석사 과정을 진행할 때 한국어 띄어쓰기 교정 시스템을 관련해서 연구를 진행했었는데, 이걸 다시 python 패키지로 만드록 싶다는 욕심이 생겨서 진행 중인 개인 프로젝트이다. 이번 포스팅에서는 그 당시에 개발했었던 방식을 간단하게 정리하고자 한다.
📽 video
👆🏻 이미지를 클릭하면 영상을 볼 수 있어요!(시연 영상은 2년 전에 C++로 개발했을 당시의 영상입니다.)
📃 논문
게재 정보
정보과학회 컴퓨팅의 실제 논문지(KTCP) 제 27권 제 3호, 2021.03
한국정보과학회 2020 한국컴퓨터종합학술대회 논문집, 2020.07 (KCC2020 언어공학부문 우수발표논문 수상)
그 당시 작성했던 논문의 제목은 '사용자의 입력 의도를 반영한 음절 N-gram 기반 한국어 띄어쓰기 및 붙여쓰기 시스템'이다. 그 때의 논문을 참고로 알고리즘을 간단하게 리뷰를 해보았다. (더 자세한 이론과 실험 내용은 아래 제 논문에서 확인할 수 있습니다🥳)
1. 서론
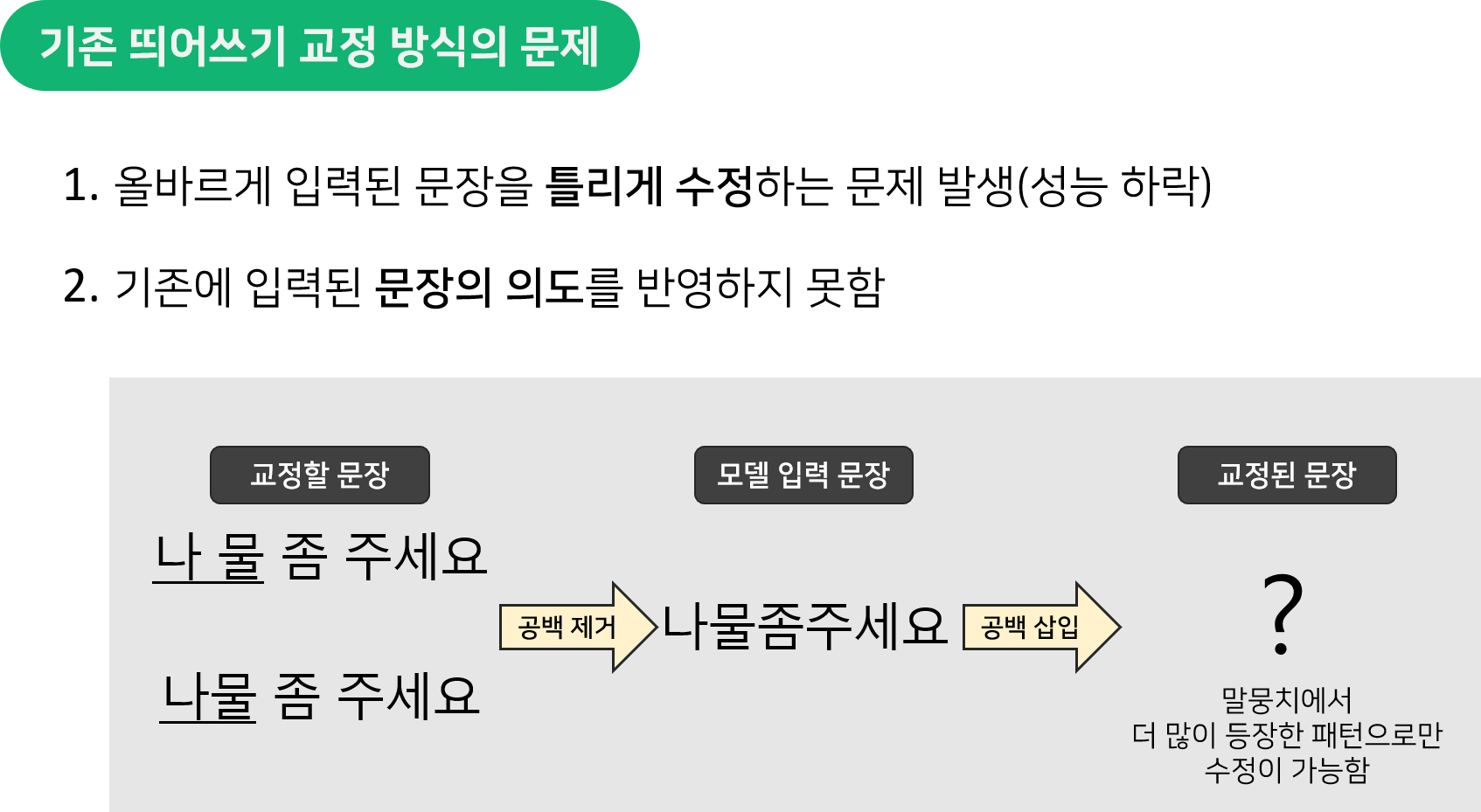

- 기존 띄어쓰기 모델들과 다르게 입력 문장의 띄어쓰기(공백)을 삭제하지 않고, 그대로 틀린 부분만 수정하는 것이 주요한 포인트였다.
- 이 방식을 이용함으로써 똑같은 음절 배열(첫 번째 사진의 예시)이더라도 입력한 문장에 따라서 교정된 결과가 달라져서 의도를 반영할 수 있었다.
2. 사용자의 입력 의도를 반영한 띄어쓰기 오류 교정
2-1. 음절 N-gram 통계
일반 한국어 문장으로 구성된 말뭉치로부터 음절 N-gram 통계 데이터를 추출했다. 추출한 N-gram은 1음절/2음절/3음절 단위(unigram, bigram, trigram)로 한정하여 사용했다.
-
통계 데이터를 수집하는 예시
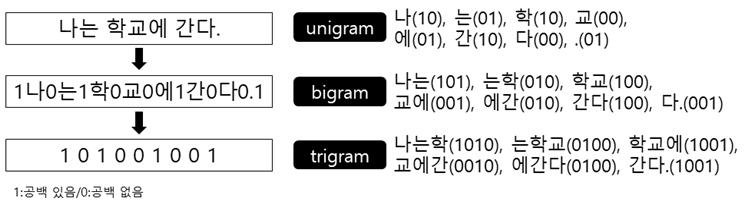
-
각 N-gram에 대해서 나올 수 있는 띄어쓰기 유형은 개이다.
- unigram(1음절) : 4가지
- bigram(2음절) : 8가지
- trigram(3음절) : 16가지
2-2. 공백 삽입 및 제거 확률 계산식
- 수집한 통계 데이터를 이용하여 공백이 삽입되거나 제거될 확률을 계산한다.
- P(임의의 음절 다음에 공백이 있음) = bigram_weight * bigram_prob + trigram_weight + trigram_prob
➡️ 이를 수식으로 표현하면 아래와 같고, 수식 내에서 ":"가 공백의 위치를 의미한다.
- 확률식에 있는 모든 가중치는 초기에 1로 설정하고 각 확률의 기여도에 따라 학습 과정에서 튜닝을 진행한다.
- 정답 레이블(공백이 있으면 1, 없으면 0), 확률 계산 결과 값
- 가중치를 조절하는 예시는 아래와 같다.

- 예시에서는 정답이 1(띄어쓰기가 있음)이기 때문에 1에 가까운 확률 결과를 얻을수록 띄어쓰기 판단 기여도가 높다고 생각하고, 더 높은 가중치를 가질 수 있도록 업데이트를 한다.
- 또한, 통계 기반 방법의 대표적인 문제인 데이터 부족 문제(OOV)를 해결하기 위해 간접적으로 확률을 계산하는 방법을 활용하였다. 참고한 논문은 '확장된 음절 bigram을 이용한 자동 띄어쓰기 시스템'이다.
- 조건부 확률을 이용하여 간접적인 확률 계산 방식
- 연속된 음절 XY가 학습 데이터에서 한 번도 등장한 적이 없지만, 각각의 음절 X와 Y는 등장한 적이 있을 때 활용이 가능한 방법.
- 음절 X와 Y의 등장 확률은 독립적이며, 중간에 띄어쓰기 유무는 X에 종속된다고 가정하여 나온 식
- 학습 데이터에 등장한 빈도(단순 횟수)
2-3. 띄어쓰기 및 붙여쓰기 임계치 결정
- 확률 계산식 와 임계치(threshold)에 의해 공백 삽입 or 제거 여부를 결정
- 이를 위해 띄어쓰기 임계치 2가지, 붙여쓰기 임계치 2가지로 총 4가지를 사용
- 실험에 사용한 세종 원시 말뭉치의 한 어절 평균 음절 수는 약 3.2
- 한 어절이 5음절 이상일 때, 두 개의 어절로 분리될 가능성 ⬆️ : 완화된 띄어쓰기 임계치 적용
- 연속된 두 어절의 음절 수 합이 3음절 이하일 때, 하나의 어절로 합쳐질 가능성 ⬆️ : 완화된 붙여쓰기 임계치 적용
2-4. 띄어쓰기 및 붙여쓰기 교정 알고리즘
-
사용자가 입력한 문장 정보를 사용하기 위해서 공백 문자를 제거하지 않고 교정을 진행
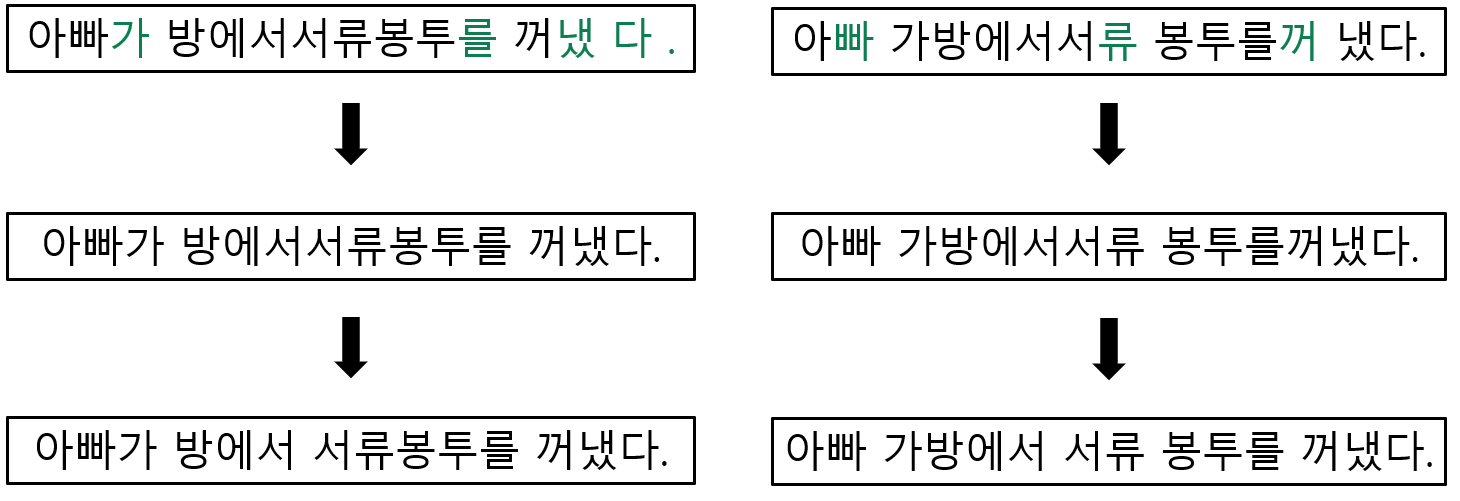
- 입력된 문장의 공백 신뢰도를 확인
- 사용자가 입력한 공백에 대한 확률 이 붙여쓰기 임계치보다 크다면 공백을 삭제
- 왼쪽 예문의 '냈 다 .'와 같은 패턴
- 1번 과정을 통해 생성된 새로운 문장의 띄어쓰기 오류를 교정
- 각 어절 내의 음절과 음절 사이의 확률 이 띄어쓰기 임계치보다 크다면 공백 삽입
- 오른쪽 예문의 '봉투를꺼냈다.'와 같은 패턴
- 입력된 문장의 공백 신뢰도를 확인
- 사용자의 입력 정보를 반영함으로 두 가지 의도를 모두 전달할 수 있음
- 입력에 따라 출력의 형태가 달라지지만 '봉투를 꺼냈다.'와 같은 확실한 띄어쓰기와 붙여쓰기는 지켜짐
💻 의사코드(pseudocode)
segmentation_correction(sentence):
//입력 문장의 띄어쓰기 태그 열을 얻음
label = labeling(sentence)
//trigram, bigram 확률 계산(2. 공백 삽입 및 제거 확률식)
tri_p = trigram_prob(sentence, label)
bi_p = bigram_prob(sentence, label)
//입력된 공백의 신뢰도 확인 후, 새로운 어절 열 생성
if space exist in sentence:
for eojeol in sentence:
threshold = pasting_threshold
//연속된 두 어절의 음절 수 합이 3음절 이하 -> 완화된 붙여쓰기 임계치 적용
if previous_eojeol_len + current_eojeol_len <= 3:
threshold = weak_pasting_threshold
index = index + eojeol_len - 1
//가중치 조정식을 통해 얻은 가중치
prob = 0.54 * tri_p[index] + 0.46 * bi_p[index]
//붙여쓰기 임계치보다 클 경우, 공백 삽입
if prob > threshold:
insert space after eojeol
index = 0
//새로 생성된 문장에 대해 trigram, bigram 확률 계산
tri_p = trigram_prob(new_sentence, label)
bi_p = bigram_prob(new_sentence, label)
for eojeol in new_sentence:
threshold = spacing_threshold
//한 어절이 5음절 이상 -> 완화된 띄어쓰기 임계치 적용
if eojeol_len >= 5:
thrreshold = weak_spacing_threshold
for i=index to index+eojeol_len-1:
prob = 0.54 * tri_p[index] + 0.46 * bi_p[index]
//띄어쓰기 임계치보다 클 경우, 공백 삽입
if prob > threshold:
insert space after ith syllable
return new_sentence3. 실험
-
세종 말뭉치를 사용하여 학습 및 평가를 진행(9:1). 입력 문장에 띄어쓰기 및 붙여쓰기 오류가 포함된 경우의 성능 측정을 위해 평가셋에 오류를 임의로 생성하여 실험
🔸 **원문** 따사로운 가을 햇볕이 우리를 반기고 있었다. 🔸 **생성된 문장** 따사 로운가 을햇볕이우리를 반 기고있었다. -
임의로 오류를 생성한 문장(INPUT)을 교정한 결과(OUTPUT)
)
3-1. 한국어 자동 띄어쓰기 성능 평가 결과
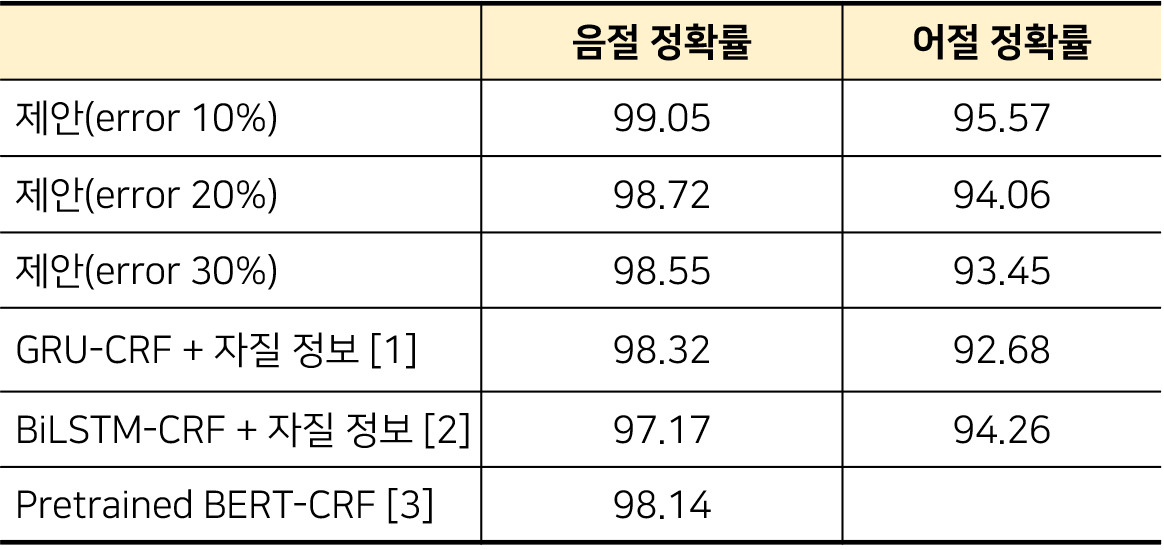
- 오류가 포함된 문장에 대해서도 딥러닝, 언어모델을 사용한 연구들보다 더 높은 정확률을 보임
- 오류가 30% 포함된 문장에 대해 [2]보다 1.3%p. 낮은 어절 F1 score를 보임
- 하지만 [2]의 경우, 복합 용언과 복합 명사를 고려하여 1,000개의 문장에 대해서만 성능을 측정한 결과임
- 동일한 방식으로 성능 평가를 할 경우, 더 높은 성능을 보일 것이라고 예상
- 기존 한국어 자동 띄어쓰기 연구들(참고 논문)
[1]딥러닝을 이용한 한국어 자동 띄어쓰기(GRU-CRF)
[2]종단 간 심층 신경망을 이용한 한국어 문장 자동 띄어쓰기(BiLSTM-CRF)
[3]BERT를 이용한 한국어 자동 띄어쓰기(Pretrained BERT-CRF)
3-2. 네이버 영화 리뷰 말뭉치에 대한 오류 교정 성능
네이버 영화 리뷰 말뭉치(NSMC : Naver Sentiment Movie Corpus)의 평가 셋 중 임의로 선정한 5,000문장에 대한 정답 셋을 생성하여 성능을 측정한 결과입니다. 정답 셋을 생성할 때, 맞춤법 오류는 교정하지 않은 띄어쓰기 오류만을 교정하였습니다.
- 비교 모델 : 공백을 모두 삭제 후 띄어쓰기 오류를 교정하는 확률 모델
- 제안 모델 : 사용자의 입력 정보를 활용하여 띄어쓰기 오류를 교정하는 확률 모델
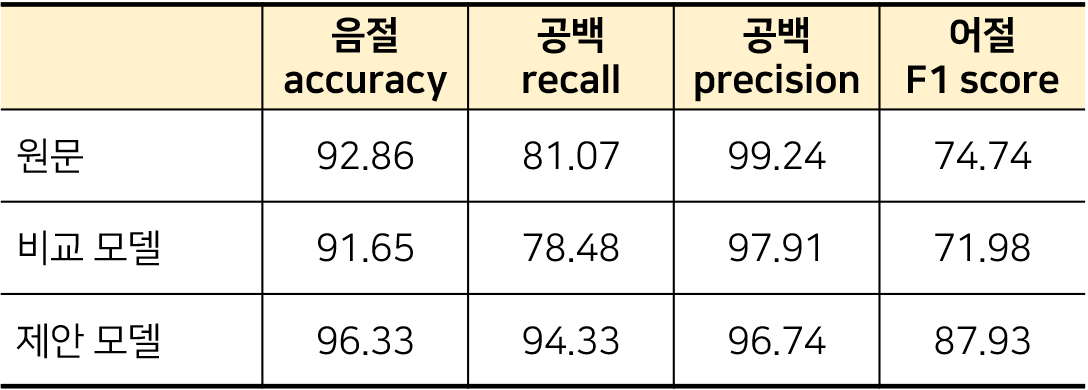
- 네이버 영화 리뷰의 원문은 생성한 정답 셋과의 비교 결과, 공백 재현율은 81.07%이지만, 공백 정밀도가 99.24%로 상당히 높은 결과를 보임 ➡️ 이를 통해서 아래와 같이 판단할 수 있었다!
1. 사용자는 실제로 띄어 써야 할 부분에서 띄어 쓰지 않는 경우는 많음
2. 띄어 쓰지 않아야 할 부분에서 띄어 쓰는 경우는 거의 없음
3. 실제 입력을 충분히 신뢰할 수 있으며, 반영하여 교정하는 것이 도움이 됨!
- 기존 모델은 실제 원문의 어절 f1 score보다도 떨어짐(약 15.95%p ⬇️)
- 제안 모델은 맞춤법 오류 전혀 없는세종 말뭉치만을 학습했음에도 성능 상승(약 13.19%p ⬆️)

안녕하세요! 성능 평가 기준에 대한 질문이 있어서 메일 보냈습니다!