강의 영상 주소 : https://www.youtube.com/watch?v=YAgjfMR9R_M&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=15
해당 슬라이드: https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture13.pdf
✍️ [p.5 ~ p.72] 내용 요약정리

Seq2Seq with RNNs
-
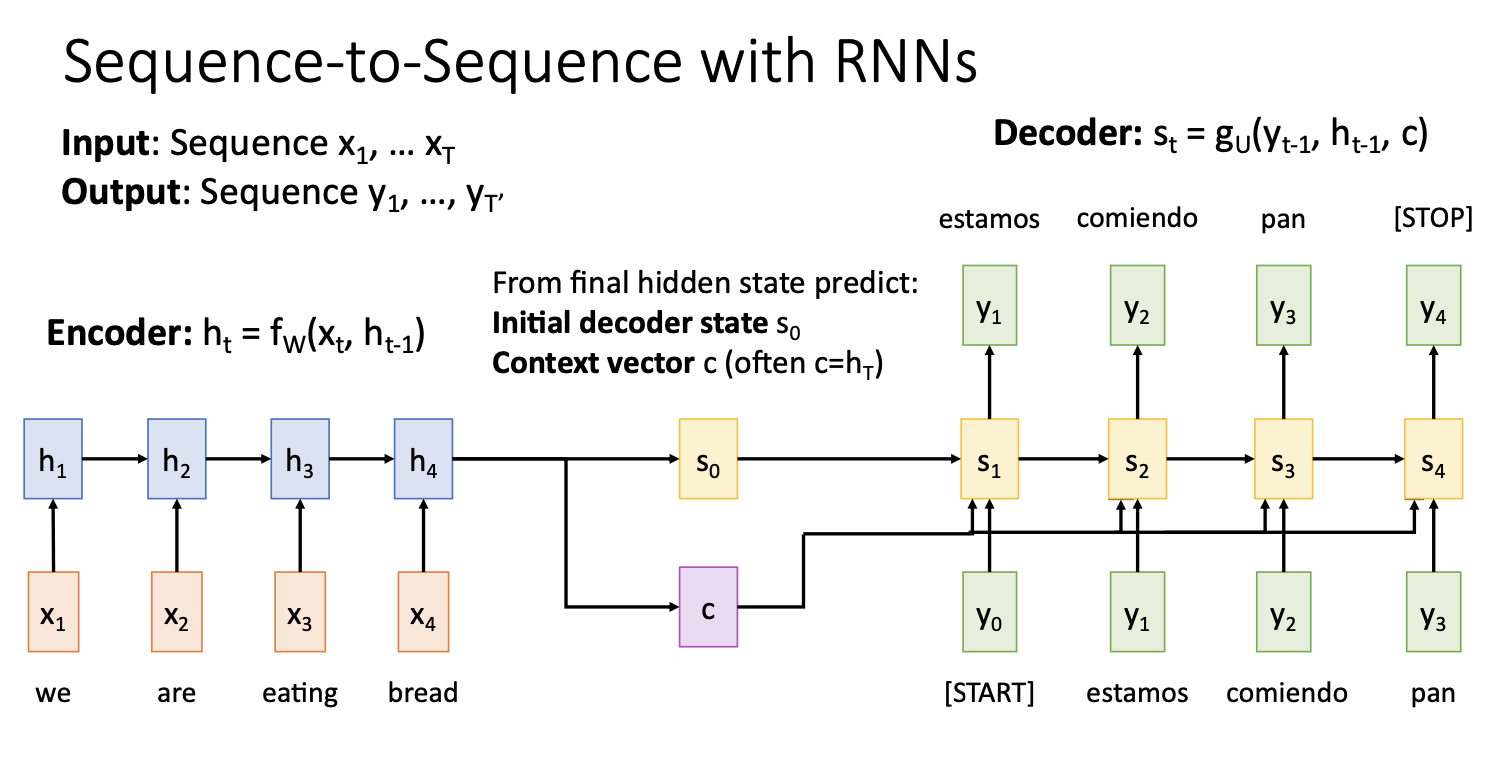
input은 영어문장, output은 스페인어 문장(영어문장을 스페인어 문장으로 만드는 예)
-
encoder에서는 input sequence를 받아서 t만큼의 step을 거쳐 hidden state를 만들고 이것을 decoder의 첫 번째 hidden state 와 context vector로 사용한다.
-
Decoder에서는 input인 START token을 시작으로 이전 state(첫번째에선 )와 context vector를 통해서 hidden state 를 만들고 이를 통해서 output 를 계산함
-
이 output을 input으로 넣어서 STOP token을 output으로 출력할 때 까지 step반복
-
이때 context vector는 input sequence를 요약하여 decoder의 매 step에서 사용되며 encoded sequence와 decoded sequece사이에서 정보를 전달하는 중요한 역할을 함
-
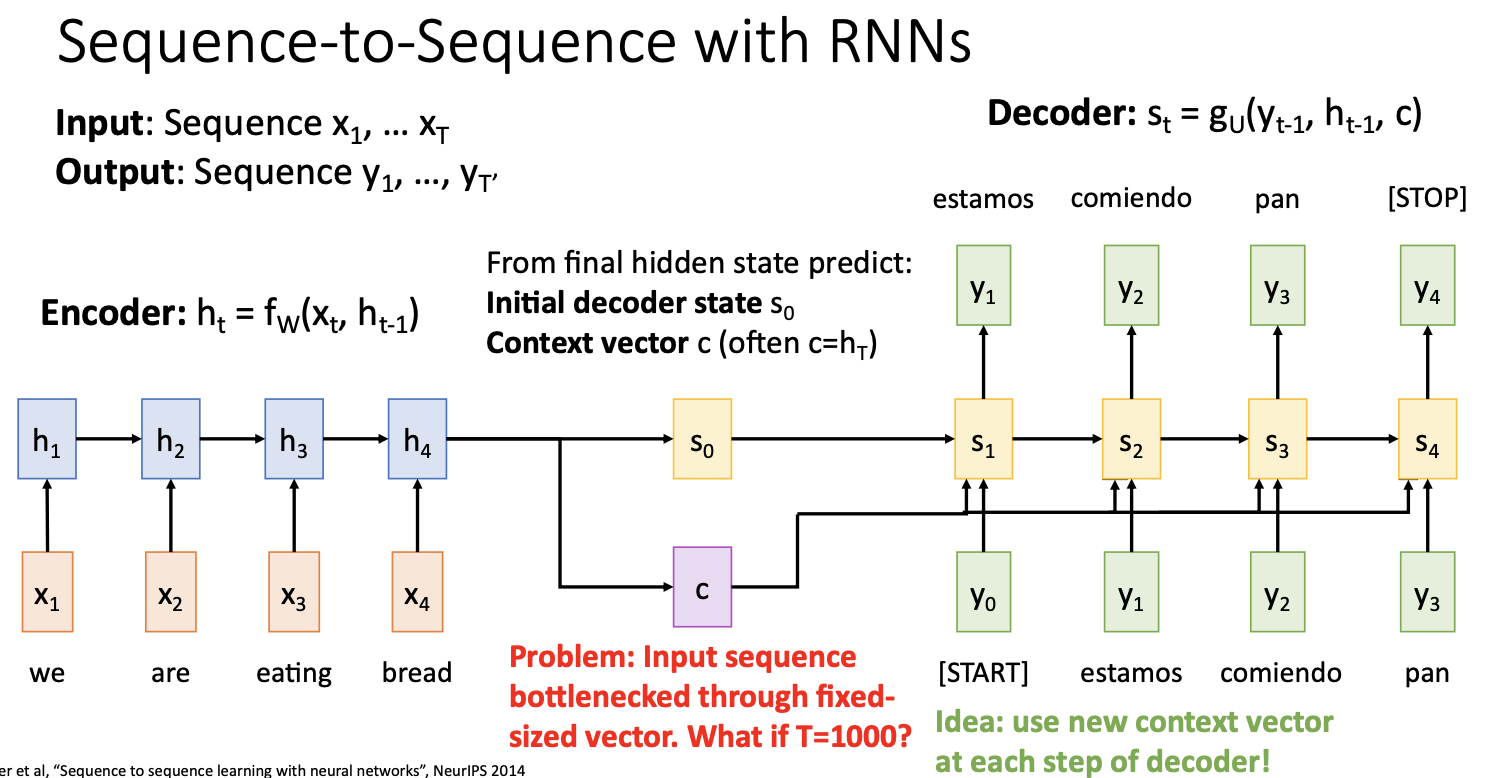
context vector c는 decoder가 sequence를 생성하는데 필요한 모든 입력 문장의 정보를 요약한 것이라서 매우 중요한 역할을 하는데, 매우 긴 문장이나 문서를 처리할 때에는 문제가 있음
-
하나의 vector로 아주 많은 문장들을 요약하는 과정에서 정보가 bottleneck된다.(input sequence의 정보가 bottleneck되는것)
-
이 문제의 해결방안으로 decoder의 매 time step마다 새로운 context vector를 계산하는 것을 생각해 볼 수 있는데 이것이 Attention의 아이디어!
-
자세하게 말하자면, 매 time step마다 decoder가 input sequence의 다른 부분에 초점을 맞춘 새로운 context vector를 선택하도록 하는 것이다.
<Bottleneck, 병목>
전체 시스템의 성능이나 용량이 하나의 구성요소로 인해 제한을 받는 현상. FFNN에서는 hidden layer1이 10차원인데 hidden layer2가 100차원인 등, 데이터가 축약되었다가 다시 확장되는 구조를 말한다.
Seq2Seq with RNNs and Attention
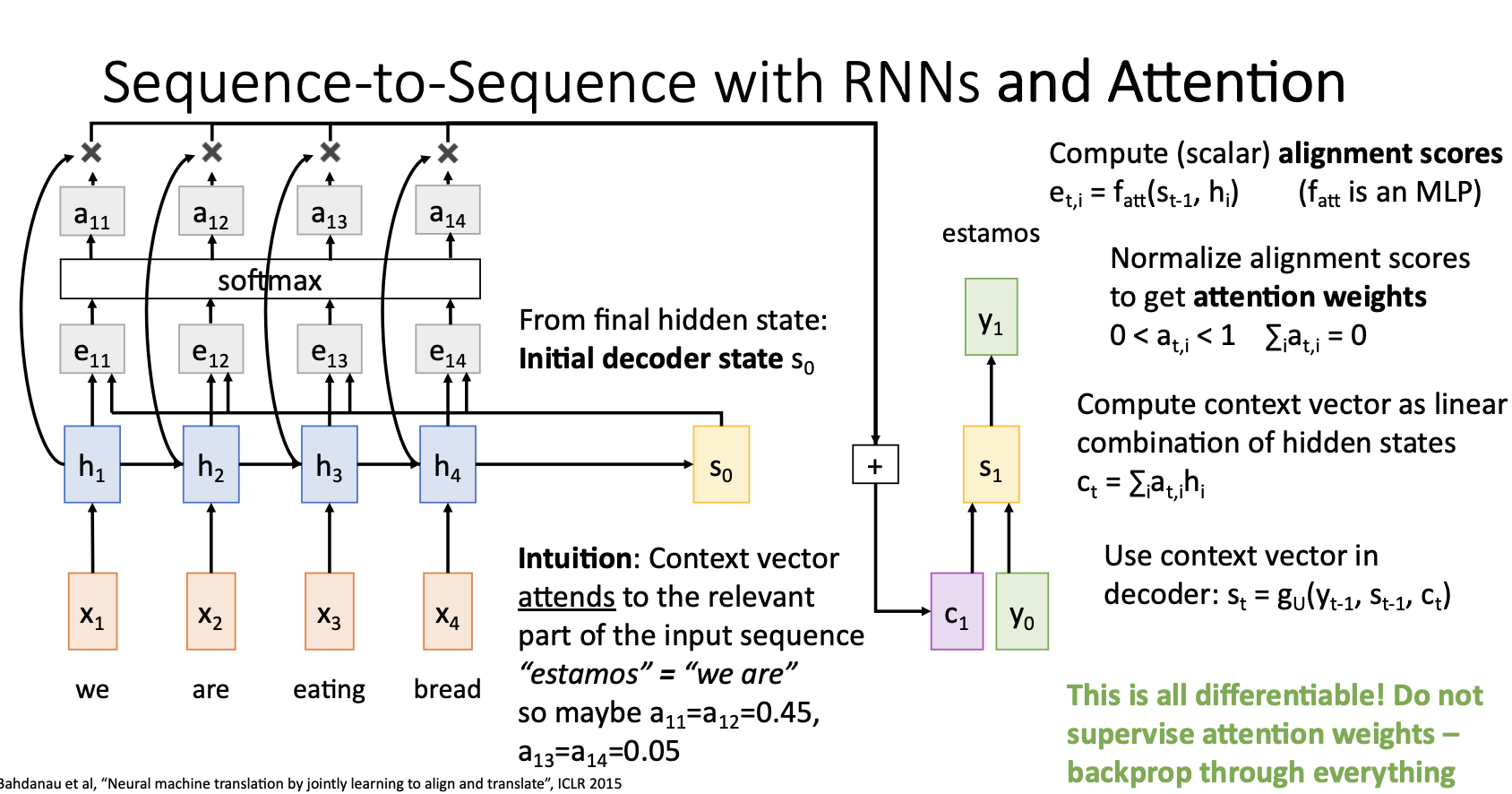
Decoder의 매 step별 context vector를 재 생성하는 Attention mechanism을 살펴보자.
-
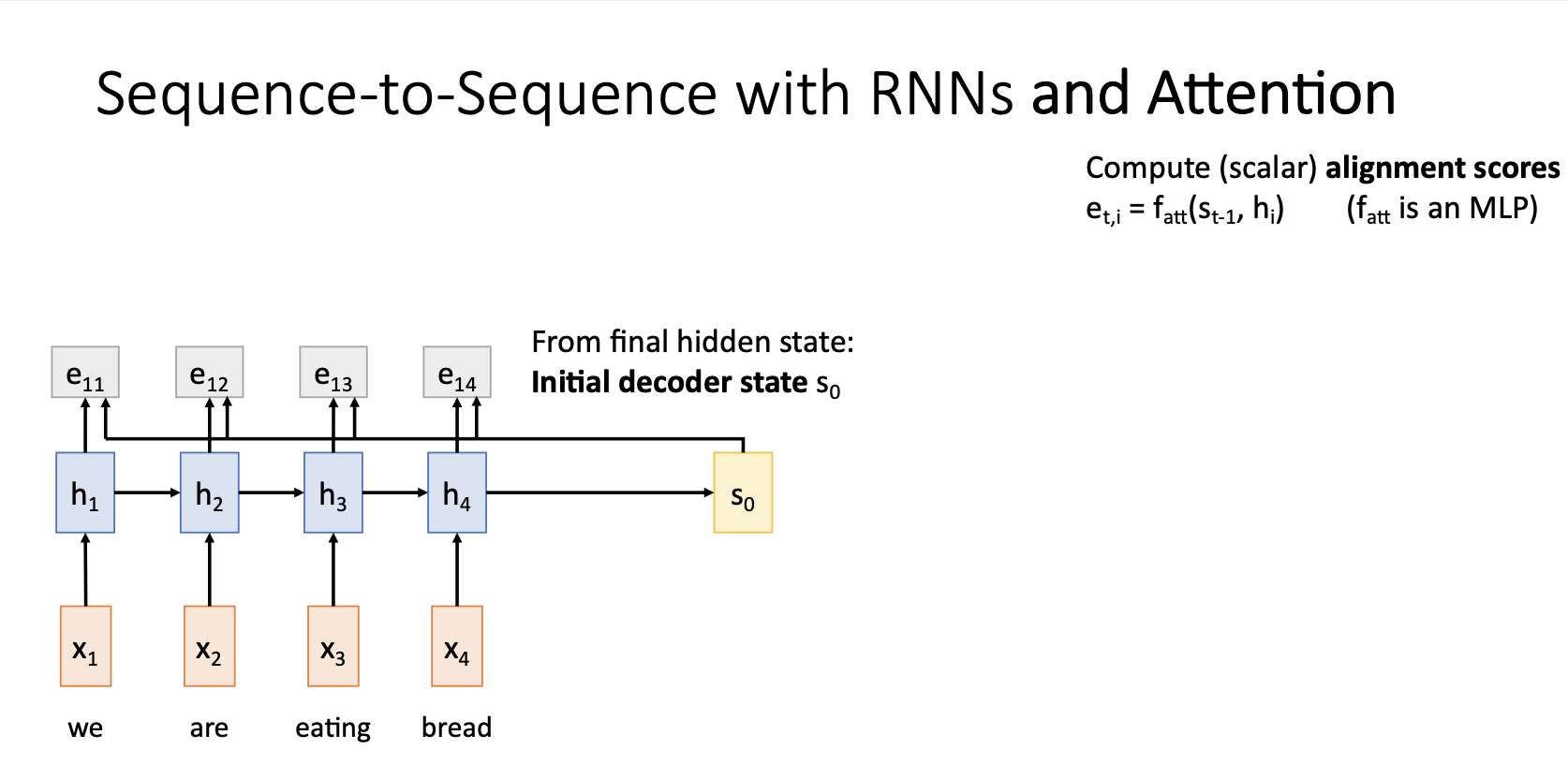
Attention을 적용한 Seq2Seq 모델에서는 alignment function 를 통해서 계산한 ailgnmemt score 를 통해서 decoder의 매 time step마다 새로운 context vector를 생성함
-
alignment function 는 decoder의 hidden state 와 encoder의 hidden state 를 입력받아 동작하는 아주 작은 Fully Connected Network.
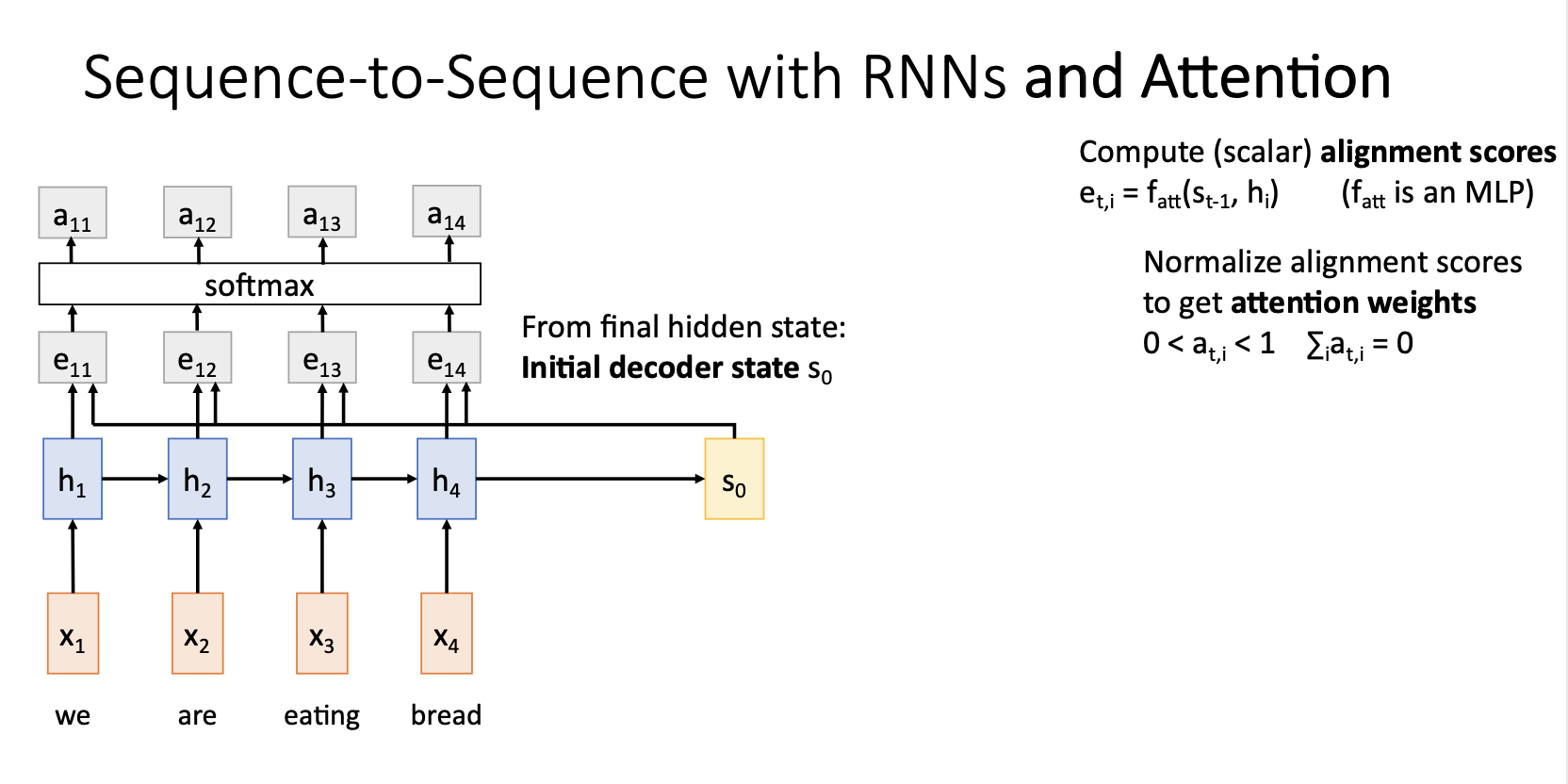
- 이전의 output score()를 softmax를 통해서 0~1사이의 값을 갖는 probability distribution으로 나타내고 이러한 softmax의 output을 attention weights 라고 하고 이는 각 hidden state에 얼마나 가중치를 둘 것이냐를 나타낸다.
-
Attention weights와 각 hidden state를 weighted sum해주어 t시점의 새로운 context vector 를 구해준다.
-
Decoder는 이러한 context vector 와 input 이전 state인 을 사용해서 t시점의 state 를 생성하고 이를통해 predict된 output을 생성해준다.
-
위 그림의 computational graph에 나타나는 모든 연산들은 differentiable하기 때문에 backprop이 가능하고 이로인해 network가 알아서 decoder의 time step별 input의 어느 state에 attention 해야하는지 학습하게 된다.
-
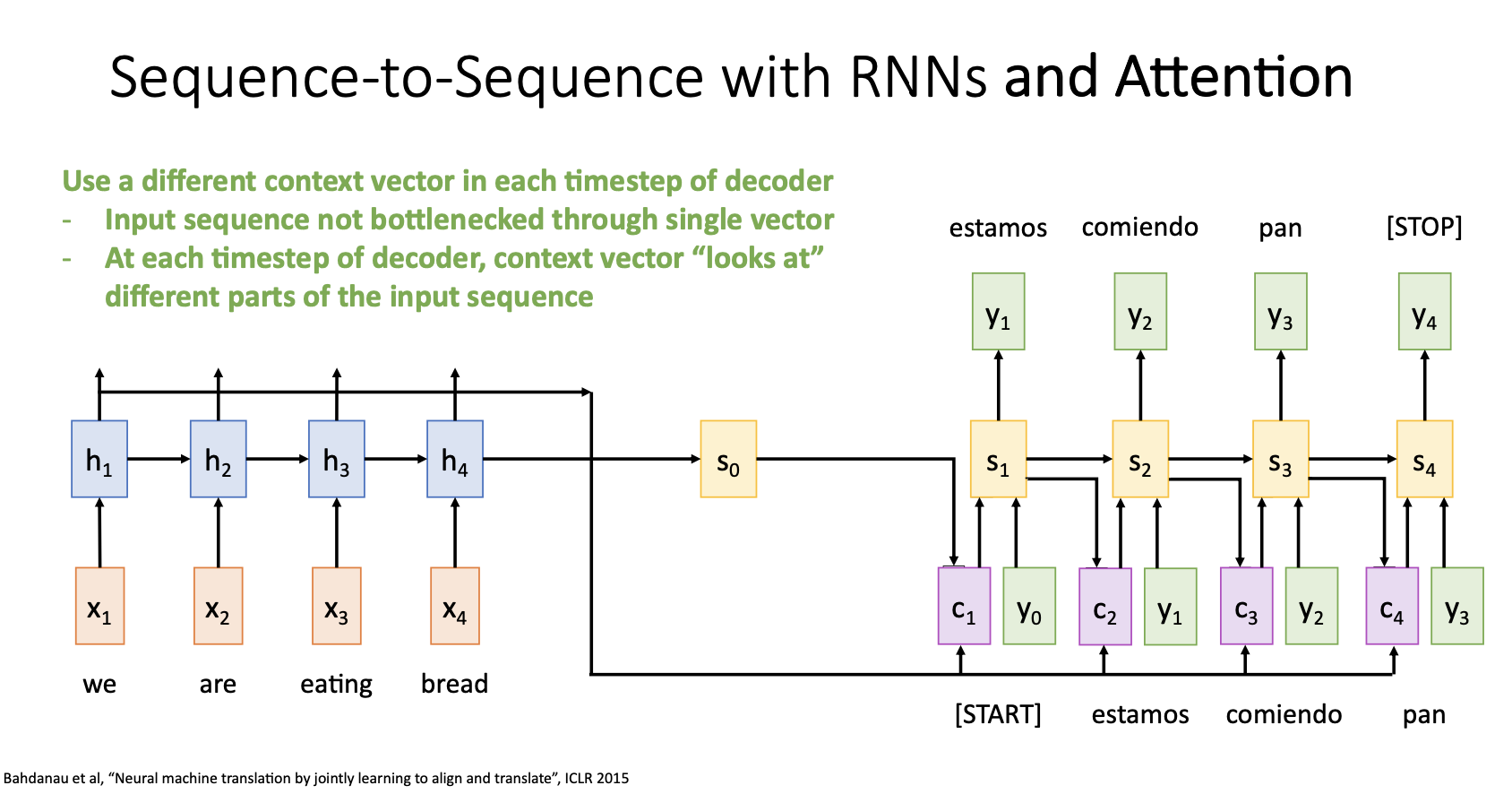
이러한 과정을 decoder의 time step마다 반복해서 사용하고 기존의 seq2seq처럼 decoder가 STOP token을 출력하면 멈추게 된다.
-
Attention을 적용한 seq2seq를 요약하자면
- input sequence의 모든 정보를 하나의 context vector에 요약하는 것 대신에, 디코더의 각 time step마다 새로운 context vector를 생성하도록 유연성을 제공하면서 bottleneck 문제를 해결- 각 time step의 output마다 input sequence에서 집중할 부분을 스스로 선택하면서 context vector를 생성
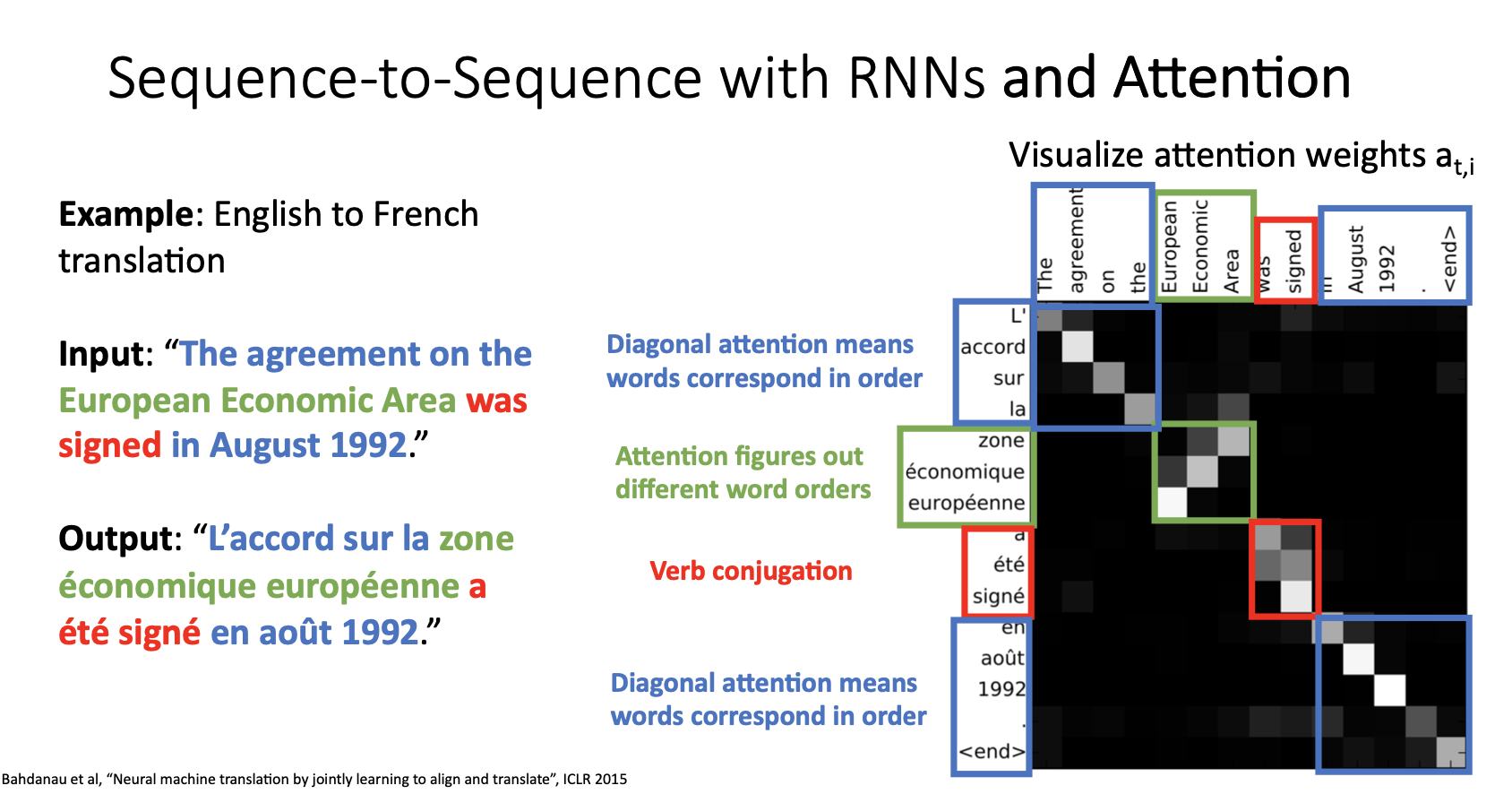
- 위 그림은 영어를 프링스어로 번역하는 예시로 seq2swq with attention 모델이 decoder 시점별 단어를 생성해낼 때 attention weights를 나타낸 것으로 모델이 시점별로 input의 어느 state에 집중하고있는지를 보여준다.
-
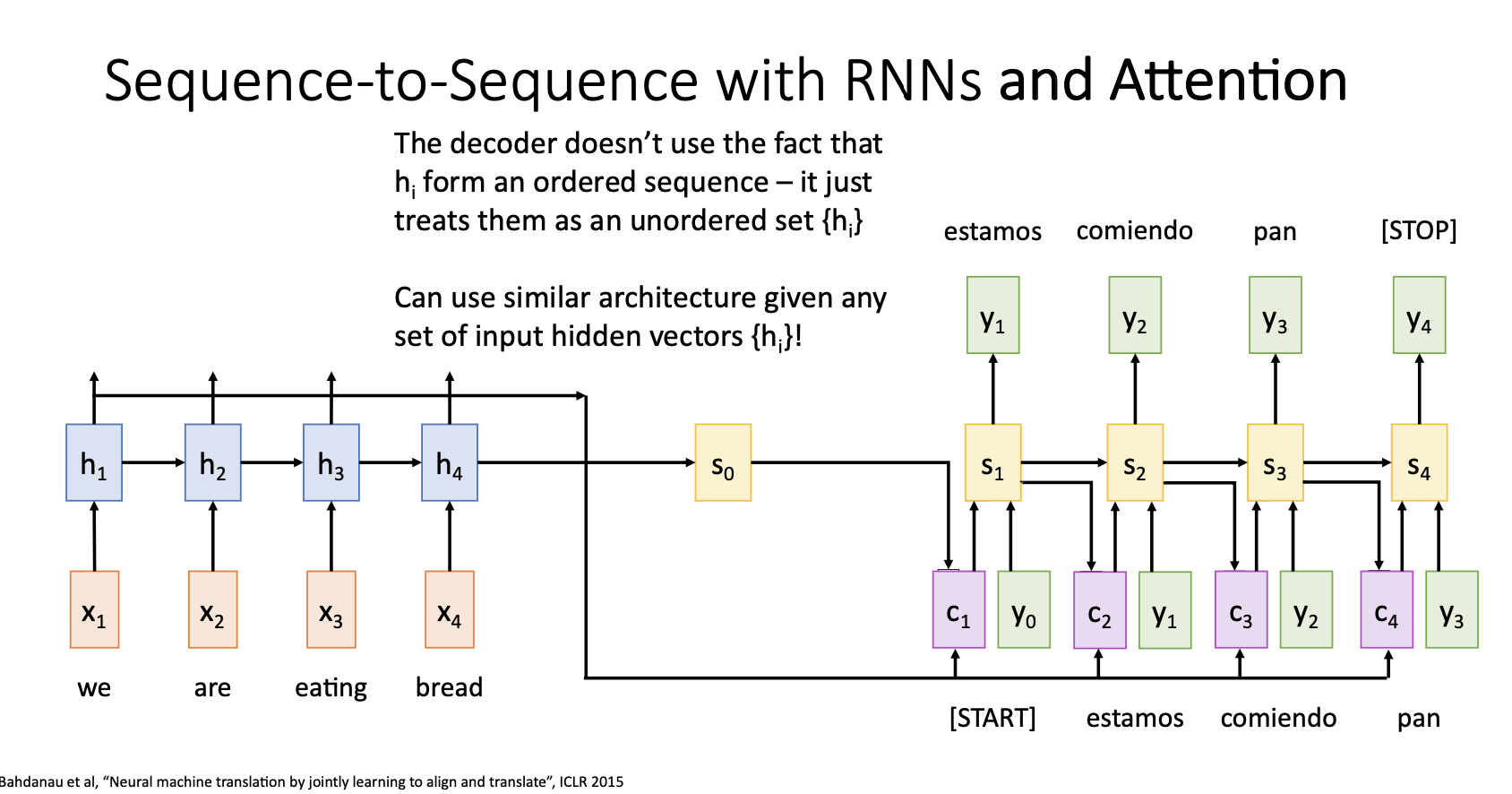
지금까지 기계 번역에 사용한 Attention mechanism의 구조를 자세히 살펴보면, 입력이 시퀀스인지에 대해서 전혀 신경쓰지 않았다는 것을 알 수 있다.
-
이는 입력 데이터의 형태가 시퀀스가 아닌 다른 모델들에도 Attention mechanism을 사용할 수 있다는 것을 의미한다.
Image Captioning with Attention
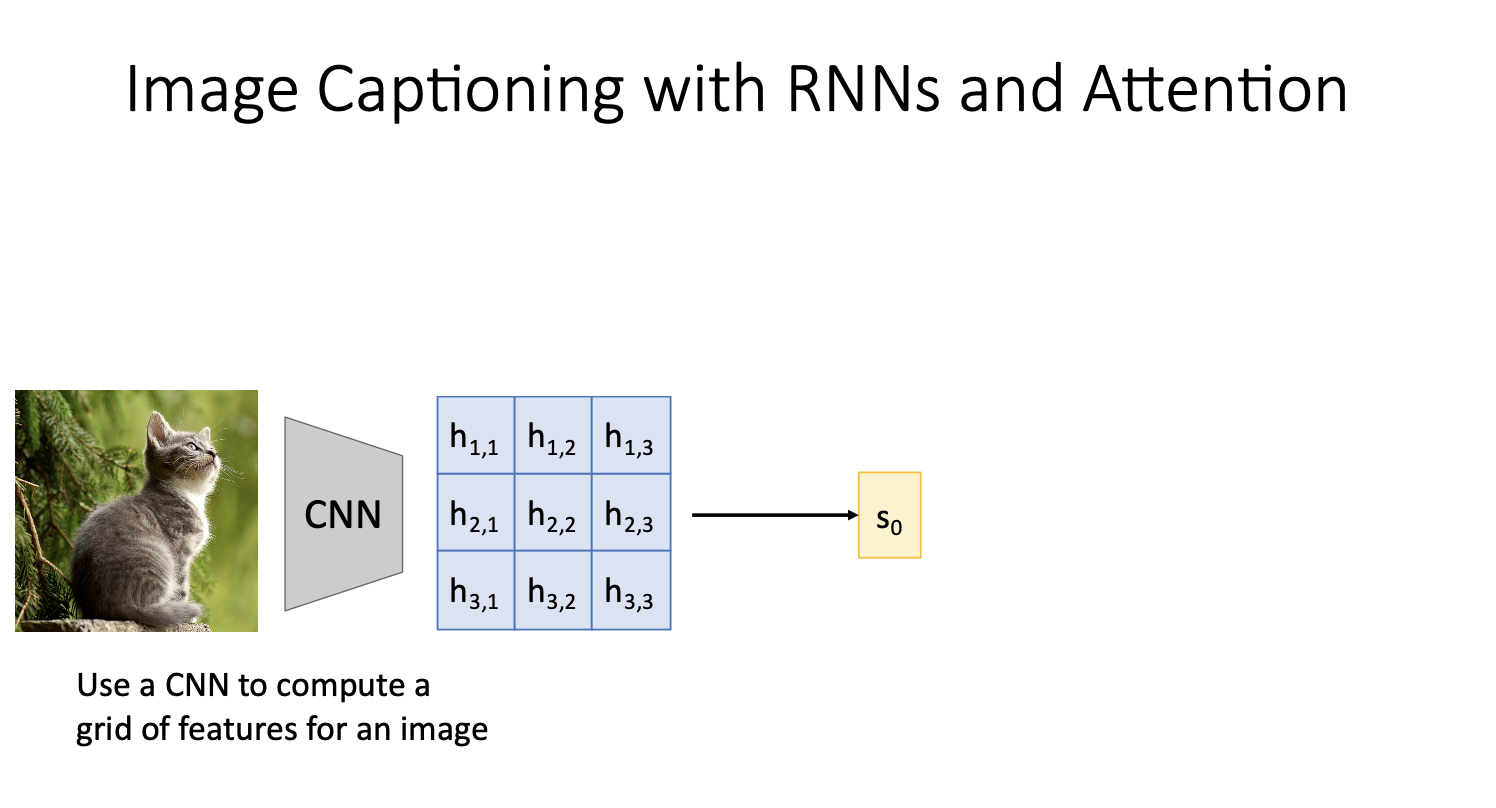
-
일단 RNN만을 사용한 image captioning에서 FC layer를 통한 feature vector(sequece vector)를 RNN모델의 input으로 사용한 것과 다르게 위 그림처럼 CNN에서 grid of feature vectors를 뽑아내 이것을 RNN모델에 input으로 집어넣는다.
-
이때 grid of feature vectors는(~) 각각 spatial position에 해당됨
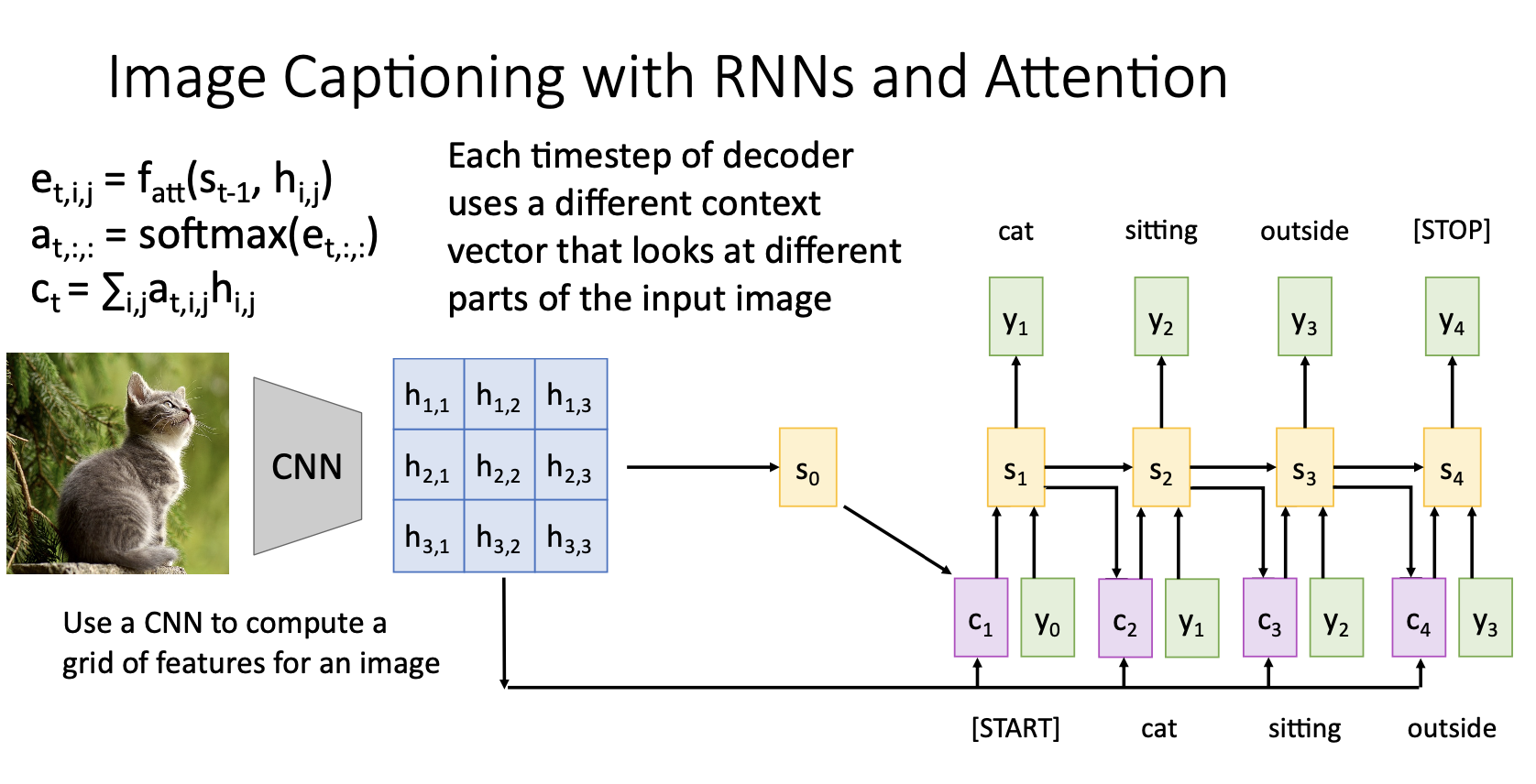
-
위 과정들을 반복하면 image caption을 모두 생성
-
Image Captioning에 적용한 attention도 전에 번역문제에서 수행한 것과 매우 유사한방법
-
Image Captioning에서의 attention은 결국 image caption의 단어를 생성하는 각 단계에서 grid의 각기 다른 feature vector들이 decoder의 현재 state인 와 weighted sum시켜 새롭게 context vector를 만든것이다.
▶️ Examples
Attention을 적용한 image captioning 예시
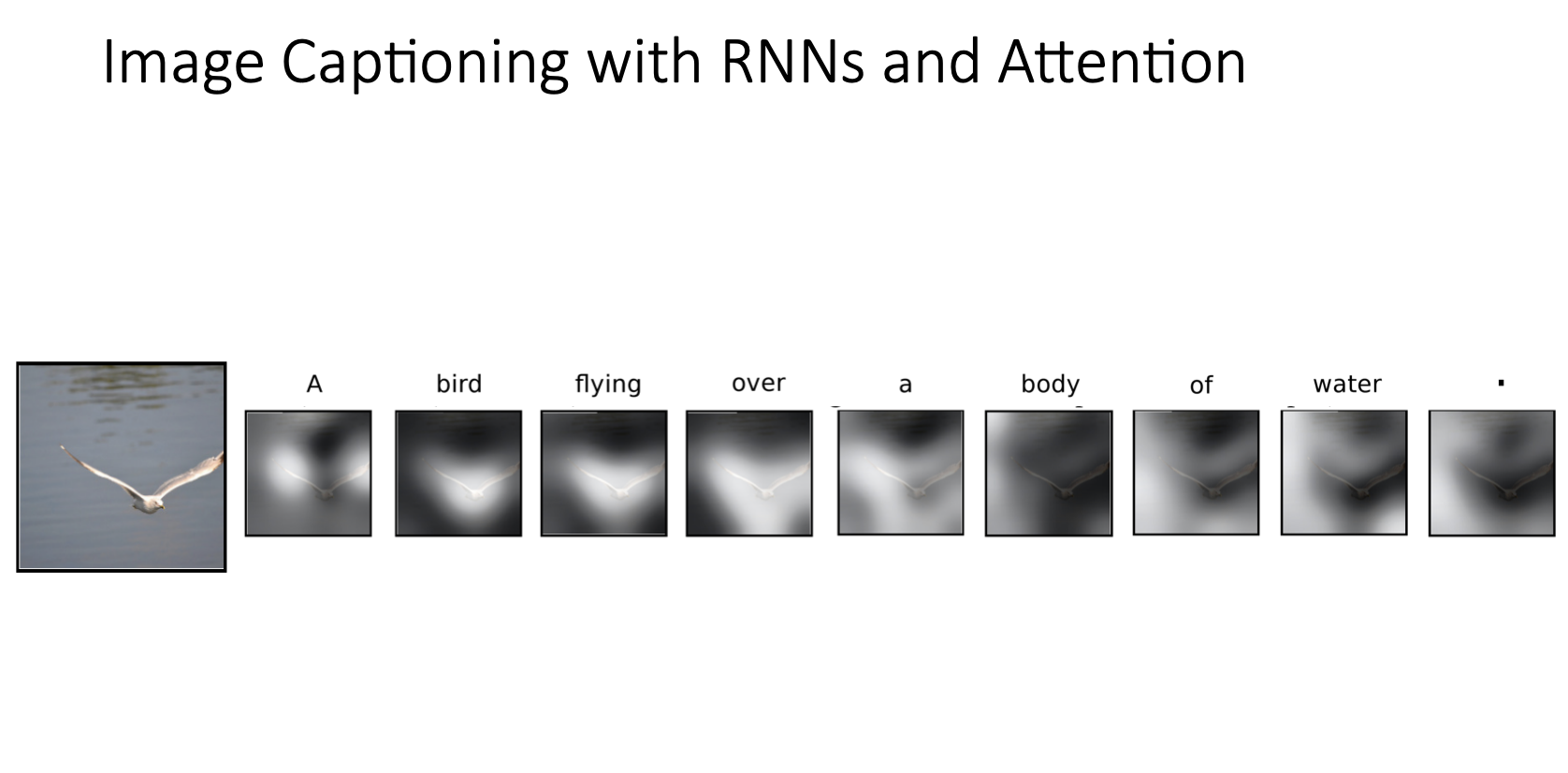
-
위 그림은 물 위를 날고 있는 새 이미지를 입력으로 받아서 모델이 "A bird flying over a body of water."를 출력하는 과정에서 문장의 각 단어별로 image grid에서 높은 가중치를 보이는 부분들을 보여준 것
-
bird라는 단어부분에서는 새 주변에 하이라이트되어서 높은 가중치를 보였다는 것을 알 수 있음

- 위 그림은 또 다른 예시인데 밑줄 친 단어들을 생성할 때 한 단어를 생성하는 state에서 입력 이미지의 어떤 곳에 높은 가중치가 부여되어서 attention되는지 시각화한 것
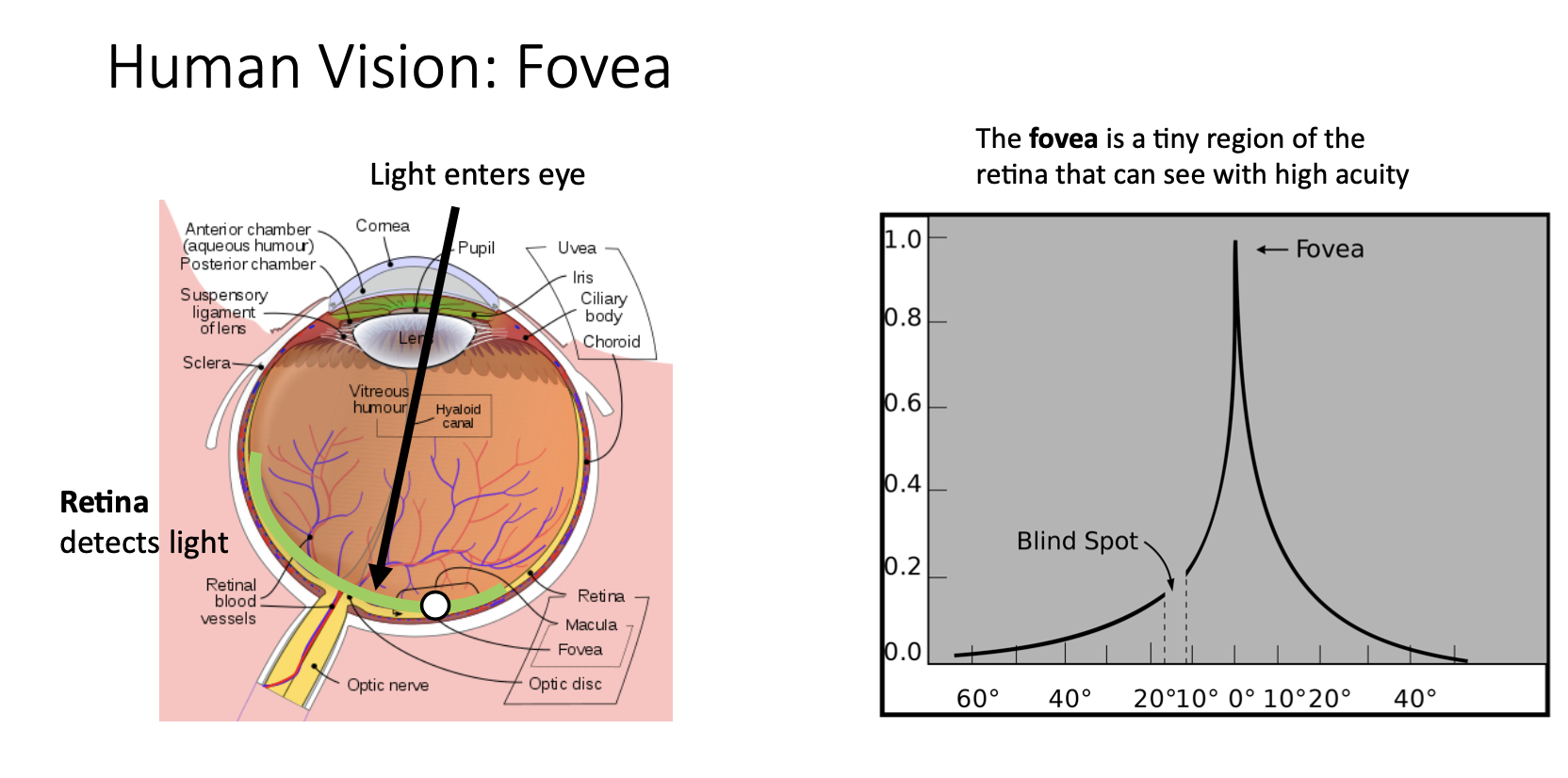
- 이런 image captioning에서의 attention은 생물학적인 관점에서 봤을 때 왼쪽 그림을 보면 우리 눈의 망막에는 fovea라는 작은 영역이 있는데 이 곳에 맺히는 상만 선명하게 볼 수 있음
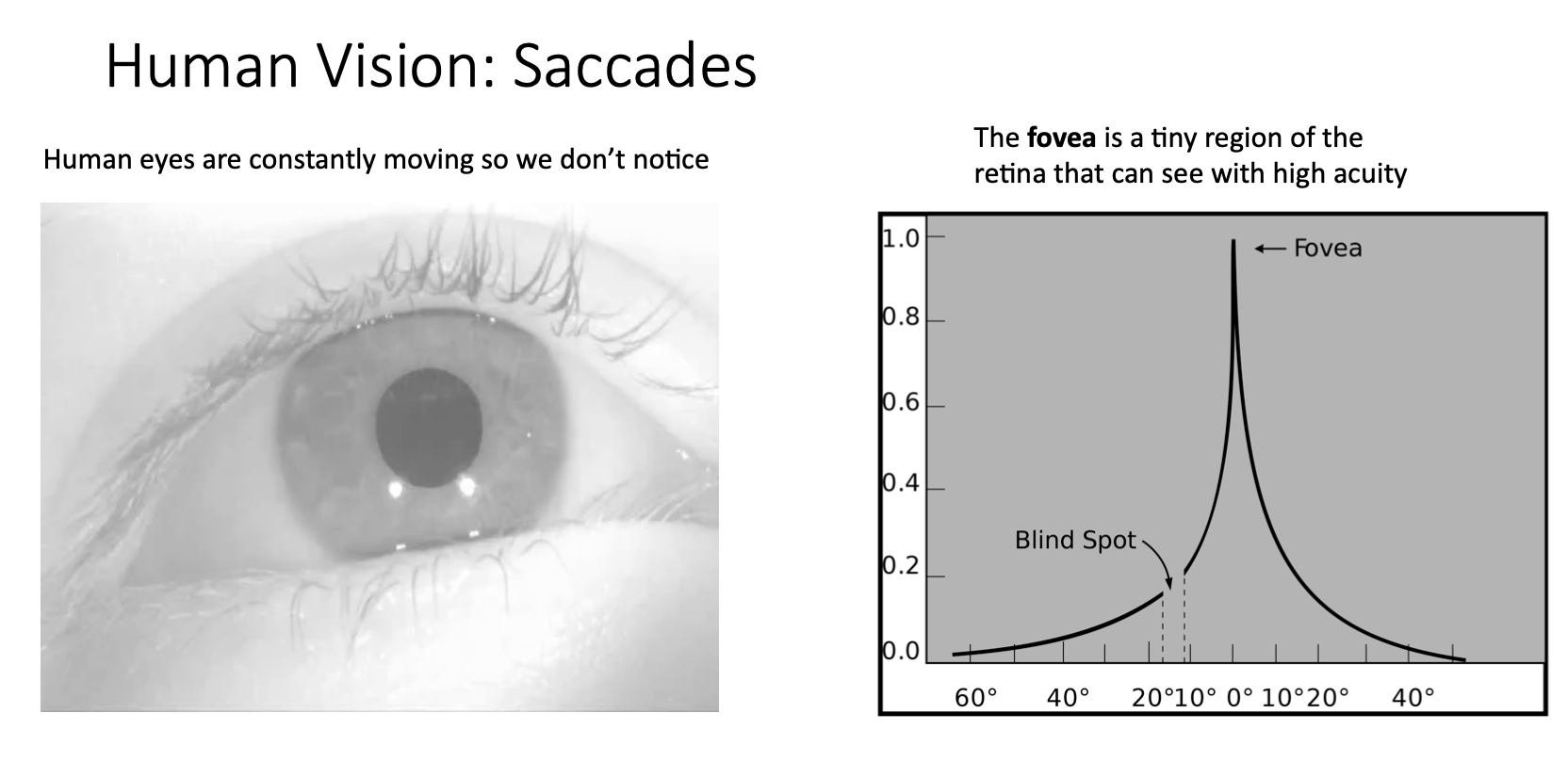
-
우리가 어떤 풍경을 봤을 때 보이는 풍경들을 한번에 동시에 다 인지하고 있다고 생각할 수 있지만 사실은 그 풍경들을 다 인지하기 위해서 사람의 동공을 바쁘게 움직이면서 인지하고 있는 것
-
fovea에 맺히는 상만 선명하게 보이는 이런 한계를 극복하기 위해서 사람의 눈이 계속해서 움직이면서 인지하게 되는건데 이런 움직임을 saccade라고 함
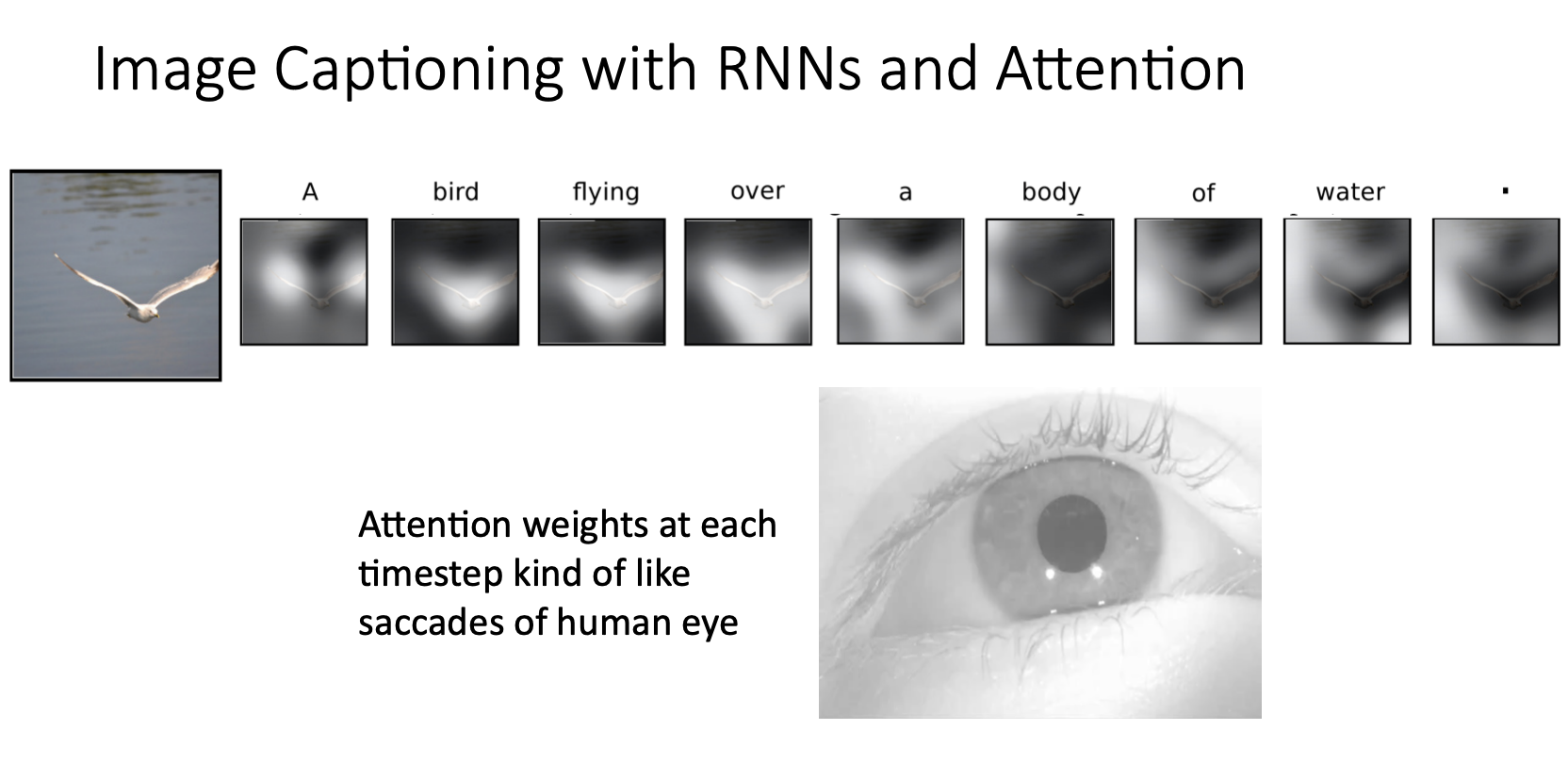
- 그래서 Attention이 각 step마다 이미지의 여러부분을 빠르게 움직이면서 보는것을 saccading에서 영감을 받은 것임
Attention Layer

-
Attention이 2015년에 나오고 나서 이 attention을 사람들이 다양하게 적용을 하게 됨
-
지금까지 봤던 attention mechanism을 여러 task에 사용할 수 있기때문에 쉽게 사용하기 위해서 Layer 형태로 일반화를 시키려고 함
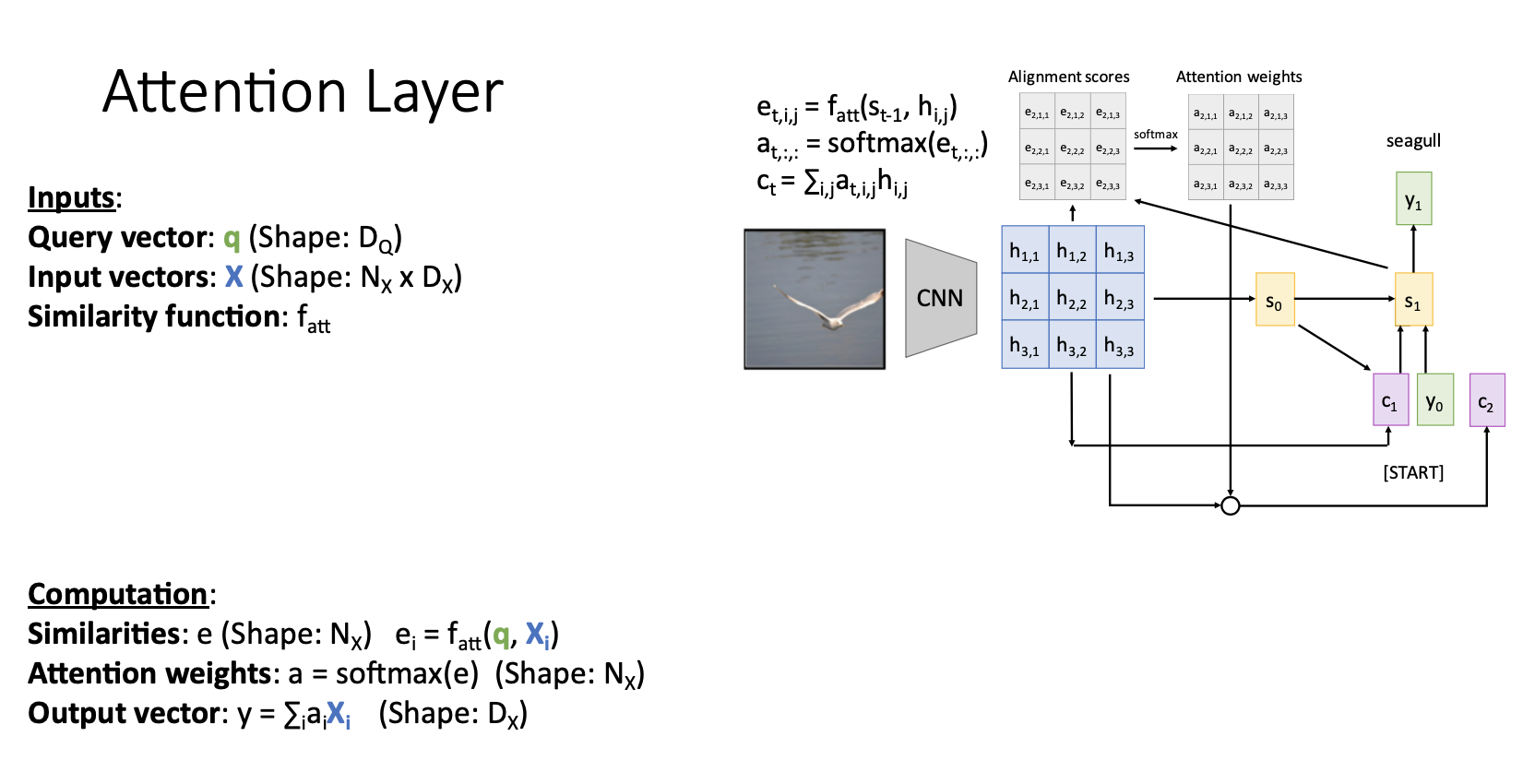
- attention mechanism을 attention layer로 일반화 하는 과정에서 아래와 같은 방식으로 reframe 시킴
-
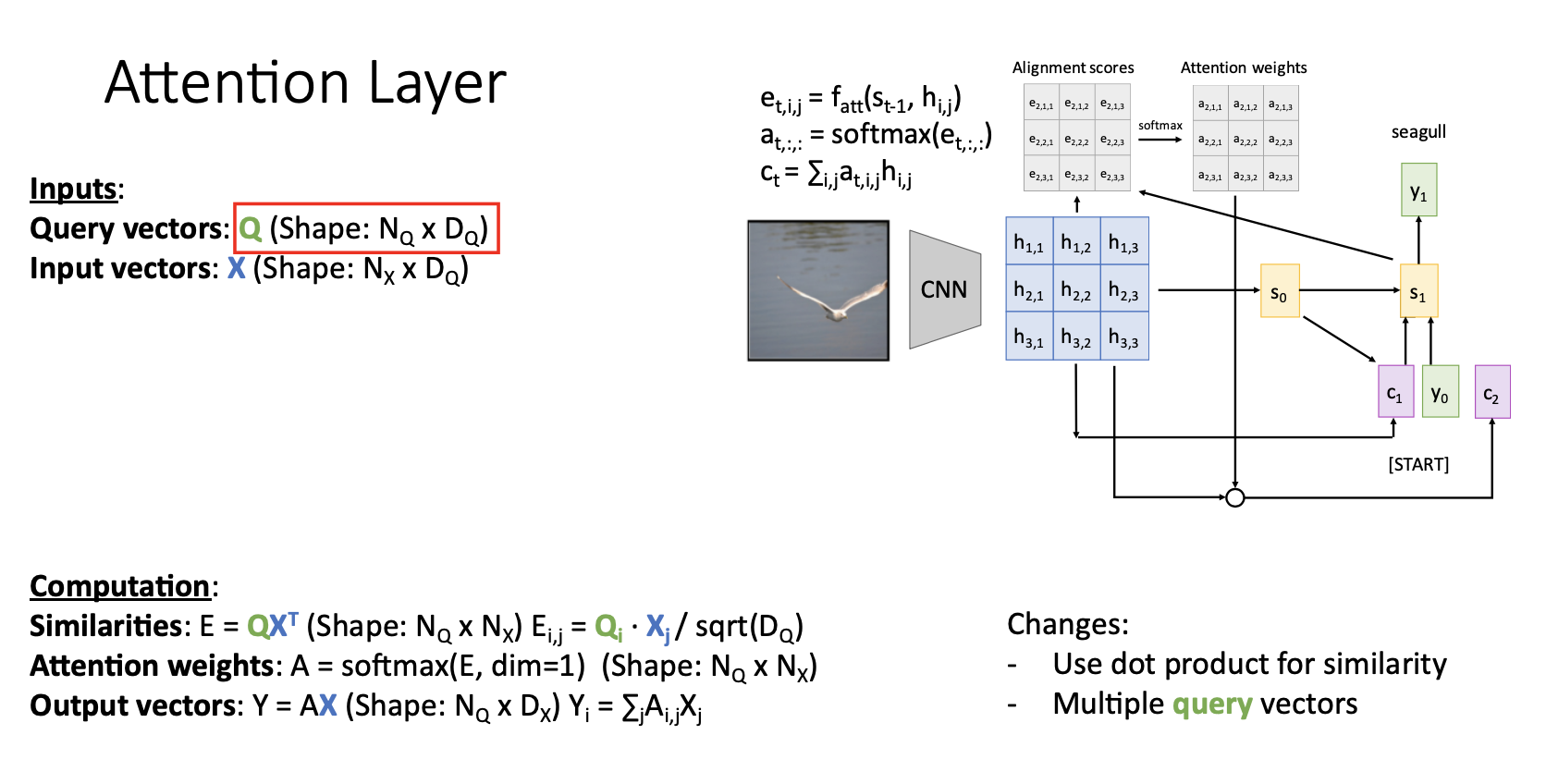
Inputs
- Query vector q : decoder의 현재 시점의 이전 hidden state vector (각각이 들이 t시점의 query vector가 되는것임)- Input vectors X : encoder의 각 hidden state()의 collection
- Similarity function tt : query vector와 각 input vector()를 비교하기 위한 함수이다.
-
Computation
- Similarities : query vector q와 input vector 를 similarity function 연산으로 unnormalized similarity scores를 얻음- Attention weights : similarity function을 통해서 얻은 를 softmax를 거쳐서 normalized probabilty distribution을 얻음
- Output vector : Attention weights와 input vector를 weights sum()
-
-
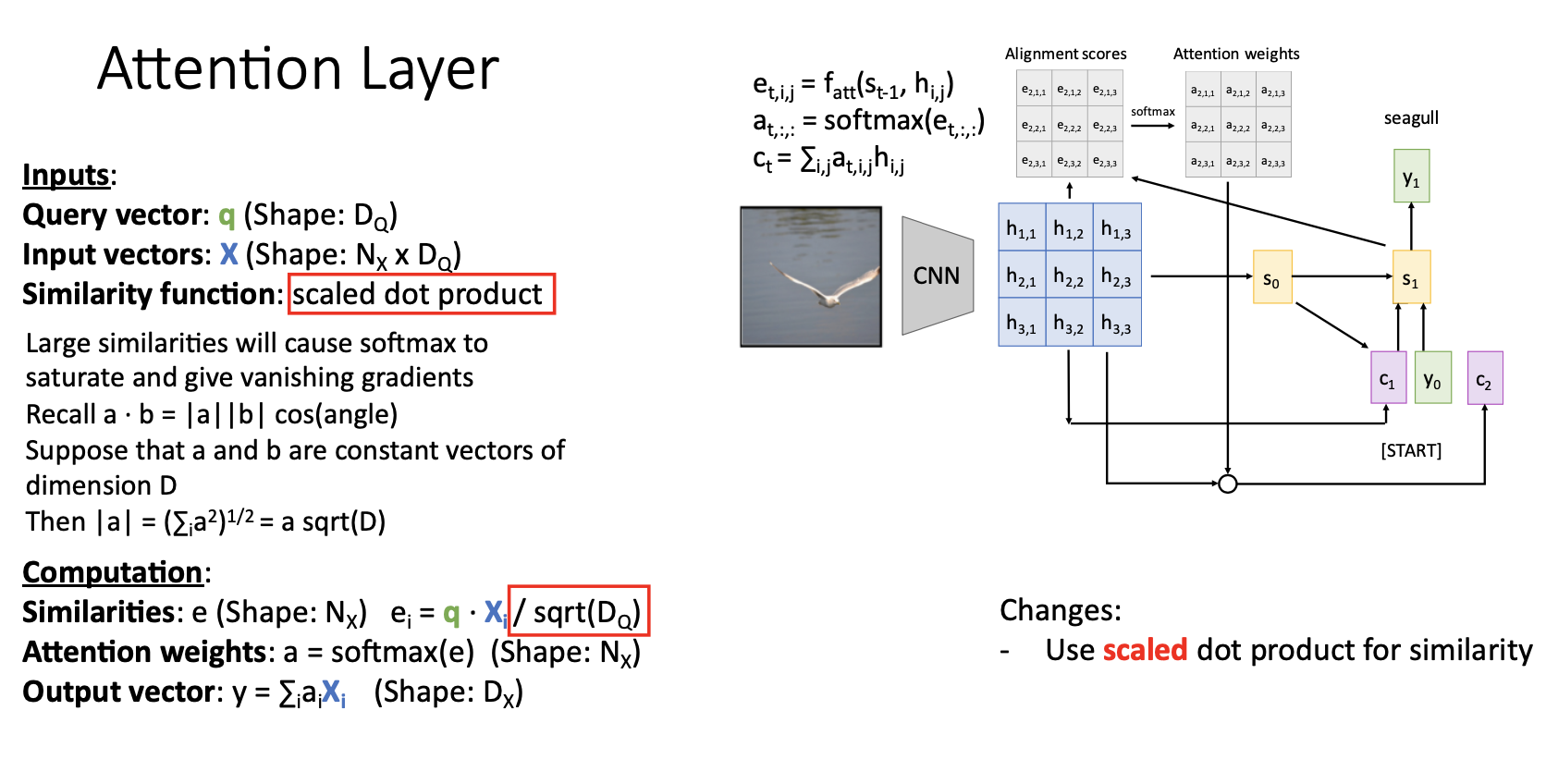
첫 번째 generalization으로 Similarity function을 scaled dot product연산으로 변경해서 matrix multiplication형태로 연산하여 훨씬 효율적으로 연산한다.
-
기존의
- similarity를 계산하기 위해서 신경망 사용
- similarity 를 신경망의 출력으로 하나씩 계산함
-
변경된
- scaled dot product사용- matrix multiplication을 통해서 모든 similarities를 한번에 계산할 수 있어서 효율적
- scaled는 나누어주는 sqrt()를 의미함 (는 input vector 와 query vector q의 dimension임)
- scaled dot product를 사용하는 이유는 similarity scores인 를 softmax에 input으로 넣게되는데 가 클수록(두 벡터 차원이 클수록) gradient vanishing문제가 발생하기 때문
- 한 지점에서 값이 엄청 큰 경우에 softmax를 통과하게 되면 그 i지점에서만 높게 치솟은 형태가 되니까 그 부분을 제외한 다른 지점에서의 gradient가 0에 가깝게 된다.
- 그래서 의 제곱근을 나누어주는걸로 scaling해서 이런 현상을 방지함
-
두번 째 일반화 과정으로는 여러개의 query vector를 허용하는 것
-
기존에 single query vector q를 input으로 받던 것을 set of query vector Q로 받아 모든 similarity socores를 single matrix multiplication operation으로 모든 연산에서 한번에 계산 (similarity function이 내적으로 변경되었기 때문에)
-
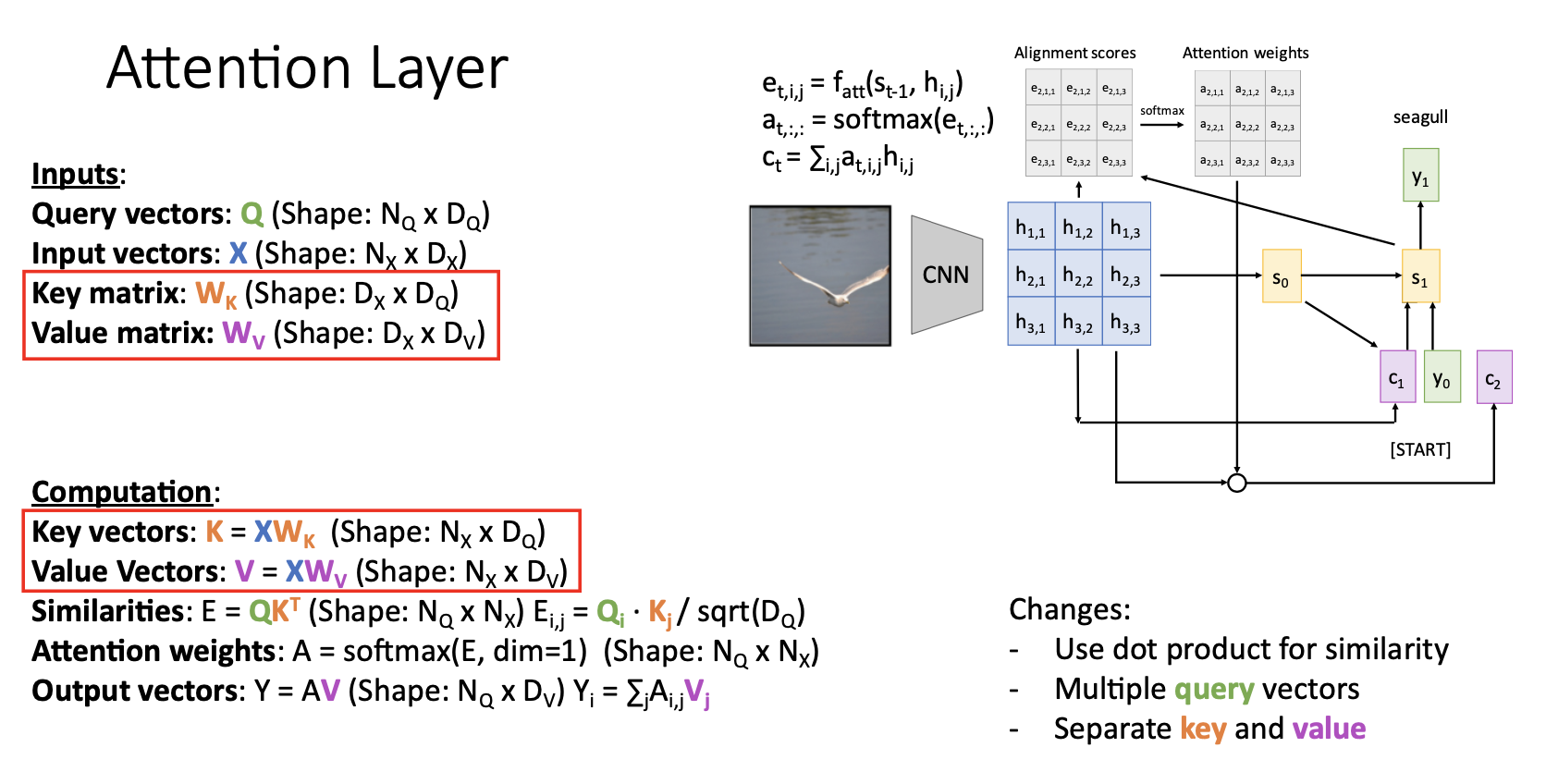
세번 째 일반화 과정은 similarity와 output을 계산할때 동일하게 사용되던 input vector X를 각각 Key vector K와 Value vector W로 분리하는 것이다.
-
예를 들어 구글에 엠파이어 스테이트 빌딩의 높이라고 검색을 한다고 하면 검색한 문장인 엠파이어 스테이트 빌딩의 높이가 query가 되고, 원하는 정보를 얻을 수 있는 웹페이지가 ouput이 됨
-
우리가 원하는 건 빌딩의 높이를 알려주는 웹페이지이고, 이는 검색한 문장(query)과는 무관한 데이터라고 생각할 수 있음
-
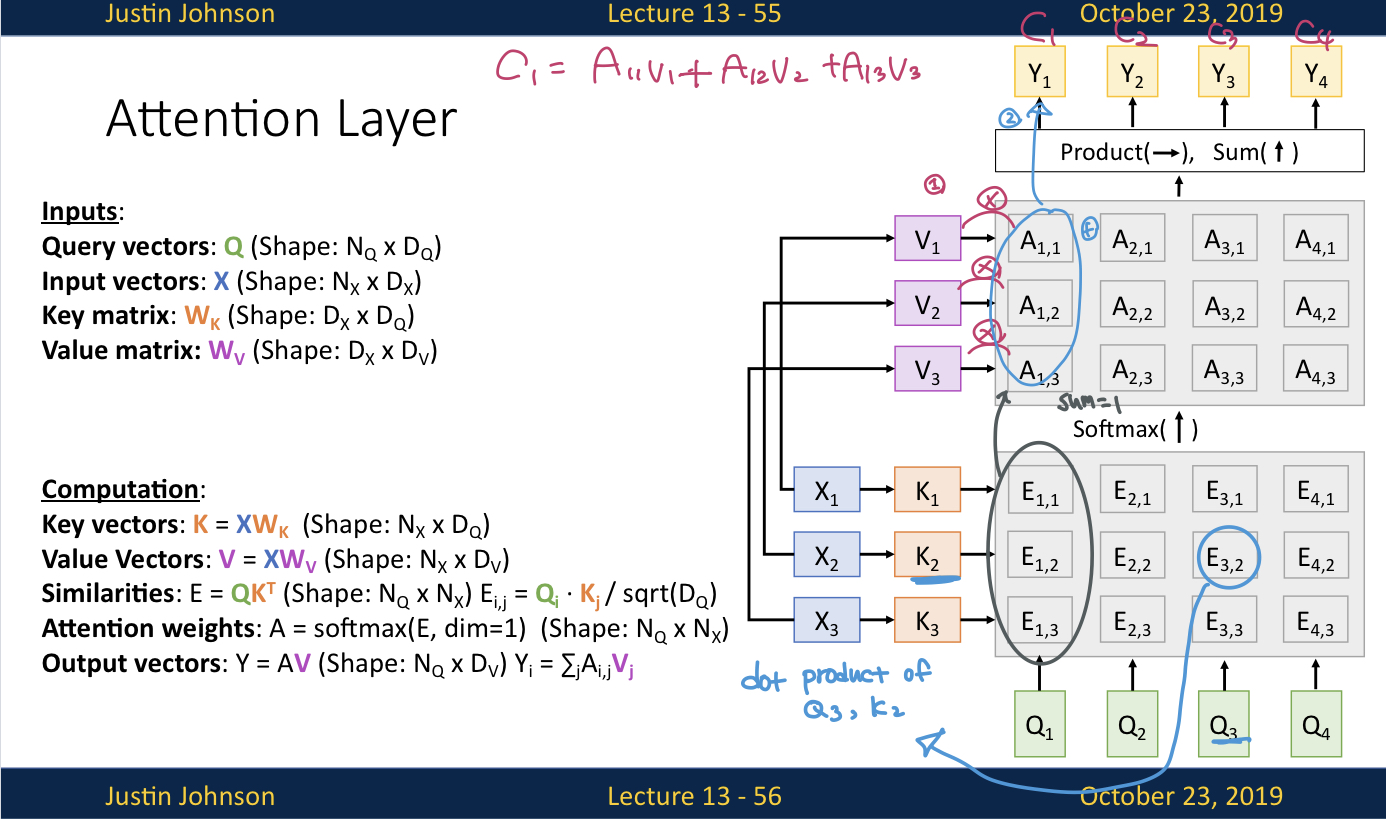
지금까지 살펴본 변경사항들을 적용한 Attention layer는 위 그림과 같이 동작한다.
-
, , 에 해당하는게 , , 였음
-
query vector는 output문장의 hidden state 였음(, , , )
-
input vectors , , 를 통해서 key vectors , , 를 생성함
-
query vectors , , , 와 key vectors, , 를 통해서 similarity matrix E를 생성함
-
: dot product of ,
-
similarity matrix E를 softmax에 통과시켜서 attention weight matrix A를 생성함
- softmax에 수직방향으로 위로 통과시킨다고 생각 -
input vectors , , 를 통해서 value vectors , , 를 생성함
-
attention weights ...., 와 value vectors , , 를 통해서 output vectors , , , 를 구하고 출력
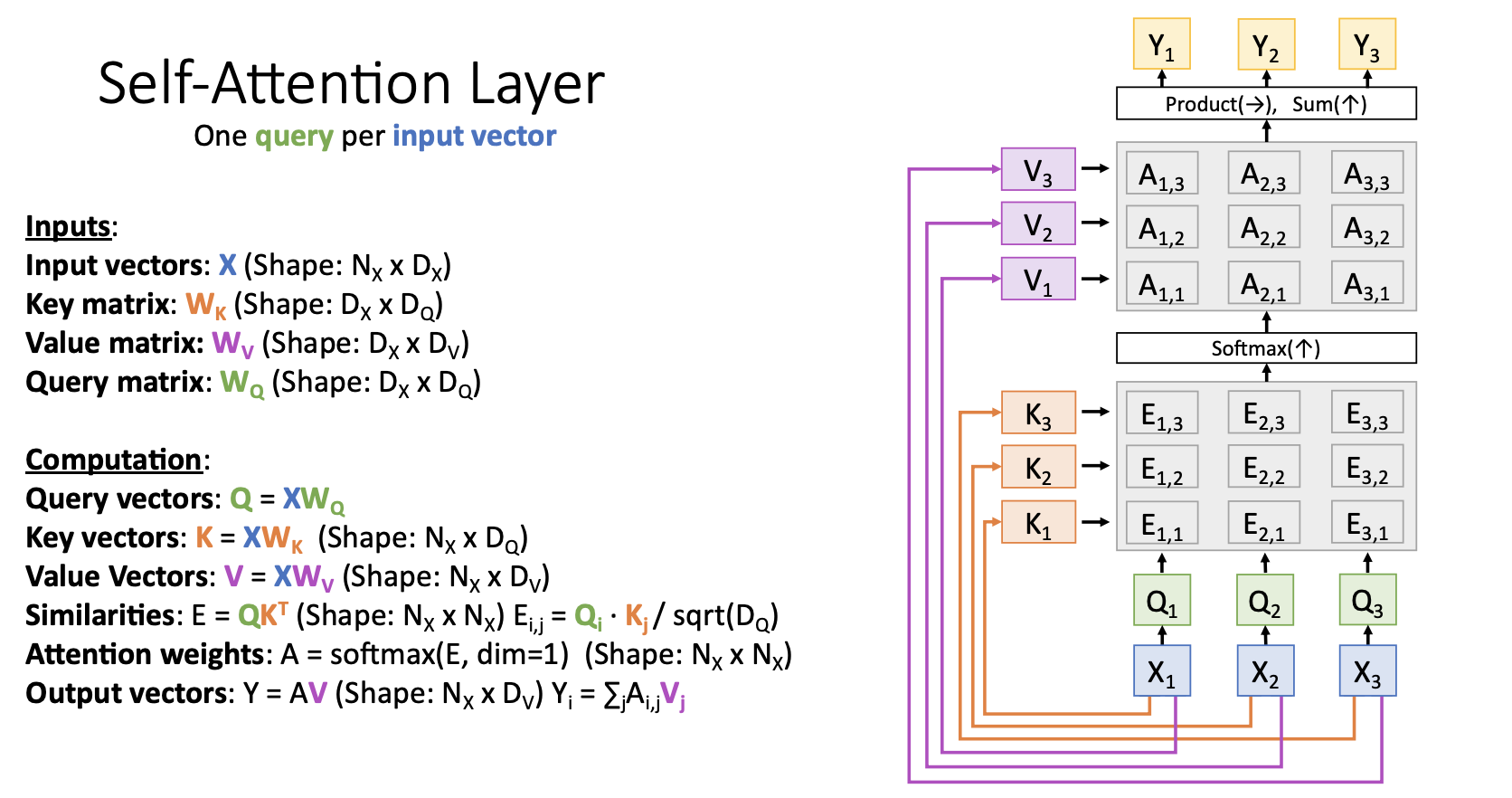
Self-Attention Layer
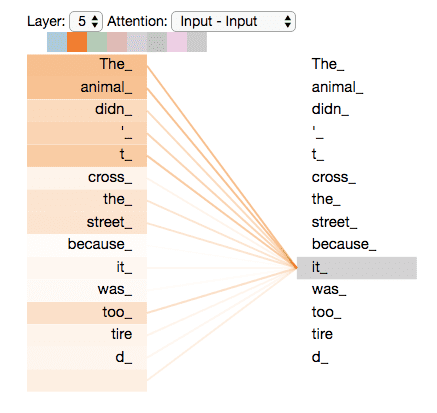
Attention Layer의 특별 case인 Self-Attention Layer는 input vector set을 입력받아서 각 input vector들끼리 비교하는 형태이다.
(입력한 문장 내의 각 단어를 처리해 나가면서 , 문장 내의 다른 위치에 있는 단어들을 보고 힌트를 받아 현재 타겟 위치의 단어를 더 잘 인코딩할 수 있게 하는 과정)
-
이전과 다르게 self-attention layer에는 query matrix와 query vectors가 새로 생김
-
self-attention layer는 query vector없이 input vector만 입력으로 받기 때문에 새롭게 추가된 query matrix (학습되는 learnable weight matrix)를 통해서 input vector로 부터 predict하는 것으로 query vector를 생성해서 비교하면서 동작함
-
query matrix 를 통해서 input vectors , , 로 부터 query vectors , , 를 생성
-
input vectors , , 를 통해서 key vectors , , 를 생성
-
query vectors , , 와 key vectors , , 를 통해서 similarity matrix E 생성
-
similarity matrix E를 softmax에 통과시켜서 attention weight matrix A를 생성
-
input vectors , , 를 통해서 value vectors , , 를 생성
-
attention weights ...., 와 value vectors , , 를 통해서 output vectors , , , 를 구하고 출력
-
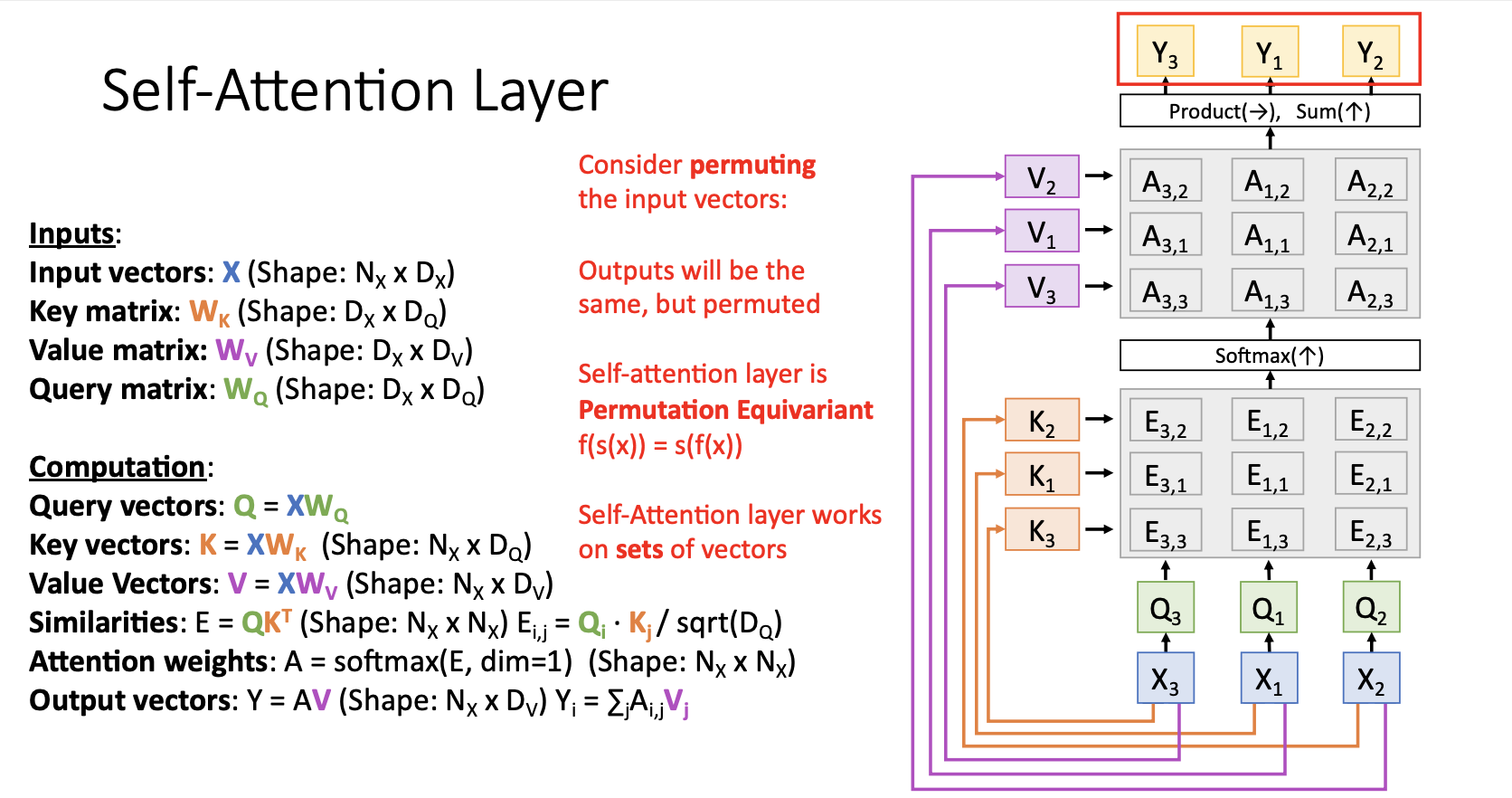
self-attention layer에서 입력의 순서를 바꿔보면(permutation) 어떻게 될까?
-
, , 로 순서를 바꿔서 input을 주면 모든 결과는 동일하고 output이 순서만 바껴서 나오게 됨
-
따라서, Self-Attention Layer는 Permutation Equivariant라고 할 수 있음
-
또한, Self-Attention Layer는 Input의 순서를 신경쓰지 않는 Layer라고도 표현할 수 있음
-
단지 Input vector set을 받아서 각 input vecter들끼리 서로 비교한 후, 새로운 vector set을 출력하기만 함
-
하지만 machine translation, image captioning task와 같이 몇몇 경우엔 intput vector의 순서를 알아야 함
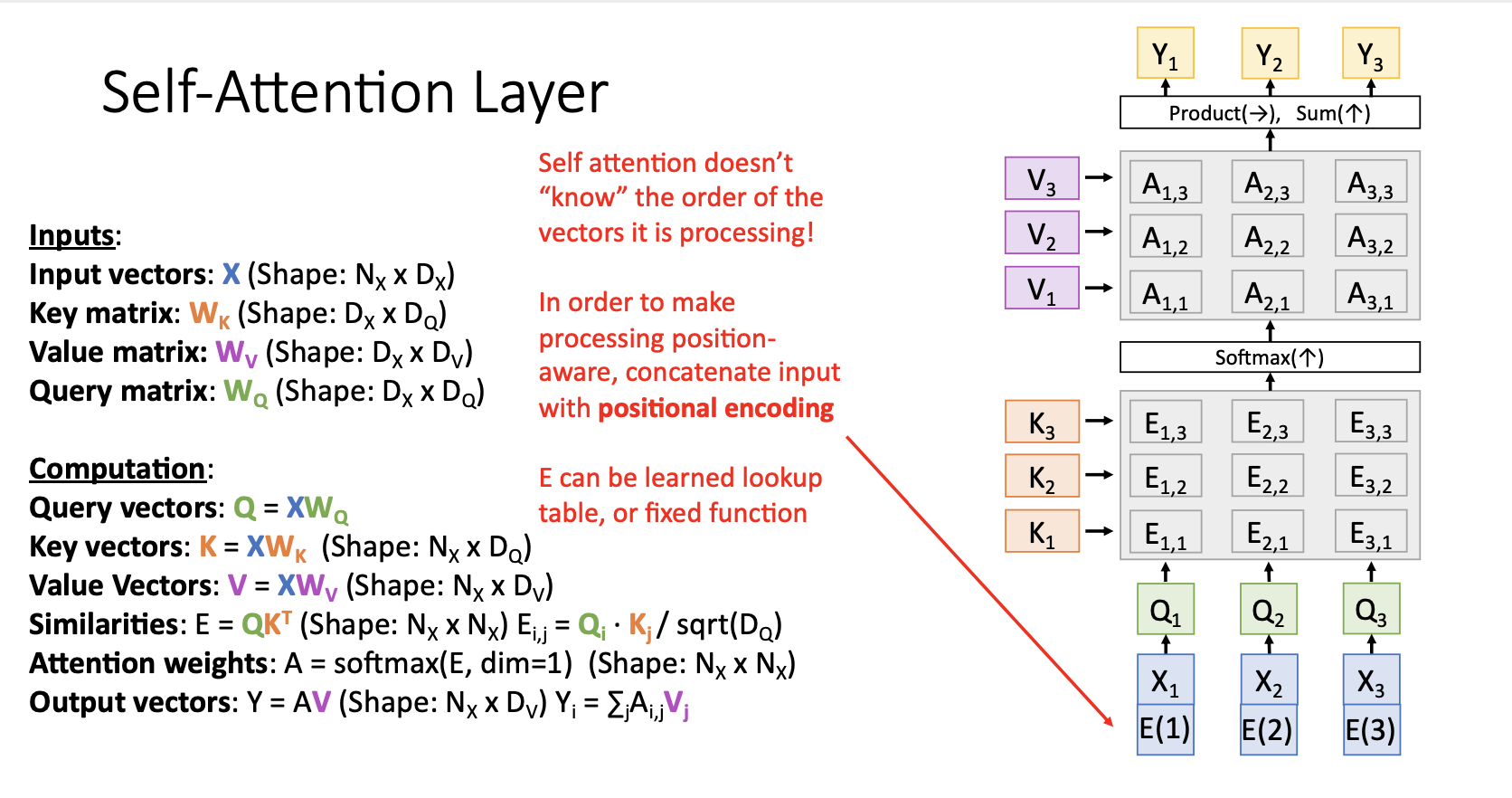
- 기본적으로 Self-Attention Layer는 순서를 알지 못하지만, 순서를 알게 하기 위한 방법으로 positional encoding을 추가해주는 방법도 있음
positional encoding이 왜 필요한가 하면, 어순은 언어를 이해하는 데 중요한 역할을 하기에 이 정보에 대한 처리가 필요하다. 따라서 attention layer에 들어가기 전에 입력값으로 주어질 단어 vector 안에 positional encoding 정보, 즉, 단어의 위치 정보를 포함시키고자 하는 것
출처: https://skyjwoo.tistory.com/entry/positional-encoding이란-무엇인가 [jeongstudy]
