Persistence Context
: Entity Manager에 의해 관리된다.
- persistence context는 3구역으로 나눠진다.
- 1차 캐시 : 객체가 저장되는 영역(entity가 들어왔다 나갔다하는곳)
- SQL저장소 :
- 스냅샷영역 :
- Customer객체를 만든다. 이는 Persistence Context와 아무 관계없음. 그저 객체를 생성했을 뿐임
- Customer객체가 1차캐시 안으로 들어오려면 기본적으로
@Entity가 붙어있는 클래스여야만 들어갈 수 있음 -> 들어가면 DB와 영속성을 계속 유지할 수 있는 상태가 될 수 있음
-> 1차캐시에 들어온 상태 : managed상태.- @Entity를 붙이면 1차캐시에 들어올 수 있다는 기본사항이고, 진짜 들어오려면 jpa용 메서드가 필요한데 대표 메서드가 Hibernate의
persist()메서드임. = JPA의save()persist()가 호출되면 managed 상태가 됨 (1차캐시 안으로 들어옴).- managed되었다는 것은 영속성이 유지돼야함. 들어오면 디비에 해당하는 정보가 있는지 확인(SELECT)하고,
SELECT로 확인 후 객체와 정보를 맞춰줌.- 행이 없다면
INSERT가 실행돼서 행추가. 있다면UPDATE실행됨.
(위와 같이 db엔티티와 영속성을 유지하기 위해 sql구문이 필요함.)- db에 생성되면 managed상태가 되었다고 표현할 수 있음.
➡︎ EntityManager를 쓰기 귀찮아서 인터페이스(Repository)로 만든 것.

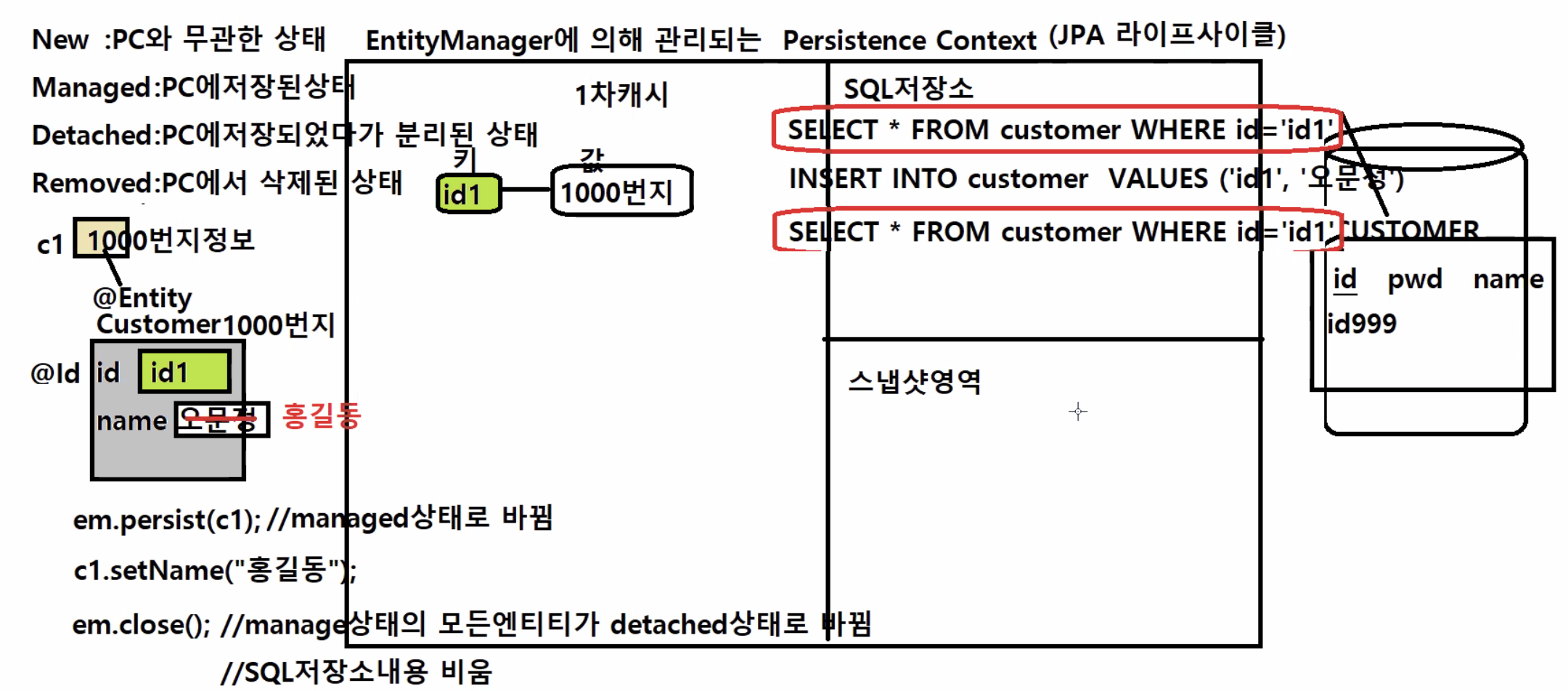
실제 예시
c1이라는 참조변수가 1000번지의 Customer의 객체를 참조하고 있을 때,em.persist(c1)을 하면 1차캐시영역으로c1이 들어감.
- 1000번지라는 정보만 가지고오면 헷갈리니까 key값
(id1, 멤버변수)을 데려옴.
key = id1,value = 1000번지정보로 이루어짐- id멤버변수에
@ID라는 어노테이션이 꼭 붙어있어야함, 그래야 1차 캐시에서key로 사용할 수 있음.
1차캐시에 들어오면SELECT * FROM customer WHERE id='id1'이라는 sql구문이 처리됨.
이 select구문을 실행해서 DB에 행 정보를 확인.
→ 컬럼들에 대한 행 정보에 id1이라는 pk가 없다면, 1차 캐시에 저장된 내용을 영속성 유지를 위해 INSERT 구문이 처리가 된다. (select후 행이 없으면 ~ insert이 실행된다. 있으면 insert 실행 안됨)
INSERT INTO customer VALUES('id1', '오문정')
➡︎➡︎ 바로 DB에 처리되는게 아니라 SQL 저장소에 쌓이게 된다.
(SELECT는 db에서 처리하고 insert는 db로 바로 송신되지 않고 쌓아놓기만 함, commit안됨)
c1: managed상태로 바뀜
c1.setName("홍길동");을 하면 1차캐시안에 들어있는 객체의 name 멤버변수의 값을 홍길동으로 바꿈.
→ 영속성을 유지하기 위해 DB에서 다시SELECT * FROM customer WHERE id='id1'로 찾고, 객체와 일치하지 않으면UPDATE구문이 실행됨.
➡︎ 근데, sql 저장소에 쌓아놓기만하고 진짜로 DB에 반영된게 아니기 때문에 SELECT했을 때 존재하는 id1이 없었기 때문에 UPDATE 구문이 만들어지지 않음..
➡︎ 객체내용만 홍길동으로 바뀌고 진짜 db에는 id1 조차 없음..... (sql저장소에INSERT INTO customer VALUES('id1', '오문정')이 저장만 돼있을 뿐임)
->em.close();또는em.clear()(refresh) 하면, managed 상태의 모든 엔티티가 detached상태로 빠져나옴. -> 객체가 삭제된 것은 아니라 detached상태에 머무르는 것 -> SQL 저장소 내용들은 모두 비움
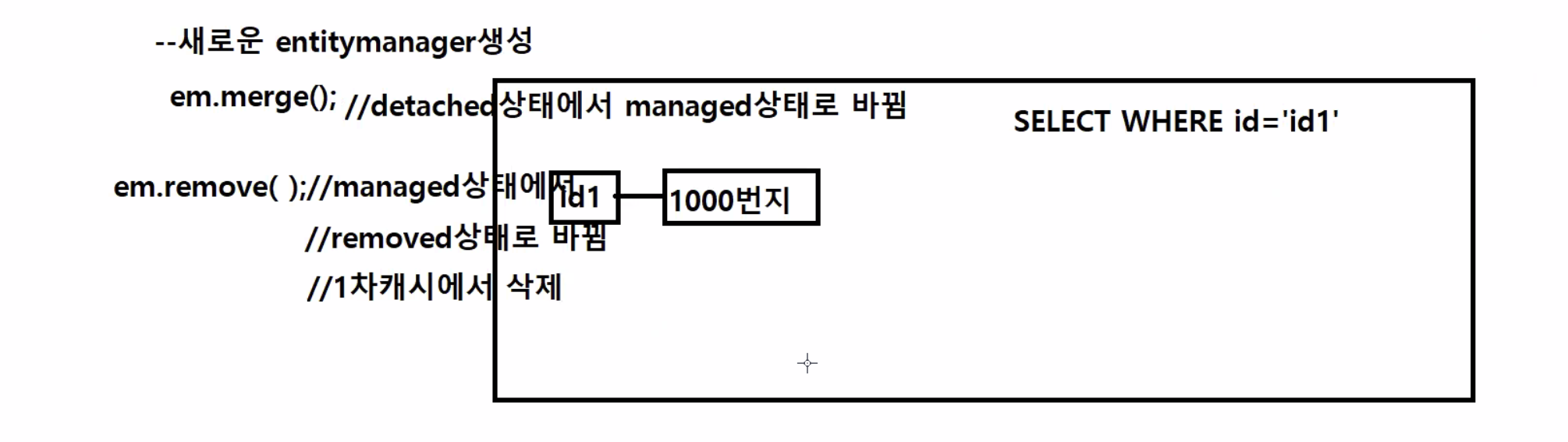
- findByID를 호출하면 1~3번 과정을 거침
- managed상태에서 객체가 만들어졌다가 findBy가 끝나면 clear()가 됨에 의해 detach 상태로 이동함
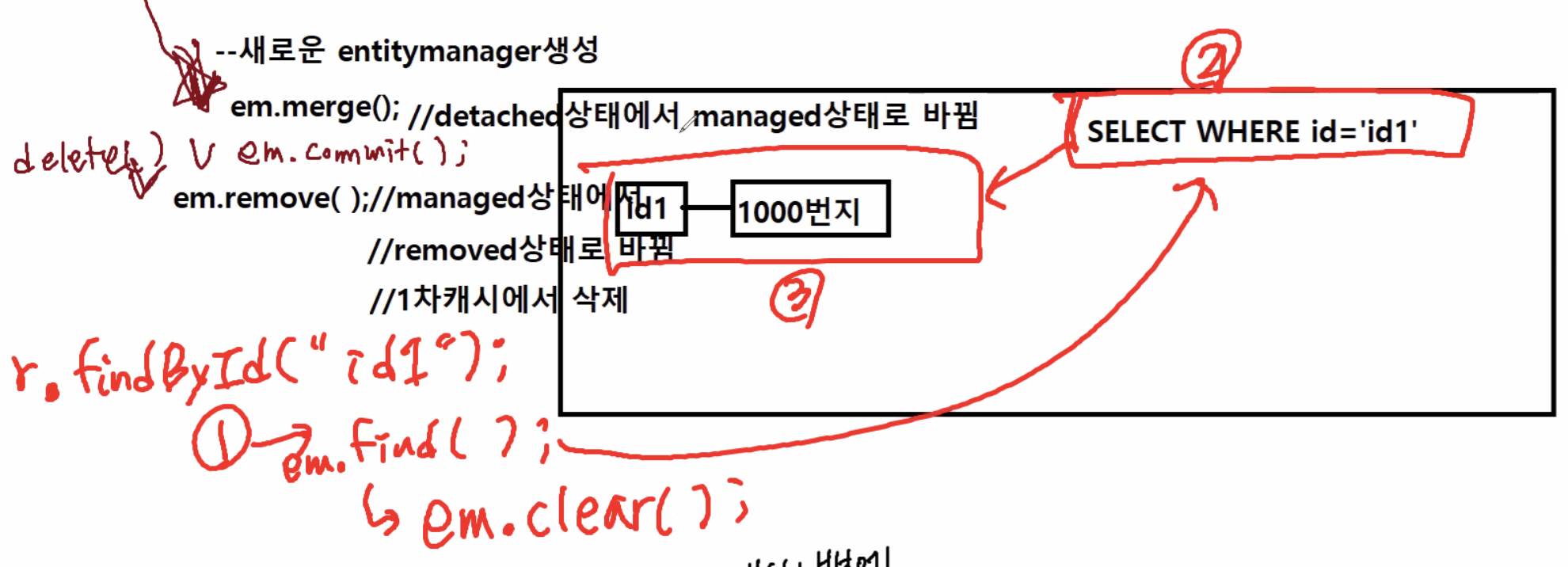
- 새로운 entityManager 생성
em.merge()메서드 호출하면 detached 상태에서 새로운 entityManager로 들어가게 됨
➡︎ managed → detached : 기존에 가지고 있던 key(id1), value(홍길동)를 가지고 있음.
→SELECT * FROM customer WHERE id='id1'구문을 다시 실행 → 그 결과가 없음.
➡︎em.remove()를 호출할 수도 있음 : managed → removed상태로 바뀜 → remove상태가 되면 1차캐시의 내용들이 사라지게 됨(SQL구문들 모두 삭제).
SnapShot
- snapshot : 사진이 한장 찍혀서 snapshot영역에 저장되는 것
→ 1차캐시의 내용이 스냅샷영역에 저장돼서 관리가 된다.
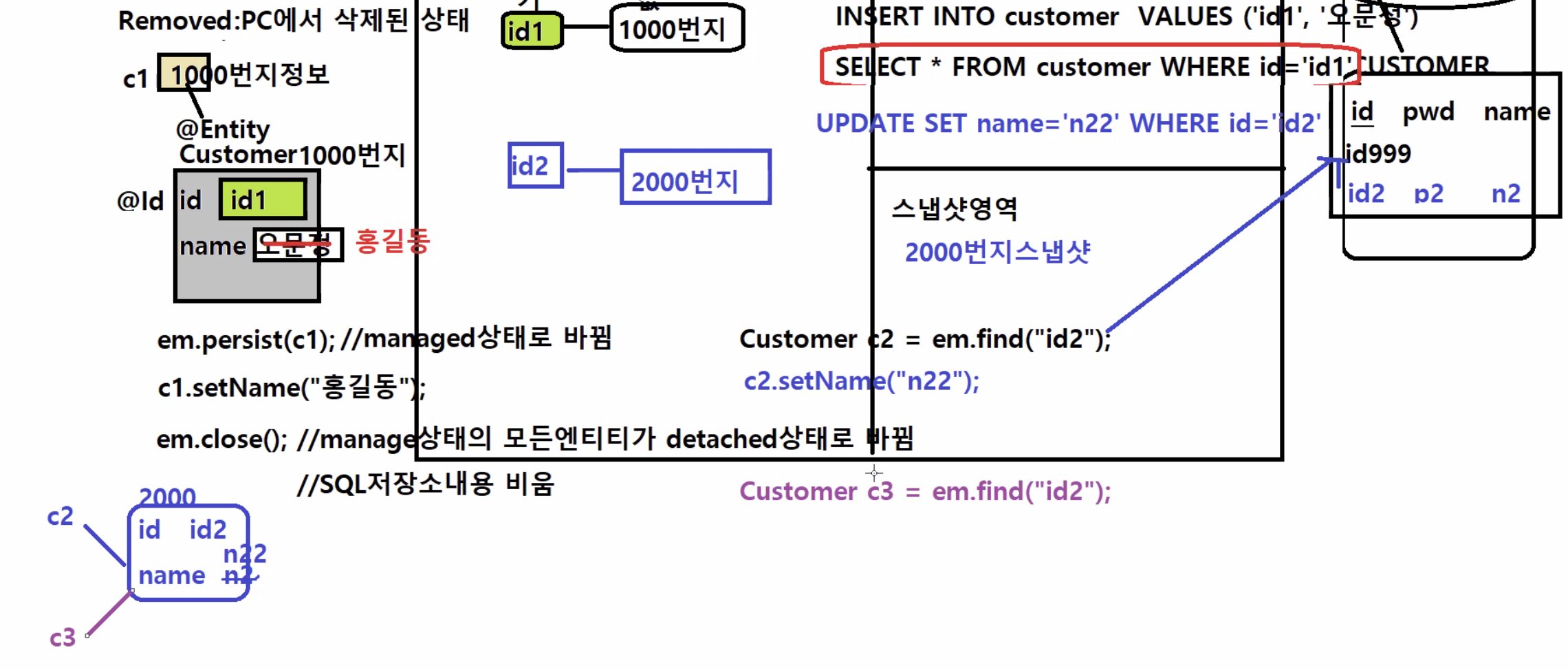
Customer c2 = em.find("id2");: id2에 해당하는 객체를 찾아서 c2에 담아줘
→ DB에 행이 있는지 부터 찾으러감. id2 행이 있다면find메서드로SELECTsql구문을 만들어서 처리함
→ Customer 객체타입으로 값을 가져옴 → 객체가 1차캐시에 자동으로 만들어짐, 2000번지로 생성 (외부에서 가져온 것이 아니라, em내부에서 찾아서 객체가 만들어진것) → 스냅샷영역에 2000번지 정보가 저장됨c2.setName("n22");→ 객체 내용 변경됨. 메모리상으로 객체를 보면 1차 캐시에서 관리되는 객체인데, set메서드를 통해 1차캐시에 있는 객체의 내용이 변경되면 똑같이 영속성 때문에 DB내용도 바꾸려고 SQL구문UPDATE SET name='n22' WHERE id='id2'를 만들어냄
Customer c3 = em.find("id2");를 하면, c3가 참조하는 객체는 같은 2000번지 메모리를 참조하게 된다.c3.setName("n3");를 하면UPDATE SET name='n3' WHERE id='id2'구문을 실행하게 되고,
실제 DB에는 전혀 반영되지 않음.(sql저장소에만 쌓여)
여기서em.close()를 하게되면 위와같이 sql저장소에 있던 구문들 다 삭제되고 모든 엔티티가detached됨.tx.commit()을 하면 sql저장소의 sql이 모두 처리
- commit전에는 영속성을 유지하기 위한 sql저장소에 저장돼있던 sql구문들이 쌓이기만 함
- 그때그때마다 항상 유지시키지 않는 이유 → 퍼포먼스가 떨어져. setter method를 호출해서 값을 바꾸는데, 이를 계속 update구문으로 계~속 바꿔주다가
close()하면 또 그 바꿨던 애들을rollback해야 되는데 이걸 복구하기가 어려움.
그래서 sql 저장소에 저장해놓고 기록을 남겨놓은 것임. 그래서 일단 저장소에 저장했다가 내가 원하는 상태에서 커밋하고, 커밋안할거면close()할 때 저장소를 삭제해버리는거임. commit안하면 롤백할 필요도 없기때문임.
→ commit을 미루는 이유는 퍼포먼스 향상문제도 있지만, 롤백되는 시점을 찾기가 어려워서 SQL저장소를 사용하는 것이다.
update/delete를 하기위해선 무조건 find부터 해야한다.
- 왜? 2000번지와 같은 객체는 1차저장소에
new키워드로 객체생성한 애가 아니라 find로 호출해서 생성해온 1차캐시에만 저장된 반환객체이기 때문에 set을 호출하면 sql저장소에 저장할 수 있음💡 sql저장소에 쌓일 기준?
: 1차캐시에 먼저 들어와야만 sql저장소에 구문 저장할수 있음!
처리할 객체가 일단 1차캐시에 있어야함. new로 객체생성해서 끝나는게아니라 find로 1차캐시에 넣어놔야해!!!!
new로 객체생성해서 update, delete하는거 아니야!
save() 메서드
- spring jpa의
save메서드를 호출하면 알아서em.persist()를 처리하거나em.merge()를 처리해줌 (둘중 하나).
save()를 호출하면 자동 merge 후 commit 작업이 이루어짐.
delete()는remove()라는 메서드가 처리. spring JPA의findById()라는 메서드가find()를 처리해줌.

백엔드를 공부하고 있습니다.