1. Data Cleaning의 개념
데이터 정제
데이터에서 부정확한 레코드를 감지 및 수정(or 제거)하는 과정
(ex. 이상치를 감지하여 제거, 결측치를 찾아 보간)
- 데이터의 유효성, 정확도, 완전성, 일관성을 유지하고 신뢰성을 향상시키는 과정
데이터 전처리
데이터를 주어진 양식에 맞게 변경/수정하는 과정
(ex. 딥러닝 학습을 위해 이미지 데이터 256X256 -> 27X27 으로 size 변경)
(데이터 전처리와는 다른 개념)
Data Cleaning의 종류
- 데이터 통합
- 결측치 처리
- 정규화
- 노이즈 제거
- Feature Selection / Extraction
(다음 chapter에서)
2. 데이터 통합
데이터 분석은 다양한 곳에서 수집하기에, 하나로 합치는 작업 필요
(데이터 분석 및 비지니스 의사 결정에 중요한 역할을 함)
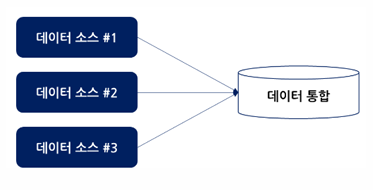
데이터 통합 프로세스
(1) 통합 데이터 선정
어떤 데이터를 통합할 지 선정하는 과정
- 요구 사항에 따라 선정
(2) 표준사전 정의
수집 데이터에 대한 표준 어휘를 사용하여 데이터의 속성을 정의
- 용어, 단어, 도메인 3가지를 정의함
(이 과정을 거치지 않으면, 사람마다 나름의 규칙으로 테이블을 생성해서 안 맞음)
(3) 중복 데이터 판단
중복 데이터는 데이터의 정확도와 신뢰성을 저해, 그래서 반드시 확인해야 함
(중복 데이터의 종류 : 인스턴스 중복 / 속성 중복)
- Instance 중복 : data set에서 동일한 레코드가 두 번 이상 나타나는 경우
(ex. 제품 데이터에서 동일한 제품이 두 개 이상인 경우) - 속성 중복 : data set에서 동일한 속성이 두 번 이상 나타나는 경우, feature명 지정 방법이 모호하거나 다른 경우 발생
(ex. 무게, 체중 같이 저장한 경우)
(4) 통합
Solution 1. 단순 데이터 붙이기 (Concatenate)
여러 개의 데이터 파일이 있는 경우, column / row를 결합하는 작업
(단순히 배열을 합치는데 사용)
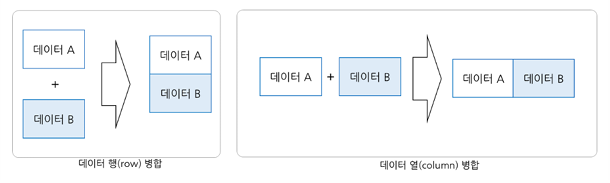
- feature을 고려하지 않고, 데이터 크기만을 비교하여 합침
- pandas의 경우 크기가 다르면 NaN값으로 채움
(일방적인 데이터 붙이기로 인해, 많은 결측치를 야기)
Solution 2. 데이터 병합 (Join, Merge)
일반적으로 특정 키 값을 기준으로 병합
- Data Join : 가장 일반적인 데이터 병합 방법

Join() 사용 방법
: index를 기준으로 합치기에, 기준 index를 지정해줘야 함
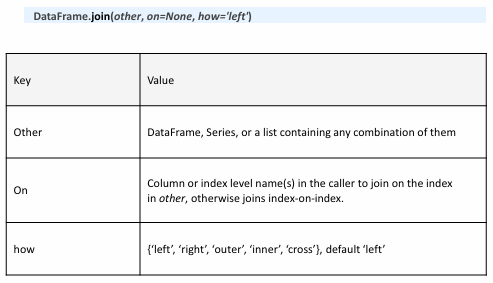
Merge() 사용 방법
: 눈치있게 알아서 value를 기준으로 합침
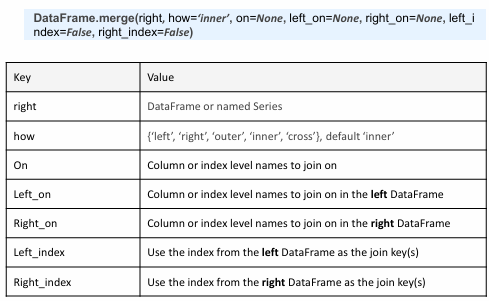
#inner join 실행
pd.merge(df1, df2, how='inner')3. 결측치 처리
결측치 : 데이터 수집을 했지만 데이터 값이 없는 경우
(NaN 혹은 Null 값 형태로 존재)
결측치 발생 원인
- 데이터 수집/관리 과정 중에 누락된 경우
- 수집할 필요가 없었는데, 새롭게 수집하기 시작한 항목이 있는 경우
- 서로 다른 속성의 데이터를 통합한 경우
결측치를 처리하는 이유
- 데이터의 신뢰성 높이기
(하지만 잘못 처리하면 데이터 편향 생길 수도 있음)
결측치 처리 가이드
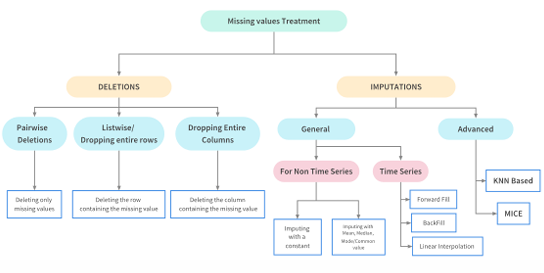
Soultion1. 결측치 삭제하기
행 또는 열을 제거하는 것
(데이터의 양이 적을 경우 유용하지 않은 방법)
결측치 삭제 기준
- 10% 미만 : Data를 삭제하거나, 치환
- 10~50% : 모델을 만들어서 처리
- 50% 이상 : column 삭제
결측치 삭제 방식
- 목록 삭제 (Listwise deletion)
결측치가 발생한 행 자체(데이터)를 삭제 - 부분 삭제 (Pairwise deletion)
결측치를 삭제하고 빈칸으로 사용하는 경우
(다른 feature에 결측치가 있어도 다른 변수가 채워져 있으면 분석에 그대로 사용)
(Listwise에 비해 많은 데이터 사용 가능) - 속성 변수 삭제 (Dropping variables)
row를 삭제하는 것이 아니라 column을 삭제
(한 feature에 결측치가 많이 포함되면 column을 삭제하는 것이 좋음)
Soultion2. 결측치 대체하기
결측치에 대해 합리적인 값으로 대체하는 방법
결측치 대체 방식
- 평균값, 중앙값, 최빈값 등의 대푯값으로 대체
(Categorical feature의 경우 NaN을 채우거나, 최빈값으로 대체) - 선형 보간법 등의 수치 예측 방법을 사용하여 대체
(시계열 데이터의 경우 이전/이후 값을 활용하여 대체) - 결측치 모델을 사용하여 대체
4. 정규화(Normalization) vs 표준화(Standardization)
두 개 이상의 변수를 탐색할 경우, 정확한 비교를 위해 scaling 필요
- 중요도가 다르게 반영되어 학습
(데이터의 크기가 들쑥날쑥하면 데이터를 이상하게 해석할 우려 존재)
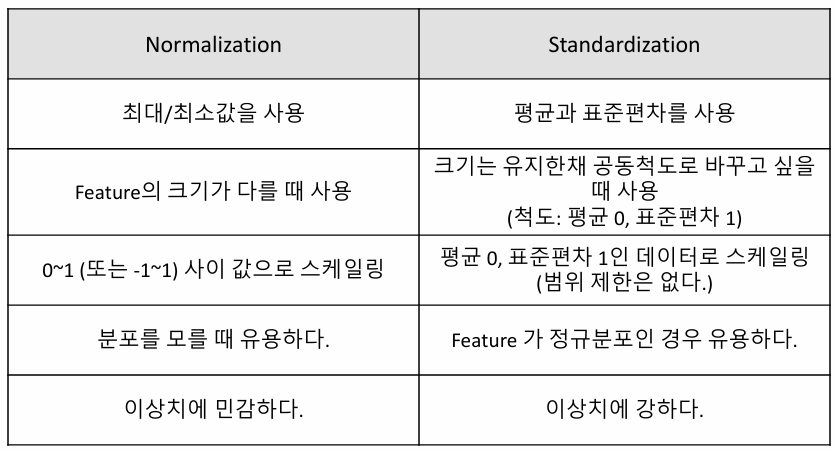
정규화(Normalization)
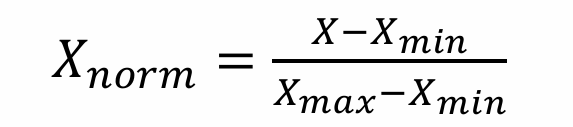
최소값을 0, 최대값을 1로(또는-1~1) 만들고 이사이에 데이터들이 배치됨.
(데이터의 최대값과 최소값이 사용되므로 Min-Max Normalization 이라고도 함)
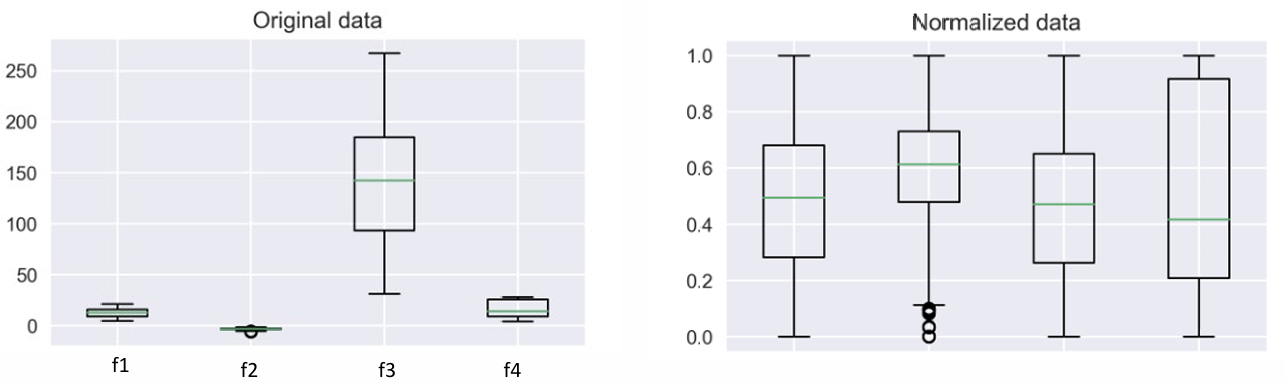
- 장점 : 모든 데이터를 0~1 사이 범위로 제한하여, 모델 학습에 각 특성이 동등하게 고려될 수 있도록 함
- 단점 : 이상치에 매우 민감하여, 이상치가 있는 경우 데이터 범위가 크게 왜곡됨
표준화(Standardization)
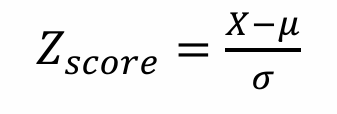
데이터의 평균을 0, 표준편차를 1로 조정하는 방법
(정규화는 스케일을 통일하지만 표준화는 데이터 범위를 통일)
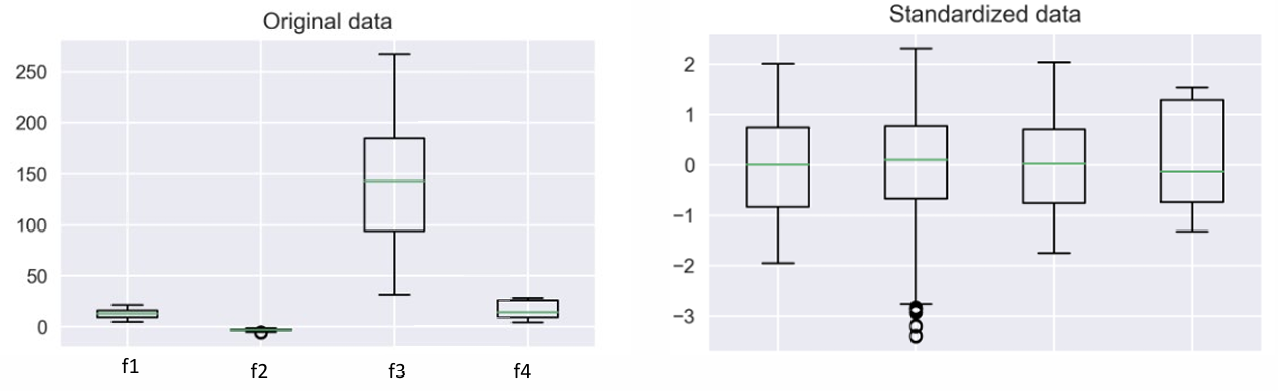
- 장점 : 이상치에 영향을 덜 받으며, 데이터 분포가 평균 주변으로 어떻게 퍼져있는지를 반영함
- 단점 : 모든 데이터 포인트가 동일한 범위에 있지 않기 때문에 중요도가 다를 수 있음
데이터 처리 tip
'Data -> 표준화 -> 이상치 제거 -> 정규화' 순으로 처리하면 좋음
5. 노이즈 제거
노이즈 : 실제 입력된 신호가 아닌 것 / 잘못 판단된 값
노이즈의 종류
- 화이트 노이즈 : 일정 규칙 없이 랜덤하게 발생하는 잡음
- 통계적 노이즈 : 통계적으로 분포를 따르는 잡음
노이즈 처리 방법 (대표적인)
- Moving Average Filter
이동하면서 주위 값들에 비해 높거나 낮을 경우 평균값으로 대체 - Median Filter
일정 범위의 중간 값을 해당 지점의 값으로 지정(잡음이 클 경우 MAF보다 좋음) - Bandpass Filter
주파수 기반의 필터
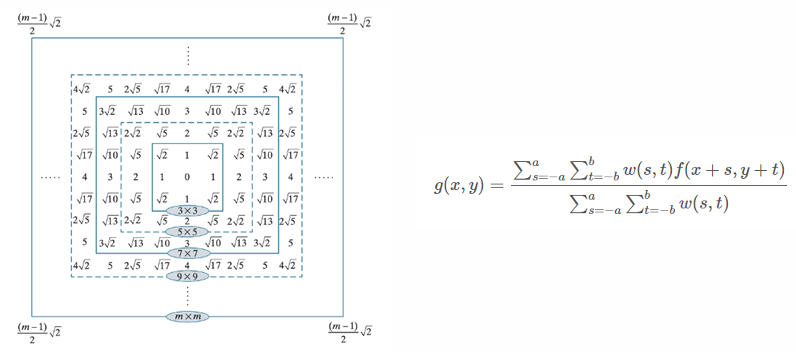
Smooth Filter
특정 윈도우 영역(Sliding window) 내에 포함되는 값들의 평균으로 필터링
(스무딩 선형필터, 평균 필터, 저역통과 필터라고 부름)
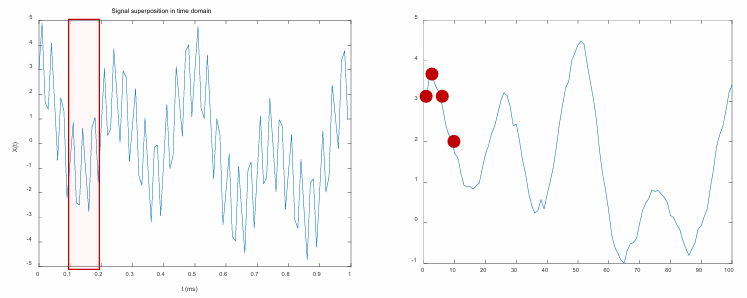
필터의 크기가 커질 수록 블러링(blurring) 효과가 커지는 것을 볼 수 있음
Gaussian Filter
가운데 있는 값이 가장 큰 정보를 가지며, 중앙으로부터 멀어질 수록 값이 작아지도록 하는 필터
실습 1. 중복 데이터 제거하기
1) drop_duplicates()로 중복제거 실행
2) subset=[‘brand’] 를 넣어서 실행
3) subset=[‘brand’, ‘style’], keep=[‘last’] 넣어서 실행
4) 3번 예제에 ignore_index=True 옵션을 넣어서 실행
5) 3번 예제에 inplace=True 옵션을 넣어서 실행 후 데이터 확인
import pandas as pd
df=pd.DataFrame({
'brand' : ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style' : ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating' : [4,4,3.5,15,5]
})
print(df)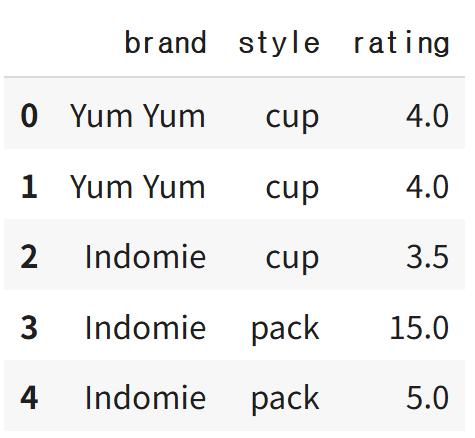
df.drop_duplicates()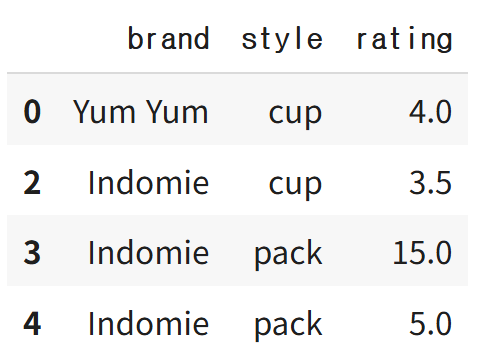
df.drop_duplicates(subset=['brand'])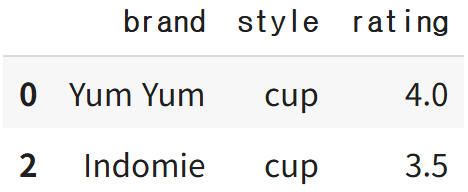
df.drop_duplicates(subset=['brand','style'],keep='last')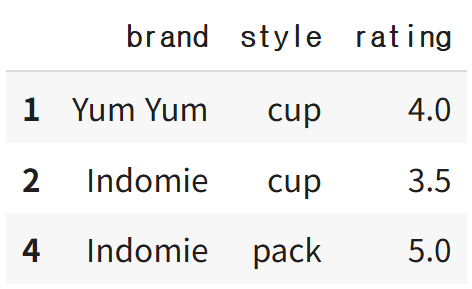
실습 2. 결측치 제거 및 대체
데이터 불러오기
import pandas as pd
import seaborn as sns
df=sns.load_dataset('titanic')
print(df)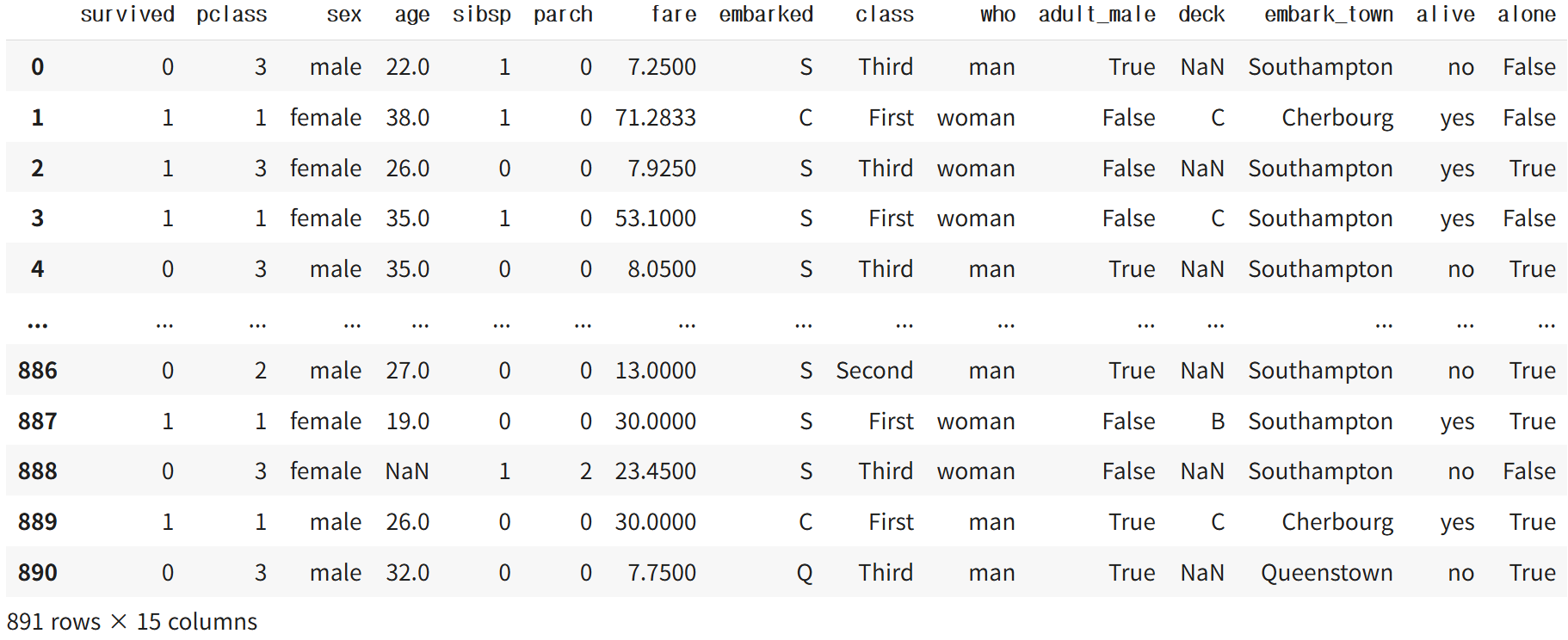
데이터 정보 살펴보기
df.info()
df.isnull().sum() #결측치 확인 1
df.notnull().sum() #결측치 확인 2
결측치 삭제
pandas의 dropna 함수를 사용하여 결측치를 삭제
axis=0 (row), axis=1 (column) 삭제를 실행
df_del_row=df.dropna(axis=0)
df_del_row.info()
df_del_row=df.dropna(axis=1)
df_del_row.info()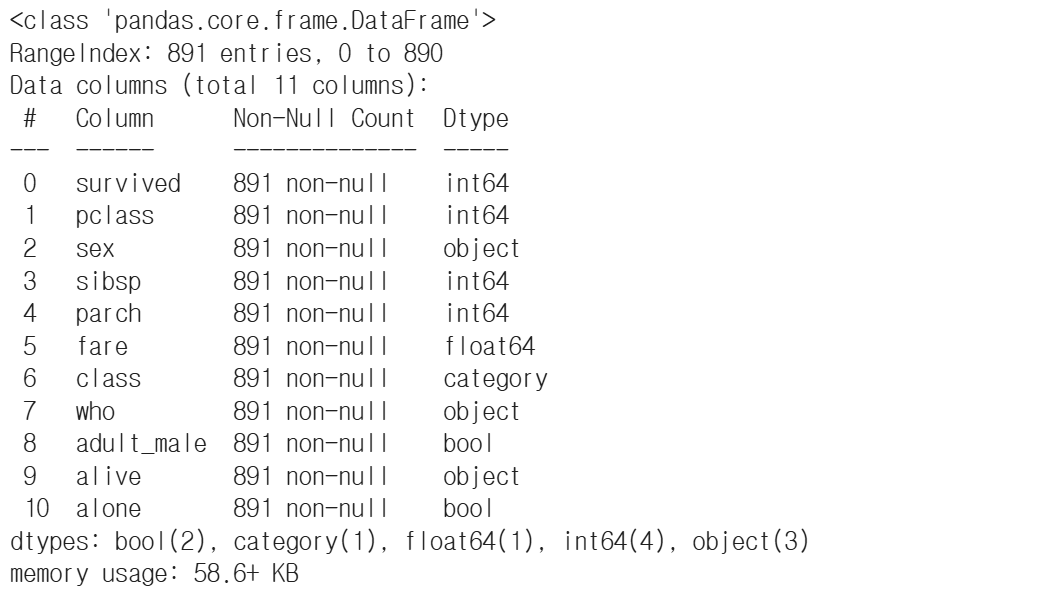
결측치 대체
pandas의 fillna 함수를 사용하여 결측치를 대체
updated_df=df
updated_df['age'].fillna(updated_df['age'].mean())
updated_df.info()
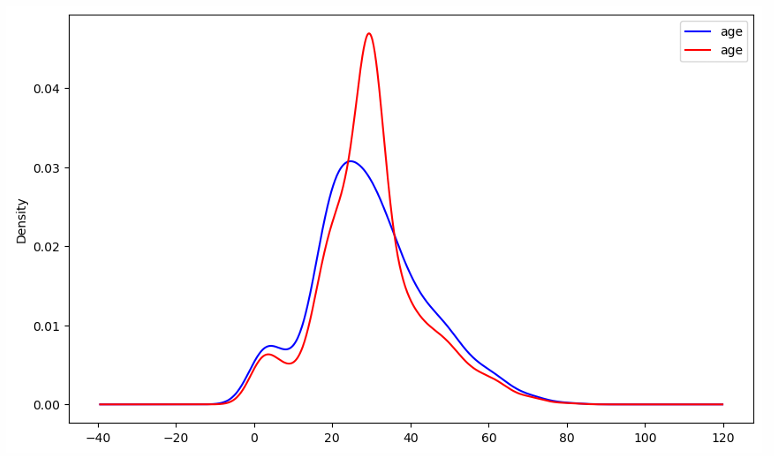
import matplotlib.pyplot as plt
fig,ax=plt.subplots(figsize=(10,6))
df['age'].plot(kind='kde', ax=ax, color='blue')
updated_df['age'].plot(kind='kde', ax=ax, color='red')
lines, labels=ax.get_legend_handles_labels()
ax.legend(lines, labels, loc='best')