[머신러닝] 비지도 학습
📁 붓꽃 데이터를 이용한 군집화
- K - 평균 군집화 혹은 알고리즘(K-means clustering) : 가장 일반적으로 사용되는 알고리즘
- sepal_length: 꽃 받침의 길이
- sepal_width: 꽃 받침의 너비
- petal_length: 꽃 잎의 길이
- petal_width 꽃 잎의 너비
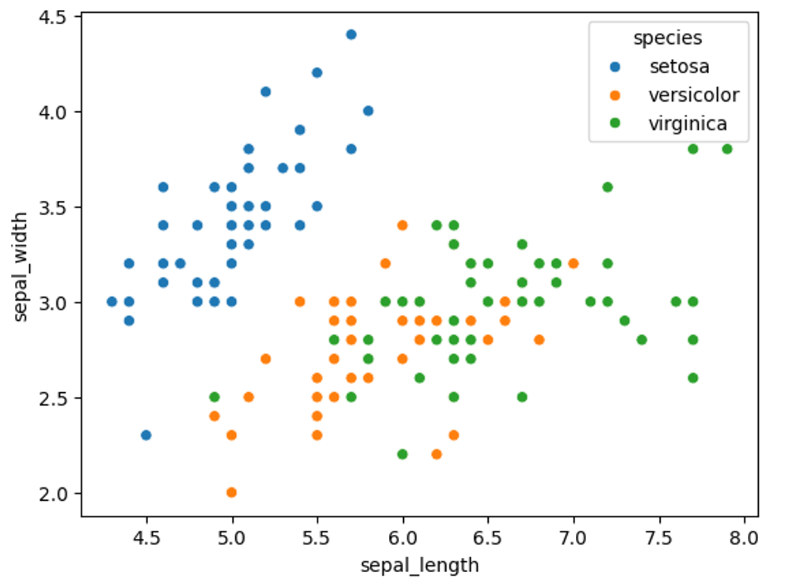
- species(Y, 레이블): 붓꽃 종(setosa, virginica, versicolor)
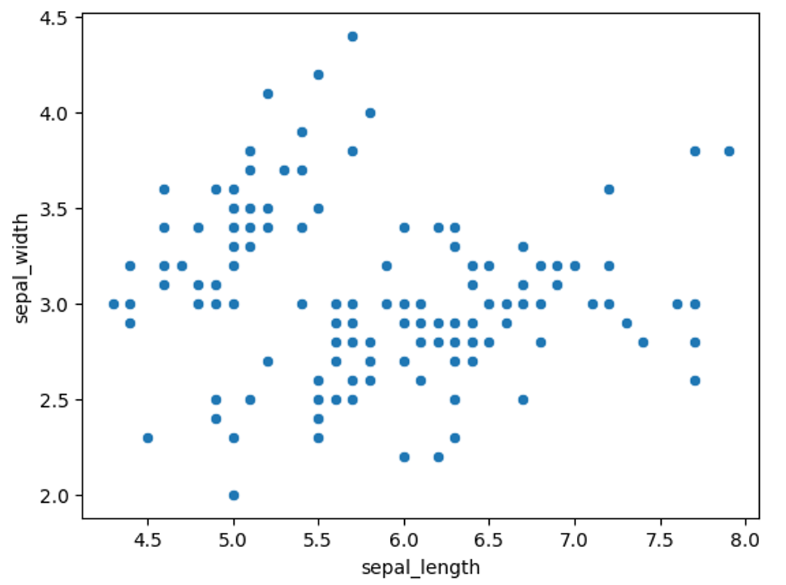
- Labeling이 안된 꽃 받침
길이-너비산점도
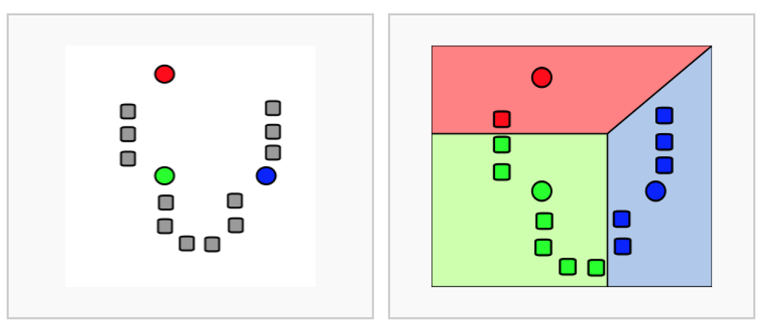
- 위의 점들을 3개로 그룹화
→ “데이터”의 기준으로 보면 3개가 아닌 K개의 그룹으로 정해볼 수 있음
📁 K-Means Clustering
<수행순서>
1. K개 군집 수 설정
2. 임의의 중심을 선정
3. 해당 중심점과 거리가 가까운 데이터를 그룹화
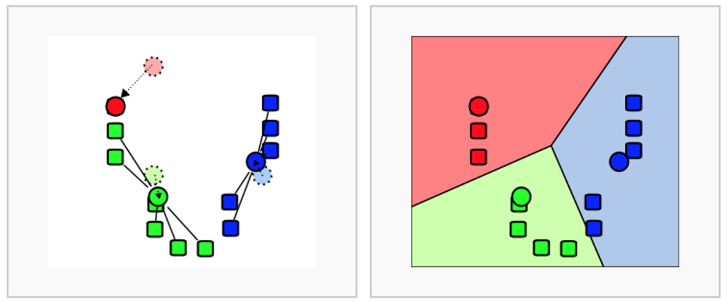
4. 데이터의 그룹의 무게 중심으로 중심점을 이동
5. 중심점을 이동했기 때문에 다시 거리가 가까운 데이터를 그룹화 (3~5번 반복)
→ 📌 이렇게 임의로 선정한 K군집수를 기준으로 데이터 군집화 프로세스를 진행
- 장점
- 일반적이고 적용하기 쉬움
- 단점
- 거리 기반으로 가까움을 측정하기 때문에 차원이 많을 수록 정확도가 떨어짐
- 반복 횟수가 많을 수록 시간이 느려짐
- 몇 개의 군집(K)을 선정할지 주관적임
- 평균을 이용하기 때문에(중심점) 이상치에 취약함
- Python 라이브러리
sklearn.cluster.KMeans- 함수 입력 값
n_cluster: 군집화 갯수max_iter: 최대 반복 횟수
- 메소드
labels_: 각 데이터 포인트가 속한 군집 중심점 레이블cluster_centers: 각 군집 중심점의 좌표
- 함수 입력 값
📁 군집평가 지표
<실루엣 계수>
- 비지도 학습 특성 상 답이 없이 때문에 그 평가를 하긴 쉽지 않음
- 군집화가 잘되어 있다는 것은 다른 군집간의 거리는 떨어져 있고 동일한 군집끼리는 가까이 있다는 것을 의미
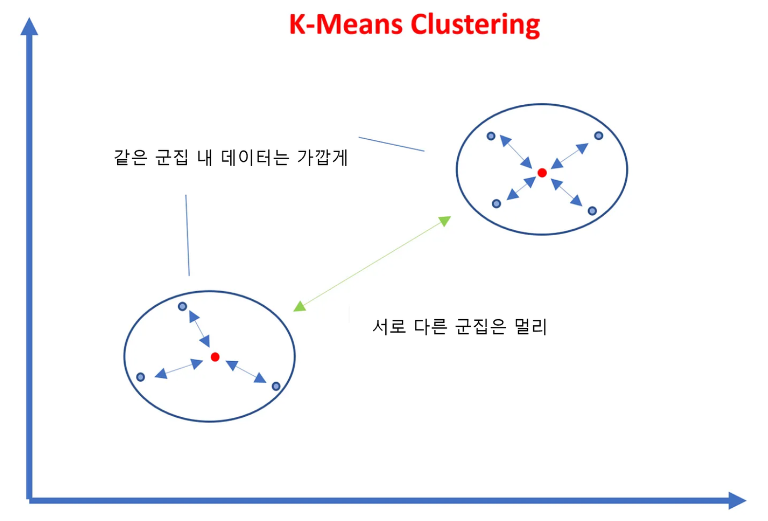
→ 📌실루엣 분석(silhouette analysis): 간 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 측정 - 실루엣 계수
- 수식:
- : 데이터 포인트 과 같은 군집에 속한 다른 포인트들과의 평균 거리
- : 데이터 포인트 와 가장 가까운 다른 군집 간의 평균 거리
- 해석 : 1로 갈수록 잘 군집화 되어 있음 / 1에 가까울수록 잘 못 군집화 되어 있음
- 수식:
→ 📌특정한 데이터 i의 실루엣 계수는 얼마나 떨어져있는가($b(i) -a(i)$)가 클 수록 크며, 이를 단위 정규화를 위해 $a(i), b(i)$ 값 중에 큰 값으로 나눔
- 좋은 군집화의 조건
- 실루엣 값이 높을수록(1에 가까움)
- 개별 군집의 평균 값의 편차가 크지 않아야 함
- Python 라이브러리
sklearn.metrics.sihouette_score: 전제 데이터의 실루엣 계수 평균 값 반환- 함수 입력 값
X: 데이터 세트labels: 레이블metrics: 측정 기준 기본은euclidean
- 함수 입력 값
📁 고객 세그멘테이션
이중 고객 세그멘테이션(Customer Segmentation): 다양한 기준으로 고객을 분류하는 기법- 주로 타겟 마케팅이라 불리는 고객 특서엥 맞게 세분화 하여 유형에 따라 맞춤형 마게팅이나 서비스를 제공하는 것을 목표로 둠
- RFM의 개념
Recency(R): 가장 최근 구입 일에서 오늘까지의 시간Frequency(F): 상품 구매 횟수Monetary value(M): 총 구매 금액

원하는 바를 이루고 싶은 사람입니다.