PyTorch Tutorial 01. Linear Layer & nn.Module

이 글은 한빛미디어의 '김기현의 딥러닝 부트캠프 with 파이토치'를 읽고 정리한 것입니다.
Linear Layer (선형 계층)
선형 계층은 심층 신경망(deep neural networks)의 가장 기본적인 요소입니다. 이는 single layer 즉, 한 층으로 구성된 신경망과 같습니다. 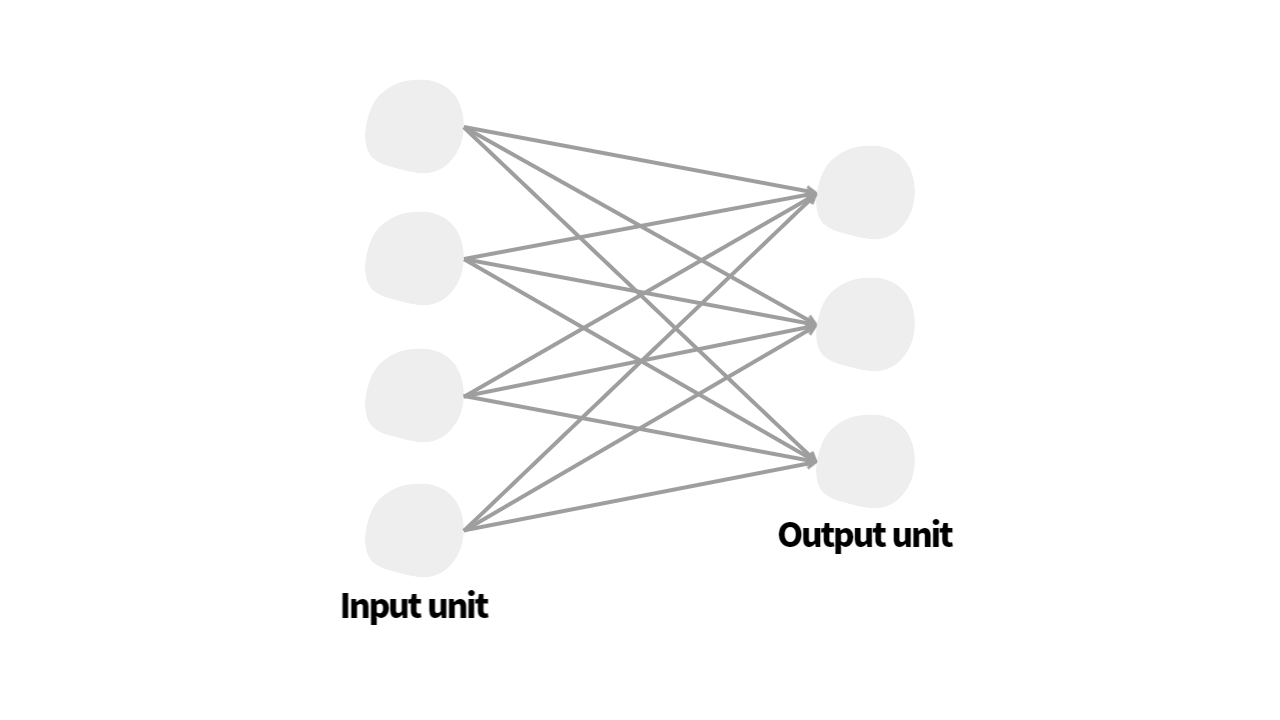
이때, 출력 노드(ouput node)는 입력 노드(input node)로부터 들어온 값에 weight parameter()를 곱한 후, bias term()를 더한 값이 됩니다.
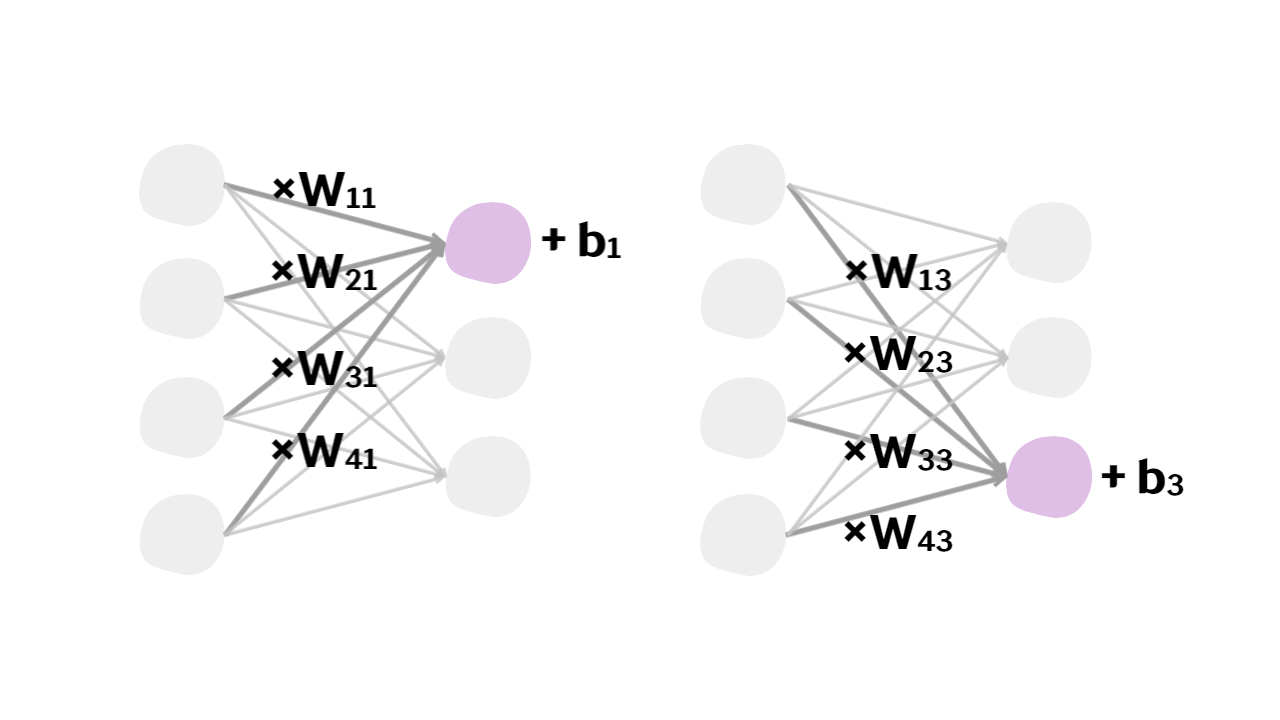
그림과 같은 예시에서는 총 12개의 weight parameter와 3개의 bias term이 존재하고 이들을 행렬 및 벡터로 표현할 수 있습니다.
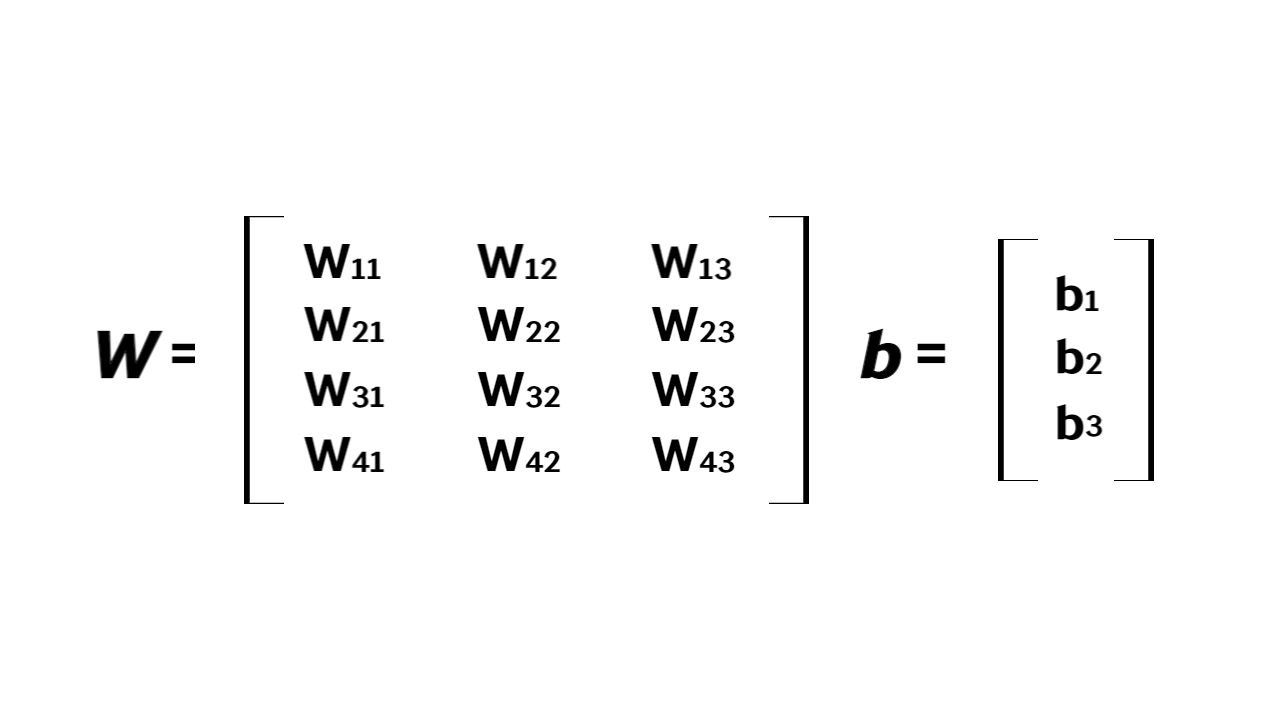
이 동작 방식을 일반화하여 수식으로 나타내면 다음과 같습니다.
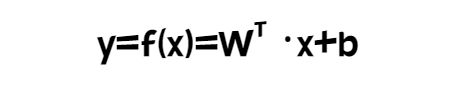 nm의 크기를 가진 행렬 에 의해 n차원의 실수 벡터인 입력 벡터 x가 m차원의 실수 벡터인 출력 벡터 y로 변환될 수 있습니다.
nm의 크기를 가진 행렬 에 의해 n차원의 실수 벡터인 입력 벡터 x가 m차원의 실수 벡터인 출력 벡터 y로 변환될 수 있습니다.
선형 계층은 행렬의 곱셈과 덧셈으로 이루어져 있으므로 선형 변환입니다. 따라서 선형 계층의 구조를 가진 모델을 설계하여 선형 데이터에 대한 관계를 분석하거나 선형 함수를 근사 계산할 수 있습니다.
지금까지 설명한 선형 계층 개념을 파이썬으로 구현해보도록 하겠습니다.
torch.nn.Module 상속 받기
nn.Module이란?
torch.nn.Module은 PyTorch의 모든 Neural Network의 Base Class입니다. 우리가 만들고자 하는 Model은 nn.Module의 subclass가 됩니다. 즉, Deep Learning Model을 만들기 위해서는 nn.Module을 상속받는 class를 만들어야합니다.
[참고자료] nn.Module의 소스코드
torch에서 model을 만들 때
- torch.nn.Module을 상속받아야 합니다.
- __init__()과 forward()를 overriding해야 합니다.
이때, __init__() method에서 super().__init__()을 입력해주어야합니다.
cf) super(class_name, self).__init__() : super().__init__()와 기능의 차이는 없으며, 단지 파생클래스를 명시합니다.
import torch
import torch.nn as nn
x = torch.FloatTensor(4, 3)
class MyLinear(nn.Module):
def __init__(self, input_dim=3, output_dim=2):
self.input_dim = input_dim
self.outpu_dim = output_dim
super().__init__()
self.W = torch.FloatTensor(input_dim, output_dim)
self.b = torch.FloatTensor(output_dim)
def forward(self, x):
y = torch.matmul(x, self.W)+self.b
return y
linear = MyLinear(3, 2)
y = linear(x)이때, 중요한 점은 nn.Module을 상속받은 객체는 __call__ 함수가 forward 함수와 mapping 되어 있어 foward 를 따로 호출할 필요가 없다는 것입니다.
#__call__과 mapping 되어 있지 않아서 따로 호출 해야할 때
y = linear.forward(x) 이렇게 nn.Module을 상속받아 선형 계층(linear layer)를 구현여 계산을 수행할 수 있지만 이 방법으로는 학습을 진행할 수 없습니다. W(weight)와 b(bias)가 학습이 가능한 parameter로 설정되어있지 않기 때문입니다. nn.Parmater을 활용하여 학습이 가능한 parameter로 인식시켜줄 수 있습니다.
class MyLinear(nn.Module):
def __init__(self, input_dim=3, output_dim=2):
self.input_dim = input_dim
self.outpu_dim = output_dim
super().__init__()
self.W = nn.Parameter(torch.FloatTensor(input_dim, output_dim))
self.b = nn.Parameter(torch.FloatTensor(output_dim))
def forward(self, x):
y = torch.matmul(x, self.W)+self.b
return y
선형 회귀 모델 nn.Linear 활용하기
torch.nn에 이미 정의된 linear layer인 nn.Linear을 이용하여 모델을 구현할 수 있습니다.
torch.nn.Linear(in_features,out_features,bias = True, device = None,dtype = None)
또한 다음과 같이 nn.Module을 상속받는 class 내부에 nn.Linear을 이용하는 방법도 있습니다.
class MyLinear(nn.Module):
def __init__(self, input_dim=3, output_dim=2):
self.input_dim = input_dim
self.outpu_dim = output_dim
super().__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
y = self.linear(x)
return yGPU 사용하기
PyTorch에서는 CUDA를 통한 GPU 연산을 지원합니다. 앞에서 구현한 코드들이 GPU에서 동작하도록 해보려 합니다.
1)
2) 
3) cuda() 함수는 tensor 뿐만 아니라 nn.Module의 하위 클래스 객체에도 적용할 수 있습니다.

device='cuda:0' 에서 cuda: 뒤에 오는 숫자는 GPU device의 index를 의미합니다. 즉, 0은 첫 번째 device인 0번 GPU를 의미합니다.
cuda() 함수의 인자에 GPU 장치의 인덱스를 입력하여 원하는 device에 복사 또는 이동이 가능합니다.
x = x.cuda(device=1)과 같이 tensor를 원하는 device에 복사합니다.- nn.Module 하위 클래스 객체의 경우에는 복사가 아닌 이동이 수행됩니다.
이때, 두 번째 GPU device를 가지고 있지 않는다면 오류가 발생합니다.
Tensor와 nn.Module의 하위 클래스 객체끼리는 서로 같은 device에 있을 때만 연산이 가능합니다. device=0과 device=1 사이의 연산도 불가능합니다.
cpu 함수
GPU 메모리 상에 있는 tensor는 cpu() 함수를 이용하여 CPU 메모리로 복사할 수 있습니다.

To 함수
Pytorch에서 제공하는 to() 함수는 device의 정보를 담은 객체를 인자로 받아 함수 자신을 호출한 객체를 해당 디바이스로 복사 또는 이동시킵니다. 이때, device 정보를 담은 객체는 torch.device를 통해 생성할 수 있습니다.
cpu = torch.device('cpu')
gpu = torch.device('cuda:0')
x = torch.cuda.FloatTensor(2, 2)
xtensor([[0.0000e+00, 1.0418e+03],
[0.0000e+00, 1.7157e-05]], device='cuda:0')x = x.to(gpu)
xtensor([[0.0000e+00, 1.0418e+03],
[0.0000e+00, 1.7157e-05]], device='cuda:0')x = x.to(cpu)
xtensor([[0.0000e+00, 1.0418e+03],
[0.0000e+00, 1.7157e-05]])
Device 속성
x = torch.cuda.FloatTensor(2, 2)
x.devicedevice(type='cuda', index=0)Tensor는 device 속성을 가지고 있어 해당 tensor가 위치한 device를 확인할 수 있는 반면 nn.Module의 하위 클래스 객체는 device 속성을 가지고 있지 않아 다음과 같은 방법을 이용합니다.
layer = nn.Linear(2, 2)
next(layer.parameters()).devicedevice(type='cpu')위와 같은 방법을 사용하는 경우 model 내부의 모든 parameter가 같은 device에 위치해야 합니다.
