✅ keras코드를 공부하기 앞서서 관련 개념들을 공부하기 위해 정리해놓은 내용입니다!
segmentation 참고 출처 1
segmentation 참고 출처 2
U-Net 논문
U-Net 참고출처 1
U-Net 참고출처 2
Xception 참고출처 1
Xception 참고출처 2
* 위의 자료들을 바탕으로 작성된 것임을 알려드립니다.
Segmentaion이란?
segmentation의 정확한 의미와 목적은 아래와 같습니다.
- segmentation(분할): 모든 픽셀의 레이블을 예측
* FCN, SegNet, DeepLab 등의 모델
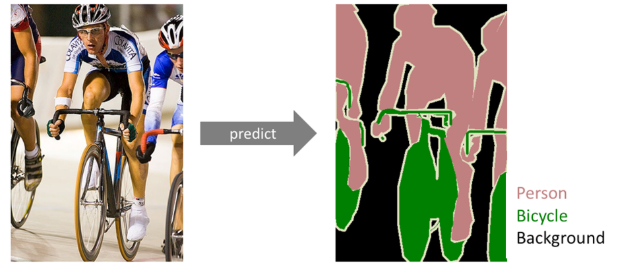
semantic segmentation은 이미지 내의 물체들을 의미있는 단위로 분할해내는 것이고, 구체적으로 얘기한다면 이미지에 있는 모든 픽셀을 해당하는(미리 지정된 개수의) class로 분류하는 것 입니다. 이미지에 있는 모든 픽셀에 대한 예측을 하는 것이기 때문에 dense prediction이라고도 불립니다.
- semantic segmentation을 어떤 이미지에 시행하면 위 그림과 같이 각 픽셀이 어느 class에 속하는지 알게 됩니다.
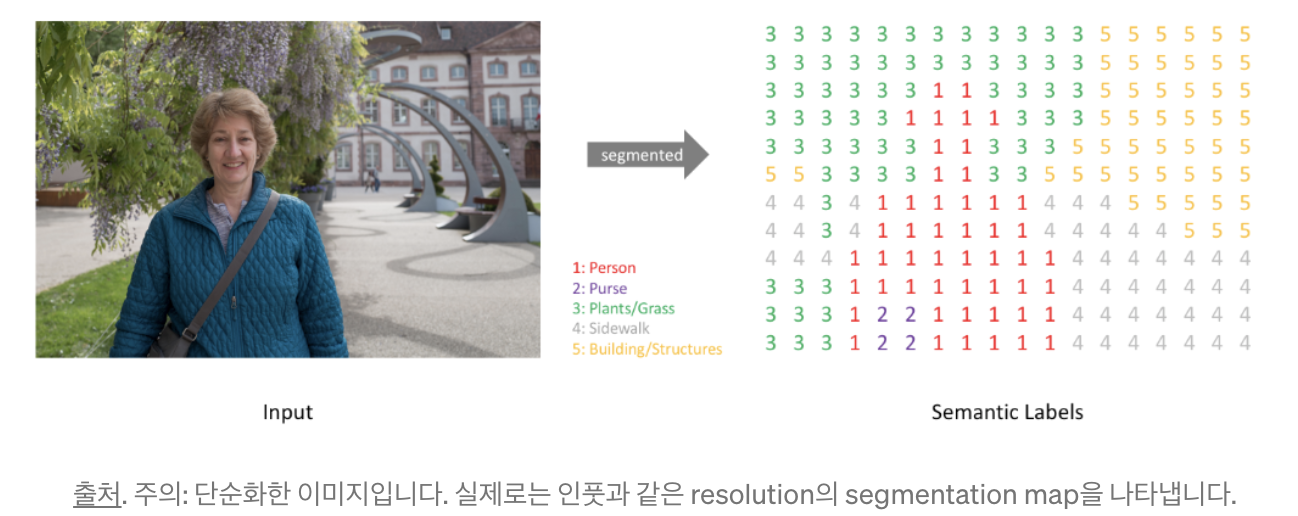
semantic segmentaion 알고리즘의 입력값은 컬러 이미지 또는 흑백 이미지이고, 출력값은 각 픽셀의 예측된 class를 나타내는 segmentation map입니다.
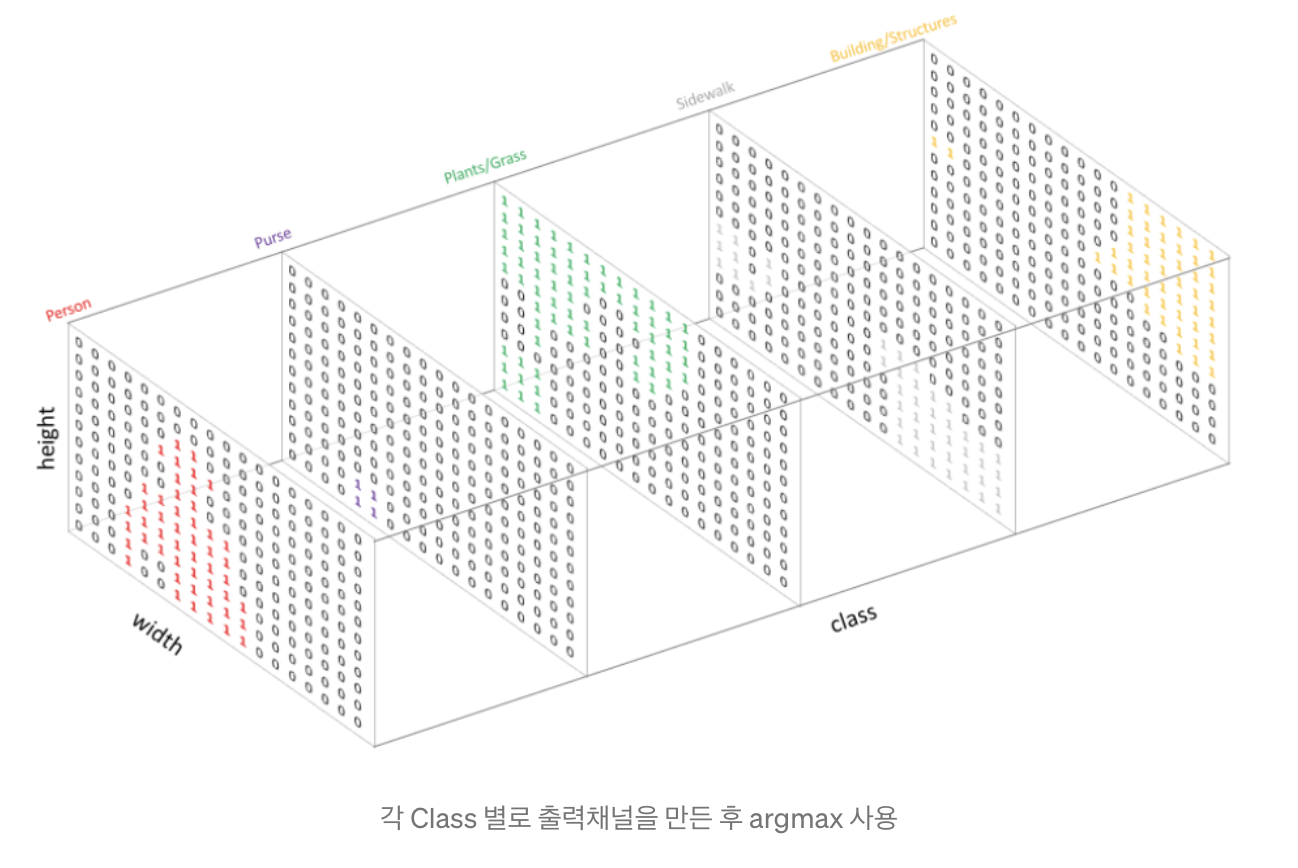
- One-Hot encoding 으로 각 class 에 대해 출력채널을 만들어서 segmentation map을 만듭니다. Class의 개수 만큼 만들어진 채널을argmax 를 통해서 위에 있는 이미지 처럼 하나의 출력물을 내놓습니다.
주의해야하는 점은 semantic image segmentation은 같은 class의 instance를 구별하지 않는다는 것인데, 이 말은 쉽게말해서 아래그림처럼
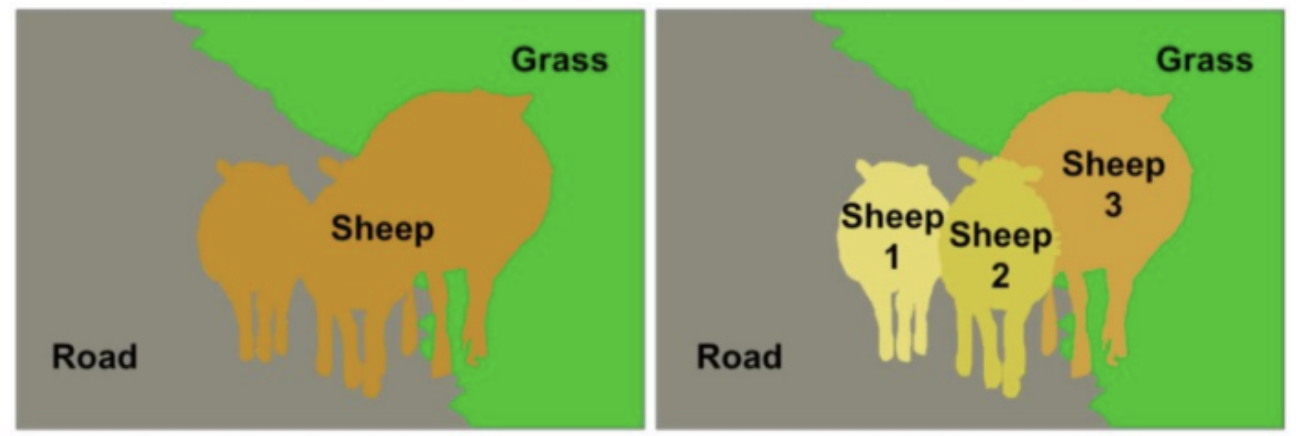
같은 class에 속하는 object(양 3마리)가 있을 때 따로 각각 분류하지 않고 그 픽셀 자체가 어떤 class에 속하는지만 관심이 있는 것입니다.(왼쪽사진에 해당)
오른쪽 사진처럼 instance를 구별하는 모델은 따로 instance segmentation이라고 불립니다.
U-Net
Biomedical 분야에서 이미지 분할(Image Segmentation)을 목적으로 제안된 End-to-End 방식의 Fully-Convolutional Network 기반 모델
- End-to-End Learning?
어떤 문제를 해결할 때 필요한 여러 스텝을 하나의 신경망을 통해 '재배치'하는 과정. 데이터 크기가 클 때 효율적.
즉 데이터가 클 때 두 단계로 나누어 각각 네트워크를 구축한 후 학습한 후 그 결과를 합치는 방법입니다. 이렇게 하는 이유는 스텝을 나누는 것이 성능이 더 좋기 때문입니다.
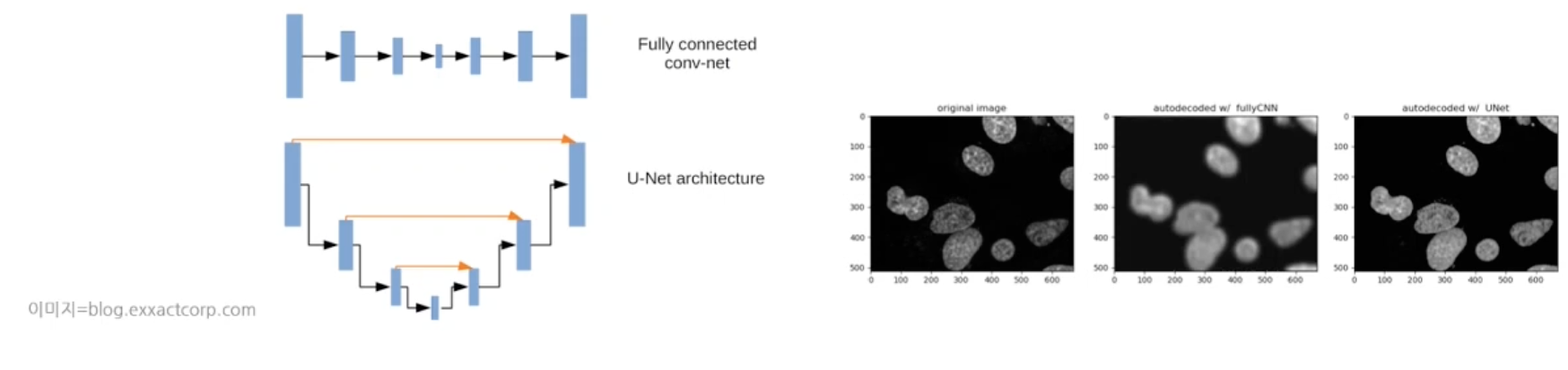
- 기존 FCN과 다른점은 U-Net에 skip connection이 있습니다. (skip connection은 입력 데이터 수준의 해상도를 복원하는 역할을 함)
- 오른쪽 이미지를 보면 FCN은 입력 이미지가 뿌옇게 나오는것에 비해 U-Net은 입력이미지 수준의 해상도로 나오는 것을 알 수 있습니다.
1) U-Net이 개선한 점
1-1) 속도를 높였다.
1-2) context 인식과 localization 간의 trade-off를 해결했다.
context는 서로 이웃한 이미지 픽셀 간의 관계를 의미합니다.
이미지의 일부를 보고 전반적인 이미지의 context를 파악하는 맥락으로 보면 됩니다.
trade-off라 함은 넓은 범위의 이미지를 한꺼번에 인식하면 전반적인 context를 파악하기에 용이하지만 localization를 제대로 수행하지 못해 어떤 픽셀이 어떤 레이블인지 세밀하게 인식하지 못합니다.
반대로 범위를 좁히면 세밀한 localization이 가능하지만 context 인식률은 떨어집니다.
2) U-Net 구조
(U-Net 구조 - U모양으로 생겨서 U-Net)
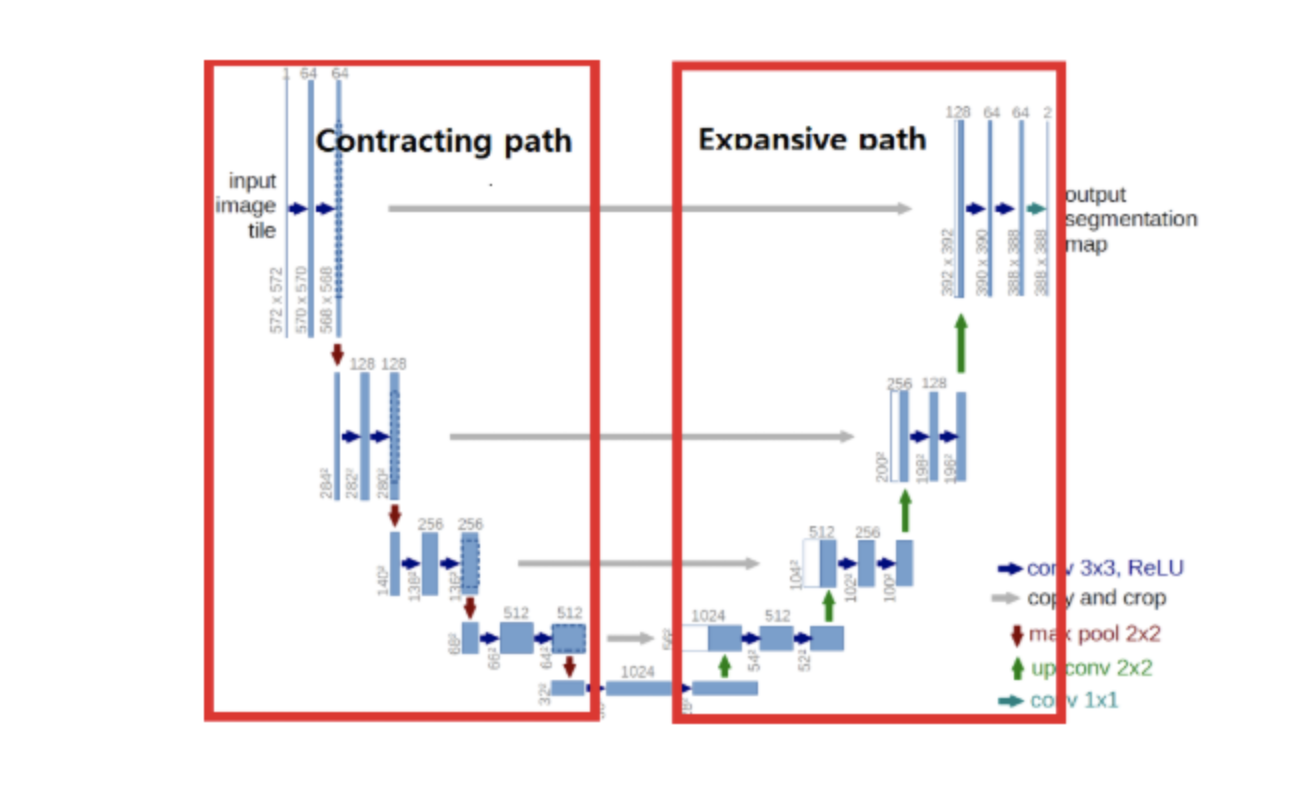
논문에서 위의 Architecture를 network중심을 기준으로 왼쪽은 Contracting Path(Encoding으로 생각하면 됨), 오른쪽은 Expanding Path(Decoding으로 생각하면 됨)로 정의하였습니다.
- Contracting Path : 입력 이미지의 Context 포착을 목적으로 구성
- Expanding Path : 세밀한 Localization을 위한 구성, Expanding Path의 경우 Contracting Path의 최종 특징 맵으로부터 보다 높은 해상도의 Segmentation 결과를 얻기 위해 몇 차례의 Up-sampling을 진행합니다.
<U-Net의 메인 아이디어>
Contracting path 는 이미지의 context를 포착할 수 있도록 돕고,
Expanding path 는 피쳐맵을 Up-sampling하고 이를 Contracting path에서 포착한 피쳐맵의 context와 결합하여 더 정확한 Localization을 합니다.
3) 구조 자세하게 보기
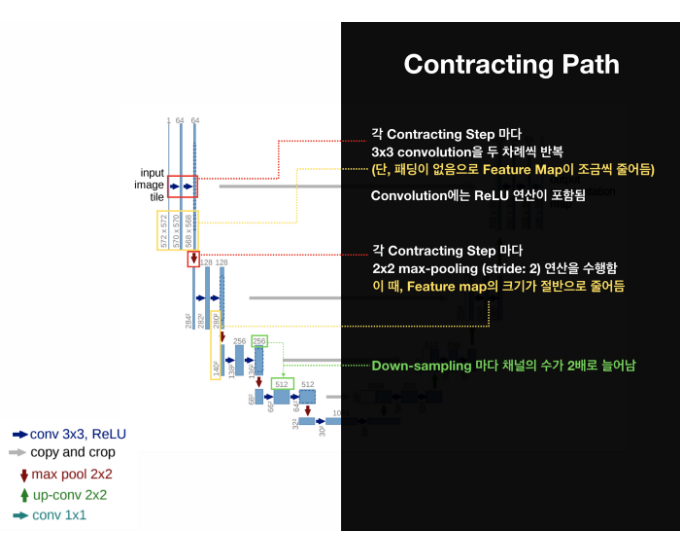
The Contracting Path
- 3x3 convolutions을 두 차례씩 반복 (패딩 없음)
- 활성화 함수는 ReLU
- 2x2 max-pooling (stride: 2)
- Down-sampling 마다 채널의 수를 2배로 늘림
Expanding Path는 Contracting Path와 반대의 연산으로 특징맵을 확장한다.
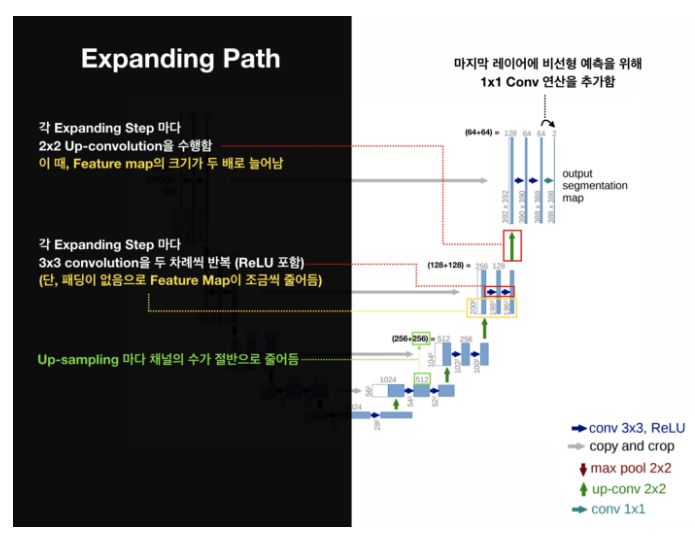
The Expanding Path
- 2x2 convolution (“up-convolution”)
- 3x3 convolutions을 두 차례씩 반복 (패딩 없음)
- Up-Conv를 통한 Up-sampling 마다 채널의 수를 반으로 줄임
- 활성화 함수는 ReLU
- 마지막 레이어에 1x1 convolution 연산
expanding path에서는 컨볼루셔널 블락에 up-conv 라고 불리는 것을 앞에 붙였습니다. 즉, contracting 과정에서 줄어든 사이즈를 다시 키워가면서 conv block을 이용하는 형태입니다. 그리고 아래쪽의 단계에서 얻어진 feature 들과 연결하여 사용합니다. (요즘 유행하는 residual 형태는 아님. 이후의 FusionNet 에서는 그렇게 한다고 함.)
즉, 멀티 스케일의 오브젝트 세그멘테이션을 위해서 다양한 크기의 피쳐맵을 concat 할 수 있도록 다운샘플링과 업샘플링을 순서대로 반복하는 구조로 되어 있습니다.
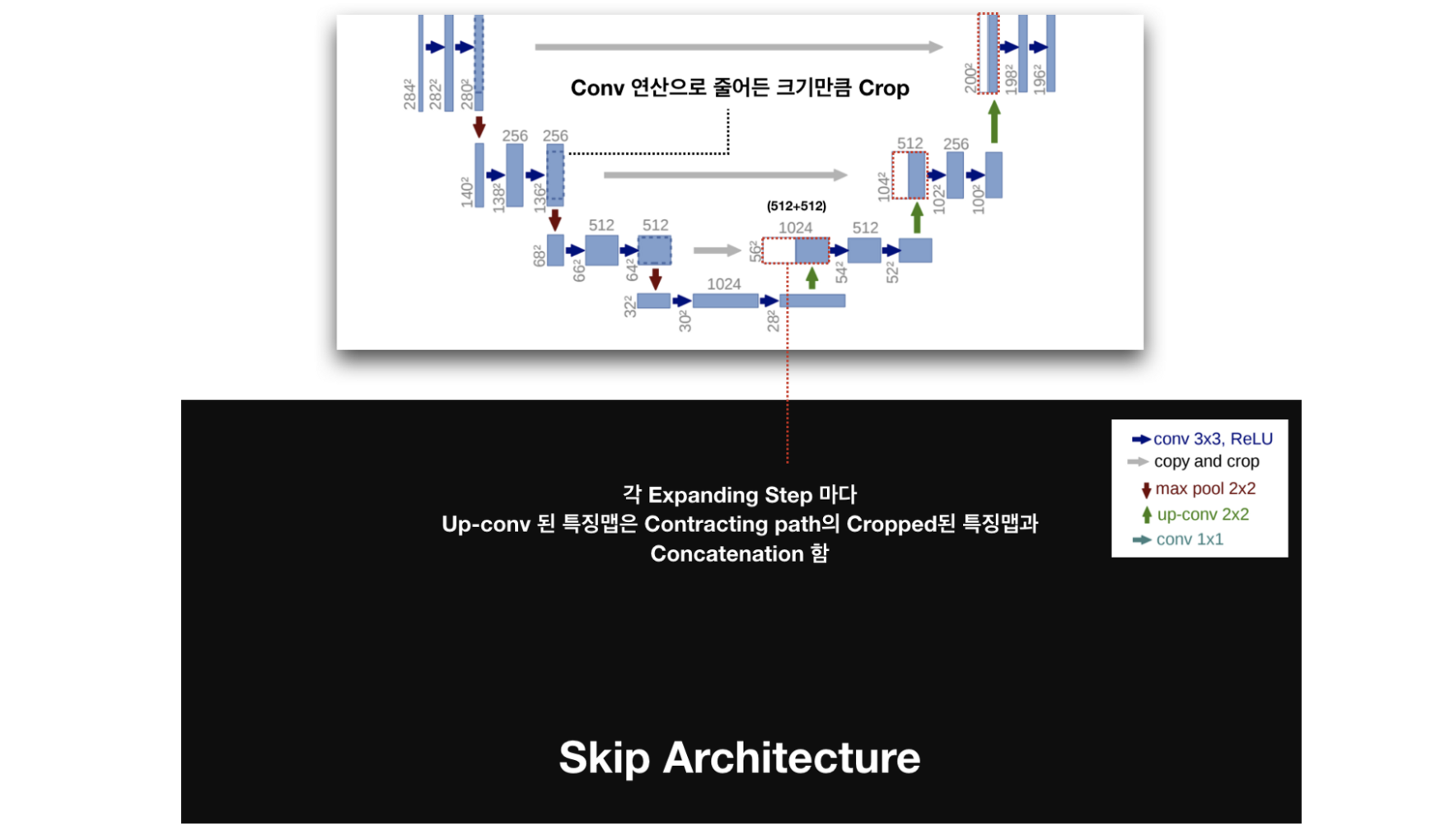
왼편의 feature를 오른 편으로 copy해서 보낼 때, 중앙 부분을 알맞은 사이즈로 crop해서 보낸다. 이는 convolution을 하면서 가장자리 픽셀에 대한 정보가 손실되는 것에 대한 양쪽의 보정이라고 합니다.
Inception
Inception은 2014년 IRSVRC에서 1등한 모델로, 이때 우승한 v1모델 이후로 여러 버전이 발표되었다.
IRSVRC대회에 참가할 당시 팀 이름이 GoogLeNet이여서 GoogLeNet이라고 부르기도 한다.
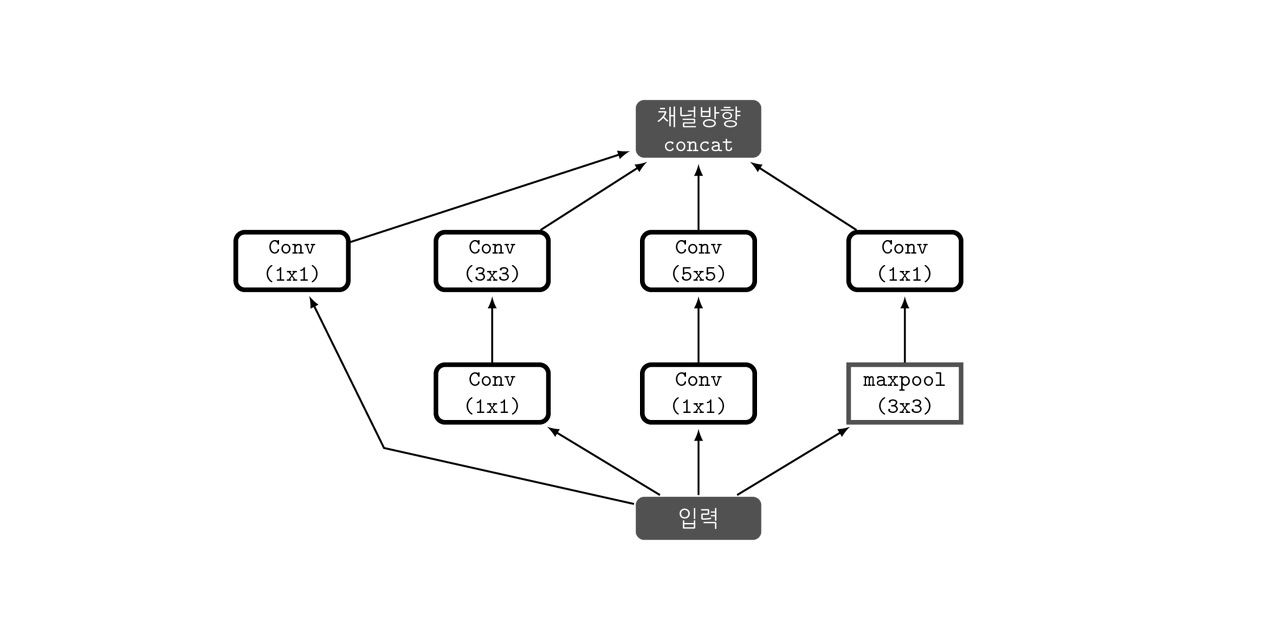
- 높은 관련성을 가진 노드들끼리만 연결하여 노드 간의 연결을 줄이면서(Sparse connectivity), 행렬 연산은 Dense 연산을 하도록 처리하는 것에서 나온 결과가 Inception module입니다.
1x1 conv 연산이 Inception module에서의 핵심역할로 기능은 다음과 같습니다.
1) 채널 수를 조절한다
채널간의 Correlation을 연산한다는 의미이다. 1x1 convolution을 사용함으로써, 최적화 과정에서 채널 간의 특징을 추출할 수 있다. 따라서 이후의 3x3 convolution 과정에서는 이미지의 지역정보에만 집중하여 특징을 추출할 수 있다. 즉 역할을 세분화 해준 것이다. 다시 정리해서 채널간의 관계정보는 1x1 conv에 사용되는 파라미터들끼리, 이미지의 지역정보는 3x3 conv에 사용되는 파라미터들끼리 연결된다는 점에서 노드간의 연결을 줄였다고 볼 수 있다.
2) 파라미터 개수를 절약할 수 있다
Xception
Xception은 inception module을 이용하여 노드들 간의 연결을 줄였던 inception 모델에서 더 나아가,채널 간의 관계를 찾는 것과 이미지의 지역 정보를 찾는 것을 완전히 분리하고자 했습니다.
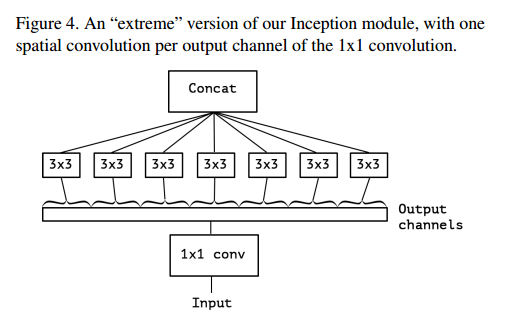
- 위 module은 채널간의 상관관계를 1X1 cov을 통해 포착하고, 각각의 output channel에 모두 별개로 3x3 conv 연산을 한다. 참고로 Xception은 extreme version of inception module의 줄임말로, Depthwise separable convoution 을 수정하여 만든 모델이다.
Depthwise separable convolution
각 채널별로 conv연산을 시행하고 그 결과에 1x1 conv 연산을 취하는 것
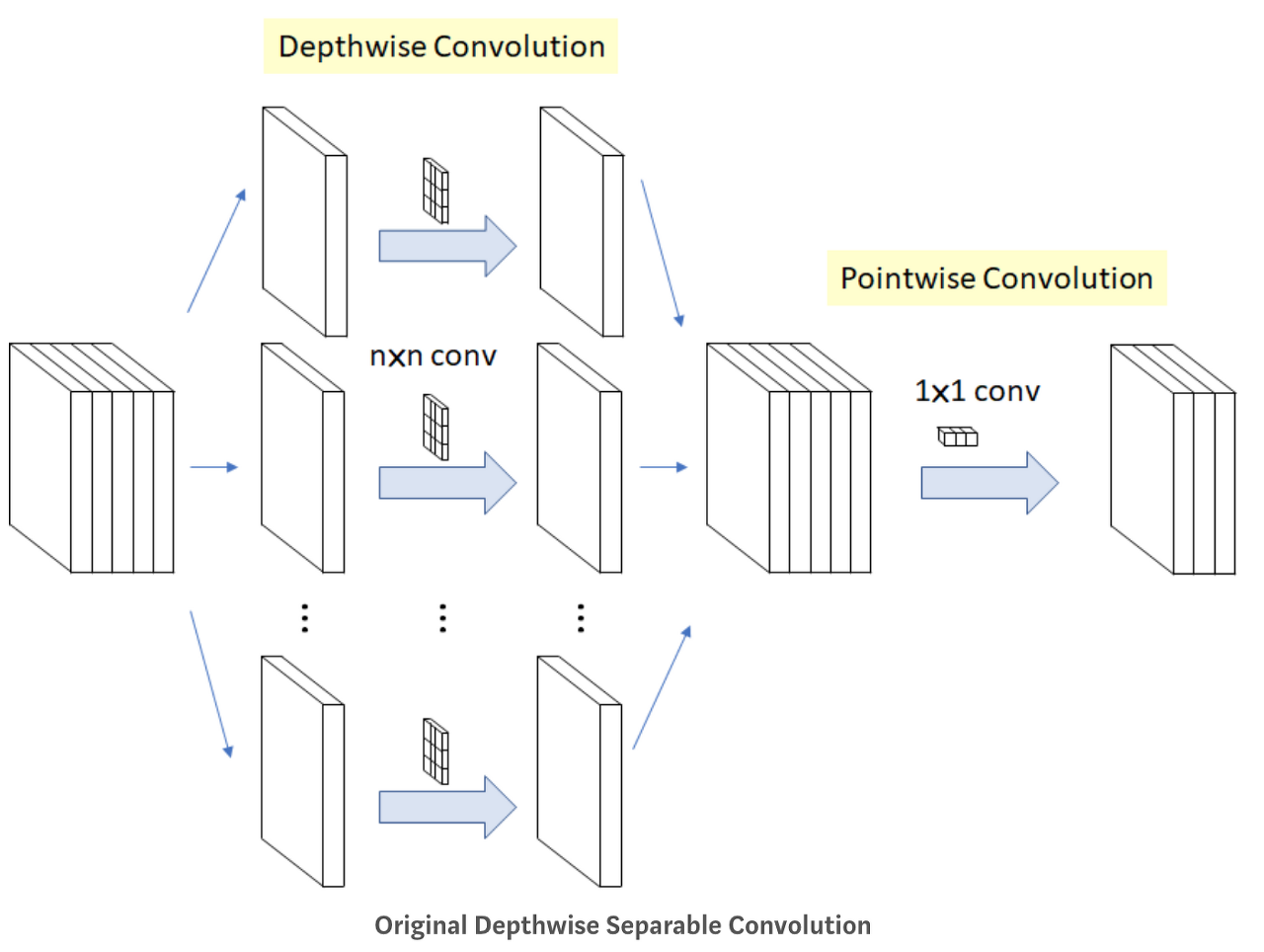
- 기존의 컨볼루션이 모든 채널과 지역정보를 고려해 하나의 Feature Map을 만들었다면, depthwise convolution은 각 채널 별로 Feature Map을 하나씩 만들고, 그 다음 1x1 conv 연산을 수행하여 출력되는 피쳐맵 수를 조정합니다. 이때 1x1 cov는 Pointwise separable convolution이라고 합니다.
1단계: Channel-wise nxnx spatial convolution
K개의 채널에 대해 nxn convolution을 따로 진행해서 합친다.
2단계 Pointwise Convolution
채널의 개수를 줄이기 위한 방법으로 사용
Xception과 Depthwise separable convolution의 차이점
1. 연산의 순서
Xception: pointwise -> depthwise
Depthwise~: depthwise -> pointwise2. 비선형 활성화함수(ReLu)의 유무
Xception: 첫 연산 후에 ReLu가 있다.
Depthwise~: 중간에 ReLu를 적용하지 않는다.