본 글은 책 <머신러닝 교과서 파이토치편, 세바스찬 라시카, 유시 (헤이든) 류, 바히드 마지리리 지음, 박해선 옮김, 길벗>, K-MOOC 강의 <모두를 위한 머신러닝, 공성근, 세종대학교, 2024-1학기>, 세종대학교 강의 <기계학습, 권순일, 세종대학교, 2024-1학기> 내용과 추가 자료를 바탕으로 재구성하였습니다.
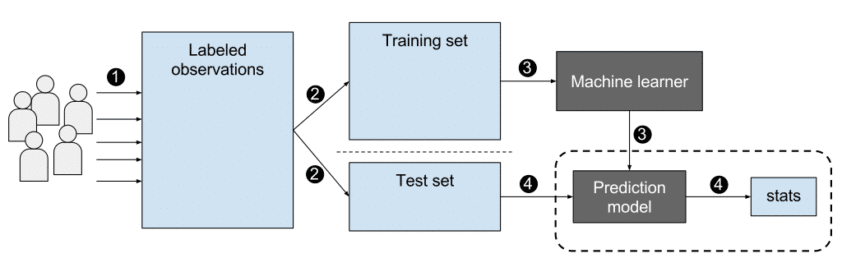
지도학습의 주요 목적은 레이블(label)된 훈련 데이터에서 모델을 학습하여 본 적 없는 미래 데이터에 대해 예측을 만드는 것이다. 때문에 지도학습은 정확한 입력-출력 쌍이 필요하며, 학습된 모델은 이러한 쌍을 기반으로 새로운 입력에 대한 출력을 예측한다. 이러한 특징 때문에 지도학습은 데이터에 매우 의존적이다.
분류(Classfication)
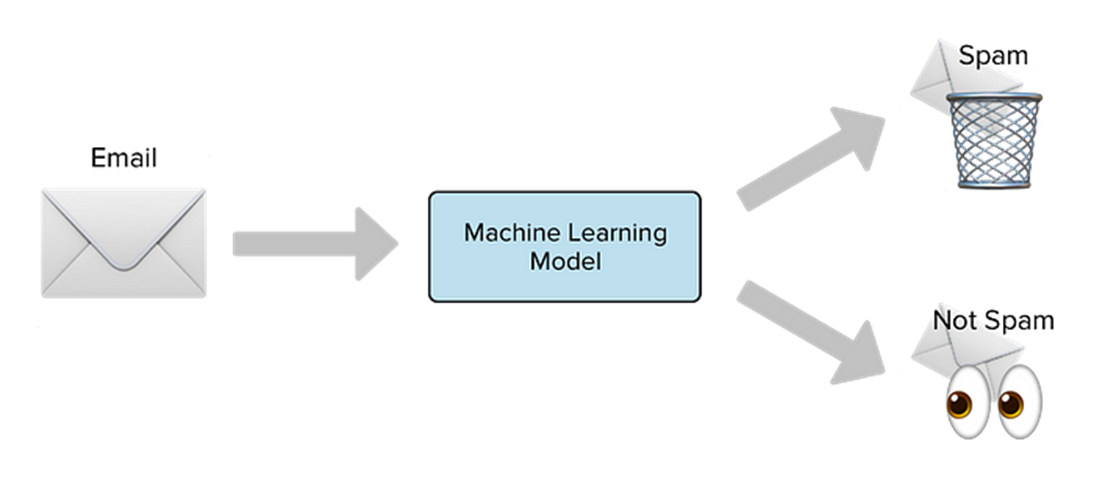
분류(Classfication)는 지도 학습의 하위 카테고리로, 과거의 관측을 기반으로 입력 데이터를 미리 정의된 여러 개의 범주 또는 클래스 중 하나로 분류하는 문제이다. 예를 들어 스팸 메일을 필터링 하기 위해 입력 데이터로 메일의 내용을 넣으면 그 출력(분류 클래스)으로 <스팸 or 스팸 아님>으로 나온다. 이를 이진 분류(binary classfication) 문제라고 한다.
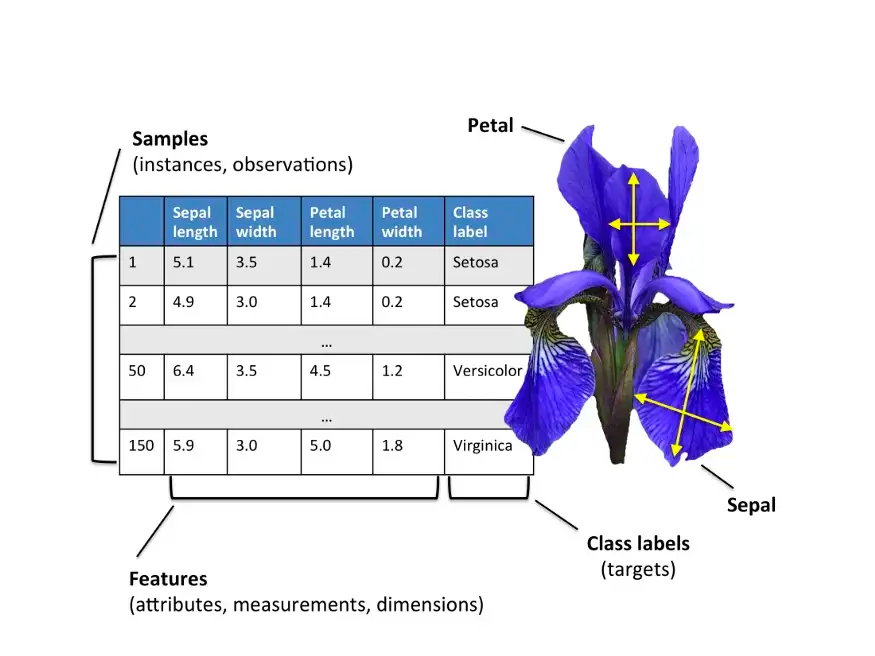
그러나 현실에서는 두 개 이상의 클래스 레이블을 가진 경우가 더 많다. 예를 들어 Iris 분류 문제의 경우 X={Sepallength,Sepalwidth,Petallength,Petalwidth}를 입력으로 받아 Y={Setosa,Versicolor,Virginica}로 나눈다. 이처럼 두 개 이상의 클래스 레이블로 나누는 문제를 다중 분류(multiclass classfication) 문제라고 한다.
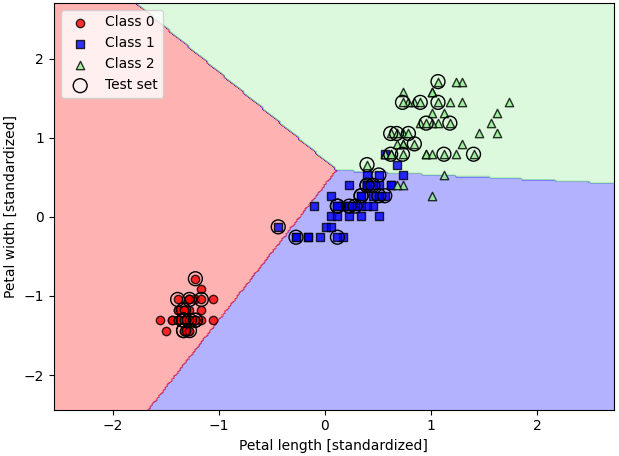
분류 모델은 데이터들을 결정 경계(decision boundary)를 이용해 분류한다. 다음과 같이 Petal length와 Petal width를 이용해 Iris class를 분류하는 모델이 있을 때, 해당 데이터들을 2차원 그래프에 두었을 때 이들 클래스를 분류하는 선을 볼 수 있다. 이 선을 결정 경계(decision boundary)라고 하며, 분류 모델은 해당 결정 경계를 학습한다.
예시
분류 모델을 확률론 관점에서 본다면 결합 확률 문제(Join probability distribution)로 볼 수 있다.
결합 분포란 확률 변수가 여러 개 일때, 이들을 함께 고려하는 확률 분포이다. 예를 들어, 주사위를 던졌을 때, A는 주사위 눈금 수가 짝수일 경우 1, 아닐 경우 0이라고 하고, B는 주사위 눈금 수가 2,3,5가 나올 때 1, 아닐 경우 0이라고 하면 이를 표로 작성하면 다음과 같다.
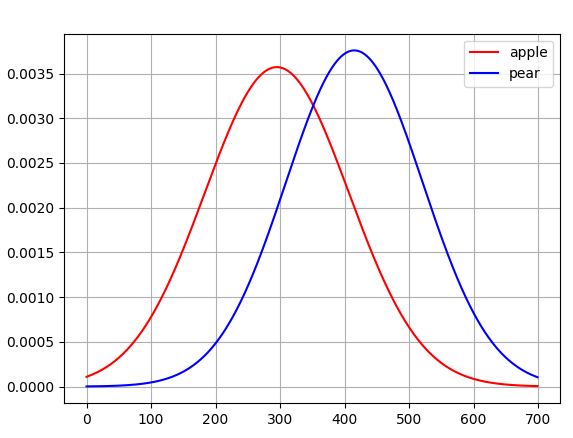
위 그래프를 봤을 때, 무게가 350g일 때 사과와 배를 구분할 수 있는 결정경계임을 알 수 있다.
여기까지 2.1 베이즈 분류기로 이동.
회귀
회귀(Regression)는 지도 학습의 한 종류로, 연속적인 출력 값을 예측한다. 회귀는 예측 변수(predictor variable, explanatory variable: 설명 변수, input: 입력)와 연속적인 반응 변수(response variable, outcome: 출력, target: 타깃)가 주어졌을 때 출력 값을 예측하는 두 변수 사이의 관계를 찾는다.
대표적인 예시로 이전에 예기했던 Engine power(hp)와 Car price($)를 보자. 여기서 Engine power는 예측 변수로 반응 변수인 Car price를 예측하기 위해 사용되는 값이다. 예측 변수와 반응 변수사이의 관계를 학습하는 것이 회귀분석이고 선형회귀를 통해 이를 알아보자.
Engine power-Car price의 선형 회귀 모델은 앞선 1.1 머신러닝이란? 에서 간략하게 소개했다. 해당 내용을 참고하자.
선형 회귀(Linear Regression)는 입력 x와 타깃 y가 주어지면 이들의 관계를 파악하는 예측함수 h(x)를 찾는다. 일반적으로 선형 회귀에서 예측함수의 식은 다음과 같다.
h(x)=wx+b
예측함수가 학습 데이터에 근접하기 위해서는 목적함수(Object function, Cost function: 비용함수)가 최소로 가도록 해야한다. 이때, 목적함수를 평균 제곱 오차(Mean Squared Error: MSE)로 정의하면 목적함수의 식은 다음과 같다.
J(θ)=n1i=1∑n(y^−y)2
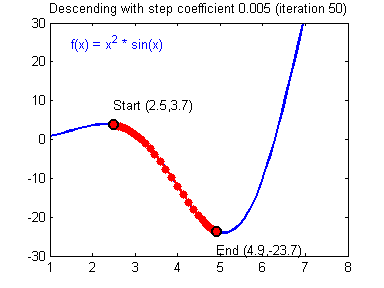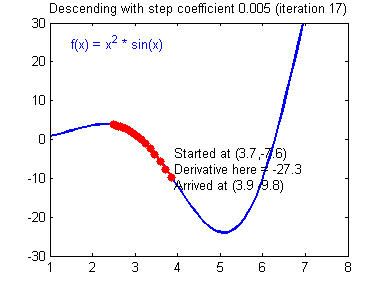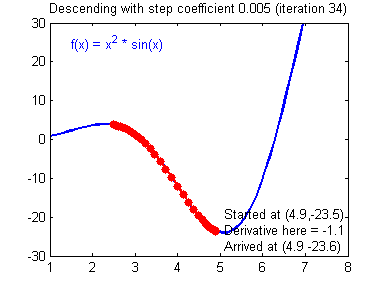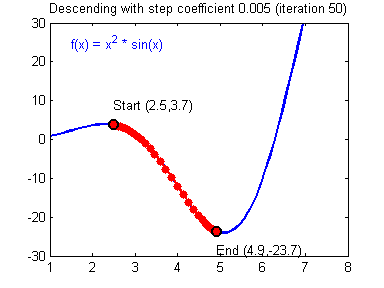
회귀 분석을 통해 우리가 원하는 것은 최종적으로 목적함수의 값이 최소가 되도록 하는 것이다. 이를 위해 우리는 경사 하강법(Gradiend Descent)을 사용할 수 있다.
경사 하강법(Gradient Descent)
경사 하강법(Gradiend Descent)은 최적화 알고리즘으로, 목적 함수의 기울기(Gradient: 경사)를 구하여 경사의 반대 방향으로 계속 이동시켜 극값에 이를 때 까지 반복하는 알고리즘이다.
앞서 우리는 평균제곱오차(Mean Squared Error: MSE) 함수를 목적함수로 사용하였다. 따라서 MSE에 대해 미분을 하여 기울기를 구한 후, 경사의 반대 방향으로 이동시켜 MSE의 극값으로 수렴하도록 하여 목적함수가 최적해로 수렴하도록 할 수 있다. 평균제곱오차(MSE)에 대하여 경사하강법을 적용하는 수식을 나타내면 다음과 같다. 여기서 η는 학습 상수이다.
wiΔwi:=wi+Δwi=−η∇J(wi)
최적해 비보장
경사 하강법은 목적 함수가 전역 최솟값(Global Minimum, 최적해)으로 도달하는 것을 보장하지 않는다. 이는 경사 하강법의 초기 시작점, 기울기 값 등에 의해 발생하는 현상으로 다음의 경우 경사 하강법은 최적해를 보장하지 않는다.
지역 최솟값(Local Minimum, 지역 최적해)에 수렴하는 경우
평평한 지역 또는 평원에 갇힌 경우
학습률이 너무 작거나 큰 경우
예시
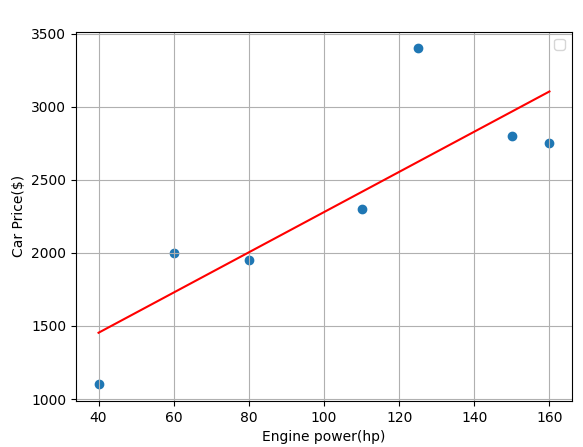
아래와 같이 Engine power에 따른 Car price 데이터가 있을 때, 단순 선형회귀(Simple Linear Regression)를 이용해 Car price를 예측하는 모델을 만들어 보자.
1
2
3
4
5
6
7
Engine power
40
60
80
110
125
150
160
Car price
1100
2000
1950
2300
3400
2800
2750
우리가 구하고자 하는 예측함수 h(x)는 다음과 같이 정의된다.
h(x)=wx+b
그리고 예측함수 h(x)를 최적화하기 위해 우리는 목적함수를 최소화 해야한다. 이때, 목적함수를 평균 제곱 오차(Mean Squred Error: MSE)를 사용하여 다음과 같이 정의한다.
J(θ)=2m1i=1∑m(h(xi)−y)2
목적함수를 최적화 하기 위해 우리는 경사하강법을 사용할 수 있다. 목적함수 J(θ)를 w와 b에 대해 편미분 하면 다음과 같다. θ=(w,b) 이다.