[논문 리뷰] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
NLP 논문 리뷰
1. Introduction
-
현재 state-of-the-art representation learning 방식은 일종의 denoising autoencoder의 학습 방법
- 레이블링 되지 않은 입력 시퀀스의 토큰 중 일부(주로 15%)를 마스킹하여 이를 복원하는 방식인 masked language modeling(MLM) 태스크를 이용하여 트레이닝을 하기 때문에 이 일부 마스킹된 토큰이 노이즈의 일종이라고 할 수 있음.
-
MLM 태스크는 양방향 표현을 학습하기 때문에 전통적인 language-model pre-training보다 효과적이지만, 문제점이 존재함.
- 입력 시퀀스의 15%만을 학습하기 때문에 상당한 계산량이 필요함.
- Pre-training 단계에서는 [MASK] 토큰을 활용하여 학습을 하지만, 실제 Inference 단계에서는 [MASK] 토큰이 존재하지 않음.
-
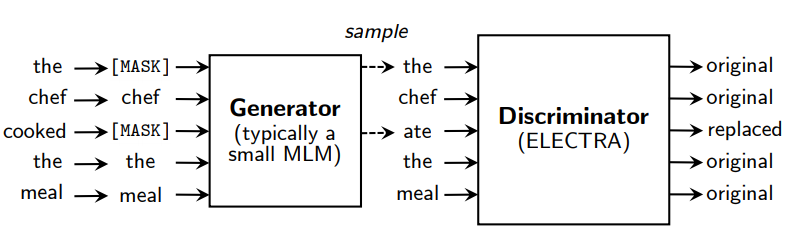
이 논문에서는 이러한 문제점을 보완하기 위하여 “replaced token detection”을 제안 (2에서 상세설명)
- generator가 실제 입력 중 일부 토큰을 그럴듯한 가짜 토큰으로 바꾸고, discriminator에서 각 토큰이 실제 입력에 있는 진짜 토큰인지 가짜 토큰인지 구분하는 방식 → 모델이 전체 입력 토큰에 대해서 학습을 하기 때문에 효율성 상승
- GAN과 유사해보이지만 텍스트에는 GAN을 적용하기 어렵기 때문에 maximum-likelihood를 활용하여 학습한다는 점에서 다름.
- generator가 실제 입력 중 일부 토큰을 그럴듯한 가짜 토큰으로 바꾸고, discriminator에서 각 토큰이 실제 입력에 있는 진짜 토큰인지 가짜 토큰인지 구분하는 방식 → 모델이 전체 입력 토큰에 대해서 학습을 하기 때문에 효율성 상승
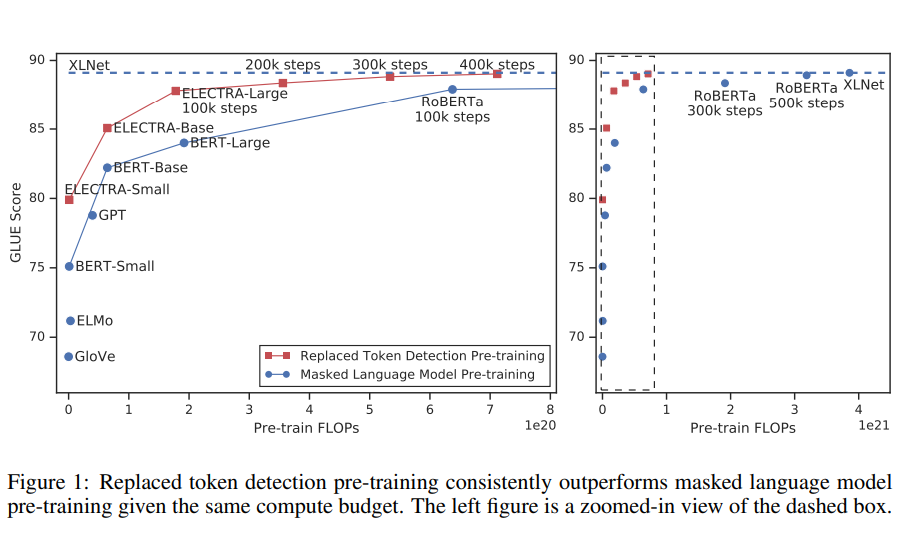
- replaced token detection으로 학습한 모델인 ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)는 동일한 조건(크기, 데이터, 계산량)의 MLM 모델에 비해 더 높은 성능을 보임
- ELECTRA-small은 1개의 GPU로 4일이면 트레이닝이 끝남. 이는 BERT-large 대비 1/20의 파라미터 수, 계산량은 1/135 정도의 수치인데도 BERT-small보다 GLUE성능이 5포인트 더 높고, 심지어 훨씬 큰 모델인 GPT보다도 성능이 높음
- ELECTRA-large는 RoBERTa와 XLNet 대비 1/4의 파라미터만을 사용했음에도 비슷한 성능을 보임.
- GLUE에서는 ALBERT의 성능을 뛰어넘었고, SQuAD 2.0에서는 state-of-the-art 달성
→ 기존 방식보다 더 효율적인 pre-training 방식임을 보여줌.
2. Method
-
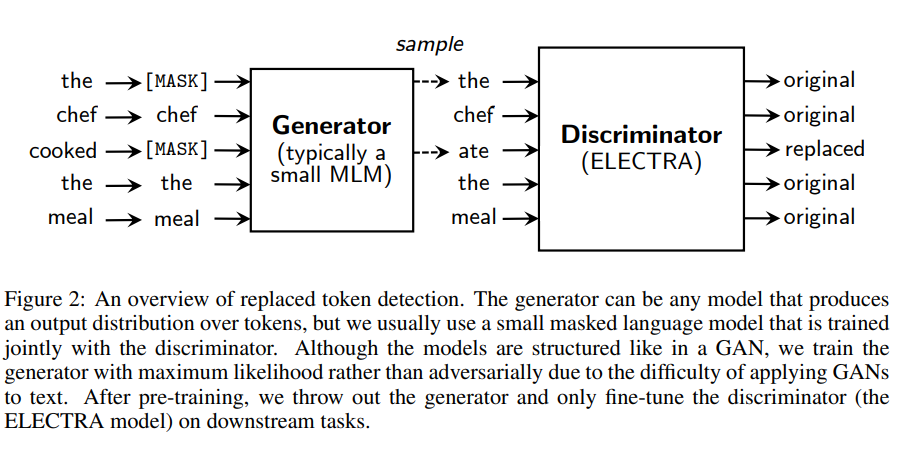
Introduction에서 간략히 설명했던 것처럼 replaced token detection 태스크로 트레이닝하기 위해서는 입력 문장의 토큰 중 일부를 다른 토큰으로 바꾸는 Generator와 진짜와 가짜 토큰을 구분하는 Discriminator가 필요
- 두 네트워크는 공통적으로 Transformer 인코더 구조이며, 입력 토큰 시퀀스 와 해당 입력의 문맥 정보를 반영한 벡터 시퀀스 로 매핑함.
-
Generator
masked language modeling과 같은 방식. 아래와 같은 순서로 학습 진행.
-
입력 이 주어졌을 때, 먼저 마스킹할 위치()를 랜덤으로 k개 선택
- 일반적으로 를 사용(전체 입력 토큰의 15%)
-
선택된 위치를 [MASK] 토큰으로 치환 : 로 표기
-
마스킹된 위치 에 대해서 softmax layer로 특정 토큰 를 생성할 확률을 계산함(마스킹된 위치에 올 토큰을 예측하는 것과 같은 의미)
- = 토큰 임베딩
-
마스킹된 토큰의 확률을 최대가 되도록(maximum-likelihood) 학습
- 최종적인 generator loss :
- 최종적인 generator loss :
-
-
Discriminator
입력 토큰 시퀀스에 대해서 각 토큰이 원 입력의 토큰(original)인지 치환된 토큰(replaced - generator에서 생성한 토큰)인지 이진 분류. 아래와 같은 순서로 학습 진행.
-
Generator에서 마스킹한 입력 토큰을 예측. 이 때, generator에서 결정한 마스킹할 위치()에는 [MASK]이 아닌 softmax 분포()에서 샘플링한 토큰으로 치환(corrupt/replaced)됨.
- 이를 로 표기하고, for
-
각 토큰의 위치 가 주어졌을 때, sigmod layer로 가 “실제" 토큰인지 아닌지를 예측. 즉, generator가 생성한 토큰인지 아닌지 예측하는 방식으로 학습
- 최종적인 discriminator loss:
- 최종적인 discriminator loss:
-
-
GAN과의 차이점
- generator가 정답 토큰(원 입력의 토큰)을 생성했다면 “가짜 토큰”이 아닌 “진짜 토큰”으로 취급(GAN에서는 negative sample로 취급함)
- generator는 discriminator를 속이려는 적대적인 방식(adversarially)으로 학습하는 것이 아니고 maximum likelihood로 학습함
- generator에서 샘플링하는 과정 때문에 역전파가 힘들어서 generator를 적대적인 방식으로 트레이닝하는 것이 어려움.
- a.때문에 generator에 강화 학습을 적용해봤지만, maximum likelihood를 사용하는 것보다 성능이 떨어졌음.
- generator의 입력으로 노이즈 벡터를 사용하지 않음
-
최종적으로 ELECTRA는 대용량의 코퍼스 에 대해서 아래와 같은 loss를 최소화 하도록 학습함.(generator loss + discriminator loss)
- discriminator의 loss를 generator로 역전파하지 않음. (앞서 GAN과의 차이점에서 설명한 것처럼 샘플링 단계 때문에 역전파를 할 수 없음)
- pre-training 단계를 끝난 후에는 discriminator만을 사용하여 각 태스크에 맞게 파인 튜닝을 함.
3. Experiments
3.1 Experimental setup
- General Language Understanding Evaluation(GLUE) 벤치마크와 Stanford Question Answering(SQuAD) 데이터셋을 사용하여 모델을 평가함.
- 대부분의 실험에서는 BERT와 똑같은 데이터(Wikipedia, BooksCorpus - 3.3B tokens)를 사용하여 pre-train.
- Large model은 XLNet과 같은 데이터(BERT 데이터 + ClueWeb - 33B tokens)를 사용함.
- 모델의 구조와 대부분의 하이퍼파라미터도 BERT와 똑같이 사용.
- GLUE fine-tuning : ELECTRA + linear classifiers
- SQuAD fine-tuning : ELECTRA + question-answering module(from XLNet)
3.2 Model Extensions
모델의 성능 개선을 위하여 몇 가지 기법을 추가함. 모델 개선 실험에서는 BERT-Base와 동일한 크기와 데이터를 사용.
- Weight sharing
- pre-training의 효율 향상을 위해서 generator와 discriminator의 가중치를 공유함. generator와 discriminator는 모두 Transformer의 인코더 구조를 사용하기 때문에 같은 크기라면 모든 가중치를 묶어서 사용할 수 있음.
- 하지만, 실험(아래 smaller generators 참고)을 통해서 generator는 더 작은 모델을 사용하는 것이 효과적임을 알아냈기 때문에 일부 가중치(token and positional embeddings) 만을 공유하는 방식을 사용.
- generator와 discriminator의 크기를 동일하게 설정하고 가중치 공유 전략을 비교함. (500k 스텝 동안 모델을 트레이닝) 가중치 공유하지 않았을 때 : 83.6 토큰 임베딩을 공유했을 때 : 84.3 전체 가중치를 공유했을 때 : 84.4
- generator와 discriminator의 크기를 동일하게 설정하고 가중치 공유 전략을 비교함. (500k 스텝 동안 모델을 트레이닝) 가중치 공유하지 않았을 때 : 83.6 토큰 임베딩을 공유했을 때 : 84.3 전체 가중치를 공유했을 때 : 84.4
- 모든 가중치를 공유했을 때의 성능이 가장 높기는 했지만 generator와 discriminator의 크기를 반드시 동일하게 사용해야 한다는 제약이 생기기 때문에 토큰 임베딩을 공유하는 방향을 사용.
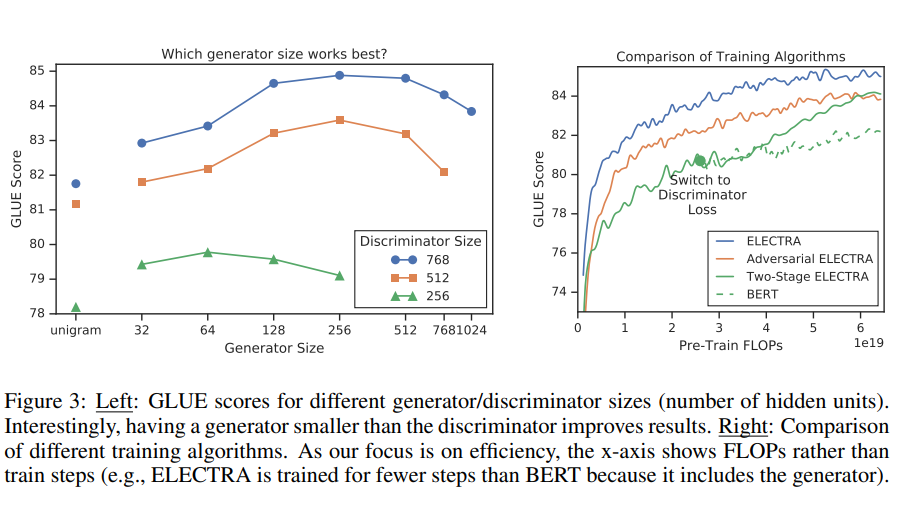
- Smaller Generators
- generator와 discriminator를 동일한 크기로 사용한다면, 일반적인 masked language modeling을 학습시키는 것보다 2배 이상의 계산량이 필요함.
- 다른 하이퍼파라미터는 그대로 사용하고, 레이어 개수를 줄임으로 모델의 크기를 줄여서 작은 generator를 사용함.
- 또한 “unigram” generator를 사용.
- unigram generator : 학습 코퍼스 내에서 토큰의 빈도에 기반하여 토큰을 생성하는 방식.
- generator와 discriminator의 사이즈에 따른 GLUE score를 측정했을 때(Figure 3 참고), generator의 크기는 discriminator의 1/4-1/2로 설정하는 것이 가장 좋은 성능을 보임.
- 논문에서는 generator의 성능이 너무 뛰어나면 discriminator에게 너무 어려운 과제가 주어져서 오히려 학습 효율이 떨어지는 것이 원인일 것이라고 해석함.
- generator와 discriminator를 동일한 크기로 사용한다면, 일반적인 masked language modeling을 학습시키는 것보다 2배 이상의 계산량이 필요함.
- Training Algorithms
- ELECTRA의 학습 방식에 대해서 여러 실험을 진행했지만, 성능 향상에 도움이 되지는 않았음.
- 기본적으로 제안하는 training object는 generator와 discriminator를 함께 학습 시키는 방식이고, 다음과 같은 두 단계의 학습 방법도 시도
-
스텝 동안 을 이용하여 generator만을 학습
-
generator의 가중치로 discriminator의 가중치를 초기화. 스텝 동안 를 이용하여 discriminator만 학습(generator의 가중치는 고정)
또한, 강화 학습을 이용하여 generator를 GAN과 같이 적대적인 방법으로 학습하는 방법도 시도함.
-
- 실험 결과, generator와 discriminator를 함께 학습 시키는 방식이 가장 성능이 좋았음(Figure 3의 오른쪽 참고)
