[Spark] 스파크, 파이썬과 데이터
- 대규모 데이터 전처리에 있어 스파크는 표준
- 실제 많은 회사가 스파크를 운용하고 있기에 협업 차원에서 도움이 됨
📁 스파크란?
Apache Spark: SQL, 스트리밍, 머신러닝 및 그래프 처리를 위한 기본 제공 모듈이 있는 대규모 데이터 처리용 통합 분석 엔진- 대용량 데이터를 다루는 것에 특화된 프레임 워크
- Pyspark: Python을 기반으로 하여 별도의 언어 공부가 필요 없음
- 대용량 데이터: 대용량 데이터를 다루는 기술에 대한 이해
- 분산 처리: 여러 대의 컴퓨터를 사용한다는 것에 대한 이해
📁 스파크 사용 이유
- 대용량 데이터 사용 시 사용할 수밖에 없음
- ex) 800GB의 Microsoft Academic Graph 데이터를 다룰 때, 스파크를 쓸 수밖에 없음
- 대용량 데이터 처리는 분할Partition하여 처리함으로써 스파크를 우회할 수 있지만, Graph 형식의 데이터는 분할하기 어려워 부득이 스파크를 사용
- 약 10~20대의 컴퓨터를 사용하여 수백만건의 논문 데이터를 교정할 수 있음
📁 파이썬 메모리 이슈로 터짐
- 파이썬 작업을 하다보면 아래와 같은 이유를 알 수 없는 에러가 종종 발생
- 이는 일반적으로 컴퓨터 공학에서는 OOM(Out of Memory)이라 하며, 특히 대용량 데이터를 처리할 때는 자주 만나게 될 문제
- 스파크를 쓰든, 파이썬을 쓰든 메모리의 관리는 굉장히 중요
📁 메모리
-
메모리 : 기억 장치
-
굉장히 세분화가 되어 있지만 크게 RAM과 Disk(SSD)로 나눔
-
RAM : 쉽게 말해 작업 공간
- 데이터를 갖고 작업하기 위해 우리는 데이터를 RAM이란 곳에 올림(read_csv 등)
- 여기에 OS(윈도우 등)와 기본적인 프로그램을 올리면 2~6GB 정도 차지함
- 컴퓨터를 끄면 RAM에 올라간 데이터는 삭제됨
-
Disk : 쉽게 말해 저장 공간
- 장기적으로 데이터를 보관(저장)하는 공간
- 컴퓨터를 꺼도, Disk의 데이터는 사라지지 않음
-
📁 CPU
- CPU : 일꾼, 보통 컴퓨터는 여러 일꾼을 가지고 있음
- 모두 이해할 필요는 없으며, 가장 중요한 것은 코어의 수라고 봐도 됨
*같은 코어 수라도, 고성능의 CPU는 수배 이상 빠를 수 있음 - 하나의 작업을 위해 여러 코어를 사용하는 것을 병렬 처리
- 스파크 또한 여러 대의 PC를, 그리고 각 PC의 여러 코어를 모두 사용
📁 Data type
- 내부적으로는 각 데이터에 대한 명확한 타입이 있음
- 적절한 데이터 타입을 사용하면, 보통 30% 이상의 메모리를 절약할 수 있음
📁 정수(Integers)
- 컴퓨터에서는 정수를 이진법으로 표현
- 뒤의 숫자는 얼마나 많은 메모리를 할당assign할 것인지에 대한 얘기
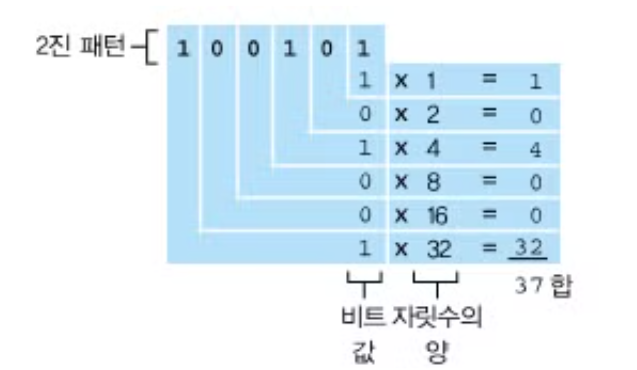
- 뒤의 숫자는 얼마나 많은 메모리를 할당assign할 것인지에 대한 얘기
- 더 많은 메모리를 할당할수록, 더 큰 숫자를 담을 수 있음
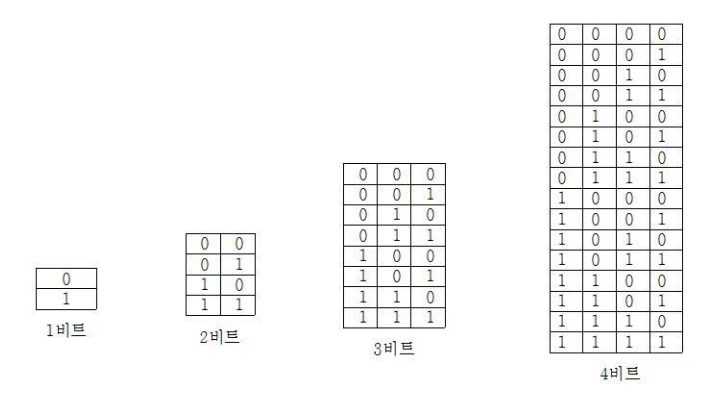
int8:-128 ~ 127int16: -32768 ~ 32727Int32: -2,147,483,648 ~ 2,147,483,647Int64: -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807
→ 엄밀히는, 부호를 위해 1비트(메모리의 단위)를 사용
📁 오버플로(Overflow)
- 크기에 맞지 않는 데이터를 넣어 의도하지 않은 결과가 나오는것을 오버플로overflow
*정확한 정의는 좀 더 복잡 - 파이썬의 데이터 타입은 기본적으로 동적Dynamic이기 때문에 자동으로 데이터형이 바뀜
- 따라서 큰 숫자를 다루는 것은 굉장히 주의해야 함!
📁 부동소수점(Floating points)
-
부동소수점 : 사람에게 직관적이지 않지만, 컴퓨터는 부득이 사용하는 개념
- 앞에서 보았듯 컴퓨터는 이진법을 사용하기 때문에, 정수는 어렵지 않게 표현할 수 있음
- 하지만 0.2, 18.5, 와 같은 정수가 아닌 숫자는 정확하게 표현할 수 없음
→5.96e-54같은 게 바로 부동소수점 -
부동소수점은 하나의 숫자를 형태와 자릿수로 구분하여 표현하는 것
- ex) ,
- 일부의 데이터는 형태(4.78224)를, 나머지 데이터로 자릿수(2)를 표현
*이진법이고, 소수부와 정수부가 다르기 때문에 정확하게는 조금 다름
-
부동소수점 또한 정수와 마찬가지로 float16, float64 등을 사용하는데, 더 큰 메모리를 사용할수록 값이 정확해지지만 데이터가 더 무거워짐
📁 부동소수점 오차
- 부동소수점은 그 원리상 필연적으로 오차를 동반

- 이러한 오차는 더 많은 메모리(16 → 32)를 사용할수록 줄어들지만, 이론적으로는 무한히 많은 메모리를 사용해야만 이 오차를 정확히 없앨 수 있음
- 딥러닝의 경우 메모리 사용을 줄이기 위해, 의도적으로 오차를 감수해서라도 메모리를 줄이기도 함(float 16등)
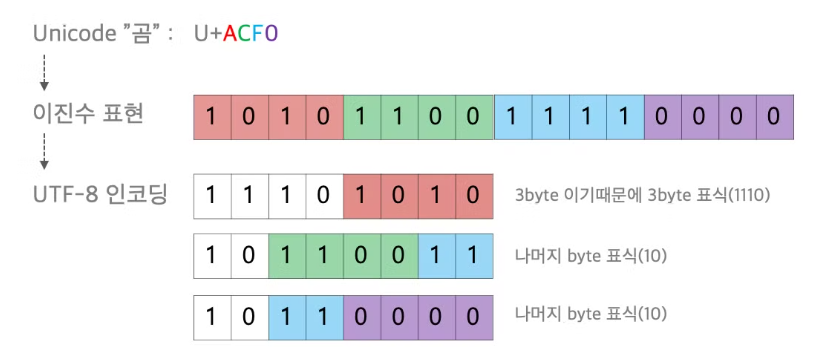
📁 String, Category
- 문자열은 문제가 더 복잡함
- 일반적으로 우리에게 친숙한 대부분의 소프트웨어는
유니코드unicode를 이용하여 문자열을 인코딩
*이러한 원리를 모두 지금 이해할 필요는 없음 - 중요한 것은 메모리를 굉장히 많이 차지한다는 것을 기억하면 된다는 것
- 이에 대한 대안으로, 범주Category형 자료를 사용할 수 있음
- Pandas의 경우 각 데이터의 고유값을 내부에서 숫자로 치환하여 사용
- 본래 문자열로 이루어져있던 칼럼을 범주형으로 변환
- 해당 범주 자료가 내부에서는 숫자로 사용되고 있음을 봄
- 이를 통해 90% 이상의 메모리를 절약할 수 있음
📁 Datetime
- 시간과 관련된 정보
- 일반적으로 소프트웨어들은 Unix Timestamp를 기준으로 함
- UTC time zone을 사용
- 1970년 1월 1일 0시를 기준으로 몇 초가 경과했는지를 숫자로 표현한 것
- 연, 월, 일 시 등의 표현은 사람마다, 소프트웨어마다, 회사마다, 팀마다 모두 다를 수 있음
- 이러한 표현들을 일반적으로 표현하기 위한 양식 또한 존재
- 이를 통해 숫자인 Unix timestamp를 사람이 이해 가능한 문자열로 바꾸거나, 거꾸로 문자열을 Unix timestamp로 바꿀 수도 있음
- 일반적으로 년도을
%y나%Y(4자리)로, 월을%m, 일은%d로 표현
## 21년 11월 6일 4시 30분을 파싱
dt = datetime.strptime("21/11/06 16:30", "%d/%m/%y %H:%M")
dt
>> datetime.datetime(2006, 11, 21, 16, 30)📁 Time zone
- 시간대time zone은 시간 데이터를 다룰 때 굉장히 중요한 부분
- 특히 소프트웨어는 범국가적이기 때문에, 시간의 표준화는 필수
- 일반적으로 컴퓨터 공학에서는 UTC를 기준으로 하며, Unix timestamp도 UTC를 따름
- 대부분의 Database 또한 timezone 정보를 필수로 함

원하는 바를 이루고 싶은 사람입니다.