ex_3sklearn
데이터 갯수가 균등해지게 나눠줌 함수:stratify
2진분류 =선형회귀 여러개 하면 다중분류
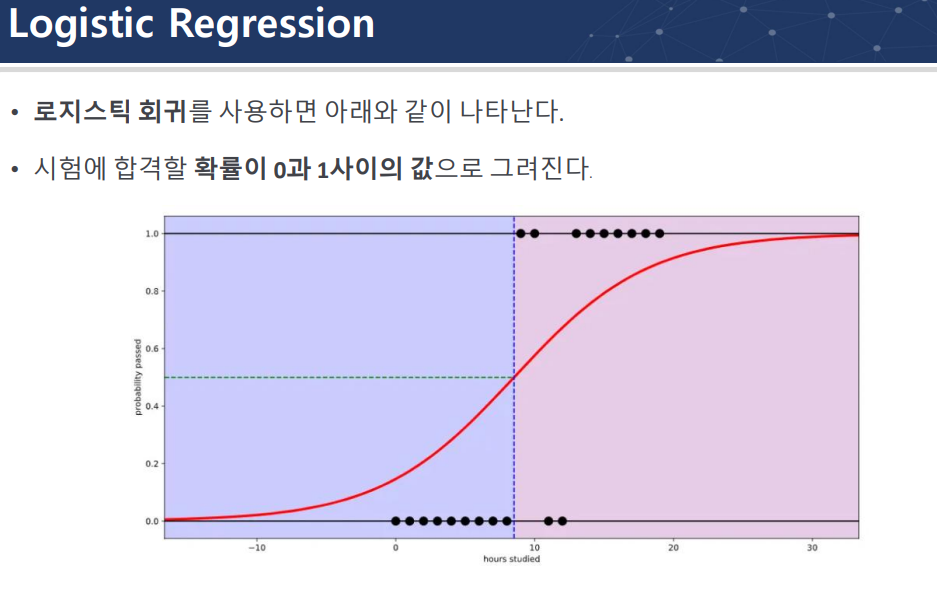
선형회귀에 log취해서 logistic regression은 분류
경사하강법 GD: 전체데이터를 다 쓰는것
SGD : 확률론적 경사하강법
Batch size: 이상치가 많을때 늘려서 사용
epoch: 한번 모델을 돌릴때 1에폭


CPU갯수 확인하기 https://itholic.github.io/python-cpu-count/
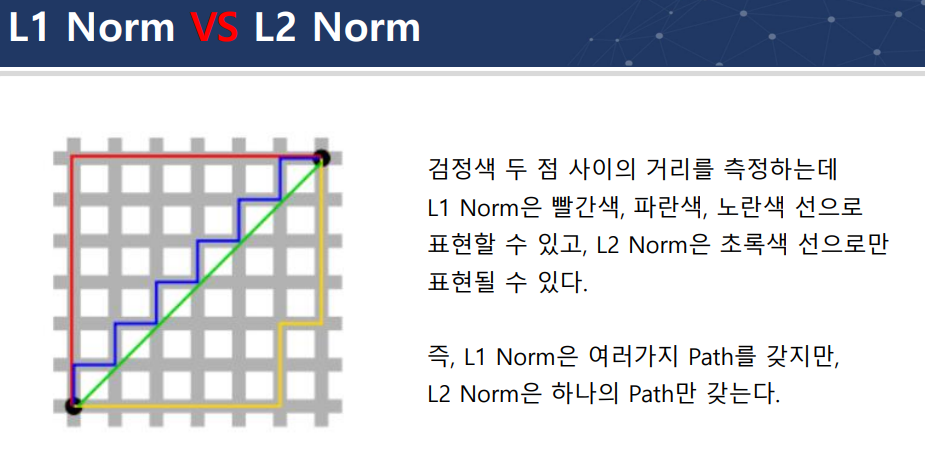
L1 규제
L1 norm


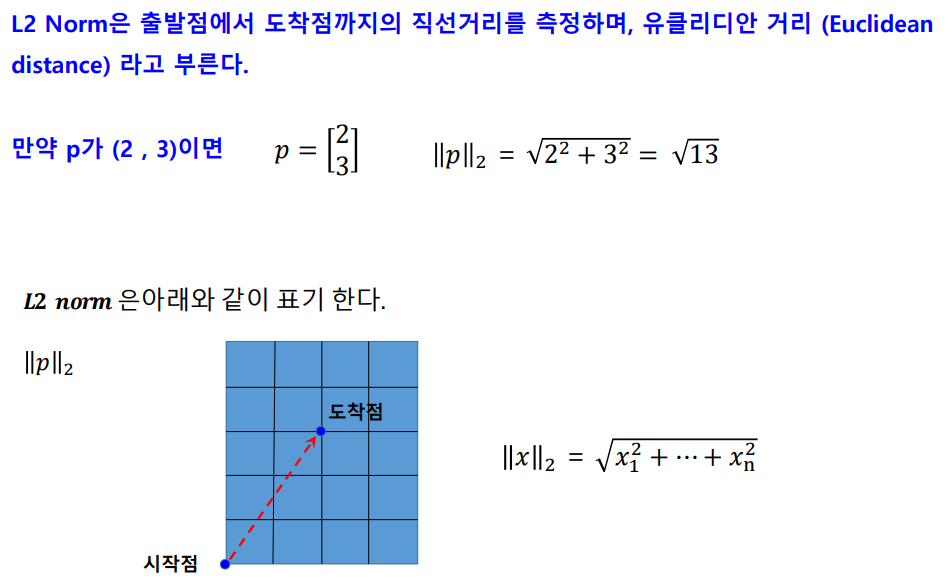
L2 norm(피타고라스) 유클리디안 distance
L1 VS L2
l2 shortcut
loss
L1 = MAE
L2 = MSE
MSE에 루트 씌우면 전체적인 크기가 작아짐. 둘다 regression 문제 풀때 이용
RMSE도 있음

L1 loss L2 loss 사용기준 (이상치에 따라서)

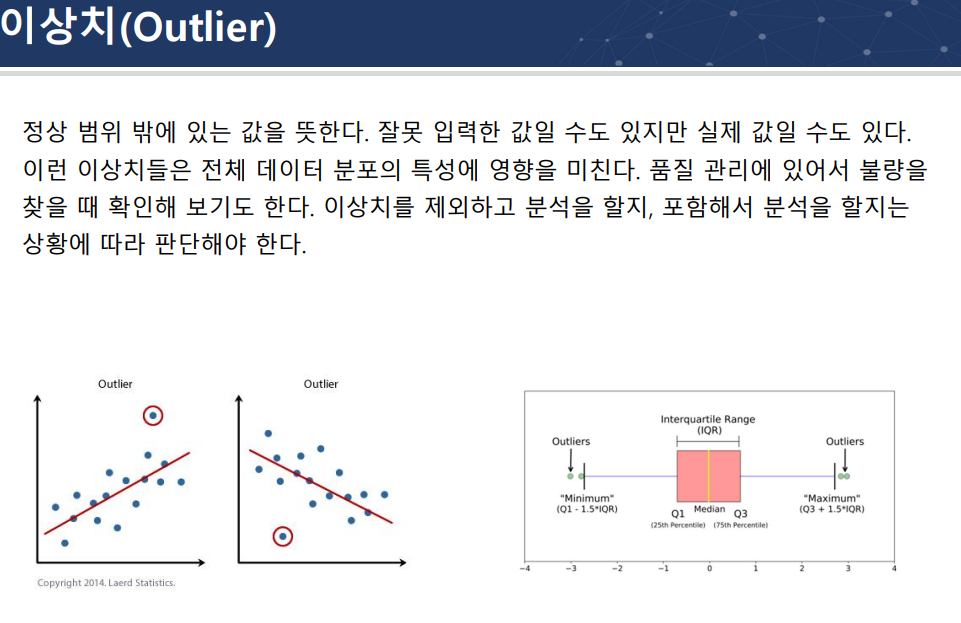
outlier
(IQR)함수로 min,max 정의해서 median
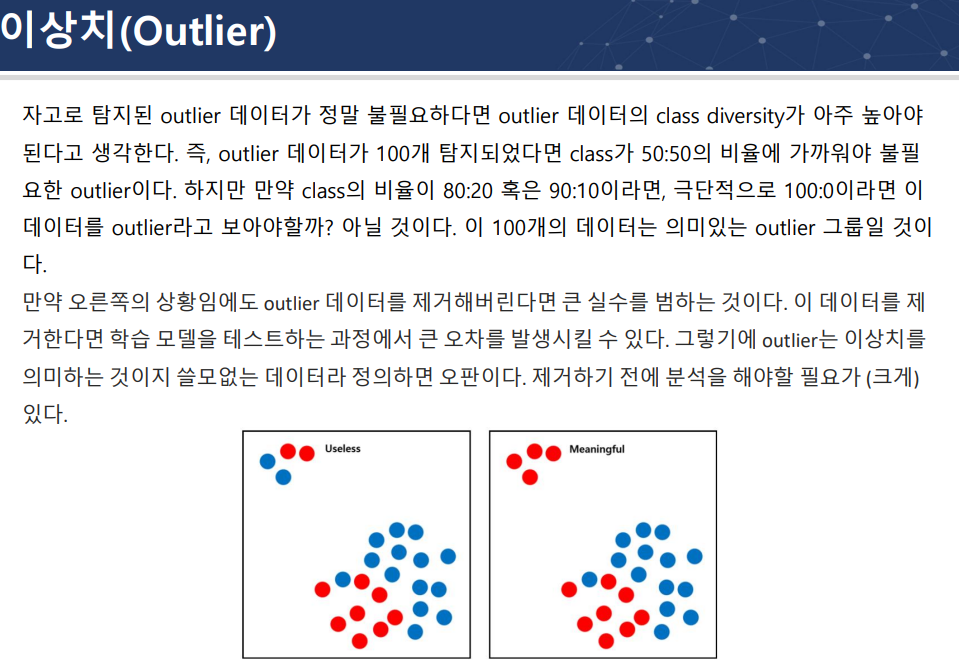
B케이스의 경우 이상치가 의미있는 데이터일 수 있음
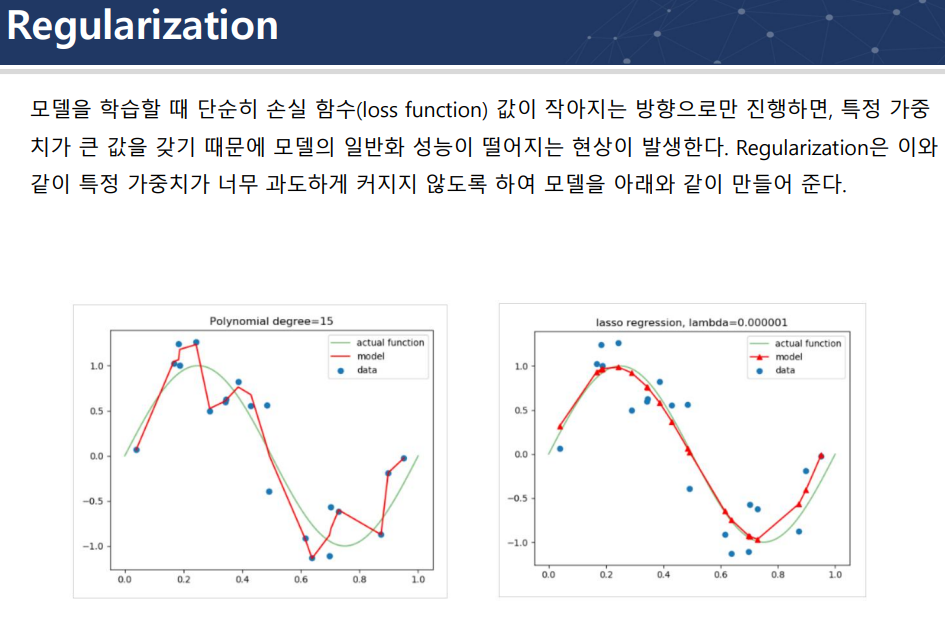
Regularization = 규제 = penalty
과도한 학습(과대적합의 판단이 들면 overfitting) 방지를 위해서 penalty를 줌