본 글은 책 <머신러닝 교과서 파이토치편, 세바스찬 라시카, 유시 (헤이든) 류, 바히드 마지리리 지음, 박해선 옮김, 길벗>, K-MOOC 강의 <모두를 위한 머신러닝, 공성근, 세종대학교, 2024-1학기>, 세종대학교 강의 <기계학습, 권순일, 세종대학교, 2024-1학기> 내용과 추가 자료를 바탕으로 재구성하였습니다.
1.2 데이터베이스의 중요성
차원이란?
[1.1 머신러닝이란?] 에서 우리는 머신러닝이 작은 개선을 반복하여 최적해를 찾아가는 수치적 방법임을 알았다. 이제 다시 아이리스 분류문제로 돌아가자. 이전 글에서 우리는 Sepal length와 Petal length를 통해 두 개의 아이리스 품종을 구분할 수 있음을 알았다. 이는 아이리스 분류에 있어서 Sepal length와 Petal length가 데이터셋의 중요한 특성(Feature)임을 의미한다.
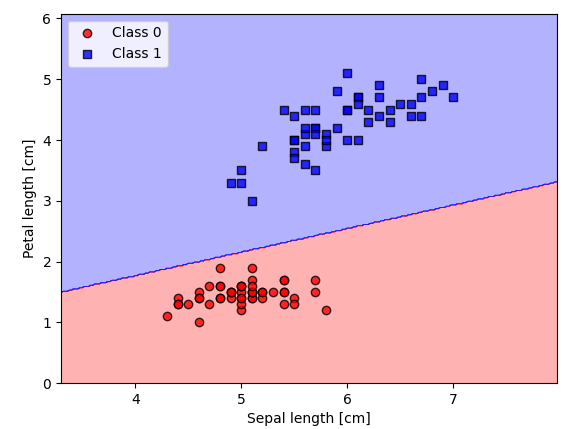
이러한 특성들의 집합을 차원(Dimension)이라고 한다. 그리고 이 차원에 따라 관측 값들이 있는 공간을 특징 공간(Feature Space)이라고 한다. 예를 들어, 위에 Sepal length와 Petal length를 사용하여 아이리스를 분류하는 데이터셋의 경우 두 개의 특성을 사용한 2차원 특징공간을 가지고있는 데이터셋이라고 할 수 있다.
이번에는 Engine power-Car price 그래프를 보자. 이 그래프도 아이리스처럼 그래프가 평면상에 그려져있다. 그러나 Engine power-Car price 데이터셋은 1차원 특징공간을 가지고있는 데이터셋이다.
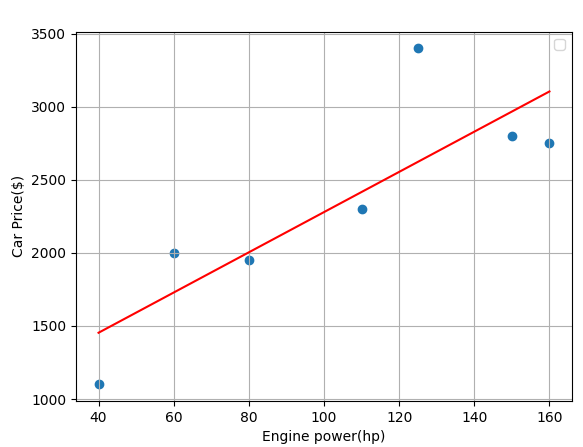
그 이유는 해당 데이터셋이 Engine power 특성 하나를 이용하여 출력 값인 Car price를 얻고자 하는 데이터셋이기 때문이다. 이처럼 데이터셋의 차원에서 중요한 것은 바로 입력값 의 특성 개수이다.
-차원 데이터
데이터의 차원은 그 데이터의 특성만큼 무한히 늘어날 수 있다. 예를 들어, 손글씨 분류를 위해 사용하는 MNIST의 경우 크기의 이미지를 사용하므로 차원의 특성 공간이 필요하다. 이는 각 픽셀 하나가 전부 특성이 되기 때문이다. 이처럼 무한히 늘어나는 차원을 우리는 벡터로 표현하고, 특징(특성) 벡터 표기는 다음과 같이 한다.
만약 -차원 데이터를 직선 모델을 사용하여 학습할 경우, 각 특성에 대해 모두 가중치가 필요하다. 이를 식으로 쓰면 다음과 같다.
이는 직선 모델을 사용하는 경우 추정해야하는 매개변수의 수가 개 임을 의미한다. 그런데 만약 직선 모델이 아닌 2차 곡선 모델을 사용할 경우 매개변수 수가 크게 증가한다. 이는 을 벡터 계산으로 하기 때문이다. 이를 수식으로 나타내면 다음과 같다.
이처럼 2차 곡선 모델을 사용할 경우 매개변수의 수는 로 크게 증가한다.
선형 분리 불가능(Linearly non-separable, XOR 문제) 문제
이번에는 직선 모델로 분류할 수 없는 경우를 보자. 아래의 두 클래스 A와 B를 나타내는 2차원 특징공간이 있을 때, 이를 완벽히 분류하는 직선 모델은 존재하지 않는다. 해당 2차원 특징 공간에서는 어느 직선을 그어도 75%의 정확률을 넘길 수 없다. 이러한 문제를 선형 분리 불가능(Linearly non-separable, XOR 문제) 문제라고 한다.
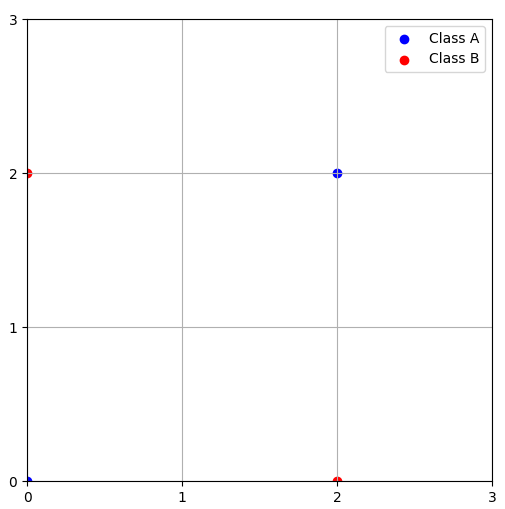
선형 분리 불가능 문제는 주어진 데이터를 선형 결정 경계로 완벽하게 분리할 수 없는 경우이다. 이는 주어진 특징 공간에서 단일 직선이나 평면으로 두 개 이상의 클래스 또는 그룹을 완벽하게 나눌 수 없는 상황을 의미한다.
선형 분리 불가능 문제가 발생하는 이유는 다음과 같다.
1. 데이터의 복잡성
데이터가 고차원이거나 복잡한 구조를 가지고 있는 경우에는 선형 결정 경계로 완벽하게 분리하기 어려울 수 있다.2. 클래스 간의 겹침
클래스들 간에 데이터 포인트가 서로 겹치는 경우에는 선형 분리가 불가능 할 수 있다.
예를 들어, 두 클래스의 데이터가 공간상에서 서로 교차하는 경우에는 선형 결정 경계로 완벽하게 분리하기 어렵다.3. 노이즈
데이터에 노이즈가 섞여 있는 경우 노이즈로 인해 클래스 간의 경계가 더 혼란스러워져 선형 결정 경계로 완벽하게 분리하기 어려울 수 있다.4. 클래스 불균형
클래스들 간의 샘플 수가 불균형하게 분포되어 있을 때에는 더 작은 클래스를 정확하게 분류하기 위해 더 복잡한 결정 경계가 필요할 수 있다.
이처럼 선형 결정 경계로 클래스를 구분할 수 없는 경우 변환된 새로운 특징공간을 도입하기도 한다.예를 들어, 원래 특징 벡터 일 때 변환된 특징벡터 을 사용한다면 특징공간은 다음과 같이 변하게 된다.
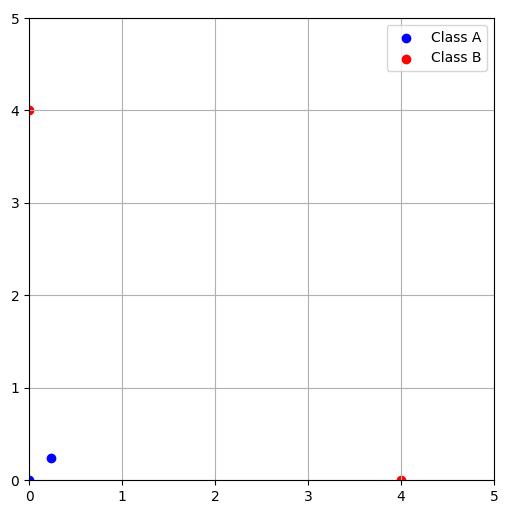
변환된 특징공간을 도입함으로서 기존에 선형 결정 경계로 클래스를 구분할 수 없던 문제를 해결할 수 있다. 그러나 이는 완벽한 해결책은 아니다.
차원의 저주(Curse of Dimensionality)
선형 분리 불가능 문제가 발생하였을 때 변환된 특징공간을 도입하면 일부의 경우 해결할 수 있다. 그러나 차원이 증가하고 복잡해질 수록 이러한 방식으로는 점점 해결하기 힘들어진다. 또한 차원이 증가함에 따라 차원의 특징공간은 매우 거대해지지만 이를 모두 채울만큼의 충분한 샘플을 확보하기 힘들어진다. 이를 차원의 저주(Curse of Dimensionality)라고 한다.
인 MNIST 샘플의 화소가 0과 1의 값을 가진다면 특징공간의 크기는 가 된다. 그러나 MNIST의 샘플은 약 6만개로 매우 희소한 분포를 띈다.
차원이 증가하면 증가할 수록 특징 공간을 채울 충분한 샘플을 확보하기 힘들어진다. 이는 데이터의 밀도가 감소함을 의미한다. 이로인해 차원의 증가는 데이터를 희소하게 만들고, 데이터 포인트 간의 관계를 파악하기 어렵게 만든다. 또한, 차원의 증가는 계산 비용이 기하급수적으로 증가하도록 만든다. 예를 들어, 거리 측정이나 군집화 알고리즘에서 모든 데이터 포인트 간의 거리를 계산하는 것은 매우 비용이 많이 든다.
마지막으로 고차원 데이터에서는 모델이 학습 데이터에 지나치게 적합되어 일반화 성능이 저하될 수 있다. 이를 과적합(Overfitting, 과대적합, 과잉적합)이라고 한다. 과적합이 발생하는 이유는 많이 있지만 고차원에서 발생하는 이유는 주로 노이즈와 낮은 데이터 밀도, 데이터 복잡성 등의 이유 때문이다.
이러한 이유로 차원이 계속해서 증가하는 것을 막기위한 방법으로 차원 축소(Dimensionality Reduction)방법을 이용한다.
차원 축소(Dimensionality Reduction)
고차원의 데이터를 이용해 머신러닝을 할 경우 차원의 저주로 인해 문제가 발생할 가능성이 있다. 이 경우 차원 축소(Dimensionality Reduction)를 통해 문제를 해결할 수 있다.
차원 축소(Dimensionality Reduction)란 매우 많은 특성으로 구성된 다차원 특징공간의 차원을 축소해 새로운 차원의 데이터 세트를 생성하는 것이다. 이를 통해 데이터의 차원을 줄이면서 데이터를 더 간결하게 표현하고, 학습 및 예측 과정에서 발생하는 복잡성을 줄일 수 있다.
차원 축소 기법에는 두 개의 주요 카테고리인 특성 선택(Feature Selection)과 특성 추출(Feature Extraction)이 있다. 특성 선택은 원본 특성에서 종속성이 강한 불필요한 특성을 제거한다. 반면 특성 추출은 기존 특성을 저차원의 중요 특성으로 압축해서 추출한다.
특성 선택(Feature Selection)
특성 선택은 특징공간 내에서 불필요하다고 판단되는 특성들을 제거하는 방법이다. 특성 선택의 예시로는 분산 기반 특성 선택과 상호정보량 기반 특성 선택 등이 있다. 분산 기반 특성 선택을 예시로 특성 선택에 대해 알아보자.
- 위 행렬에서 각 열은 데이터 포인트, 행은 특성을 의미한다. 따라서 는 5개의 데이터 포인트를 가진 3차원 특징공간이다.
위와 같은 3차원 특징공간의 데이터가 있을 때 분산 기반 특성 선택을 한다면 분산이 기준치인 0.2 이하인 특성을 제거할 수 있다.
위의 식으로 각 특성에 대해 분산을 계산하면 다음과 같다.
이와 같은 방식으로 분산이 기준치인 0.2 이하인 특성을 제거하면 최종 특성 공간은 다음과 같다.
특성 추출(Feature Extraction)
특성 추출은 고차원의 원본 특성 공간을 저차원의 새로운 특성 공간으로 압축하는 방법이다. 특성 추출은 일부 특성을 빼내는 특성 선택과는 다르게 기존 특성을 조합해 새로운 특성을 만드는 기법으로 데이터의 차원을 줄이고 중요한 정보를 보존하는데 중점을 둔다. 대표적인 특성 추출 방법으로는 주성분분석(Principal Component Analysis: PCA)과 선형판별분석법(Linear Discriminant Analysis: LDA) 등이 있다. 다음의 주성분분석(PCA) 예시를 보고 특성 추출에 대해 알아보자.
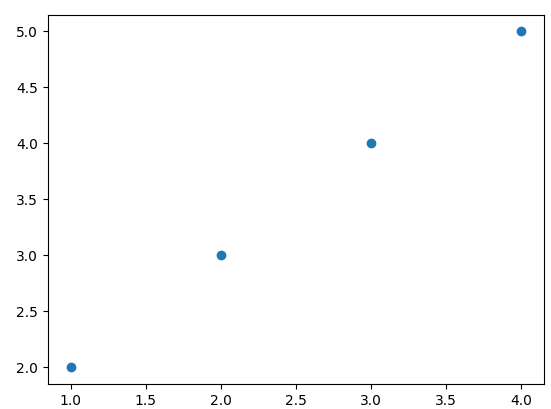
위와 같은 2차원 특징공간의 데이터가 있을 때, 이를 평면 그래프 상으로 나타내면 다음과 같다.
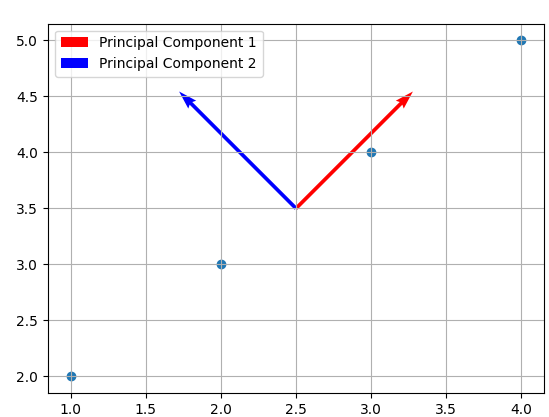
위 그래프를 보면 데이터들은 한 축을 중심으로 방향성을 띔을 알 수 있다. 이 축을 주성분 축이라고 한다. 주성분 축은 벡터로 나타내고 다음과 같이 계산할 수 있다.
여기서 는 공분산을 나타낸다. 공분산에 대한 고유값 분해(Eigen value Decomposition: EVD)를 통하여 고유값 행렬 와 고유벡터 를 구하면 다음과 같다.
고유벡터 를 구하기 위해 다음이 성립함을 이용한다.
주성분 축(고유 벡터)을 무엇을 선택하느냐에 따라 사영하는 모습이 달라지므로 최종 차원축소한 데이터의 값이 달라질 수 있다. 이제 주성분 축 을 선택하여 데이터를 사영하여 차원축소를 해보자.
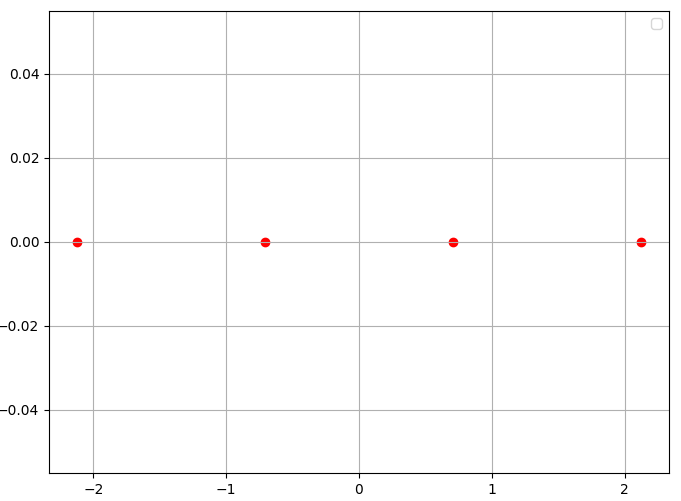
고차원 데이터에 대해 적절한 차원 축소를 수행할 경우 노이즈를 제거하여 계산 비용을 줄일 수 있고 이로 인해 모델 성능을 향상시킬 수 있다. 그러나 차원 축소를 진행함에 따라 정보 손실은 피해갈 수 없다. 또한 특성 추출을 통해 데이터를 압축하면 해석에 어려움을 겪을 수 있어 계산 복잡성이 증가할 수 있다. 때문에 고차원일 때 적절한 수준의 차원 축소를 진행해야 이러한 손실들을 최소화할 수 있다.
과소적합과 과잉적합
데이터에 대해 머신러닝을 통해 예측함수를 구하다보면 예측함수가 데이터에 대해 제대로 예측을 수행하지 못하거나 아니면 훈련 데이터에 과도하게 적합한 경우가 있다. 이를 각각 과소적합, 과잉적합이라고 한다.
과소적합
과소 적합은 모델이 너무 단순하여 데이터의 복잡한 패턴을 파악하지 못하는 경우를 말한다. 즉, 모델이 데이터의 특성을 충분히 학습하지 못하고 일반화하지 못하는 상황이다.
예를 들어, 아래 그림과 같이 2차원 특징공간을 가지는 100개의 데이터 셋이 있다고 가정해보자. 해당 데이터 셋에 대해 선형 회귀 모델을 적용하여 예측함수를 구할 경우 모델은 너무 단순해져 데이터의 복잡한 패턴을 파악하지 못할 수 있다.
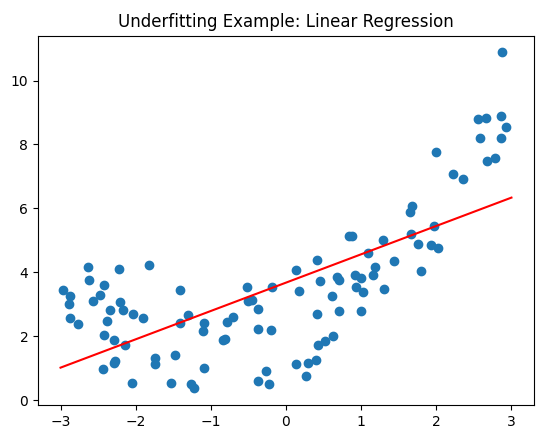
결과적으로 모델은 데이터의 실제 관계를 잘 파악하지 못하고 예측 성능이 낮을 수 있다.
과잉적합
과잉적합은 모델이 학습 데이터에 너무 맞춰져서 새로운 데이터에 대한 일반화 성능이 떨어지는 현상이다. 과잉적합이 일어나는 원인에는 모델 복잡도가 너무 높거나, 데이터 부족 혹은 노이즈, 잘못된 모델 선택, 특성 과다 등이 있다.
아래 그림은40개의 샘플데이터를 가진 2차원 특징공간 데이터셋이 있을 때, 다항 회귀 모델을 사용하여 다항식 차수(degree)를 변경하며 학습한 결과이다. 차수가 15일 때, 모델이 학습 데이터에 너무 맞춰진 것을 알 수 있다. 이는 차수의 증가, 즉 모델 복잡도의 증가가 모델의 과잉적합을 유도할 수 있다는 것을 의미한다. 또한 그래프를 보면 데이터의 노이즈가 과잉적합을 추가로 발생시킴을 알 수 있다.
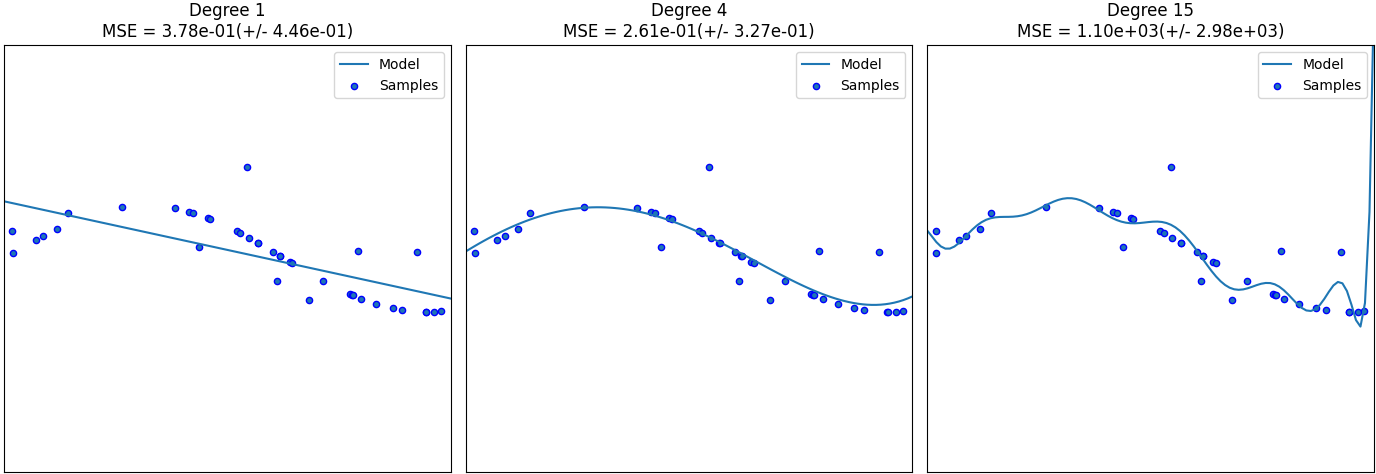
반면 차수가 1인 경우 과소적합으로인해 모델이 제대로된 예측을 수행하지 못하는 것을 알 수 있다. 그러나 차수가 4인 경우 모델은 주어진 학습 데이터에 대해 높은 일반화 능력을 보여주고 있다. 즉, 위 데이터 셋에 대해서는 차수가 4인 다항 회귀 모델이 적합한 모델임을 알 수 있다.
과잉적합의 해결방법
모델의 과잉적합을 해결하기 위해서는 모델 검증(Cross-validation, 교차 검증), 부트스트랩(boot strap), 규제(Regularization), 데이터 확대, 차원 축소, 모델 단순화 등이 있다.
모델 검증
학습된 모델이 과잉적합이 일어났는지 판단하기 위해서는 모델 검증이 필요하다. 모델을 검증하기 위해서는 훈련집합과 테스트집합과 다른 별도의 검증집합(Validation Dataset)이 필요하다.
검증집합 은 모델이 학습과정에 참조되어 과잉적합이 발생했는지를 판별하기 위해 사용되는 별도의 데이터 셋이다. 일반적으로 실제 머신러닝 개발에서는 을 별도로 구축하기보다는 에서 일부 데이터를 추출하여 구축한다.
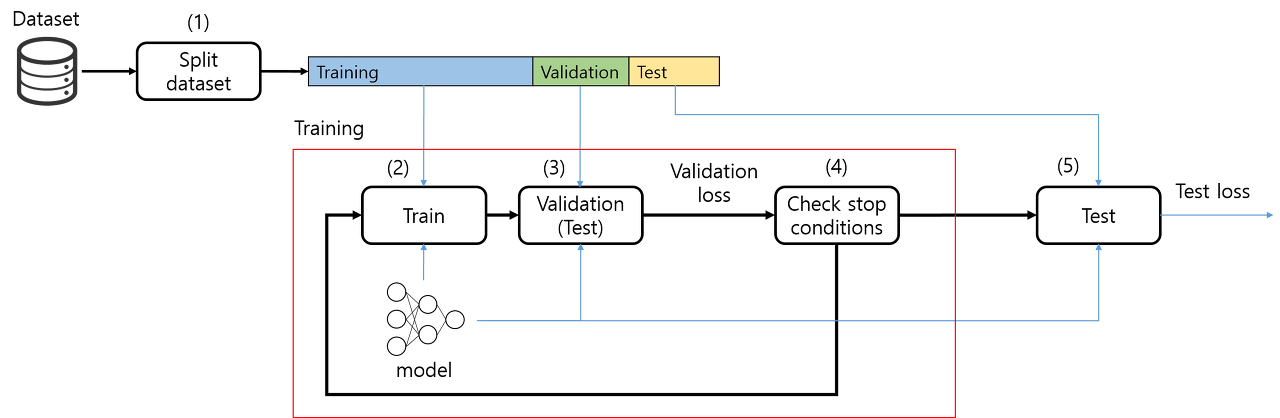
-
주어진 데이터셋을 으로 나눈다.
-
에 대한 비용함수를 최소화하도록 모델을 학습시킨다.
-
에 대한 모델의 비용함수를 계산한다.
-
만약 에 대한 비용함수가 증가했다면 학습을 종료한다. 그렇지 않을 경우에는 2 과정으로 돌아가서 학습을 계속 진행한다.
-
에 대한 비용함수를 측정함으로서 학습된 모델의 최종 성능을 평가한다.
기존의 만을 가지고 수행했던 모델 학습과는 다르게 에 대한 비용함수를 평가하는 단계를 추가함으로서 현재의 모델이 학습 과정에서 참조하지 않았던 데이터를 얼마나 정확하게 예측하는지를 평가하고, 평가 결과를 학습의 종료 조건으로 이용함으로서 과대적합을 간접적으로 방지한다.
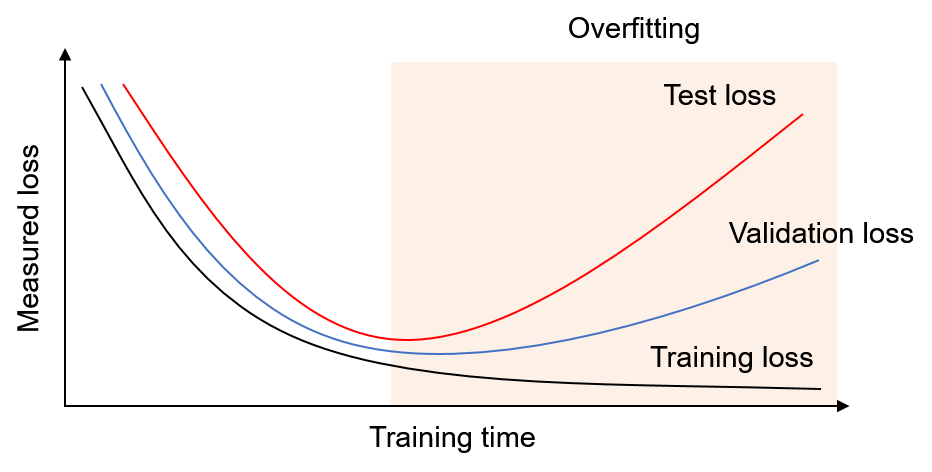

부트스트랩(boot strap)
부트스트랩(boot strap)은 검증집합이 없는 경우 사용할 수 있는 방법이다. 부트스트랩은 재표본화(Resampling) 기법 중 하나로, 표본 데이터로부터 복원추출을 통해 샘플을 반복적으로 추출하여 통계량을 계산하는 방법이다. 이 방법은 표본 데이터가 작거나 특정 분포를 가정하기 어려운 경우에 유용하게 사용된다. 부트스트랩의 수행 방법은 다음과 같다.
- 으로부터 복원추출을 사용하여 샘플을 추출한다. 이 때, 샘플의 크기는 원본 데이터 셋과 동일하게 설정한다.
- 추출한 샘플을 사용하여 통계량이나 모델을 계산한다.
- 위 과정을 여러 번 반복하여 여러 개의 부트스트랩 샘플을 생성한다.
- 생성된 부트스트랩 샘플을 사용하여 통계량이나 모델의 분포를 추정한다.
부트스트랩은 통계적 추론을 이용하여 모델의 검증하기 때문에 작은 표본 크기나 비모수적 방법을 사용해야 하는 경우에 유용하다.
규제(Regularization)
규제(Regularization)는 모델을 단순하게 하고 과잉적합의 위협을 감소시키기 위해 모델에 제약을 가하는 것을 말한다. 규제는 보통 다음과 같은 형태로 표현된다.
규제는 크게 규제항을 무엇을 선택하는지에 따라 라쏘 회귀(Lasso Regression, L1), 릿지 회귀(Ridge Regression, L2) 등이 있다.
라쏘 회귀(Lasso Regression, L1)는 가중치의 절대값을 규제항으로 사용하여 일부 가중치를 0으로 만들어 특성 선택을 수행한다. 이로써 모델이 덜 중요한 특성을 무시하고 모델을 간단하게 만든다.
릿지 회귀(Ridge Regression, L2)는 가중치의 제곱을 규제항으로 사용하여 가중치의 크기를 제한한다. 이는 가중치가 커지지 않도록 하여 모델의 복잡도를 줄이고 일반화 성능을 향상시킨다.
아래 그래프는 차수가 15인 모델에 대해 각각 규제를 적용한 모델 그래프이다. 규제를 하지 않았을 때 보다 과잉적합이 완화되었음을 알 수 있다.
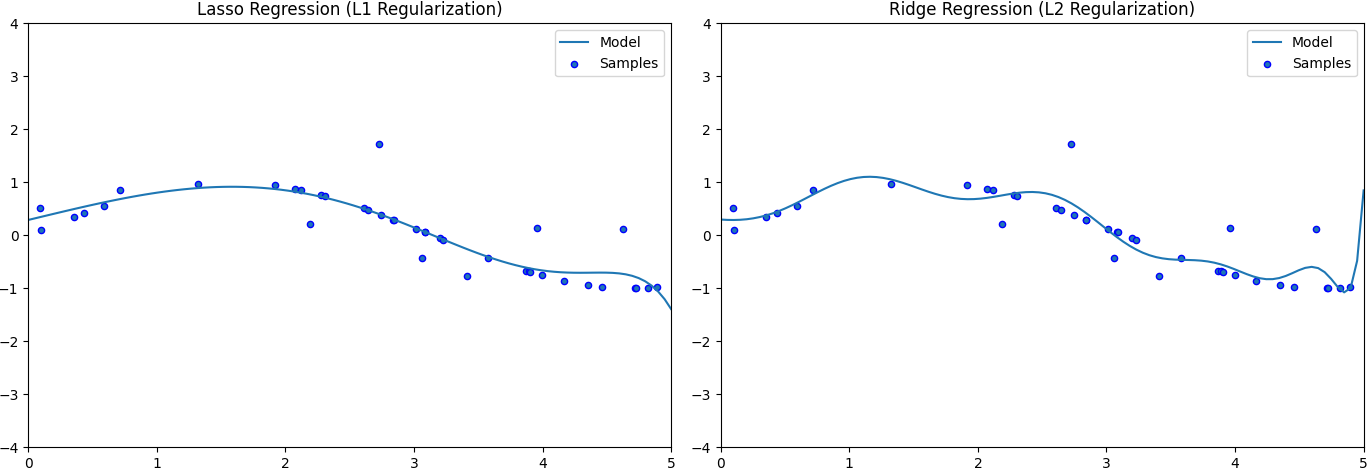
그 외 방법
데이터셋을 기존 데이터셋보다 더 확대함으로서 과잉적합을 해결할 수 있다. 그러나 이는 그라운드 트루스를 사람이 일일이 레이블링해야하기 때문에 많은 비용이 발생한다. 또한 인위적으로 데이터를 확대했기 때문에 더 많은 노이즈가 발생할 수도 있다.
모델 단순화는 기존 모델의 복잡도를 낮춰 완화된 모델을 사용함을 말한다. 아래 그림과 같이 차수가 15인 다항 회귀 모델이 아닌 차수가 4인 다항 회귀 모델을 사용함으로서 과잉적합을 해결할 수 있다.
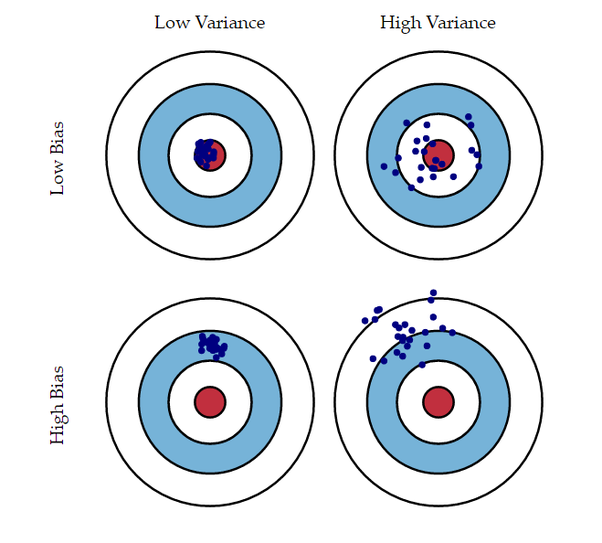
바이어스(bias)와 분산(Variance)
바이어스(bias, 편향)
바이어스(bias)는 추정 결과가 한 쪽으로 치우치는 경향을 보임으로써 발생하는 오차를 말한다. 이는 모델이 예측한 결과가 실제 값과 일정하게 차이가 나는 정도를 의미한다. 모델의 바이어스가 높으면 예측이 실제 값에서 멀어지는 경향이 있다. 고편향된 모델은 단순하고 너무 제한적인 구조를 가지고 있어 데이터의 복잡한 패턴을 잡아내기 어려울 수 있다.
분산(Variance)
분산(Variance)는 데이터들이 퍼져있는 정도를 말한다. 이는 주어진 데이터 포인트에 대한 모델 예측의 가변성을 의미한다. 고분산 모델은 데이터에 더 적합하지만 새로운 데이터에 대한 일반화가 어려울 수 있다. 이는 모델이 학습 데이터에 너무 맞춰져 새로운 데이터에 대해 취약해지는 과잉적합 문제를 발생시킬 수 있다.
바이어스와 분산의 관계
일반적으로 용량이 작은 모델은 바이어스는 크고 분산은 작다. 반면 복잡한 모델은 바이어스는 작고 분산은 크다. 즉, 이 둘은 트레이드오프 관계이다. 따라서 바이어스의 희생을 최소로 유지하며 분산을 최대로 낮추는 전략이 필요하다.
데이터 전처리란?
주어진 원본 데이터를 이용하여 모델을 학습하였을 때, 모델이 최적의 성능을 내기에 적합한 경우는 매우 드물다. 때문에 원본 데이터에 대하여 데이터 전처리를 수행하여 모델이 최적의 성능을 내도록 유도한다.
데이터 전처리에는 노이즈 제거, 특성 스케일링, 범주형 데이터 인코딩, 차원 축소, 데이터 분할 등 여러 방법이 있다. 여기서는 정규화(Nomalization)와 표준화(Standardization)에 대해 간단히 알아보자.
정규화(Nomalization)
정규화(Nomalization)은 데이터 전처리 과정에서 데이터 값의 범위(scale)을 [0, 1] 또는 [1, -1] 사이의 값으로 바꿔주는 방법이다. 이는 데이터의 범위의 차이를 왜곡하지 않고 공통 척도록 변경하는 것이다.
Min-Max Scaling
Min-Max Scaling은 정규화의 한 방법으로 모든 특징이 정확하게 [0, 1] 사이에 위치하도록 데이터를 변경한다.
표준화(Standardization)
표준화(Standardization)는 데이터 전처리 과정에서 데이터의 값의 범위(scale)을 평균 0이고 단위 분산을 가진 표준 정규 분포(Standard Normal Distribution)으로 변환하는 방법이다.
Z-Score Standardization
Z-score Standardization은 표준화의 한 방법으로 데이터를 표준 정규 분포로 변환한다.
이때, 는 데이터 의 평균, 는 표준편차를 의미한다.
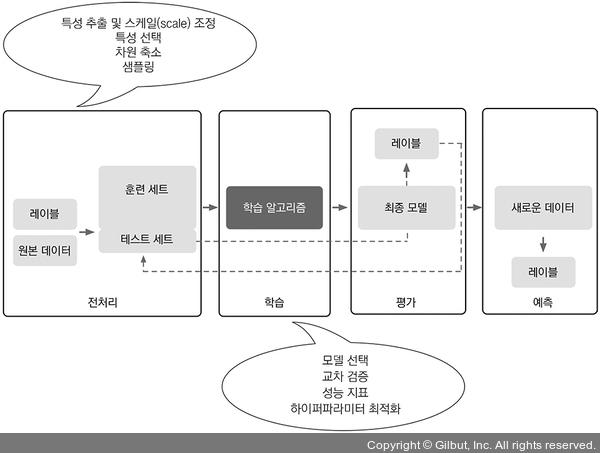
머신 러닝 시스템 구축 로드맵
참고자료
- 머신러닝 교과서 파이토치편, 세바스찬 라시카, 유시(헤이든) 류, 바히드 미자리리 지음, 박해선 옮김, 길벗, 2023
- K-MOOC 강의, 모두를 위한 머신러닝, 공성근, 세종대학교, 2024-1학기
- 세종대학교 강의, 기계학습, 권순일, 세종대학교, 2024-1학기
- 차원(Dimension), 한 페이지 머신러닝, Woneui Hong, 2018.08.12, 2024.03.20
- 06-02 퍼셉트론(Perceptron), PyTorch로 시작하는 딥 러닝 입문, 유원준, 안상준 지음, 위키독스, 2023.10.06, 2024.03.20
- 차원의 저주 개념, 발생 원인과 해결 방법, 퇴근 후 study with me, palette, 2021.08.01, 2024.03.21
- 차원 축소(Dimension Reduction)-PCA, LDA, Feel's blog, jeongpil, 2021.07.14, 2024.03.21
- 특성 선택, 생각정리, Now Hyun, 2023.03.09, 2024.03.22
- 주성분분석(Principal Component Analysis), ratsgo's blog, 2017.04.24, 2024.03.23
- <선형 변환, 위키백과, 2024.03.08, 2024.03.23>
- 공분산, 위키백과, 2023.07.19, 2024.03.23
- 고유값 분해, 위키백과, 2022.06.19, 2024.03.23
- 고유값 행렬, 위키백과, 2022.04.19, 2024.03.23
- 고윳값과 고유 벡터, 위키백과, 2022.08.13, 2024.03.23
- [머신러닝]과적합(Overfitting)과 Validation Dataset의 개념, Untitled Blog, CHML, 2019.12.25, 2024.03.24
- [머신러닝-이론] Regularization(규제), 안녕, 바보1, 2022.10.18, 2024.03.24
- [Machine Learning] 정규화(Normalization) vs 표준화(Standardization), Koo's Devlog, Sungwoo Koo, 2022.05.14, 2024.03.24
- 이미지 [머신 러닝 시스템 구축 로드맵]
필자는 기계학습을 공부하는 학부생일뿐이므로 잘못된 정보가 있을 수 있습니다. 본 글에 잘못된 정보, 추가 정보, 오타 등이 있으면 댓글로 달아주세요.
