
1. Underfitting vs Overfitting
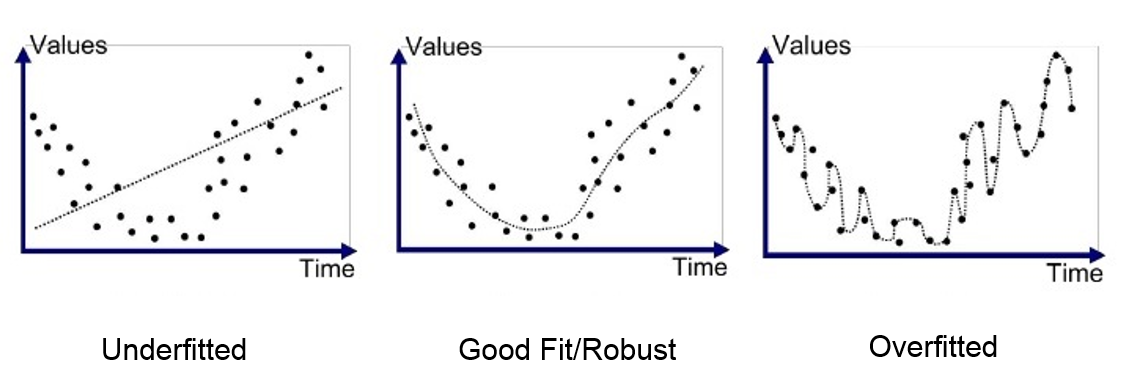
Underfitting
모델이 데이터를 제대로 학습하지 못해서, 학습 데이터조차 잘 예측하지 못하는 상태
Underfitting의 원인
- 데이터셋 충분하지 않음
- 모델이 너무 단순
- 데이터 전처리 부족
Underfitting의 특징
- 높은 Bias를 보여줌 (학습 데이터에 대해서도 성능 확보 X)
- 학습 및 테이스 데이터 모두 성능 확보 X
Overfitting
모델이 학습 데이터에 너무 과하게 학습하여, 학습 데이터에 대한 성능은 좋지만
새로운 데이터에 대해서는 성능이 떨어지는 상태
(일반화 성능 저하가 핵심 문제)
Overfitting의 원인
- 모델이 복잡함
- 학습 데이터 부족
- 정규화 부족
Overfitting의 특징
- 예측에서 높은 Variance 보여줌
- 새로운 데이터에 낮은 성능 보임
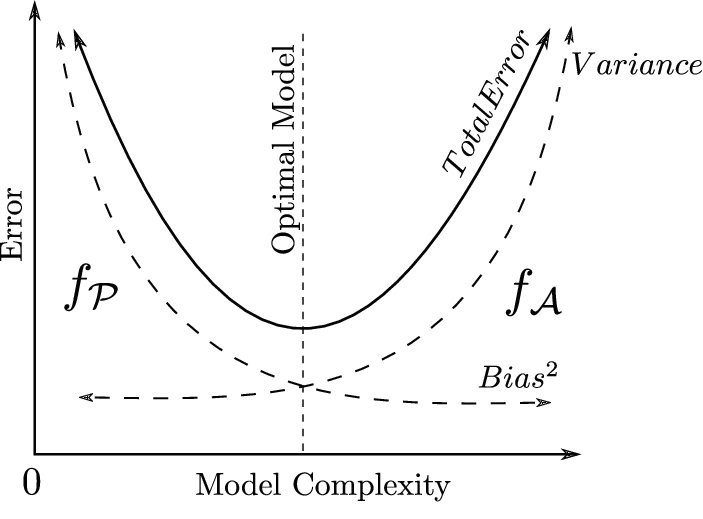
2. Bias vs Variance
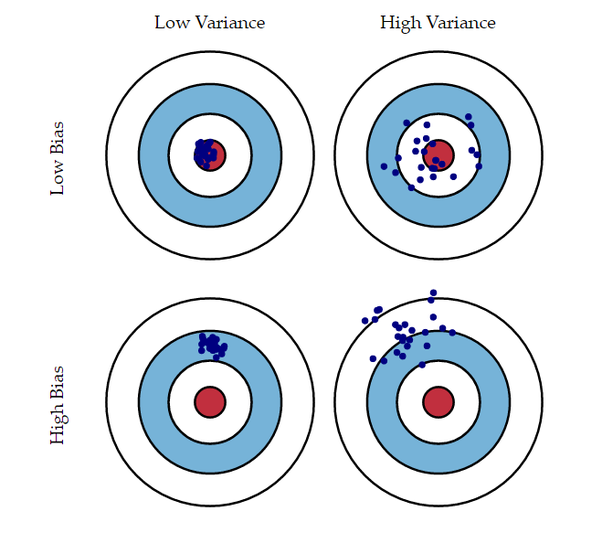
Bias
모델이 학습 데이터의 복잡한 관계를 단순하게 가정하여 발생하는 오차
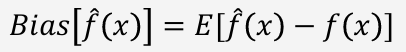
Variance
학습 데이터의 변화에 모델이 과민하게 반응하여 예측 결과가 크게 달라지는 현상
Example. Bias and Variance 판단하기

3. Learning Curves: Model
모델의 복잡도에 따라 Bias와 Variance trade off
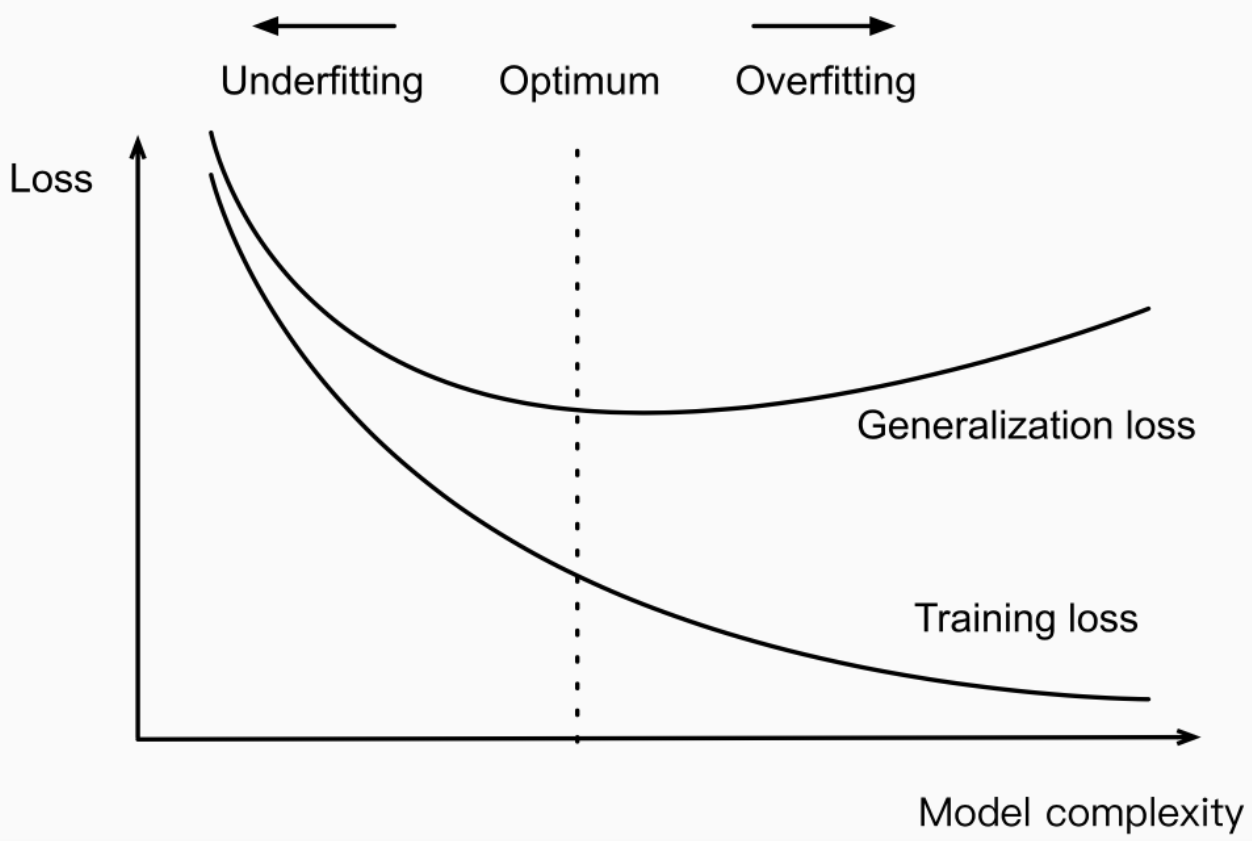
Early Stop
학습을 오래할 수록 학습 데이터를 외워버리는 특성으로 인해 overfitting 문제 생길 수 있음
→ 적당한 시기에 조기 종료 필요
Early stopping의 시점
조기 종료를 위해서 Validation dataset 필요
- Validation dataset의 평가 성능이 떨어지는 시점에 종료
Data size
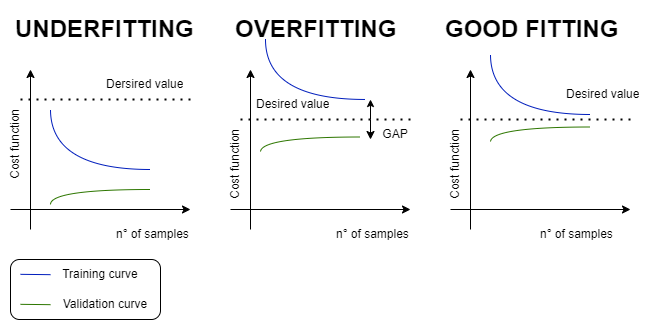
학습 데이터 크기가 작을 경우 → High Variance
- 학습 데이터에 대해서만 성능 좋음 (테스트는 성능 낮음)
학습 데이터 크기가 클 경우 → High Bias
- 학습 데이터에 대한 성능이 떨어질 수 있으나, 일반화 성능이 향상되어 새로운 데이터에 적응 잘함
Model Design 추천
Underfitting의 경우
- 큰 네트워크를 사용
- 오래 학습하기
- 학습 dataset 늘리기
- 다른 신경망 구조 고려
overfitting의 경우
- 작은 네트워크를 사용
- 학습 dataset 늘리기
- Early Stopping 적용
- regularization 적용
4. Vanishing Gradient
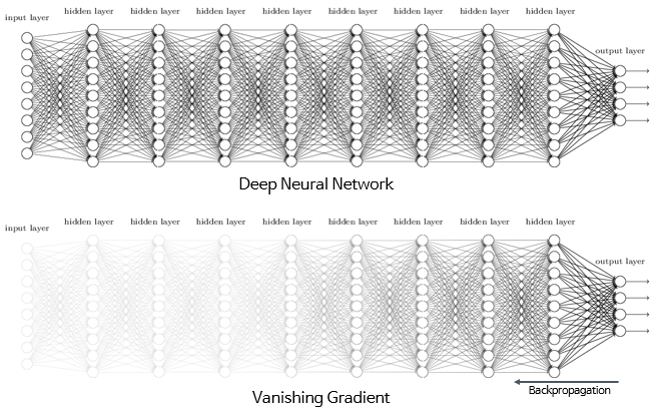
역전파 계산 과정에서 Gradient가 점점 작아져서 0에 가까워지는 현상
(input layer와 가까운 쪽에 학습 이루어지지 않는 문제 발생)
주요 원인
- 역전파의 미분값이 0~1사이의 값을 가지는 활성화 함수를 사용
→ 0에 수렴하는 현상 발생 - 특히 깊은 신경망에서 주로 나타남
Solution. ReLU Function
5. Dropout
학습 중에 일정 확률로 뉴런을 꺼서,
매번 다른 네트워크 구조를 학습하게 하는 정규화 기법
주로 Hidden layer에 사용하고, Output layer에는 사용 안 함
(→ 예측에 직접적인 영향을 주기에)
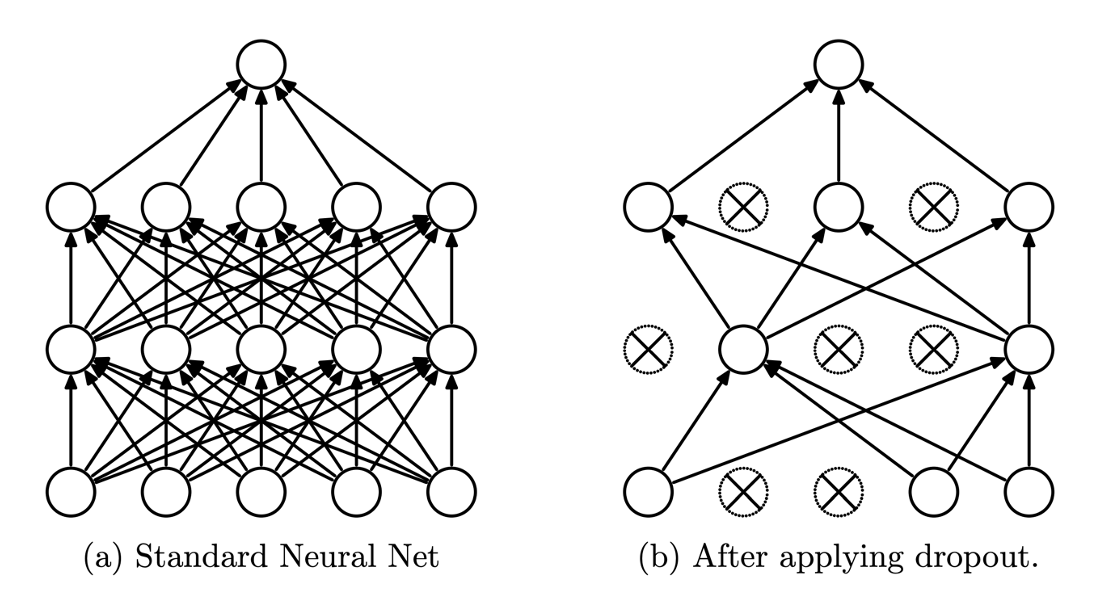
Dropout 동작 방식
- train
뉴런이 꺼질 확률 설정 (하이퍼 파라미터)
학습을 할 때마다 무작위로 은닉층에서 뉴런의 출력 0으로 만듦 - test
모든 뉴런 사용 (Dropout 사용 x)
Dropout의 특징
- 앙상블 효과 : 매번 다른 네트워크로 학습
- 특정 뉴런에 의존하지 않음
Dropout 효과
- 과적합 방지 : 뉴런이 특정 패턴에 과하게 적응하는 것 방지
- 일반화 성능 향상 : 테스트 데이터에 더 잘 맞는 모델 생성
- 구현 간단함
- Co-Adaption 방지: 각 뉴런들의 의존성을 방지하고 독립적으로 유용한 특성을 학습하도록 유도
Co-Adaption (공적응)
여러 뉴런들이 서로 의존해서 작동하도록 학습되는 현상
→ Dropout은 특정 뉴런 조합이 유지되지 못하게 강제하기에, 독립적으로 특징 포착하도록 유도

Dropout 고려해야될 것
1) Dropout Rate (드롭아웃 비율)
- 값이 너무 큰 경우 : Underfitting 가능성 존재
- 값이 너무 작은 경우 : 일반화 효과 떨어짐
2) 적용 위치
- Input layer : 입력층에는 거의 사용 X (적용하더라도 낮은값)
-Hidden layer : 주로 사용
-Output layer : 사용 X (예측값이 불안정해짐)
3) Testing
테스트할 때는 반드시 Dropout 사용 X
4) Model size
모델이 작으면 성능 떨어질 수 있음
5) Data size
데이터 양이 많을 경우, Dropout효과 미미
Dropout의 사용 여부
Dropout이 효과적인 경우
- 훈련데이터가 작고, 과적합 심한 경우
- 모델 복잡성이 높은 경우
- 일반화 성능을 높이고 싶은 경우
Dropout이 효과적이지 않은 경우
- 데이터가 충분히 많고, 일반화가 잘 된 경우
- 모델 크기가 작은 경우
- 다른 정규화 기법을 같이 쓸 경우
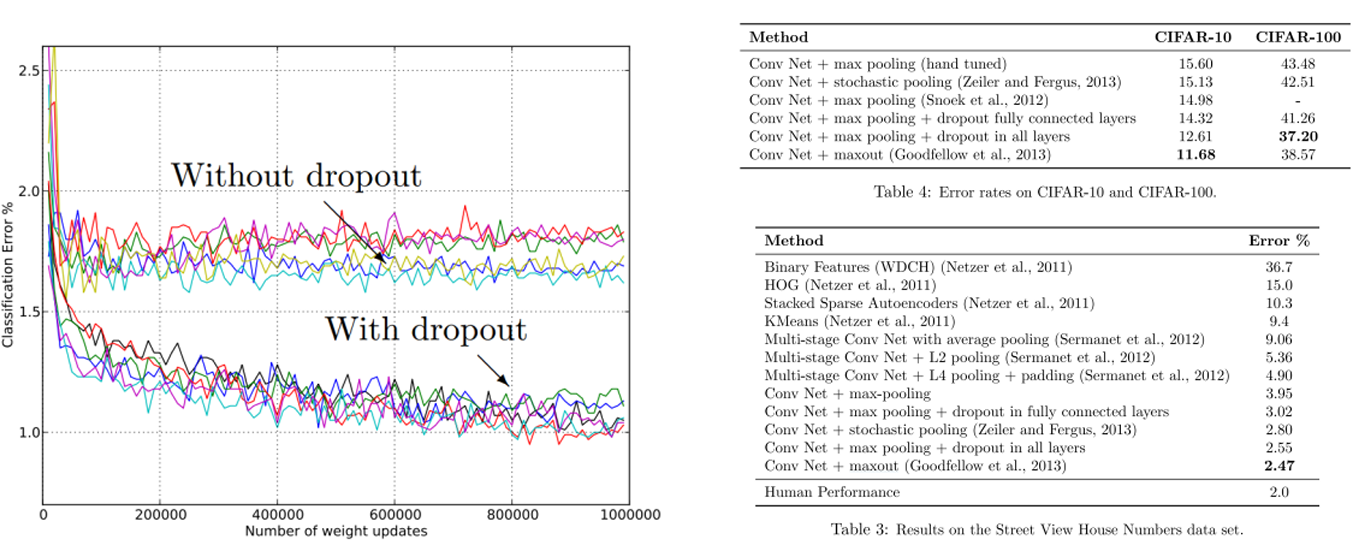
Dropout 성능
6. Batch Normalization (BN)
각 미니배치마다 활성화값을 정규화 하여
학습 안정화와 속도 향상을 유도하는 기법
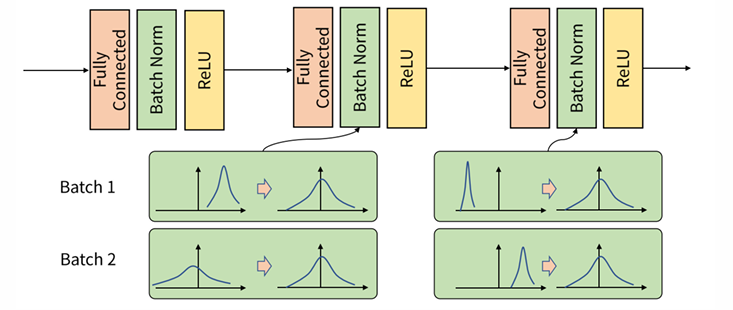
Network -> BatchNorm -> Activation(ReLU) 순서로 작동
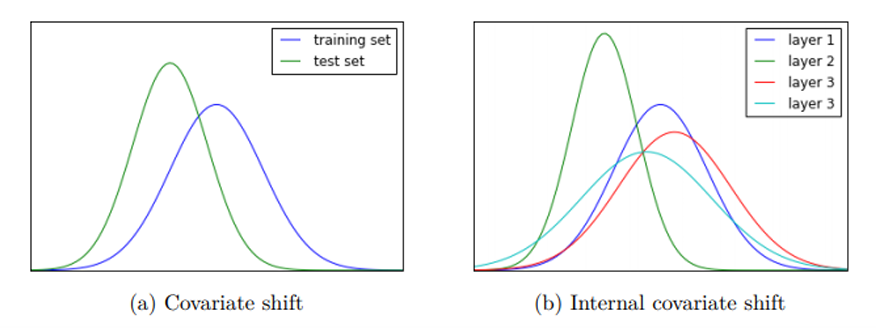
Internal Covariant Shift
학습 데이터(미니배치) 마다 입력 분포가 달라짐
(train dataset과 test dataset의 분포도 다를 수 있음)
- 각 층의 입력 분포가 훈련 도중 계속 바뀌는 현상
- 이에 따른 학습률 조정이나 초기값 설정 어려움
- 깊은 네트워크일 수록 이 현상이 심해짐
Batch Normalization 동작 과정
배치 단위로 입력 를 분포로 정규화
Step1. 배치 평균 계산
Step2. 배치 분산 계산
Step3. 정규화
Step4. 배치 정규화 및 스케일링&쉬프팅
BN 특징
- 학습 속도 증가 : 더 큰 학습률 사용 가능 및 빠른 수렴
- 초기값 민감도 감소 : weight 초기화 잘못되어도 학습됨
- 과적합 완화 : Regularization 효과 가짐
- 안정된 학습 : Exploding / Vanishing gradient 완화
BN 주의할 점
- 배치 크기가 너무 작으면 성능 떨어짐
