RecSys'22
온라인 소설에 대한 사용자 반복 소비 행동 모델링
https://dl.acm.org/doi/10.1145/3523227.3546762
해당 논문을 고른 이유
- 소설책 분야에서는 어떻게 추천시스템이 이루어지고 있는가?
- 기존의 소설책 분야에서의 추천시스템과는 어떤 점이 다른가?
- 소비행동을 어떻게 모델링 하였는지?
- 데이터를 어떤 것을 사용하였는지?
이 부분들이 궁금하여 논문을 선택 하게 되었다.
Abstract
- 지난 7일 동안 신규 사용자에 대한 온라인 소설을 추천하는 것
- 두 가지 관찰사항을 확인하였다.
- 신규 이용자의 반복적인 신규 소비는 공통적이다.
(막산다는 것인가?) - 사용자와 소설책의 상호작용은 유익하다는 것
-> 사용자가 소설을 다시 소비할지를 예측하려면 세분화된 수준에서 각 상호작용을 특성화 하는 것이 중요하다는 것이다.
- 신규 이용자의 반복적인 신규 소비는 공통적이다.
이러한 사항들을 참고하여 Novel Net이라는 온라인 소설추천을 위한 신경망을 제안한다.
Novel Net은 사용자가 소비한 소설과 새로운 소설 모두에서 다음 소설을 추천할 수 있다.
동시에, interaction(상호작용)의 세밀한 속성을 고려한 정확한 interaction representaion을 얻기 위해 interaction encoder을 사용한다.
온라인 소설 추천 데이터셋은 잘 알려진 올라인 소설 읽기 플랫폼에서 구축되어 벤치 마크로 공개됨.
-> 실험결과를 통해 Novel Net의 효율성을 보여준다.
Introduction
기존의 도서 추천을 많이 연구가 되어왔다 하지만 온라인 소설 추천과는 다르다는 점이다.
뭐가 다를까?
- 추천 모델은 사용자가 개별 소설을 읽는 과정을 모델링 해야한다는 것.
- 모델이 제공하는 플랫폼
- 사용자의 과거 이력을 참고하지 않았다는 것.
또한 플랫폼은 신규 사용자를 끌어들이기 위해 수백만 달러를 지출하였으므로,
신규 사용자가 플랫폼에 머물도록 하는 것이 추천 시스템의 도입이 시급하다는 것이다.
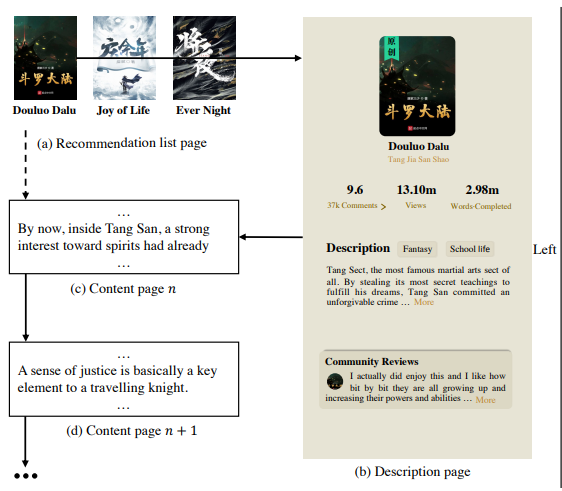
(그림1)
interaction (상호작용)
논문은 사용자와 소설책간의 interaction에 대해서 중요하게 생각한다.
왜냐하면, 사용자가 소설을 다시 소비할지 여부를 정확하게 예측 하기위해 각 interaction을 세분화된 수준에서 특성화해야 하기 때문임.
소설책에 관심이 있는 경우
사용자가 추천 목록 페이지(그림 1의 a)에서 소설 페이지(그림 1의 b)로 이동할 때 interaction이 시작된다고한다.
-> 사용자가 추천된 목록에서 흥미로워 보이는 것을 고를 경우를 말한다.
소설책에 관심이 없는 경우
사용자가 소설의 설명 페이지를 읽은 다음 추천 목록 페이지로 돌아가면 사용자가 소설에 관심이 없고, 따라서 해당 소설과 다시 상호작용하지 않을 것이라는 거다.
쉽게 말하자면
- 설명 페이지 --> 추천 목록 페이지로 돌아간다면, 상호작용 없음
- 설명 페이지 --> 콘텐츠 페이지로 간다면, 상호작용 있음
또한, 논문에선 새로운 사용자가 이미 알고 있는 소설을 추천하는 동기를 더 명확하게 하기 위해
두 가지 중요한 온라인 소설 추천 시나리오를 추가로 설명한다고 한다.
시나리오 1.

플랫폼은 새로운 사용자가 플랫폼에 적극적으로 방문하지 않을 때
새로운 사용자에게 푸시 알람을 보낸다.
(위의 사진과 같이 푸시알람을 통해 알림을 보냄)
시나리오 2.
플랫폼에 새로운 사용자가 다음에 플랫폼에 들어올 때
이전에 소비된 소설을 새로운 사용자에게 제시할 수 있다는 것이다.
이러한 점들을 고려하여 Novel Net이라는 온라인 소설추천을 위한 신경망을 제안한다고 한다.
여기까지 정리하자면 Novel Net은
- 사용자가 소비한 소설, 새로운 소설 모두에서 사용자가 선호할 수 있는 소설을 동시에 추천한다는 것이고
- interaction encoder을 통해 세분화된 interaction속성을 추출한다는 것이다.
Related Work
기존의 온라인 소설추천방법은 Li et al이 연구한 협업모델링(TDCIM)을 사용한
"태그 기반 알고리즘"을 제안하였고 대다수의 사용자가 특정 기간 동안 몇가지 유형의 소설만 소비한다는 사실을 관찰 하였다.
이전의 협업필터링 모델은 추천 목록에서의 문제는 광범위한 소설 범주가 있었지만, TDCIM이 새로운 태그를 활용하여 이러한 문제를 해결하였다.
해결한 방법으로는
새로운 태그를 활용하여 흥미롭지 않은 카테고리의 순위를 낮추고, 흥미로운 카테고리의 순위를 높힌 것
그러나 Li et al은 사용자의 반복적인 새로운 소비 행동을 고려하지 않았으며, 데이터 셋은 공개적으로 사용할 수 없다는 점이다. 또한 본 논문은 신규 사용자에게 중점을 둔다는 차이가 있다.
Repeat consumption
Repeat consumption은 다양한 도메인(전자상거래, 음악 감상, 라이브 스트리밍, 웹 재방문, 반복되는 웹 검색 쿼리)에서 연구 되어왔다.
하지만 온라인 소설책 읽기에서는 아직 연구가 되지 않았다는 것.
모델의 방향으로 잡을 3가지 범주로 나눌 수 있다.
1. interaction이 반복 소비가 될지의 여부를 예측하는 모델
2. 현재 소비가 반복 소비라는 사실을 고려하여 사용자가 선호할 소비 품목을 예측하는 것
3. 새로운 항목과 이전에 소비된 항목을 동시에 추천하는 모델
로 범주를 나누었었고, 본 논문의 작업으로는 3의 경우에 속한다고 한다.
3의 경우로 연구된 이전의 모델과 비교했을 때, 본 논문의 방법은 신규 사용자의 온라인 소설 추천의 특성을 고려하여 더 많은 interactin 속성을 입력으로 사용한다고 한다.
Book recommendation
Session-based recommendation
사용자의 이전 이력을 사용한다는 것은 세션기반의 모델과 비슷할 수 있다.
다만 세션기반의 모델과의 핵심 차이점은
- 세션기반 : 일반적으로 항목 ID가 있다.
↕ - 온라인 소설 추천의 상호작용 : 항목 ID, 기타 interaction
다만 몇몇 세션기반 모델도 사용자 반복 소비행동을 고려한다.
그래서 중요하거나, sota를 달성한 세션기반 모델들은 해당 논문의 베이스라인으로 잡았다.
Method
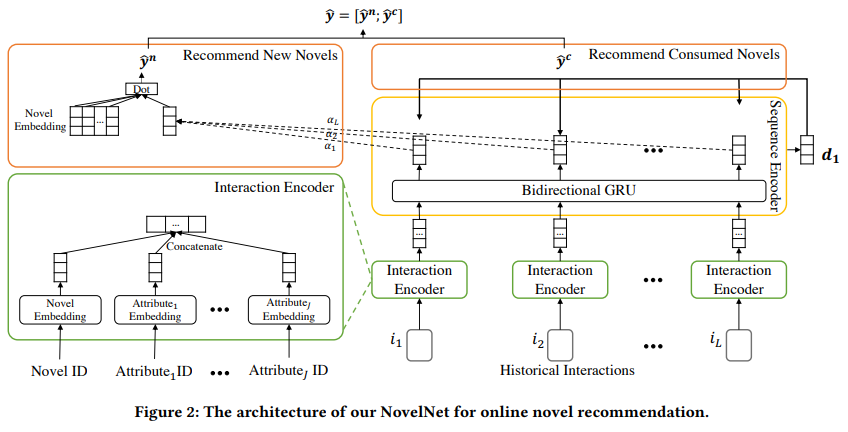
Novel Net Module에는 4가지 모듈이 있다.
- Interaction Encoder
- Sequence Encoder
- Recommended New Novels
- Recommended consumed Novels
Interaction Encoder
사용자와 소설간의 상호작용을 탐구하기 위한 것이다.
이 부분에서는 5가지 관점을 바탕으로 5가지 상호 작용 속성이 추출된다.
1. 사용자가 설명 페이지를 읽은 후 내용 페이지(content page)를 계속 읽는 경우
2. 많은 content page를 읽는 경우
3. 자신의 라이브러리에 소설을 추가하는 경우
4. 소설책을 읽는데 많은 시간을 보낸 경우
5. 소설책과 여러번 interaction 했을 경우
(아마 여러번 소설책을 봤을 경우인가?)
들을 통해 5가지 상호 작용 속성이 추출된다.
- description_content
만약 사용자가 처음으로 설명페이지를 읽은 후, 적어도 한 번의 content page를 읽은 경우면
이 속성의 값은 2이고, 다른 경우엔 1이다. - real_read
만약 사용자가 적어도 두 번 content pages를 읽은 경우
이 속성의 값은 2이고, 다른 경우엔 1이다. - collect
만약 사용자가 자신의 라이브러리에 소설책을 추가한 경우
이 속성의 값은 2이고, 다른 경우엔 1이다. - read_duration
이 interaction이 지속되는 minutes - novel_count
interaction 할때 까지의 사용자의 기록에서 소설이 등장한 횟수
또한 위의 상호작용 속성외에도 다른 영역에서 "재소비"를 예측하는데 유용한 것으로 입증된 4가지 속성도 탐색하였다.
Anderson et al의 연구에선
최근의 소비된 아이템은 다시 소비될 가능성이 높고, 고품질의 아이템일 수록 소비될 가능성이 높다는 것이다.
고로 최신성과 품질이 재소비 예측에 유리함을 보인다.
Bensonet at al의 연구에선
아이템의 지루함이 증가하면 결국 아이템을 포기하게 된다는 사실을 관찰하였고 동일한 아이템을 사용자가 소비하는 간격을 아이템의 지루함을 나타내는데 사용하였다.
(사용자의 소비간격을 통해 아이템의 지루함을 표현하였다.라는 말인것 같다.
지루함은 소비하는데 부정적인 요인이기 때문!)
"재소비"를 예측하는데 유용한 4가지 속성
- recency
target 시간과 interaction 시작시간의 시간 차이 - quality
Chen et al에 따라, 각 소설의 quality를 측정하기 위해 popularity(인기도)를 사용한다.
소설 인기도는 훈련 셋에서 소설 빈도의 자연로그로 정의 된다. - temporal_gap
소설책에 마지막 interaction의 시작시간 과 이 interaction 시작 시간간의 시간차
만약, 사용자가 첫 번째 interaction일 경우 이 값은 0으로 설정된다. - index_gap
소설책의 마지막 interaction 과 이 interaction 간의 나타난 소설책들의 숫자
만약, 사용자가 소설책에 처음으로 interaction일 경우 이 값은 0으로 설정된다.
또한 소설 ID는 소설책을 추적하는데 사용된다.
novel tag: 사용자를 위해 새로운 소설책을 발견하는데 유용함. 고로 interaction속성으로 취급
- novel
novel ID - novel_tag
소설책에 연결된 tag id이다. (예를 들어 romance와 같음)
각 속성이 정수가 아닌경우 값은 값 보다 크거나 같은 최소 정수인 정수로 변환된다.
a^j 속성에 대해, interaction encoder는 임베딩된 look-up table 을 통해 벡터 e^j로 변환된다.
이러한 속성들은 다른 임베딩된 look-up table도 사용한다.
Then, 벡터 [e^1,e^2,,,e^11]의 집합을 얻는다.
interaction representaion r은 이러한 속성 벡터들의 연결이다.
r = [e^1,e^2,,,e^11]
Finally, interaction sequence Su는 interaction encoder에 의해 [r^1,r^2,,,r^11] 벡터들의 sequence로 변환되어 진다.
Sequence Encoder
세션 기반 추천에서 최근 경험적인 분석은 GRU가 neural 모델 사이에서 매우 경쟁력이 있음을 보여준다.
Inaddition, 논문의 파일럿 실험에서 bidirectional GRU는 undirectional GRU보다 더 나은 성능을 달성함
(성능 측면에서 / bidirectional GRU > undirectional GRU)

Thus, 저자들이 사용한 sequence encoder는 bidirectional GRU 이다.
bidirectional GRU는
input으로 interaction vector의 sequence,
output으로 forward vectors 와 backward vectors로 취한다.
Recommend New Novels
오직 하나의 디코딩 스텝이 있는 포인터 네트워크는 소비된 소설책을 추천하는데 사용된다.
시쿼스 인코더의 출력값이 주어지면, 첫 번째 디코더 은닉층은 d1에 의해 얻어 진다.
그런다음 포인터들은 다음과 같이 계산된다.
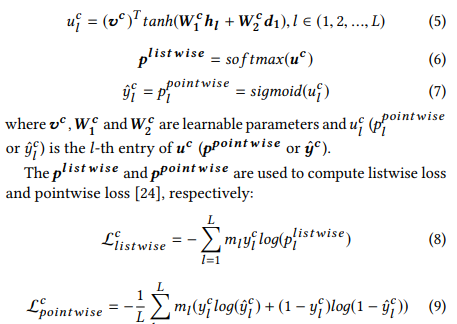
p^(list wise)와 p^(point wise)는 각각 list wise 손실과 point wise손실을 계산하기 위해 사용 되어진다.
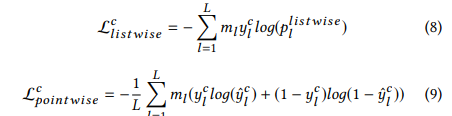
여기서 l번째 interaction과 연관된 ground truth 소설책이면,
y1^c =1 이고 아니라면 0이다.
l번째 interaction과 연관된 소설책에 대해,
만약 l번째 interaction이 소설책의 마지막 interaction이라면
m1=1이고 아니라면 0이다.
이러한 배경은 소설책에 마지막 interaction의 문맥화된 표현이 소설책에 모든 interaction을 요약하고 소설책을 읽는 사용자의 모든 process를 모델링하기 위해 사용된다.
Experiments
Dataset
Li et al의 연구에선 데이터셋을 배포하지 않았다.
그대신 저자는 다음과 같이 데이터셋을 만들었다.
- 14일 동안 중국의 텐센트에 속한 유명한 온라인 소설책 읽기 플랫폼 QQ브라우저로 모은 로기 기반 온라인 소설책 추천 데이터셋
- 새로운 유저의 로그는 2021/11/18 ~ 2021/11/24일 까지 나타났으며
- 데이터셋을 만들기 위해 모든 새로운 사용자의 하위집합은 랜덤하게 추출되었다.
- 2021/11/18~2021/11/22 training
- 2021/11/23 validation
- 2021/11/24 test
Metrics
- MRR
원하는 소설의 상호 순위의 평균,
순위가 k보다 크면 역 순위는 0으로 설정됨- MRR@1
MRR@1은 온라인 소설 추천 시나리오에서 오직 하나의 추천 소설만 사용자에게 표시될 기회가 있기 때문에 주요 평가 지표임. - MRR@5
- MRR@10
- MRR@20
- MRR@1
- Recall
원하는 소설이 나오는 경우의 비율 * Recall@5- Recall@10
- Recall@20
experimental results
- 비신경망 기반 모델이 다른 신경망 구조의 모델보다 더 정확한 추천을 제공한다.
- 소설을 다시 읽는 것이 일반적인 현상이고 많은 재소비 행동이 마지막으로 읽은 소설 사용자와 관련이 있기 때문이다.
- 반복 신규 소비를 명시적으로 모델링해야 할 필요성이 있음.
- 포인터 네트워크와 point wise 손실 및 마이닝된 interaction 속성의 조합의 효율성을 나타냄.
impact of interaction attribute
NovelNet-160,320 : 160,320차원으로 임베딩된 novel net
observe
- Novel Net-160,320의 모델 성능은 비슷한 성능을 가지고 있음
-> 이는 단순히 새로운 임베딩 차원을 늘리는 것만으로는 모델 성능을 향상시킬 수 없다는 것을 의미함. - NovelNet-description_content, real-read,read_duration은 하나의 추가 속성을 한 모델과 Novel-160만을 사용한 모델 보단 더 나은 성능을 보임
-> 온라인 소설 읽기의 특수성을 고려하여, 마이닝된 상호 작용 속성이 더 강력함을 나타냄 - NovelNet-novel_count, recency, temporal_gap도 NovelNet-160을 훨씬 능가하므로 NovelNet에 포함된다.
- collect 속성은 모델 성능을 향상시킬 수 없다.
-> 한 가지 가능한 이유는 일부 수집 작업이 사용자 자체가 아니라 플랫폼에 의해 수행되므로 수집 속성이 noise하다는 것이다. - Novel_quality, novel_tag는 NovelNet-160을 능가하지 않으며,
NovelNet-index_gap은 temporal_gap보다 열등하므로 속성 quality, novel_tag 및 index_gap은 최종 NovelNet에 포함되지 않는다. - NovelNet은 단 하나의 속성을 사용하는 모델보다 성능이 우수하다.
-> 효과적인 interaction 속성을 결합하면 모델 성능을 더 향상시킬 수 있으며, 이는 interaction을 정확하게 특성화하는 것이 필수적임을 나타냄.
Impact of Pointwise Loss
-
NovelNet이 w/o pointwise 및 w/o listwise 보다 더 나은 성능을 얻는 것을 관찰함.
-> pointwise loss와 listwise loss 모두 도움이된다. -
w/o pointer는 NovelNet보다 훨씬 월등하다.
-> 신규 사용자의 반복적인 새로운 소비 행동을 명시적으로 모델링해야 할 필요성과 pointwise loss이 있는 pointer network의 효율성을 나타냄
Why is the new part of MRR@1 of Models Small?
모델의 MRR@1의 new part가 작은 이유는?
결론으론
1. 모델의 추천 결과의 반복률은 매우 크고 테스트 셋의 반복률보다 훨씬 높다.
-> 모델인 popularity bias probelm을 가지고 있어, 새로운 소설은 추천될 가능성이 적어서 MRR@1의 점수가 낮다.
2. ?
3. w/o pointer가 w/o listwise보다 반복 비율이 작지만 w/o listwise는 w/o pointer보다 MRR@1의 더 큰 새로운 부분을 얻음으로써 pointwise loss의 효율성을 더 보여준다.
그리고 또 다른 이유는
새로운 소설을 예측하는 것이 소비된 소설을 예측하는 것 보다 어렵기 때문일 수 도 있다.
그래서 실험을 또 했다.
새로운 소설 예측 vs. 소비된 소설 예측
그림 6을 보면
모든 모델의 새로운 소설을 예측하는 MRR@1의 점수가 더 적다는 것을 볼 수 있음.
-> 이 결과로 보아 새로운 소설을 예측하는 것은 어렵
-> 한 가지 이유는 추천 소비 소설 모듈의 후보 수가 추천 신작 소설 모듈의 후보 수보다 훨씬 적다는 것이다.
Conclusion
논문은 온라인 소설 도메인분야 에서 next-item recommendation을 다룬다.
구체적으로 저자는
- 새로운 사용자의 반복적인 소설책 소비가 일반적이며
- interaction을 정확하게 특성화하는 것이 반복적인 소설책 소비를 모델링하는데 중요하다는 것을 관찰하였다.
- 세분화된 interaction 속성을 고려하여 interaction을 부호화하고
- pointwise가 있는 pointer network를 사용하여 사용자 반복 소비 행동을 모델링하는 NovelNet을 제안함.
- 사용한 데이터 셋은 온라인 소설책 읽기 플랫폼에서 구축되어 벤치마크로 공개한다.
- 하지만 실험 결과에서 다룬바, 모델은 popularity bias probelm을 겪는다.
향후 연구론
popularity bias probelm을 완화하도록 할 것이며,
읽기 프로세스를 명시적으로 모델링할 것임.
pointer network
기계 번역 및 텍스트 요약과 같은 시퀀스 간의 작업을 위해 2015년에 도입된 신경망 아키텍처 이다. 고정된 어휘에서 각 출력 기호를 생성하는 기존의 시퀀스-시퀀스 모델과 달리 포인터 네트워크는 입력 토큰을 직접 지정하여 어휘의 일부가 아닌 기호를 출력할 수 있다.
-> 이는 포인터 네트워크가 출력 어휘가 매우 크거나 알 수 없는 작업에 특히 유용하다는 것이다.
pointwise approaches
pointwise는 손실함수에서 한번에 하나의 아이템만 고려한다.
하나의 Query(=User)가 들어왔을 경우 이 값에 대응하는 하나의 item만 가져와서 Score(User,Item)을 계산하고, 이를 Label score(Ground truth)와 비교하여 최적화 시키는 것이다.
pairwise approaches
pairwise는 손실함수에서 한번에 2개의 아이템을 고려한다.
구체적으론, 1개의 positive item 과 1개의 negative item을 고려함.
Score(User,Pos item,Neg item)을 계산한다.
listwise approaches
listwise는 손실함수에서 한번에 전체의 아이템을 고려한다.
전체 아이템간의 Rank를 학습하며, 이는 꽤 복잡함.
느낀점
맨 처음에 질문을 던졌던 부분에 대해 답을 찾아 보자면 이렇다.
해당 논문을 고른 이유
- 소설책 분야에서는 어떻게 추천시스템이 이루어지고 있는가?
저자들이 아는한에서는 온라인 소설 추천을 위해 collaborative item modeling이 있는 태그 기반 알고리즘만이 제안되어왔다.
-
기존의 소설책 분야에서의 추천시스템과는 어떤 점이 다른가?
또한 기존의 도서 추천은 연구되어 왔지만 이는 온라인 소설 추천과는 다르다고 한다.
도서추천 / 온라인 소설 추천의 차이점
모델이 제공하는 플랫폼이다.
도서추천: 사용자가 책을 찾는데 도움을 주는데 그침.
온라인 소설 추천: 추가로 사용자가 자신의 플랫폼에서 소설책을 읽을 수 있도록함 -
소비행동을 어떻게 모델링 하였는지?
세분화된 interaction 속성들을 고려하여 interaction을 부호화하고,
pointwise가 있는 pointer network을 사용한다. -
데이터를 어떤 것을 사용하였는지?
데이터셋은 잘 알려진 소설책 읽기 플랫폼에서 만들어 졌으며, 벤치마크로 공개적으로 사용하도록 배포함
에 대한 질문들을 해결할 수 있었다.
논문을 읽은 바론 저자들은 실험을 많이 한걸로 보인다.
(속성들에 대한것과, 소비된것과 새로운 것의 차이, 평가 메트릭에 대한 차이 등등)
(엄청나게 많은 실험 결과를 해석하기가 어려웠음..)
또한 저자들의 논문에서 부족한 점 (popularity bias problem)을 언급하였고, 이 부분은 향후 연구에서 보완한다는 점이 기대가 된다.
Ref)
About pointwise,pairwise,listwise
https://junklee.tistory.com/126
https://yamalab.tistory.com/119
