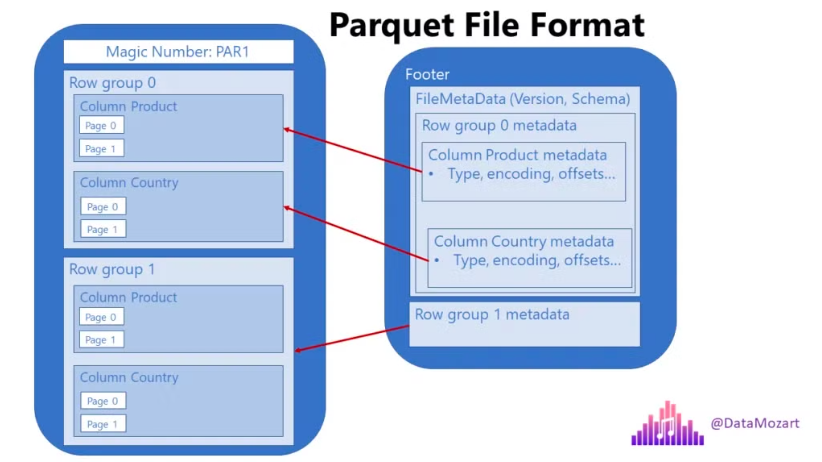
- 대용량 데이터 저장에서 표준 (보통 “파케이”라고 읽음)
- 굉장히 가볍고, 빠름!
- 다수의 OLAB Database가 내부적으로 parquet를 사용하여 데이터를 저장
- Spark 또한 Parquet를 지원
📁 기타
- arrow나 hdfs, feather도 때에 따라 유용하게 사용됨
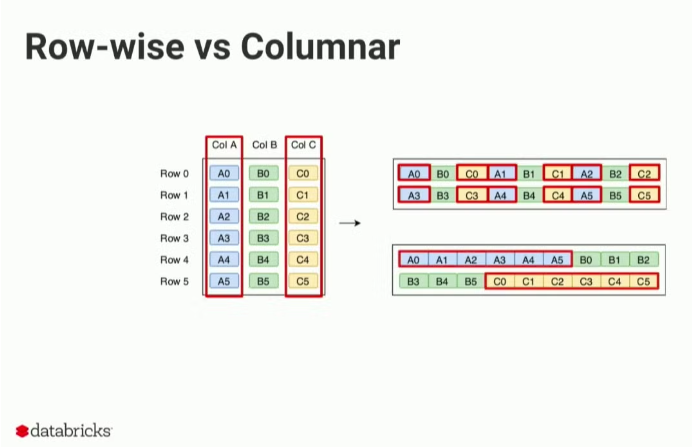
- 위와 같은 압축, 속도가 가능한 이유는 기본적으로 칼럼기반columnnar이기 때문
📁 I/O
- Input & Output을 가리킴
- 다양한 맥락에서 쓰이지만, 여기서는 데이터의 입출력을 말하는 것
<I/O의 메모리 사용>
- 전처리에서 잘 돌던 데이터가, 저장save에서 터지는(OOM) 경우가 있음
<I/O Speed>
- 언급한 것 중 가장 빠른 데이터 수급은 메모리
- 좀 더 자세히는 Network < Disk < Memory
- 이러한 이유로 In-memory DB를 사용하기도 함
- 스파크는 기본적으로 모든 데이터를 Memory에서 처리
- 내부적으로는 lazy computation 등으로 좀 더 복잡

원하는 바를 이루고 싶은 사람입니다.