
1. Pytorch 소개
Facebook AI Research(FAIR)에서 개발한 오픈소스 딥러닝 프레임 워크
- 동적 계산 그래프 기반 → 코드 흐름을 유연하게 디버
깅, 실험가능
PyTorch의 핵심 구성 요소
- Tensor : 기본 데이터 구조 (Numpy 처럼 생겼지만 GPU 연산 지원)
- Autograd : 자동 미분 기능 내장
- torch.nn : 신경망 모듈 구성 도구
- torch.optim : 학습 최적화 도구(SGD, Adam 등)
- torch.utils.data : 데이터셋 및 미니배치 처리 도구
Tensor 변환
1) NumPy 배열 -> Tensor 변환
import torch
import numpy as np
arr=np.array([1,2], [3,4])
t=torch.from_numpy(arr)
n=t.numpy()2) list -> Tensor 변환
data=[1,2,3]
t=torch.tensor(data)
t=torch.FloatTensor(data)
t=torch.tensor(data, dtype=torch.float32)3) Pandas -> Tensor 변환
import pandas as pd
df =pd.DataFrame({'a': [1, 2], 'b': [3, 4]})
t =torch.tensor(df.values)
# DataFrame→ NumPy → Tensor2. 신경망 구성하기
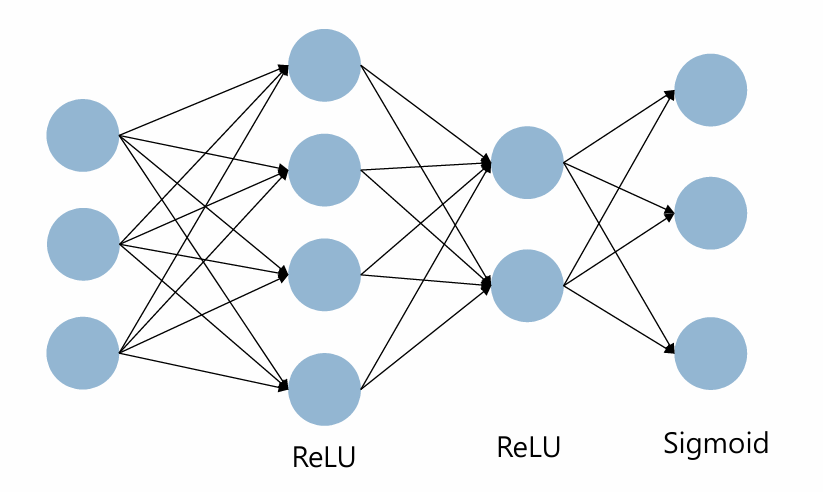
Pytorch로 신경망 구현
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self, input_size, output_size):
super(SimpleModel, self).__init__()
self.linear1=nn.Linear(2,4)
self.linear2=nn.Linear(4,2)
self.linear3=nn.Linear(2,3)
self.act_relu=nn.ReLU()
self.act_sigmoid=nn.Sigmoid()
def forward(self,x):
x=self.linear1(x)
x=self.act_relu(x)
x=self.linear2(x)
x=self.act_relu(x)
x=self.linear3(x)
x=self.act_sigmoid(x)
return xnn.Sequential로 신경망 구현
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.model=nn.Sequential(
nn.Linear(2,4),
nn.ReLU(),
nn.Linear(4,2),
nn.ReLU(),
nn.Linear(2,3),
nn.Sigmoid()
)
def forward(self,x):
return self.model(x)nn.functional로 신경망 구현
import torch.nn as nn
import torch.nn.functional as F
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.linear1=nn.Linear(2,4)
self.linear2=nn.Linear(4,2)
self.linear3=nn.Linear(2,3)
def forward(self,x):
x=F.relu(self.linear1(x))
x=F.relu(self.linear2(x))
x=F.sigmoid(self.linear3(x))
return x3. Loss Function 구현하기
모델이 예측한 결과와 실제 정답 값의 차이를 수치화하는 함수
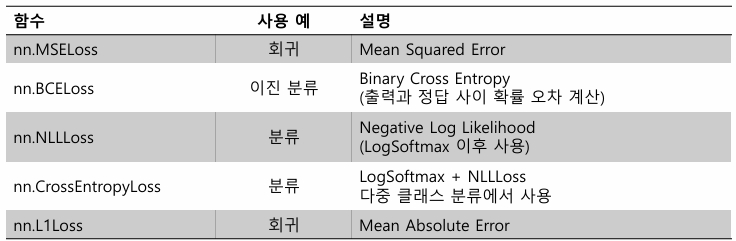
- nn.MSELoss : 회귀
- nn.BCELoss : 이진 분류
- nn.NLLLoss : 분류
- nn.CrossEntropyLoss : 다중 클래스 분류
- nn.L1Loss : 회귀
사용 예시 코드
loss_fn = nn.BCELoss() # loss 함수 정의
Pred = model(X)
# 모델 출력
loss = loss_fn(pred, Y)
# loss 함수를 이용한 예측과 정답 간 오차 계산4. Optimizer 구현하기
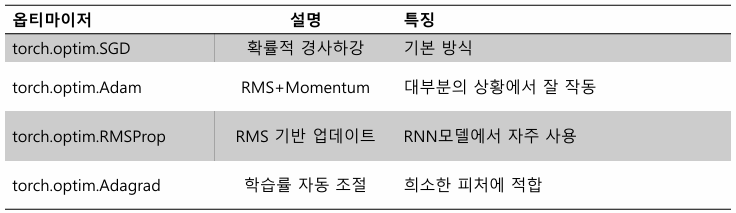
- torch.optim.SGD : 확률적 경사하강법
- torch.optim.Adam : Adam 사용
- torch.optim.RMSProp : RMS 기반 업데이트
- torch.optim.Adagrad : 학습률 자동 조절
사용 예시 코드
import torch.optim as optim
model=MyModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)5. 학습 루프 구현하기
epochs = 1000
for epoch in range(epochs):
outputs = model(x)
loss = criterion(outputs, y)
optimizer.zero_grad() # 기울기 초기화
loss.backward() # 역전파: 기울기 계산
optimizer.step() # 파라미터 업데이트6. PyTorch 신경망 구현 실습
: 딥러닝 모델을 만들고, 학습 후 결과를 출력하기
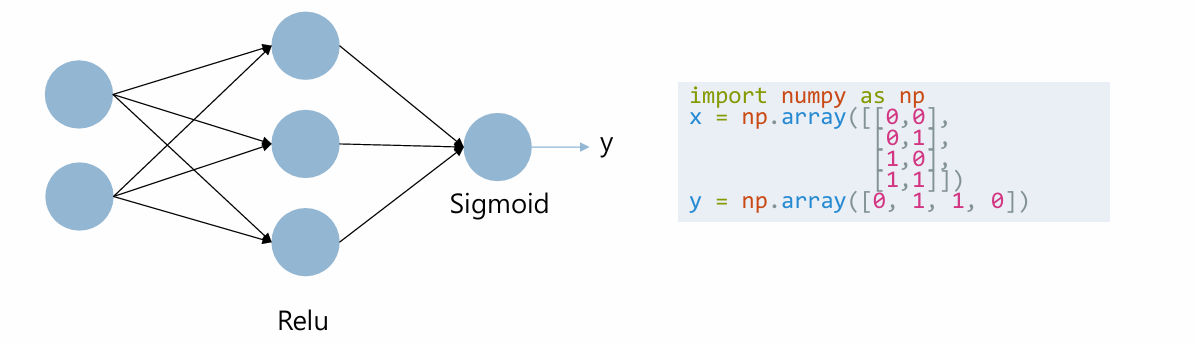
Model 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
class XOR_Model(nn.Module):
def __init__(self):
super(XOR_Model, self).__init__()
self.l1=nn.Linear(2,2)
self.l2=nn.Linear(2,1)
def forward(self, x):
out=F.relu(self.l1(x))
out=F.sigmoid(self.l2(out))
return out
model=XOR_Model()
import torch.optim as optim
criterion=nn.BCELoss()
optimizer=optim.Adam(model.parameters(), lr=0.001)Model 학습
import numpy as np
x = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([0, 1, 1, 0])
x_t = torch.FloatTensor(x).view(-1,2)
y_t = torch.FloatTensor(y).view(-1,1)
num_epochs = 10000
for epoch in range(num_epochs):
outputs =model(x_t)
loss= criterion(outputs, y_t)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 100== 0:
print(f'Epoch[{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
model.eval()
pred = model(x_t)
print(pred)

안녕하세요 :)