NoSQL
- Not Only SQL || Non-Relational Operational DataBase의 약자. 비관계형 데이터베이스이다. 기존의 RDBMS가 Consistency와 Availability에 중점을 두었다면 NoSQL은 Scalability와 Availability에 중점을 두고 있다.
- 대량의 분산된 비정형 데이터를 저장하고 조회하는데 특화된 데이터베이스로 스키마 없이 사용하거나 느슨한 스키마를 제공한다. 주로 빅데이터, 분산 시스템 환경에서 대용량의 데이터를 처리하는데 적합하다.
특징
-
RDBMS와 달리 데이터 간의 관계 (Relation)를 정의하지 않는다.
- RDBMS: 데이터 간의 관계를 Foreign Key로 정의하고 Join 연산 가능
- NoSQL: Key-Value 형태로 저장되기 때문에 Join 연산 불가능
- RDBMS에 비해 대용량의 데이터 저장 가능
- 분산형 구조로 설계
- 여러 곳의 서버에 데이터를 분산 저장하여 특정 서버에 장애가 발생했을 때도 데이터 유실 혹은 서비스 중지가 발생하지 않도록 한다.
- 고정되어 있지 않은 테이블 스키마를 갖는다.
- RDBMS와 달리 테이블(컬렉션)의 스키마가 유동적이고 데이터를 저장하는 컬럼이 각기 다른 이름과 다른 데이터 타입을 갖는 것이 허용된다.
장단점
RDBMS에 비해 저렴한 비용으로 분산처리와 병렬 처리 / 비정형 데이터 구조 설계로 설계 비용이 감소 / Big Data 처리에 효과적 / 가변적인 구조로 데이터 저장이 가능 / 데이터 모델의 유연한 변화가 가능
데이터 업데이트 중 장애가 발생하면 데이터 손실 발생 가능 / 많은 인덱스를 사용하려면 충분한 메모리가 필요. 인덱스 구조가 메모리에 저장되기에 / 데이터 일관성이 항상 보장되지 않음
→ 최종적 일관성(Eventually Consistent)을 지향한다.
종류
- Key-Value Database
ex. Redis, Oracle NoSQL DB, VoldeMorte - Wide-Column Database
ex. Hbase, Cassandra, GoogleBigTable, Vertica - Document Database
ex. MongoDB, CouchDB, Riak, Azure Cosmos DB - Graph Database
ex. Sones, AllegroGraph, neo4j, BlazeGraph, OrientDB
MongoDB 간단 정리
- 뛰어난 확장성과 성능 / 데이터 복제 / 데이터 분산(Sharding) /
- 저장구조 document DB
- Collection(=Table)
- Document(=Row)
- 데이터 입출력 시: JSON 형식
- 저장 시: BSON(Binary JSON)
- Field(=Column)
- Schema 선언 없이 Document의 Field를 자요롭게 추가/삭제하는 유연한 구조
Elastic Search 간단 정리
- java 오픈소스 분산 검색 엔진. DB를 대체하지는 않음. 데이터를 실시간으로 저장, 검색, 분석할 수 있고 검색을 위해 단독 사용되기도 함
- ELK: Log 및 데이터 분석 도구
- ElasticSearch: 데이터 분석 / 저장 기능
- Logstash: 데이터 수집 기능
- Kibana: 데이터 시각화
- 저장구조
- Index(=Database)
- Type(=Table)
- Document(=Row): Document 내 같은 Field는 데이터 타입이 같음
- Field(=Column)
- 핵심개념: 클러스터, 노드
Redis 간단 정리
- in-Memory Data Store.
- 다양한 데이터 타입 지원 / 분산 key-value store / 캐시 서버 / 메시지 브로커로 활용
- 저장구조
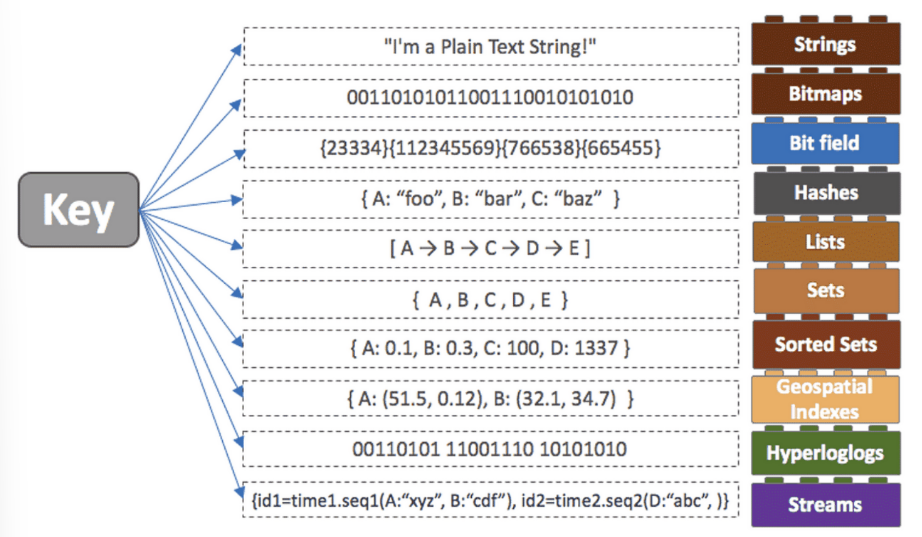
- 아키텍처
- 데이터 복제
- 데이터 분산
- Query Off Loading: 동시접속자수 및 처리속도 향상
- 대부분 DB 트랜잭션에서 (웹의 경우) read:write=90[80]:10[20]이기 때문에 read 트랜잭션을 적절히 분산시키면 처리시간 및 속도의 비약적 향상이 가능함
- redis-cluster: 메모리 제한 이슈로, 주기적인 scale out이 필요함(서버 추가)
Cassandra 간단 정리
- 단일 장애 없이 고성능 제공 / 수많은 서버 간의 대용량 데이터 관리를 위한 아키텍처 / 여러 데이터센터에 걸친 클러스터 지원 / 마스터리스 비동기 레플리케이션으로 클라이언트의 낮은 레이턴시 / 효율 성능
- 저장구조 Wide-Column(Column Family), Schema-less

- KeySpace: 논리적 데이터 저장소. 그 아래 table이 존재함
- Table: 다수의 Row로 구성
- Row: Column Name(Key), Column Value(Value)로 이루어진 Column으로 구성 - 아키텍처: Ring형
- 링을 구성하는 각 노드에 데이터를 분산 저장
- 데이터 분산 기준: 데이터의 Hash 값
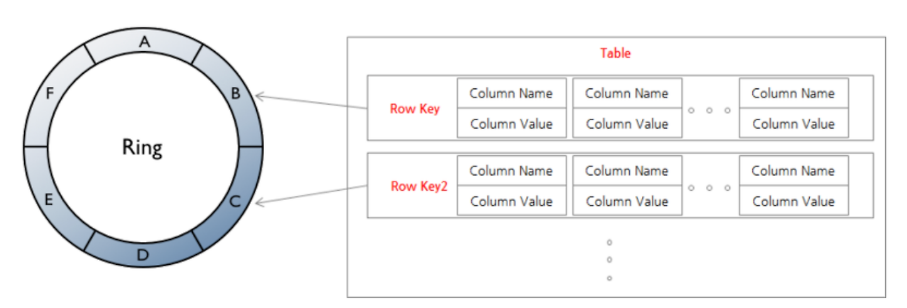
- Masterless
- 모든 노드가 동일하게 read/write 작업 수행이 가능
- 마스터 노드에 대한 장애 발생 여지가 없음
- 확장성과 고성능
- 기존 환경에서의 응용프로그램 확장은 기존 노드와의 데이터를 동기화하고 유지하는 내부 매커니즘이 필요하여 시간과 비용이 많이 듦.
- 수직 확장: 기존 HW에 용량 추가
- 수평 확장: HW 추가로 요청 처리를 여러 HW가 나눠 가짐
- 반면 Cassandra는 노드 추가만 하면, 클러스터 중단 없이 새 노드에 로드밸런싱이 됨(수평확장)
- e.g. 2개 노드, 초당 10만개 트랜잭션 처리 -> 8개 노드, 초당 40만개 트랜잭션 처리
- 기존 환경에서의 응용프로그램 확장은 기존 노드와의 데이터를 동기화하고 유지하는 내부 매커니즘이 필요하여 시간과 비용이 많이 듦.
- 고가용성
- 모든 노드가 Read/Write가 가능하기 때문에 장애 발생 시 가까운 정상 노드로 자동 라우팅, 교체됨.
- 다중 데이터 센터에 데이터를 복제해 로컬 성능 개선 가능
- 데이터 센터 화재 등의 문제에도 이를 복제해서 서비스 중단을 예방할 수 있음
- 데이터 입력의 자동화 처리가 어려움
- Join 등 복잡한 조건의 검색이 불가하므로, 데이터는 대량이지만 검색 조건은 단순한 쿼리를 가진 서비스에 적합(Row Key와 Column. 2가지의 인덱스만 존재)
ref) [NoSQL이란](https://shuu.tistory.com/135) 읽어보면 좋을 자료: [NoSQL 비교 정리](https://csj000714.tistory.com/622)

기억력이 맹구라 늘 기록해야해