[ v8이란? ]
웹 브라우저를 만드는 데 기반을 제공하는 Google이 개발한 오픈소스 자바스크립트 엔진입니다. 자바스크립트 엔진이란 자바스크립트 코드를 마이크로프로세서가 이해할 수 있게 기계어로 변환해서 실행할수 있는 프로그램, 또는 인터프리터를 말합니다. 오늘은 v8의 최적화 기법중 하나인 포인터 압축에 대해 이야기해보려 합니다.
[ 성능과 메모리의 트레이드 오프 ]
메모리와 성능 사이에는 끊임없는 싸움이 존재합니다. 사용자로서 우리는 빠른 속도와 적은 메모리 사용량을 원하지만, 안타깝게도 보통 성능 향상은 메모리 사용량 증가의 대가가 따릅니다.
저는 사실 처음 공부할 때 여기서 첫번째 의문이 들었습니다.
".. 메모리를 늘렸기 때문에 더 많은 프로그램을 실행시킬 수 있어서 성능 향상이 되는 것인가?"
그래서 이유는 무엇일까요? 사실 답은 아주 간단합니다. 성능 향상을 위해서 우리는 주로 데이터를 캐싱하거나, 데이터 구조를 더 빠른 구조로 변경합니다. 예를들면 트리나 해시테이블 같은 구조로 말이죠. 이때 메모리가 더 많이 사용된답니다. 또한, 여러 스레드로 데이터를 처리할때도 있습니다. 이러한 경우에도 하나의 스레드로 처리할때보다 메모리 사용률이 높습니다.
[ 64비트 프로세스의 전환 ]
2014년, Chrome은 32비트에서 64비트 프로세스로 전환했습니다. 그 당시 64비트 아키텍처를 가진 컴퓨터들이 생산되었고 따라서 64비트 모드로 실행되게 크롬을 변경했습니다. 이는 Chrome에 더 나은 보안성, 안정성, 성능을 제공했습니다. 하지만 포인터 크기가 8바이트로 증가하면서 메모리 사용량이 더 늘어났습니다. 이때서부터 V8에서 오버헤드를 줄이고 낭비되는 4바이트를 최대한 되찾기 위한 도전이 시작됩니다.
" 메모리는 줄이면서 성능은 늘리고싶어! "
[ 포인터 압축 ]
포인터 압축은 V8의 메모리 사용량을 줄이기 위한 여러 노력 중 하나입니다.
64비트 포인터 대신 어떤 "기준" 주소로부터의 32비트 오프셋을 저장하는 것입니다.
# 기준 주소는 무엇인가요 ?
기준 주소를 아무거나 정합니다.ex:) 기존 주소는 16번지로 정한다면
0번지는 16 + 0 = 16번지
6번지는 16 + 6 = 22번지 가 됩니다.
이렇게 사용하겠다는 뜻입니다.
# 근데 왜 그렇게 해요?
그래야만 (64비트 포인터 대신) 32비트만으로 넓은 메모리를 사용할수 있습니다. 기준 주소가 없다면 기준 주소가 0이랑 같은 상황인데요, 그러면 모든 v8 인스턴스들이 0부터 4기가까지의 메모리를 사용하게 됩니다. 만약 스레드를 5개돌린다고 하면 5개 모두 0부터 4기가까지 공동으로 쓰이게 됩니다.
하지만 그런것보다 ...
0번 스레드는 0부터 4기가
1번 스레드는 4기가부터 8기가,
2번 스레드는 8기가부터 12기가,
이렇게 나눠주면 더 넓게 쓸수있습니다. 힙 레이아웃 파트에서 더욱 자세한 설명이 이어집니다.
[ V8의 Heap ]
V8 힙에는 부동 소수점 값, 문자열 문자, 인터프리터 바이트코드, 태그된 값 등 다양한 것들이 포함되어 있습니다. 힙을 살펴보니 실제 웹사이트에서 이 태그된 값들이 V8 힙의 70% 정도를 차지하고 있었습니다. 태그된 값이 무엇인지 자세히 알아볼까요?
[ V8의 값 태깅 ]
일반적으로 원시값은 스택에, 객체는 힙에 할당된다고 알려져있지만 V8에서 자바스크립트 값은 객체, 배열, 숫자, 문자열 여부에 관계없이 객체로 표현되고 V8 힙에 할당됩니다. 이를 통해 모든 값을 객체에 대한 포인터로 나타낼 수 있습니다.
[ Smi ]
V8 엔진은 포인터 태깅이라는 기법을 활용하여 특정 범위의 정수 값을 다른 개체와는 다르게 특별 취급합니다. 그리고 이에 해당하는 정수 값을 V8 엔진에서는 Smi라고 별도로 구분하여 지칭합니다. 정수가 증가할 때마다 새로운 숫자 객체를 할당하는 것을 피하기 위해 V8은 잘 알려진 포인터 태깅 기법을 사용하여 V8 힙 포인터에 추가 데이터,또는 대안 데이터를 저장합니다.
태깅(Tagging)이란 데이터나 포인터에 추가적인 정보를 포함시키는 것을 의미합니다. 메모리 사용이 더 효율적이 되고, 필요한 정보를 더 빨리 접근할 수 있습니다. 덕분에 추가적인 저장 공간을 사용하지 않고도 중요한 정보를 포인터에 포함시킬 수 있습니다.
태그 비트는 두 가지 목적으로 사용됩니다.
- V8 힙에 있는 객체를 가리키는 포인터가 강한 포인터인지 약한 포인터인지 표시합니다.
- smi를 나타냅니다.
- *강한 포인터(Strong Pointer): 객체를 직접 참조하는 포인터로, 객체가 가비지 컬렉션(메모리 해제)되지 않도록 방지
*약한 포인터(Weak Pointer): 객체를 참조하지만, 가비지 컬렉터가 객체를 해제할 때 방해하지 않는다. 객체가 더 이상 필요하지 않으면 메모리에서 제거될 수 있다.
따라서 정수의 값은 태그된 값에 직접 저장될 수 있으며, 추가 저장 공간을 할당할 필요가 없습니다.
V8 엔진은 메모리 주소의 가장 하위 비트를 사용해서 데이터 타입과 참조 유형을 구별합니다.
32 비트 시스템에서는,
가장 하위 비트가 0이면 작은 정수(Smi)로 간주합니다.
가장 하위 비트가 1이면 힙 객체 포인터로 간주하고, 두 번째 하위 비트로 강한 참조와 약한 참조를 구별합니다.
[ 32비트 ]
|----- 32 bits -----|
Pointer: |_____address_____w1|
Smi: |___int31_value____0|w는 강한 포인터와 약한 포인터를 구분하는 데 사용되는 비트입니다.
-230~230-1 범위의 정수값, 즉 31비트 부호있는 정수값이 직접 저장됩니다
32비트 플랫폼에서 -230~230-1 범위의 정수값, 31비트 부호있는 정수값이 직접 저장됩니다.
[ 64비트 ]
|----- 32 bits -----|----- 32 bits -----|
Pointer: |________________address______________w1|
Smi: |____int32_value____|0000000000000000000|
64비트 플랫폼에서 -231~231-1 범위의 정수값, 32비트 정수값이 직접 저장됩니다.
Smi는 힙 메모리에 할당되지 않는 즉치값이기 때문에 메모리 힙 스냅샷에 찍히지 않습니다.
[ 압축된 태그된 값과 새로운 힙 레이아웃 ]
포인터 압축을 통해 우리는 64비트 아키텍처에서 두 종류의 태그된 값을 모두 32비트로 맞추려고 합니다.
어떻게 맞출 수 있을까요?
-모든 V8 객체가 4GB 메모리 범위 내에 할당되도록 합니다.
-이 범위 내에서의 오프셋으로 포인터를 표현합니다.
[ 단순한 힙 레이아웃 ]
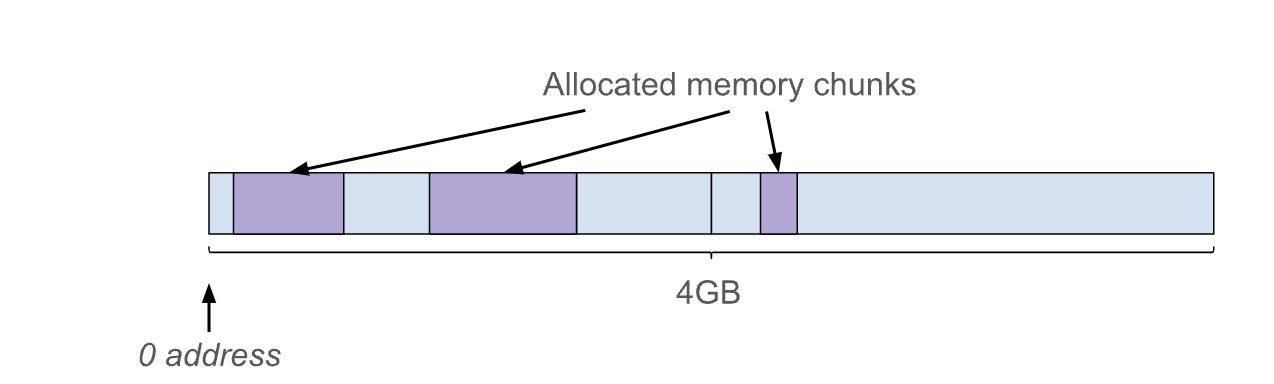
0에서부터 시작하는 방식입니다. 이는 V8에서 선택할 수 없는 방법입니다. Chrome의 렌더러 프로세스는 웹/서비스 워커 등을 위해 동일한 렌더러 프로세스에서 여러 V8 인스턴스를 만들어야 할 수 있습니다. 이 방식에서는 모든 V8 인스턴스가 동일한 4GB 주소 공간을 두고 경쟁하므로 모든 V8 인스턴스에 총 4GB 메모리 제한이 부과됩니다.
[ 힙 레이아웃 v1 ]
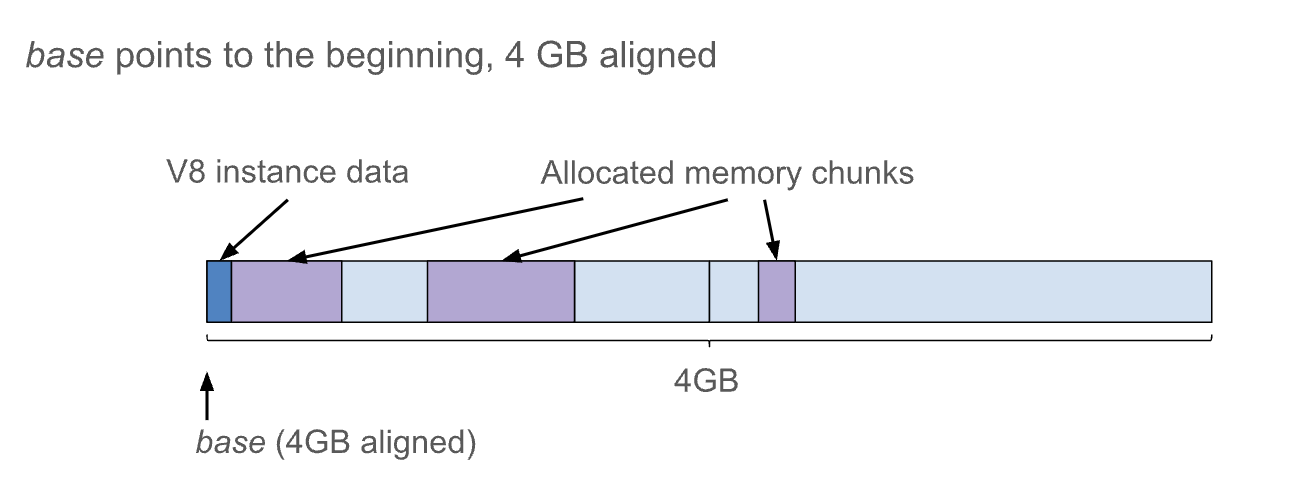
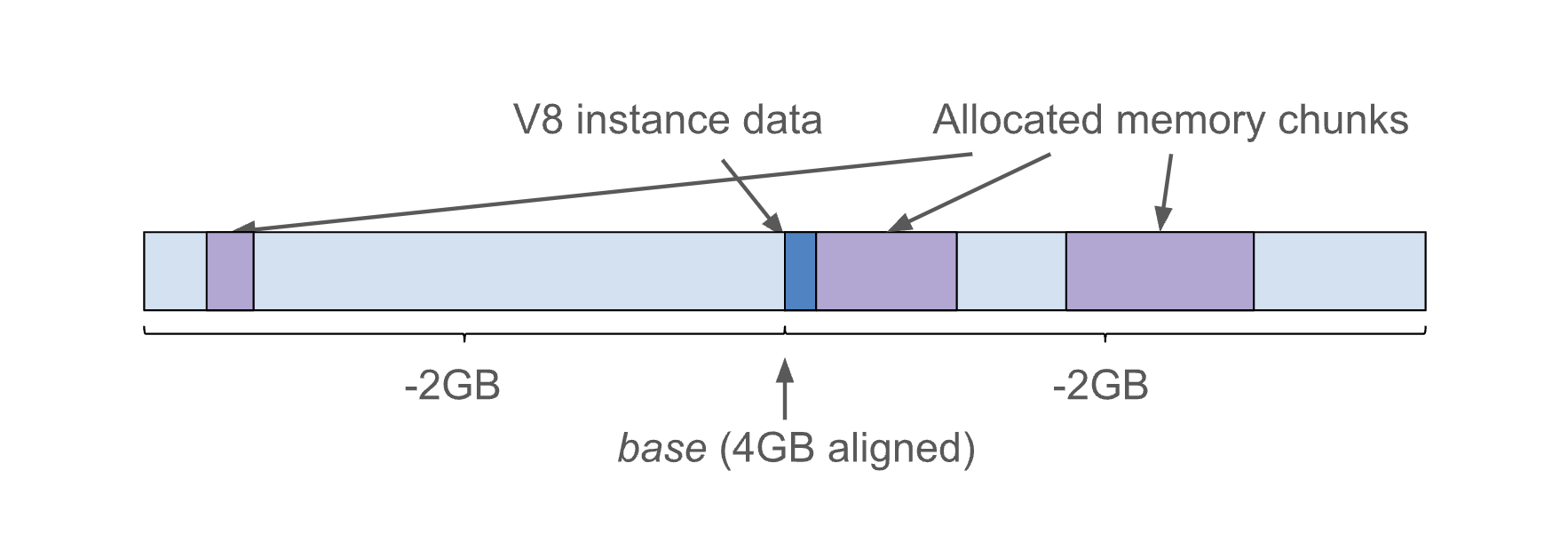
V8 힙을 연속된 4GB의 메모리 주소 공간에 배치한다고 가정하면,힙의 시작 주소(Base)로부터의 부호 없는 32비트 오프셋이 포인터를 고유하게 식별할 수 있습니다. 기준을 4GB로 정렬되도록 하면 상위 32비트는 모든 포인터에 대해 동일합니다.
Example :
힙메모리 배치
V8의 힙 메모리를 0x10000000에서 시작하는 연속된 4GB 공간에 배치한다고 가정합니다. 이 4GB는 0x10000000부터 0x1FFFFFFF까지의 주소를 포함합니다.
기본 주소(Base Address)
힙의 시작 주소(Base Address)는 0x10000000.
오프셋(Offset)
힙 내의 어떤 객체가 0x10001000 주소에 있다고 합니다. 이 주소는 힙의 시작 주소(Base Address)로부터 0x00001000만큼 떨어져 있습니다.
32비트 오프셋
이 오프셋을 32비트 값으로 표현하면 0x00001000이 됩니다. 따라서, 힙의 시작 주소와 오프셋을 조합하면 해당 객체의 정확한 위치를 고유하게 식별할 수 있습니다.
[ pointer ]
|----- 32 bits -----|----- 32 bits -----|
Pointer: |________base_______|______offset_____w1|
Smi 페이로드를 31비트로 제한하고 하위 32비트에 배치하면 Smi도 압축 가능하게 만들 수 있습니다. 기본적으로 32비트 아키텍처의 Smi와 유사하게 만드는 것입니다.
[ smi ]
|----- 32 bits -----|----- 32 bits -----|
Smi: |sssssssssssssssssss|____int31_value___0|
s는 Smi 페이로드의 부호 값입니다.
*32비트 아키텍처와 유사하게 31비트를 사용하고 0으로 태깅을 하고 있습니다.
[ 결과 ]
메모리를 절반으로 줄일 수 있습니다.
|----- 32 bits -----|
Compressed pointer: |______offset_____w1|
Compressed Smi: |____int31_value___0|[ 압축 해제 코드 ]
uint32_t compressed_tagged;
uint64_t uncompressed_tagged;
if (compressed_tagged & 1) {
// pointer case
uncompressed_tagged = base + uint64_t(compressed_tagged);
} else {
// Smi case
uncompressed_tagged = int64_t(compressed_tagged);
}압축 해제 코드는 좀 더 복잡합니다. Smi의 부호 확장과 포인터의 0 확장을 구분해야 합니다.
[ 부호확장 ]
컴퓨터에서 숫자의 비트 수를 늘릴 때, 원래 숫자의 부호를 유지하면서 확장하는 방법
[ 힙 레이아웃v2 ]
압축 방식을 변경하여 압축 해제 코드를 단순화해 봅시다.
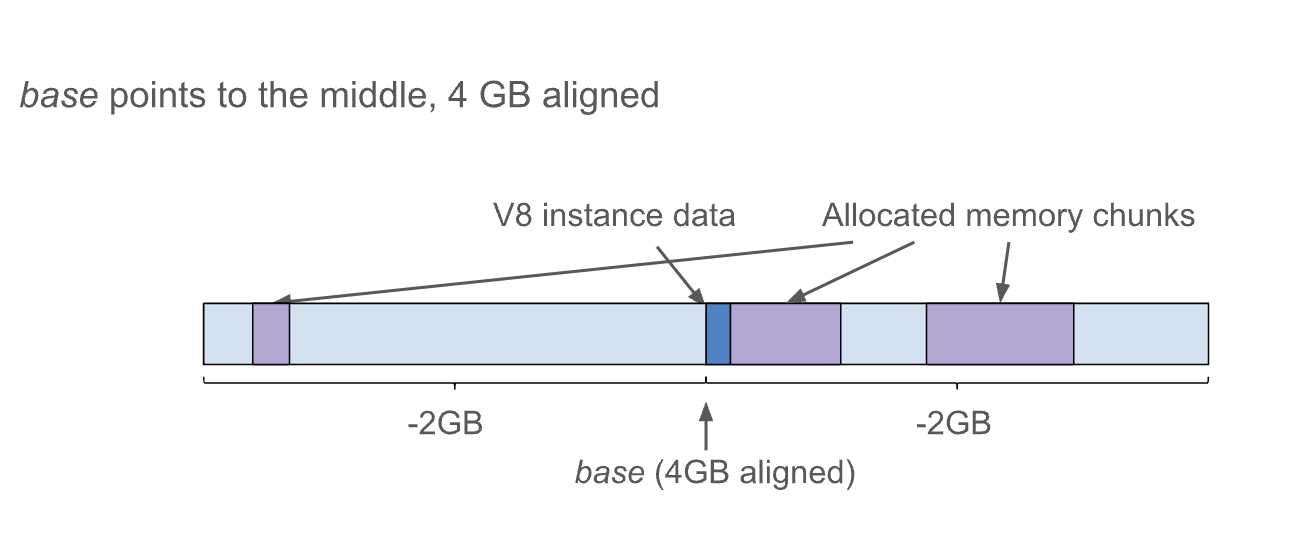
기존의 힙 레이아웃1 에서는 힙의 시작(base)이 4GB의 시작 부분에 위치했지만, 새로운 레이아웃2 에서는 힙의 시작(base)을 4GB 영역의 중간에 둡니다. 이렇게 하면 압축된 값을 기준(base)으로부터의 부호 있는 32비트 오프셋으로 처리할 수 있습니다.
[ 압축 해제 코드 ]
이 새로운 레이아웃에서 압축 코드는 동일하게 유지됩니다. 압축 해제 코드는 더 좋아집니다. 부호 확장은 이제 Smi와 포인터 경우 모두에 공통입니다. 분기(if)는 포인터 경우에 기준을 더할지 여부에 대한 것뿐입니다.
int32_t compressed_tagged;
// 포인터와 Smi 케이스 모두에 대한 공통 코드
int64_t uncompressed_tagged = int64_t(compressed_tagged);
if (uncompressed_tagged & 1) {
//uncompressed_tagged & 1을 통해 포인터인지 Smi인지를 구분.
// 포인터 케이스
uncompressed_tagged += base;
//uncompressed_tagged는 힙의 시작 주소(base)로부터의 오프셋 값
//따라서, 원래의 포인터 주소를 복원하기 위해 base를 더해야 함
}[ 분기 없이 압축 해제 구현 ]
한다면..더 나은 성능을 얻을 수 있지 않을까?
그래서 분기 없는 구현으로 시작하기로 결정했습니다.
int32_t compressed_tagged;
// Same code for both pointer and Smi cases
int64_t sign_extended_tagged = int64_t(compressed_tagged);
int64_t selector_mask = -(sign_extended_tagged & 1);
// Mask is 0 in case of Smi or all 1s in case of pointer
int64_t uncompressed_tagged =
sign_extended_tagged + (base & selector_mask);[ 코드설명 ]
1.부호 확장 (Sign Extension)
int64_t sign_extended_tagged = int64_t(compressed_tagged);-
compressed_tagged는 32비트 압축된 값입니다.
-
이를 64비트로 부호 확장하여 sign_extended_tagged에 저장합니다.
-
이 과정은 포인터와 Smi 모두에 동일하게 적용됩니다.
2. 선택자 마스크 생성 (Selector Mask)
int64_t selector_mask = -(sign_extended_tagged & 1);-
sign_extended_tagged & 1은 하위 비트를 검사하여 포인터인지 Smi인지를 판별합니다.
-
포인터인 경우 하위 비트가 1이고, Smi인 경우 하위 비트가 0입니다.
-
(sign_extended_tagged & 1)은 하위 비트가 1이면 -1 (모든 비트가 1인 64비트 값)이고, 하위 비트가 0이면 0이 됩니다.
3. 압축 해제 (Uncompressed Tagged)
int64_t uncompressed_tagged = sign_extended_tagged + (base & selector_mask);-
base & selector_mask는 포인터일 경우에만 base 값을 유지합니다.
-
따라서, sign_extended_tagged + (base & selector_mask)는
포인터일 경우: sign_extended_tagged에 base를 더한 값이 됩니다.
Smi일 경우: sign_extended_tagged 그대로의 값이 됩니다.
다음 글 스포 : 분기 없는 코드가 더 빠르다? .. (x)
[ 마무리 ]
V8의 많은 노고가 느껴지시나요? 해당 글은 v8 포인터 압축 원문을 보고 여러분에게 쉽게 풀어 설명하기 위해 작성된 글입니다. 꼭 원문 블로그 글도 함께 읽는 것을 권장드립니다.
내가 혼자 공부하는 컴퓨터 + 운영체제 책을 완독한 이유(부제:v8)
"스택 포인터란 뭘까?"
"tagged pointer가 뭐지?"
"왜 메모리 할당을 이렇게까지 해서 아껴야하는거지..?"
기술 블로거 모여라! 스터디의 첫 번째 글의 주제는 "포인터 압축" 이었습니다. 해당 글을 작성하면서 제가 가졌던 궁금증들이 해결되었습니다. 공부하는데 많은 도움을 주신 척척석사님 Lukas 감사합니다. 2편은 v8 성능 발전으로 돌아오겠습니다.

2개의 댓글

V8 작동원리에 대해 어느정도 파보았다고 생각했는데, Heap 메모리에서 offset기반으로 포인터를 관리하는 방식은 처음 알았어요.
정말 정말 흥미롭고 좋은 내용이네요.
앞으로도 좋은 글 계속 부탁드리겠습니다!
정말 어렵지만 유익한 글이였어요. 분기가 없는 코드가 빠르다 (X)도 너무 기대가 됩니다.