[머신러닝] 회귀, 분류 모델링
📁 의사결정나무(Decision Tree, DT)
- 의사결정규칙을 나무 구조로 나타내어 전체 자료를 몇 개의 소집단으로 분류하거나 예측을 수행하는 분석 방법
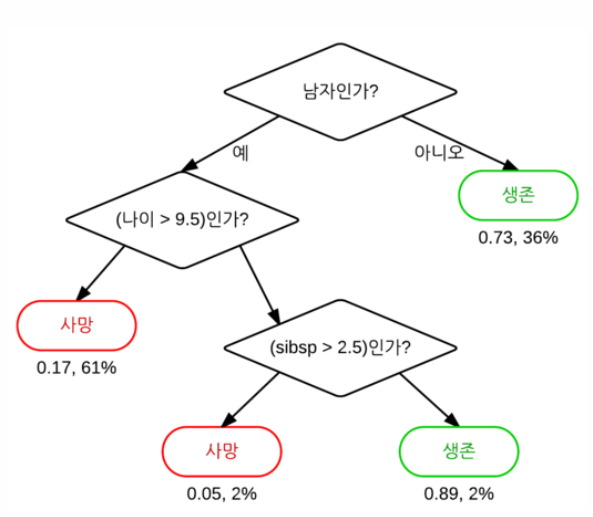
- 타이타닉의 예시
- 성별의 기준으로 의사결정나무 시각화

- 결정 트리의 과정
→ 출처 : https://eehoeskrap.tistory.com/12 - 명칭
루트 노드(Root Node): 의사결정나무의 시작점 / 최초의 분할조건리프 노드(Leaf Node): 루트 노드로부터 파생된 중간 혹은 최종 노드분류기준(criteria): sex는 여성인 경우 0, 남성인 경우 1로 인코딩. 여성인 경우 좌측 노드로, 남성인 경우 우측 노드로 분류불순도(impurity)- 불순도 측정 방법 중 하나 인 지니 계수는 0과 1사이 값으로 0이 완벽한 순도(모든 샘플이 하나의 클래스), 1은 완전한 불순도(노드의 샘플의 균등하게 분포) 됨을 나타냄
- 리프 노드로 갈수록 불순도가 작아지는(한쪽으로 클래스가 분류가 잘되는)방향으로 나무가 자람
샘플(samples): 해당 노드의 샘플 개수(891개의 관측치)값(value): Y변수에 대한 배열 / 549명이 죽었고(Y = 0), 342명이 살았음(Y = 1)클래스(class)- 가장 많은 샘플을 차지하는 클래스를 표현
- 위에서는 주황색(Y = 0 다수), 파란색(Y=1 다수)를 표현
<의사결정나무 정리>
- 장점
- 쉽고 해석하기 용이
- 다중분류와 회귀에 모두 적용이 가능
- 이상치에 견고하며 데이터 스케일링이 불필요(데이터의 상대적인 순서를 고려해서)
- 단점
- 나무가 성장을 너무 많이하면 과대 적합의 오류에 빠질 수 있다.
- 훈련 데이터에 민감하게 반응하여 작은 변화가 노이즈에도 나무의 구조가 크게 달라짐(불안정성)
- Python 라이브러리
sklearn.tree.DecisionTreeClassifiersklearn.tree.DecisionTreeRegressor
📁 랜덤 포레스트 이론
- 의사결정 나무는 과적합과 불안정성 대한 문제가 대두
- 이를 해결하기 위한 아이디어는 바로 나무(tree)를 여러 개 만들어 숲(Forest)를 만드는 것
<배깅(Bagging)의 원리>
- 언제나 머신러닝은 데이터의 부족이 문제
- 이를 해결 하기 위한
Bootstrapping + Aggregating방법론
-Bootstrapping: 데이터를 복원 추출해서 유사하지만 다른 데이터 집단을 생성하는 것
-Aggregating: 데이터의 예측,분류 결과를 합치는 것
-Ensemble(앙상블): 여러 개의 모델을 만들어 결과를 합치는 것
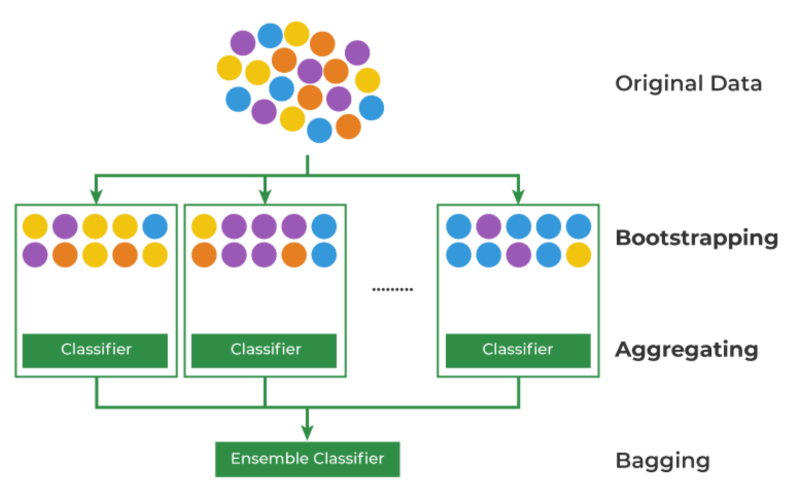
- Bootstrap은 “자기 스스로 해낸다”의 뜻의 유래를 가지고 있고, 영단어로는 부츠 신발의 끈을 의미
- 이를 차용하여 데이터를 복원추출한다는 것을 뜻
- 이렇게 생성된 데이터 샘플들은 모집단의 분포를 유사하게 따라가고 있어 다양성을 보장하면서 데이터의 부족 이슈를 해결하게 됨
<Tree를 Forest로 만들기>
- 여러 개의 데이터 샘플에서 각자 의사결정트리를 만들어서 다수결 법칙에 따라 결론을 냄
- ex) 1번 승객에 대해서 모델 2개는 생존, 모델 1개는 사망을 분류하였다면, 1번 승객은 최종적으로 생존으로 분류
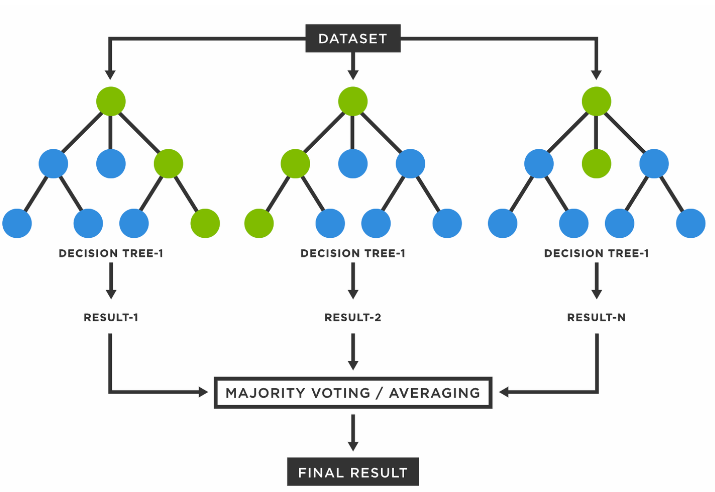
→ 📌 의사결정나무의 장점은 수용하고 단점은 보완하여, 랜덤 포레스트는 일반적으로 굉장히 뛰어난 성능을 보여서 지금도 자주 쓰이는 알고리즘
<랜덤 포레스트 정리>
- 장점
- Bagging 과정을 통해 과적합을 피할 수 있음
- 이상치에 견고하며 데이터 스케일링이 불필요
- 변수 중요도를 추출하여 모델 해석에 중요한 특징을 파악 할 수 있음
- 단점
- 컴퓨터 리소스 비용이 큼
- 앙상블 적용으로 해석이 어려움
- Python 패키지
sklearn.ensemble.RandomForestClassifersklearn.ensemble.RandomForestRegressor
📁 최근접 이웃
K-Nearest Neighbor(KNN, KNN): 주변의 데이터를 보고 내가 알고 싶은 데이터를 예측하는 방식
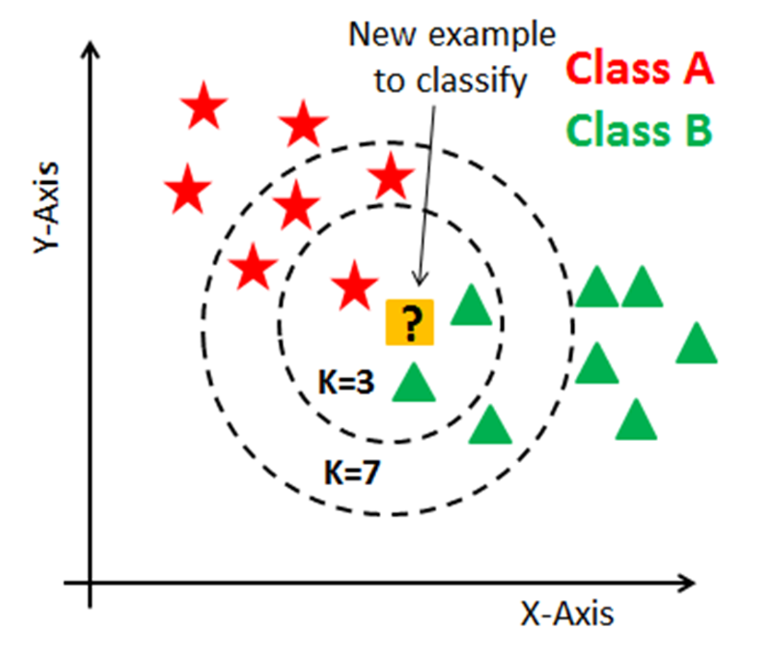
- K=3이라면 별 1개와 세모 2개이므로 ? 는 세모로 예측될 것
- K=7이라면 별 4개와 세모 3개이므로 ?는 별로 예측될 것
→ 📌KNN의 기본 원리: 확인할 주변 데이터 K개를 선정 후에 거리 기준으로 가장 많은 것으로 예측하는 것
<하이퍼 파라미터의 개념>
파라미터(Parameter): 머신러닝 모델이 학습 과정에서 추정하는 내부 변수이며 자동으로 결정 되는 값- Ex) 선형회귀에서 가중치와 편향
- (혼동주의) Python에서는 함수 정의에서 함수가 받을 수 있는 인자(입력 값)를 지정하는 개념
하이퍼 파라미터(Hyper parameter): 데이터 과학자가 기계 학습 모델 훈련을 관리하는데 사용하는 외부 구성변수이며 모델 학습과정이나 구조에 영향을 미침
<거리의 개념>
유클리드 거리(Euclidean Distance): 두 점의 좌표가 주어지면 피타고라스의 정리로 거리를 구할 수 있는 것- 유클리드 거리 공식:
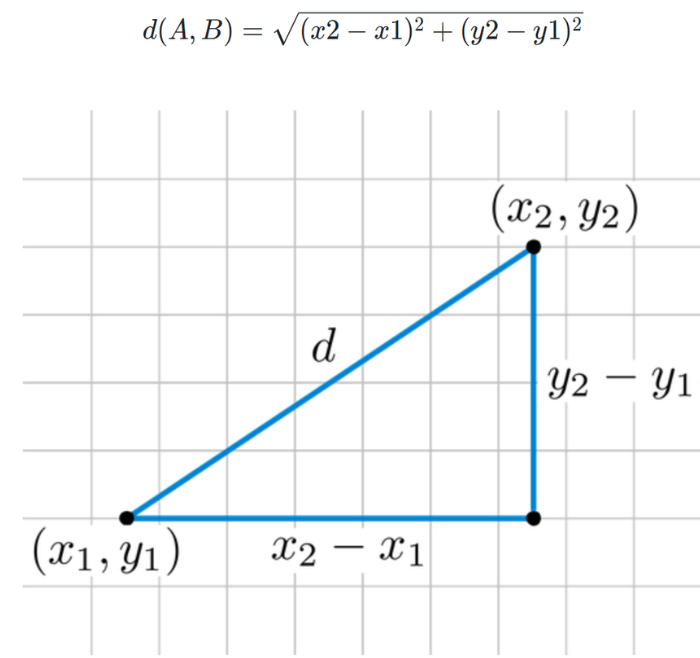
- 표준화는 필수
<KNN 모델의 정리>
- 장점
- 이해하기 쉽고 직관적
- 모집단의 가정이나 형태를 고려하지 않음
- 회귀, 분류 모두 가능함
- 단점
- 차원 수가 많을 수록 계산량이 많아짐
- 거리 기반의 알고리즘이기 때문에 피처의 표준화가 필요함
- Python 라이브러리
sklearn.neighbors.KNeighborsClassifiersklearn.neighbors.KNeighborsRegressor
📁 부스팅 알고리즘
- 부스팅(Boosting) 알고리즘 : 여러 개의 약한 학습기(weak learner)를 순차적으로 학습하면서 잘못 예측한 데이터에 가중치를 부여하여 오류를 개선해나가는 학습 방식
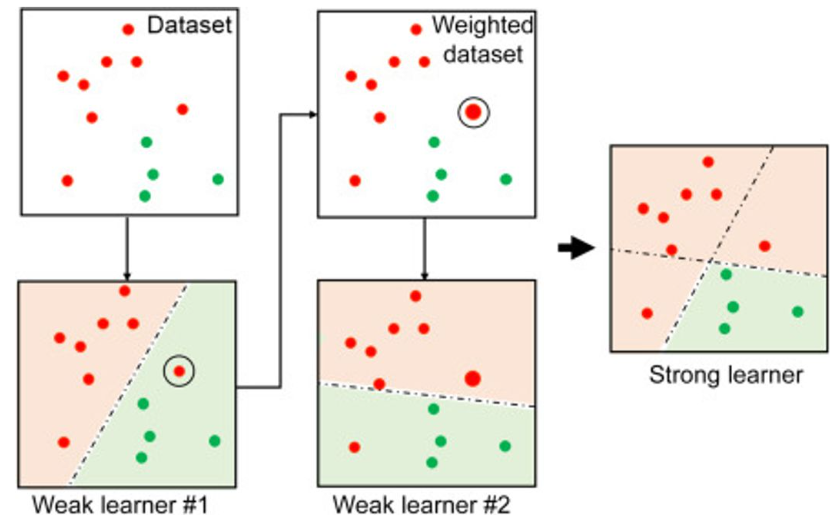
- 빨간색과 초록색을 분류하는 문제의 경우 1개의 선(learner)으로 구별되지 않는 경우가 있음
- 이를 통해 여러 개의 learner를 합친 ensemble을 통해 성능을 올리는 방법
- 부스팅 알고리즘 종류
Gradient Boosting Model- 특징
- 가중치 업데이트를 경사하강법 방법을 통해 진행
- Python 라이브러리
sklearn.ensemble.GradientBoostingClassifiersklearn.ensemble.GradientBoostingRegressor
- 특징
XGBoost- 특징
- 트리기반 앙상블 기법으로, 가장 각광받으며 Kaggle의 상위 알고리즘
- 병렬학습이 가능해 속도가 빠름
- Python 라이브러리
xgboost.XGBRegressorxgboost.XGBRegressor
- 특징
LightGBM- 특징
- XGBoost와 함께 가장 각광받는 알고리즘
- XGBoost보다 학습시간이 짧고 메모리 사용량이 작음
- 작은 데이터(10,000건 이하)의 경우 과적합 발생
- Python 라이브러리
lightgbm.LGBMClassifierlightgbm.LGBMRegressor
- 특징

원하는 바를 이루고 싶은 사람입니다.