PythonAlgorisim
1.구현 문제 정리

먼저 구현문제를 풀 때 사용했던 개념들을 정리하고, 구현 문제에서 어려웠던 부분을 정리하겠다.zip함수는 조금 특이하다. 동일한 개수로 만들어진 자료형을 묶어주는 역할을 하는데, 리스트와 딕셔너리 형식으로 출력이 가능하다.리스트 comprehension과 같이 사용하면
2.Q26. [백준]카드 정렬하기
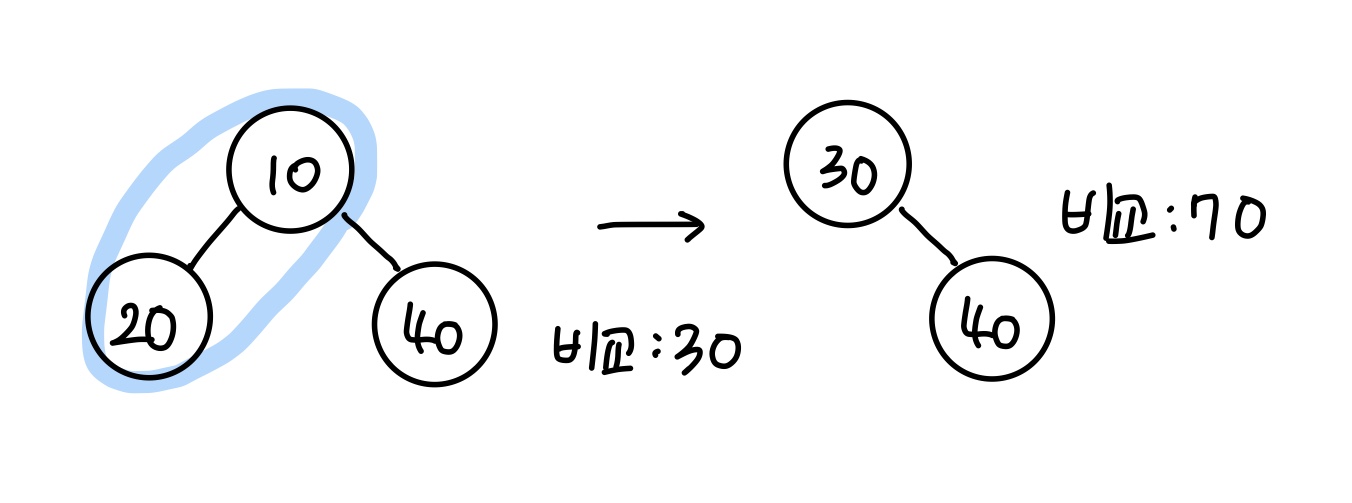
정렬하기 문제를 풀러가기 전에, 힙에 대해 정리해보도록 하겠다. 정렬하기 문제에서 무조건 sorted함수나 deque만 사용할 수 있다고 생각하면 간단하게 못 푼다ㅠㅠheapq은 이진트리 기반의 자료구조이다. 구현하고자하는 heapq이 최소 힙이냐, 최대 힙이냐에 따라
3.Dynamic Programming 예제

문제 풀이 다이나믹 프로그래밍의 메모이제이션을 적용해서 풀어보면 된다.
4.Q31. 금광
<이코테 Q31번>이 문제는 인덱스가 넘어가지 않게 문제를 푸는 것이 키 포인트이다.1\. 이를 위해서 맨 위에서 오는 경우, 맨 아래 인덱스에서 오는 경우를 제외해주어야 한다.또한 왼쪽에서 오른쪽으로 금광을 캐므로 평소에 2차원 리스트 for문을 돌릴 때와는 반
5.[백준] 9324 진짜 메시지
https://www.acmicpc.net/problem/9324같은 알파벳이 3의 배수로 나올 경우 result를 false로, 아닐 경우 true로 한다.=> 예외 : 12의 배수일 경우 3의 배수이지만 진짜 메세지가 된다.알파벳으로 인덱스 매기기입력받은
6.탐색 알고리즘 DFS, BFS
파이썬 개념들은 모두 notion에 대충 정리해뒀는데, 제대로 정리해서 벨로그에 올려둬야지 했었다. 특히 탐색 알고리즘은 이해하기 힘들어서 더 필요성을 느꼈던 것 같다🤔 내겐 아직 너무 먼 탐색 알고리즘이지만,,,ㅜㅠ 친해지고 싶다
7.[백준] 14465 소가 길을 건너간 이유

이 문제를 처음 접할 때 1. 그래프 이론 아니면 2. 합 연산 이라고 생각했는데 전혀 아니었다. 특이한 이론이니 기억해두도록 하자.슬라이딩 윈도우는 이진탐색이나 투 포인터와 마찬가지로 left와 right변수를 이용해서 리스트를 탐색하는 기법이다.그림과 같이 왼쪽 -
8.정렬 알고리즘
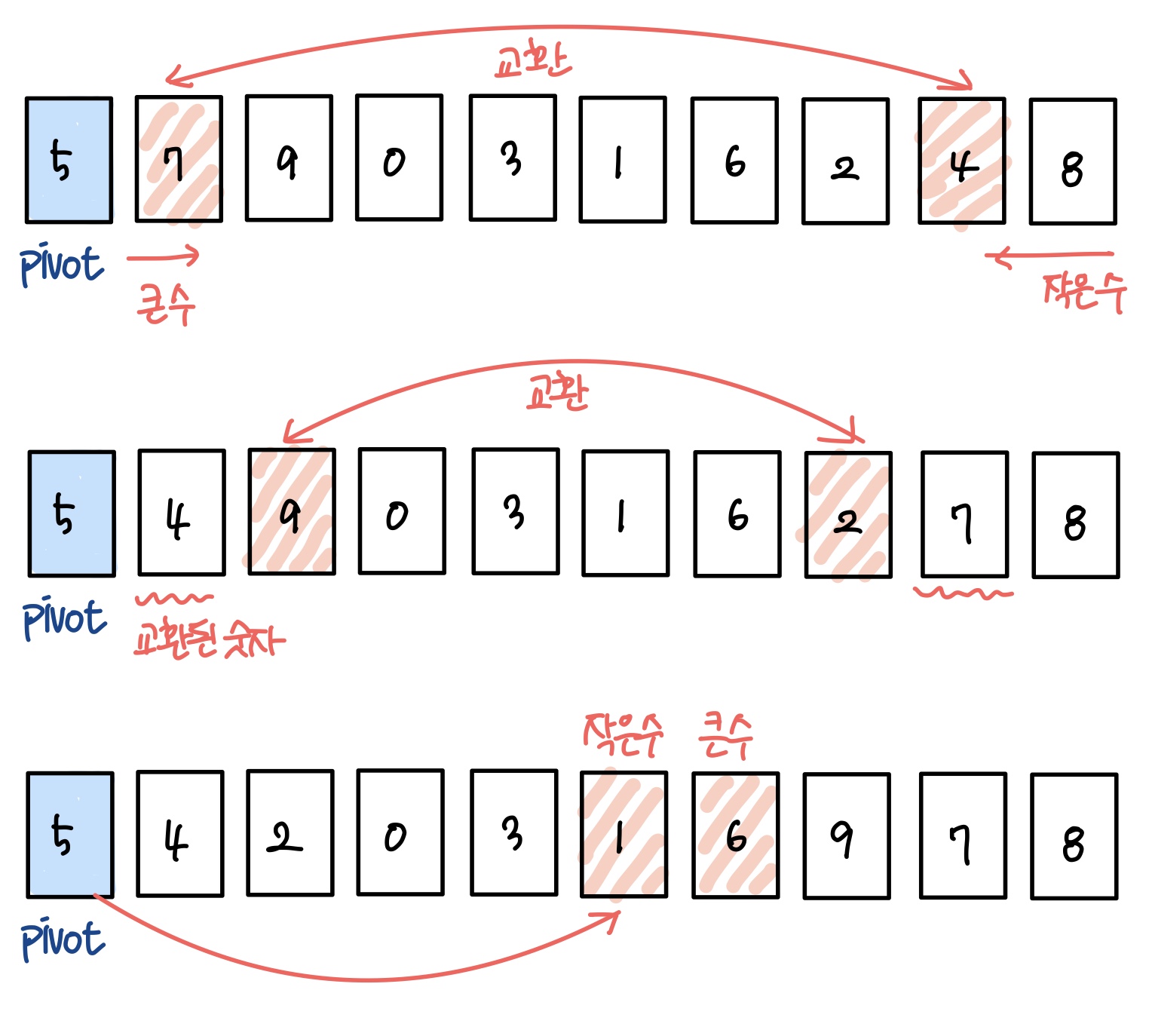
데이터를 특정한 기준에 따라서 정렬하는 것을 정렬 알고리즘 이라고 한다. 정렬 알고리즘으로 데이터를 정렬한 후에는 데이터가 순서대로 정렬되어있기 때문에 이진 탐색 이 가능해진다. 정렬은 대부분의 언어에서 라이브러리 함수로 제공하고 있는데 파이썬은 sort와 sorted
9.이진 탐색 알고리즘
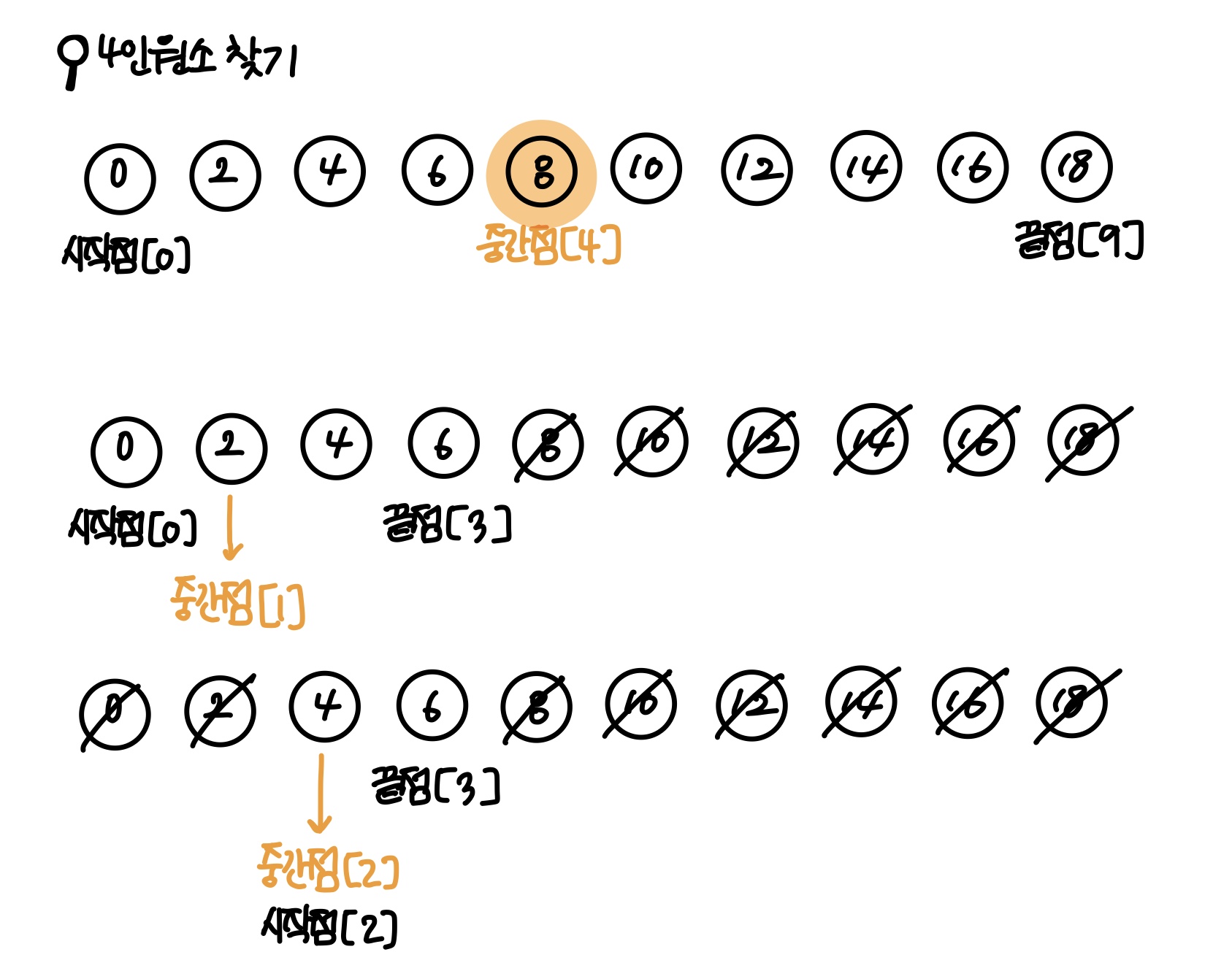
데이터를 차례대로 탐색하는 순차 탐색 이 있지만, 이진 탐색을 사용하는 이유는 원소가 정렬된 조건이라면 더 빠르게 특정 데이터를 찾을 수 있기 때문이다. 반으로 나누면서 탐색하는 탐색 과정인데, 위치를 나타내는 변수를 사용해 원하는 데이터를 찾는 것이 이진 탐색 과정이
10.[백준] 2564번 경비원 (실버 1)
오랜만에 블로그에 올리는 백준 문제 풀이..ㅎㅎㅎㅎㅎ노션에는 적었지만 블로그에는 뭔가 더 어려운 문제를 올려야할 것 같아서 안올렸는데 이러다가 하나도 못올릴 것 같아서 블로그에도 올려보려고 한당이 문제는 최단 거리를 구하는 방법만 정하면 쉽게 풀 수 있는데 문제에서 힌
11.[백준] 14719번 빗물 (골드 5)
문제 링크구현 문제는 풀 때마다 느끼는 거지만 문제 해결 방향이 가장 중요한 것 같다.. 보통 문제에서 답을 찾는 과정을 설명해주면서 그 방향을 귀띔해주는 경우가 많은데 이 문제는 없어서 더 헤맸던 것 같다ㅎㅎ이 문제를 보고 내가 생각했던 문제 풀이의 방향은 물을 담는
12.[백준] 11559번 Puyo Puyo (골드 4)
문제 링크예전에 스팀에서 뿌요뿌요 게임 했던 걸 생각하며 즐겁게 들어갔는데 그걸 진짜 알고리즘으로 짜려니 신경써야 할 것도 많고ㅎㅎ,, 까다로웠던 문제이다. 구현 문제들이 으레 그렇듯 이 문제도 테케 통과해서 돌려보면 틀리고 질문 검색에서 반례를 뒤져야 뭐가 틀린지 깨
13.[백준] 2206번 벽 부수고 이동하기
이 문제는 bfs()를 수행할 때 두 가지 조건의 경우에만 queue에 원소를 넣으면 원하는대로 알고리즘을 수행할 수 있다.1\. 벽을 깨지 않았고 벽이 있을 경우2\. 벽이 없는 경우최단 경로를 출력하려면 bfs 알고리즘을 수행한 경로, 즉 visited 배열을 만들
14.[백준] 7682번 틱택토
경우의 수를 정말 잘 따져봐야하는 문제BFS 알고리즘을 이용해서 풀었는데, 경우의 수와 고려해야할 반례가 많아서 구현이나 시뮬레이션 같은 문제였다. 코테에서 정말 만난다면 반례 생각 못하고 그냥 냈을 것 같다ㅎㅎ먼저 input을 받고 말의 개수를 먼저 센다. 조건에 맞