ORM, JPA
- ORM(ObjectRelationMapping)이란
OOP의 Object와 RDBMS의 Entity를 매핑(연결)하려는 개념이다.
java persistence api 라이브러리를 사용한다. 항상 똑같은 값을 같도록 영속성 유지함!메서드
- persist() : sql중
INSERT구문이 실행될 수 있음- remove :
DELETEsql 구문 처리
상태변경할 때 사용하는 하이버네이트 메서드
- managed -> detached : detach()
- datached -> managed : merge() ,
UPDATE- managed상태가 되면 항상 db 테이블과 값이 같은지를 찾음 -> find() 메서드
SELECT가 실행됨
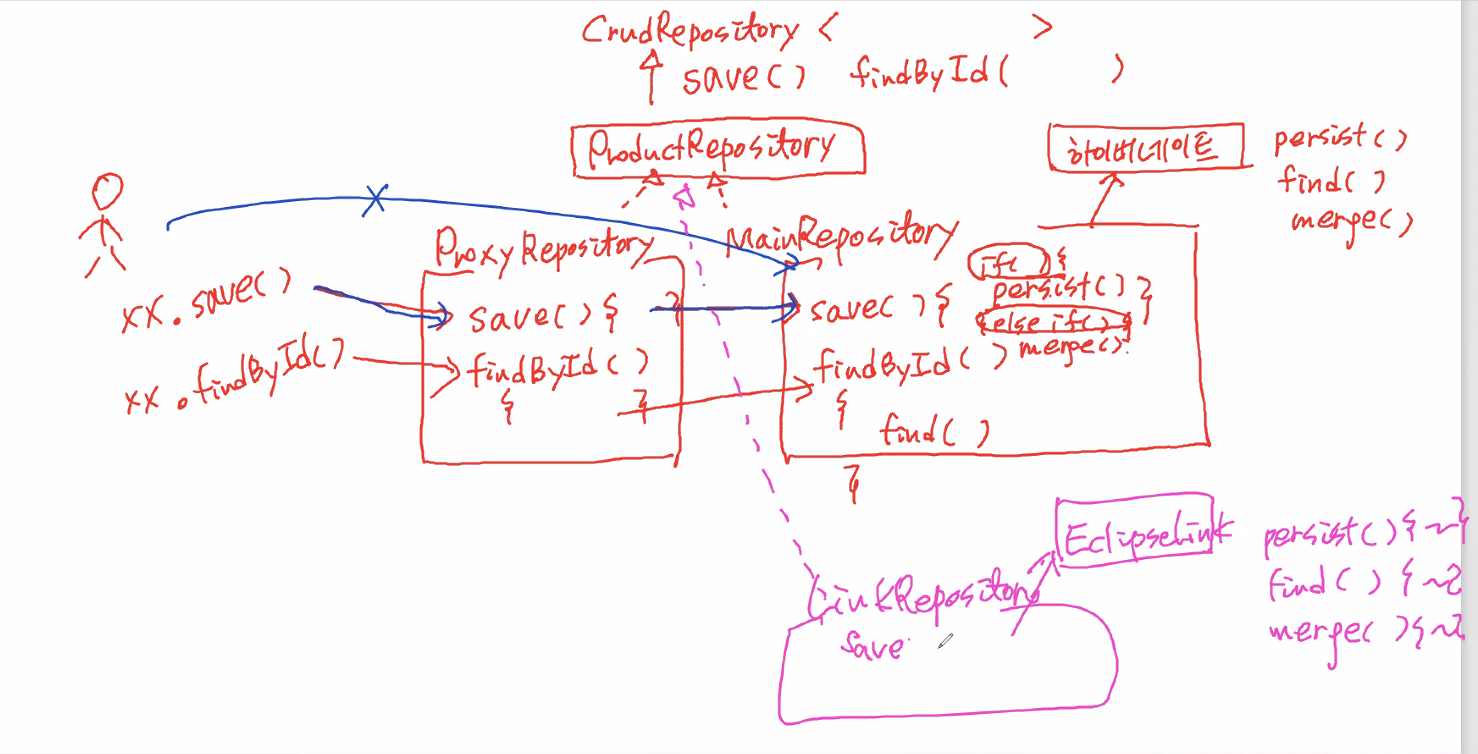
Proxy
- proxy를 기반으로 인터페이스를 구현한 하위클래스의 메서드가 만들어진다.
- proxy? 대리자 패턴
객체지향모델링 패턴중에 대리자 패턴을 사용하는 것이 대표 AOP, JPA임.
- CrudRepository라는 상위 클래스가 가지고 있는 대표 메서드중에 save(), findById()
CrudRepository를 상속받은 ProductRepository는 껍데기 인터페이스가 있다.
인터페이스는 일을 못하니까 이를 구현한 클래스 2개가 있음
(근데 여기서, 우리는 껍데기인 ProductRepository만 생성하면 되고, 밑에 두 클래스는 알아서 스프링 컨테이너가 생성해준다.)
1) MainRepository: hibernate를 상속?받은 클래스,save(),findById()를 가짐
2) ProxyRepository:save(),findById()를 오버라이딩해서 가지고 있을 것- ProxyRepository의
save()를 호출하면 MainRepository의save()를 호출하는데, 이 메서드는 하이버네이트와 의존관계를 맺어서 사용하건 상속 받건 간에(정확X) MainRepository가 하이버네이트의 메서드를 save메서드 내부에서 사용한다.
-> 하이버네이트의 어떤 조건(if)에 따라서 managed상태면persist()또는 detach상태면merge()를 호출함.
-> 마찬가지로 ProxyRepository의 findById를 호출하면 MainRepository의 findById를 호출하고 이는 내부에서 하이버네이트의 메서드를 호출함.
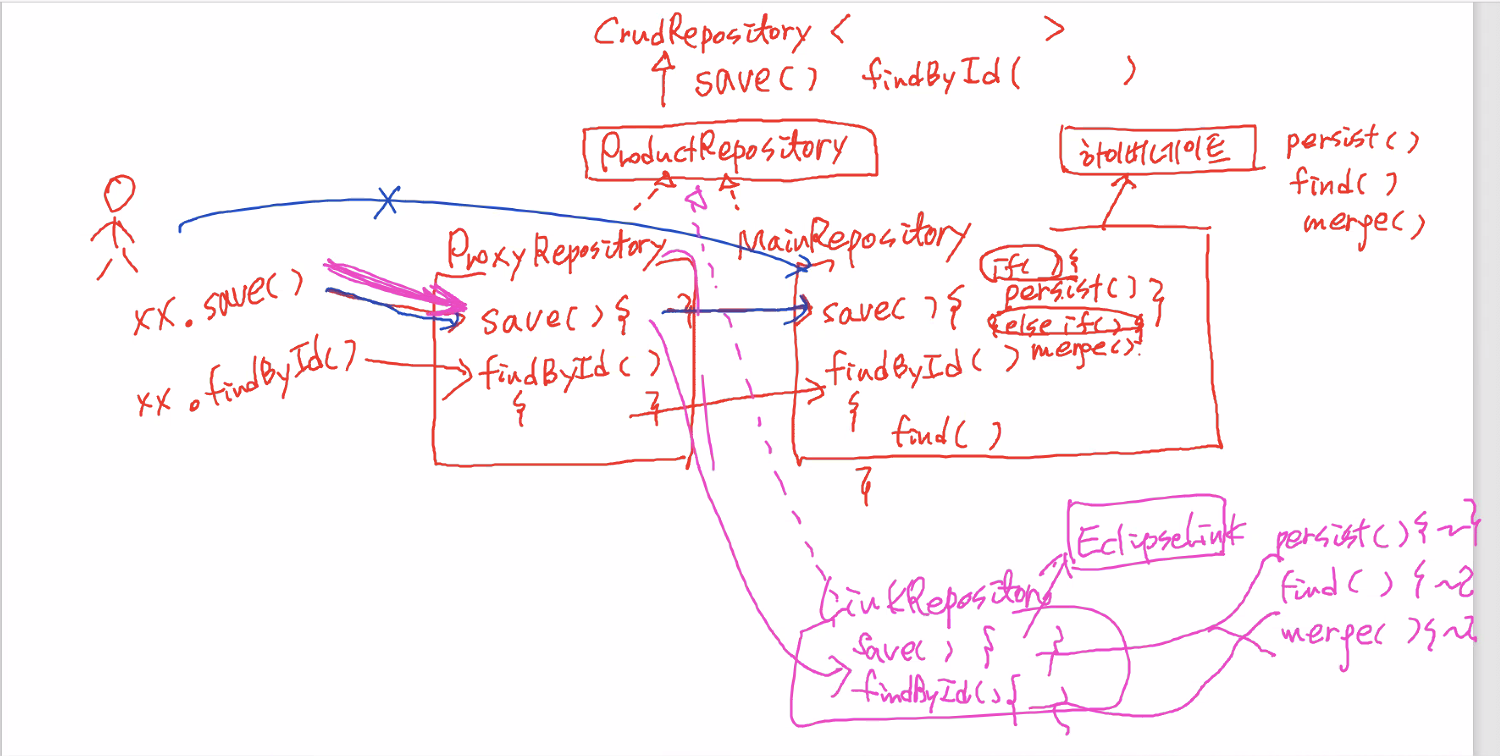
➡︎➡︎ 여기서 ProxyRepository를 대리자(Proxy)라고함.
왜 메인리파지토리를 직접사용(접근)하지않고 프록시를 한번 거쳐서 쓰느냐?
- jpa를 구현해놓은 프레임워크가 하이버네이트 말고도 있는데,
예를들어 EclipseLink도 persist, find, merge가 있는데 하이버네이트의 메서드의 내부구조와 이클립스링크의 내부구조는 다르다.- jpa가 하이버네이트를 사용할 경우에는 하이버네이트에 적절한 리파지토리가 만들어질것이고, jpa가 eclipselink를 사용한면 또 이에 적절한 repository를 만들것이다.
- 프록시는 동일하게 유지해야하기때문에 ProxyRepository는 전혀 바뀌지 않도록 구성하고, 실제 구현체는 안쪽에 가려놓는것임. 안쪽에 있는 구현체를 원하는 프레임워크로 바꿔서 처리할 수 있기 때문에 앞단에 프록시를 주는 것임 마치 인터페이스를 끼워넣은것과 같이 비슷한 구조이지만 프록시를 이용해서 사용자가 대리자만 이용할 수 있도록 하는 것임
- 사용하기 편하게 만들어놓은것이 spring용 data jpa인 것이고 우리는 인터페이스만 만들면 되고, 알아서 하위 클래스를 만들고 객체를 생성해준다. 메인 클래스만 하위클래스로 만들어주는것이 아니라 프록시도 만들어주고 실제 메인클래스는 가려놓는다.

백엔드를 공부하고 있습니다.