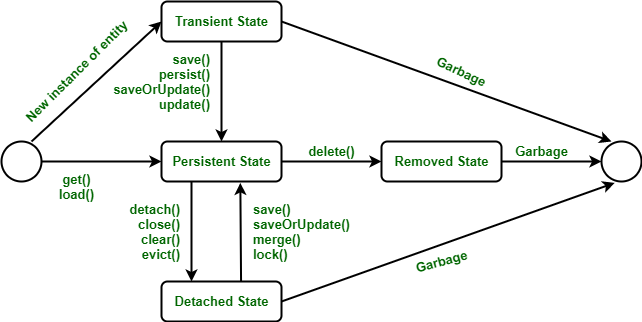
Hibernate Life Cycle
- hibernate용 객체가 만들어 지면 (맨처음 하얀 동그라미) 일단
Transient State로 간다. 그때 save()가 호출되면PERSISTENT State로 가고Detached State로 가고 다시Persistent State로 갈 수 있다.- Garbage : 종료된 상태
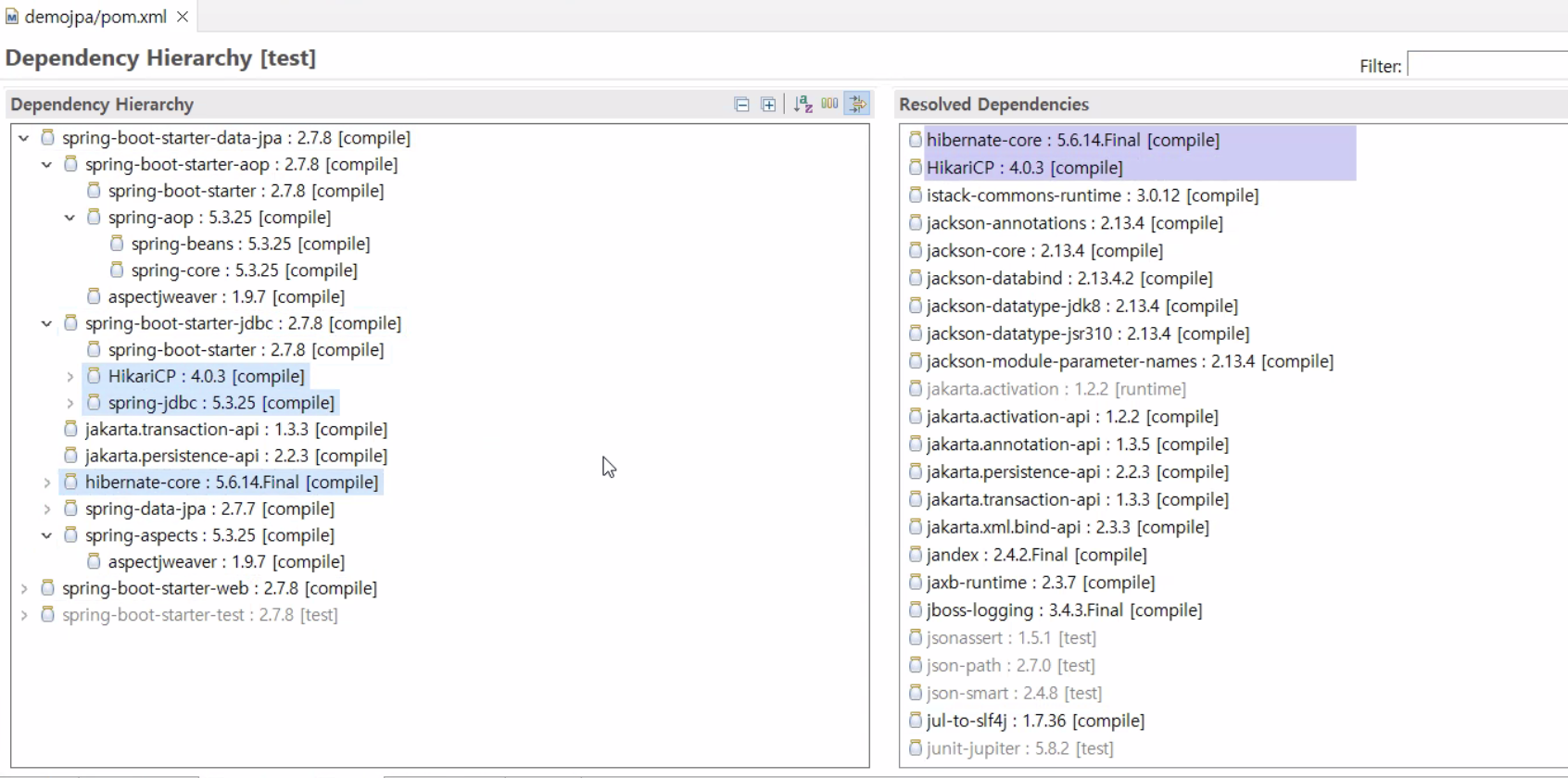
- spring boot 내부 dependency에 spring 레거시에서 새로 추가해줬던 HikariCP가 내장돼있고, spring-jdbc도 내장돼있다.
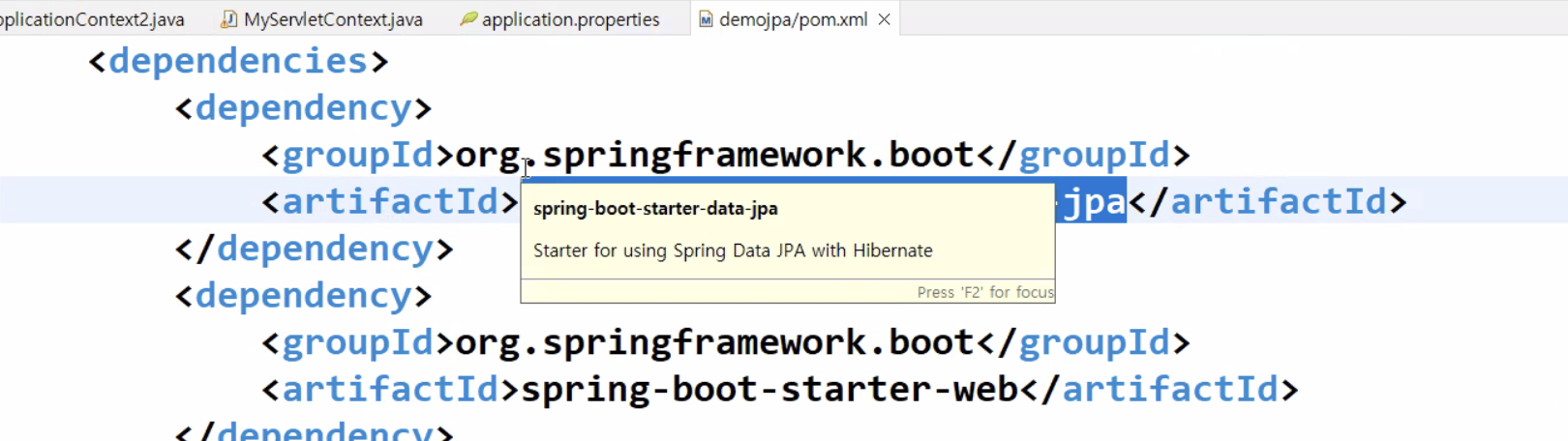
- Spring Data JPA 안에 Hibernate가 있다는 것을 확인할 수 있다.
실제 사용
// jpa에서 사용할 클래스의 역할을 주려면 CrudRepository를 상속받아야 함 public interface ARepository extends CrudRepository<A, String> { // 테이블의 한 행과 매핑을 할 때, A: A클래스가 Entity와 매핑될 객체라는 뜻. // 테이블에서의 primary key가 String 이다. }

Hibernate LifeCycle
- 1000번지의 객체가 있고, 이는 멤버변수로 값이 "one"과 1로 이뤄져있다고 하자.
이 객체가 하이버네이트의 라이프사이클(hibernate context)에 들어올 때, hibernate는 항상 db테이블과 매핑이 돼야하기 때문에(영속성) 테이블에 그 객체에 해당하는 행이 하나 자동으로 추가되도록 할 것이다.new로 객체를 만들면 hibernate에 바로 들어오는 것이 아니라, 라이프사이클 안쪽에 객체가 들어오면 그 객체와 DB테이블의 엔티티와 같은 값을 유지하도록(persistence)할 것이다.
-> 하이버네이트의 특정 기능(save)을 이용해서 life cycle로 들어오게 된다.- 1000번지 객체를 없애버리면 하이버네이트와 연결된 디비에서 영속성이 유지돼야하다보니까 그 디비의 행도 삭제된다.
-> 이 관계를 유지시키려면 그 둘을 이어주는 Repository가 필요하다.
영속성
- 그래서 영속성을 어떻게 유지할 것이냐?
➡︎ 객체가 하이버네이트 컨텍스트에 들어왔을 때 행이 추가되고, 하이버네이트에서 소멸되면 행이 삭제되고,
객체가 활동할 때 내용을 수정하면 똑같은 값을 유지해야되니까 테이블의 행도 업데이트를 시켜줌.
➡︎ Entity 클래스와 repository 클래스를 가지고 모든 작업을 할 수 있다.
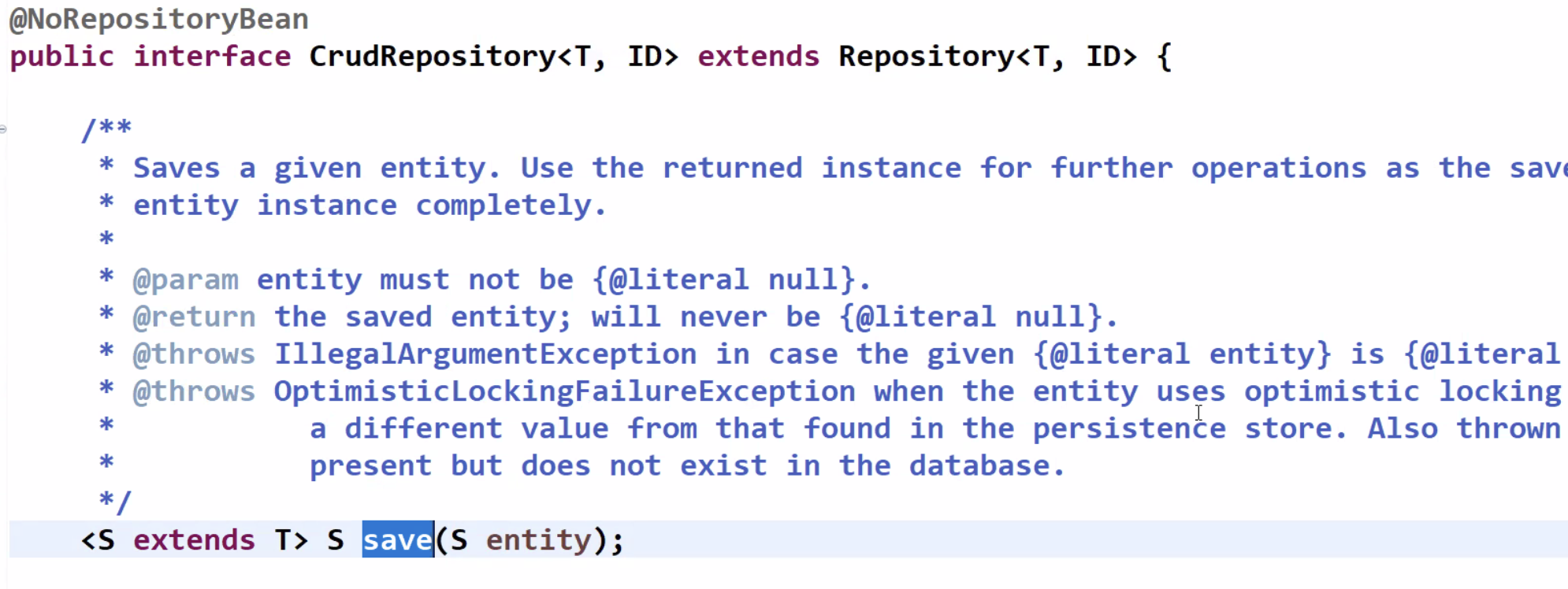
- repository는 CrudRepository<>라는 상위 인터페이스를 상속받아야 하는데, 이 인터페이스는 save() 메서드를 가진다.
- 하이버네이트 컨텍스트(라이프사이클)로 객체를 들여보내는 것이 save()의 역할이다.
save의 인자로 A클래스를 보내면 항상 퍼시스턴트를 유지하기 위해 디비에 행을 유지하게 만들어줌findById()라는 메서드를 호출하게 되면 아이디에 해당하는 객체를 찾게되는데 이는 영속성을 유지하는 애이기 때문에select구문 처리와 같은 역할을 함findAll()=select *deleteById()ordelete: hibernate 컨테이너에서 내보내는 작업
-> 연결된 영속성을 유지하기 위해서는 테이블의 행이 삭제된다.
즉, 각각의 메서드를 호출하면 save() = insert sql이 자동 호출돼서 작동하고 delete() 메서드를 호출하면 delete 되는 것임.
작동 방식
- @Entity 어노테이션은 CrudRepository<A, String> 에서 A(A.class)에 붙인다.
A a = new A();라고 객체를 만들었다고 가정하고,
a.setA_1("one");a.setA_2(1);를 한 후
repository.save(a)를 호출하면insert into A values("one", 1);이라고 sql 구문이 처리된다.- 두번째 String 은 save의 인자로 쓰이게 하는것이고, 두번째(String)가 PK에 매핑된 멤버변수가 누구인가를 알리는 것(타입을 적어준다.)
@Id로 설정한 컬럼의 자료형을 CrudRepository의 <> 두번째 인자로 넣어준다.repository.findById("one");의 메서드의 경우에는
CrudRespository에 두번째 인자로 정의해놓은 타입의 형태로 요청해야한다.
그럼 그 pk에 해당하는 "one"이라는 값에 대한 value를 찾아옴 (Key의 역할을 한다)
select * from A where a_1="one"
서비스 구조
- jpa를 하기 위해선 Vo로 하긴 어려움. DTO + Entity 클래스로 쪼개야됨.
DB테이블과의 연결된 자료를 알리는 ENTITY, 메서드의 매개변수나 리턴타입으로 쓰일 DTO클래스.
스프링 레거시 프로젝트에서는 objectMapper라는 라이브러리를 써서 Vo와 연결했다.
jpa를 사용할 때 DB테이블에 있는 정보와 dto를 섞어 쓰지말아!- 결국 하이버네이트의 라이프사이클을 공부하는 것이다.

백엔드를 공부하고 있습니다.