[MongoDB] Atlas Search 한글 검색 설정
MongoDB의 atlas search를 이용해 검색 기능을 구축해보겠습니다.
Atlas search 는 ElasticSearch 와 같은 Apache Lucene 기반의 검색엔진을 제공해주는데요,
이 Lucene의 장점은 다양한 언어에 형태소 분석 기능을 제공한다는 점입니다. (영어, 한글 등..)
오늘은 nodejs의 NestJS 프레임워크를 이용해서 간단하게 검색 API를 구축하고
테스트해 보겠습니다.
아래 순서대로 진행을 해보겠습니다
- 한글 샘플 데이터 로드하기
- Atlas 에서 Search Index 만들기
- NestJS 프로젝트 생성
- MongoDB client 환경 구축
- aggregate search query 코드 작성
- 검색 API 테스트
사전 준비사항
이번 포스트에서는 아래 작업까지는 다루지 않습니다.
nodeJS
- npm 설치
아래 공식 홈페이지에서 운영체제에 맞게 다운로드 받으셔서 준비해주세요
LTS 버전으로 받으시는 것을 추천드립니다.
MongoDB
- MongoDB 회원가입
- Organazation 설정
- Project 생성
- Cluster 생성
아래 공식 문서를 따라 무료 플랜의 Cluster를 준비해주세요
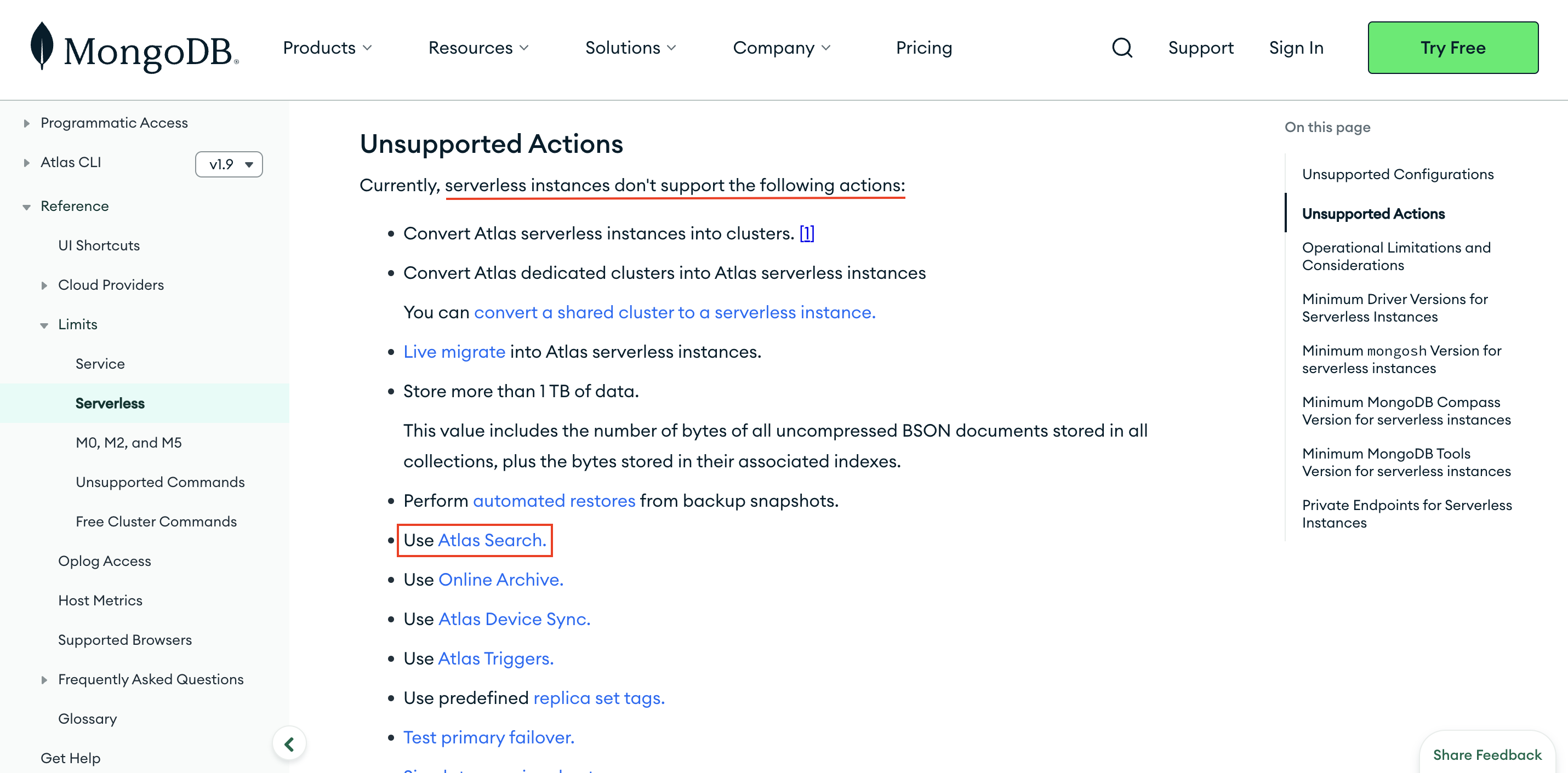
Cluster Tier를 설정하실때, Serverless로 생성하지 않도록 주의해주세요.
MongoDB는 현재 Serverless 티어에서 Atlas Search를 지원하지 않습니다
1. 한글 샘플 데이터 로드하기
먼저 검색에 사용할 샘플 데이터를 준비해주겠습니다.
저희는 MongoDB의 웹 콘솔인 Atlas 에서 새 Database와 Collection을 만들고 Documents 여러개를 넣어주겠습니다.
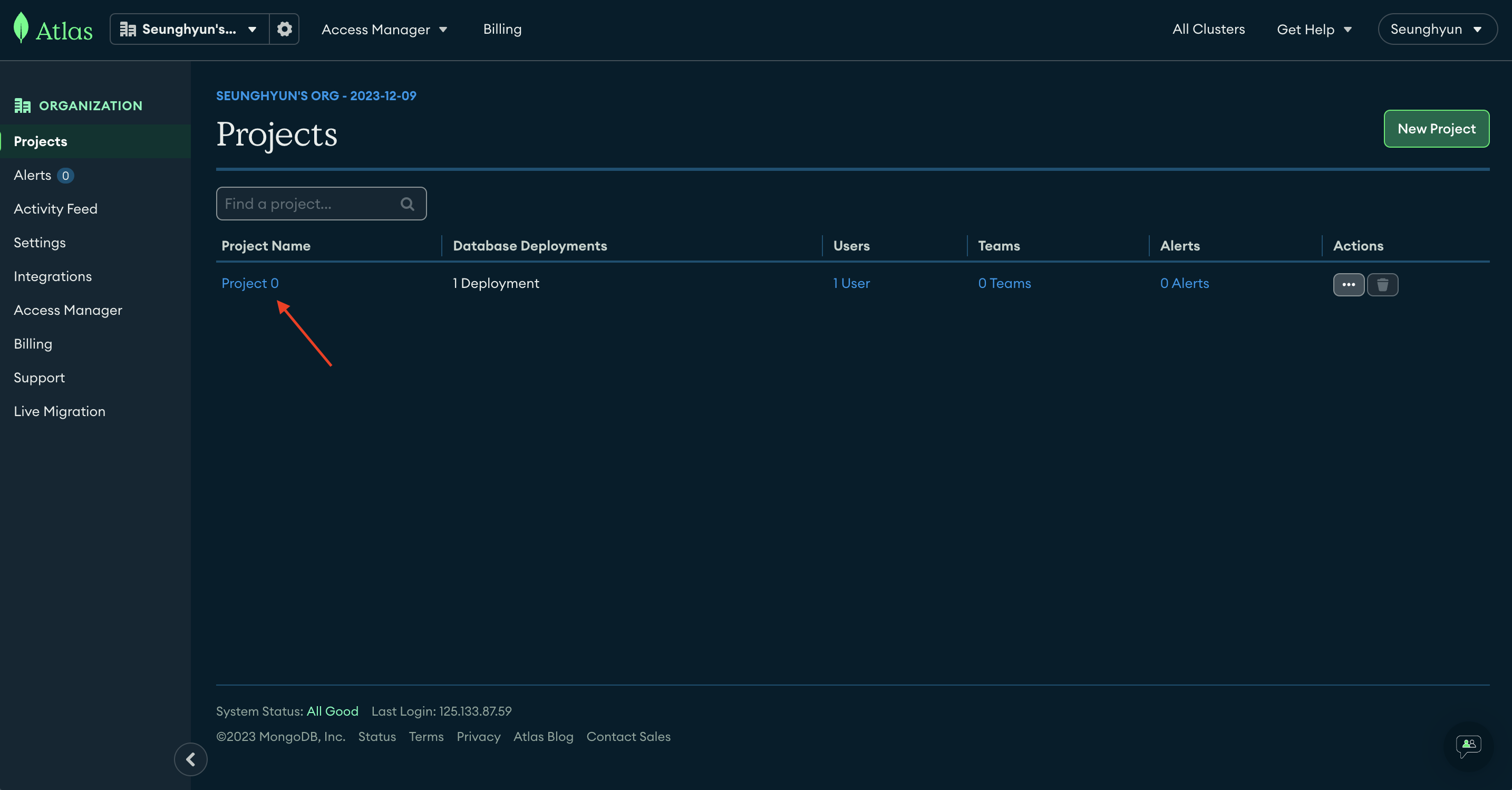
처음 Atlas 에 진입하시면 위 화면을 만나게 되실텐데요, 이 화면은 Seunghyun's org 라는 Organazation 의 Project 리스트를 보여주는 곳입니다.
참고로 간단히 설명 드리자면 MongoDB의 구조는 아래와 같다고 보시면 됩니다.
- MongoDB 의 구조
Organization (조직)
↓
Project (프로젝트)
↓
Cluster (서버)
↓
Database (Collection들의 집합)
↓
Collection (Document들의 집합)
↓
Document (여러 필드로 구성)
↓
Field (각각의 데이터)
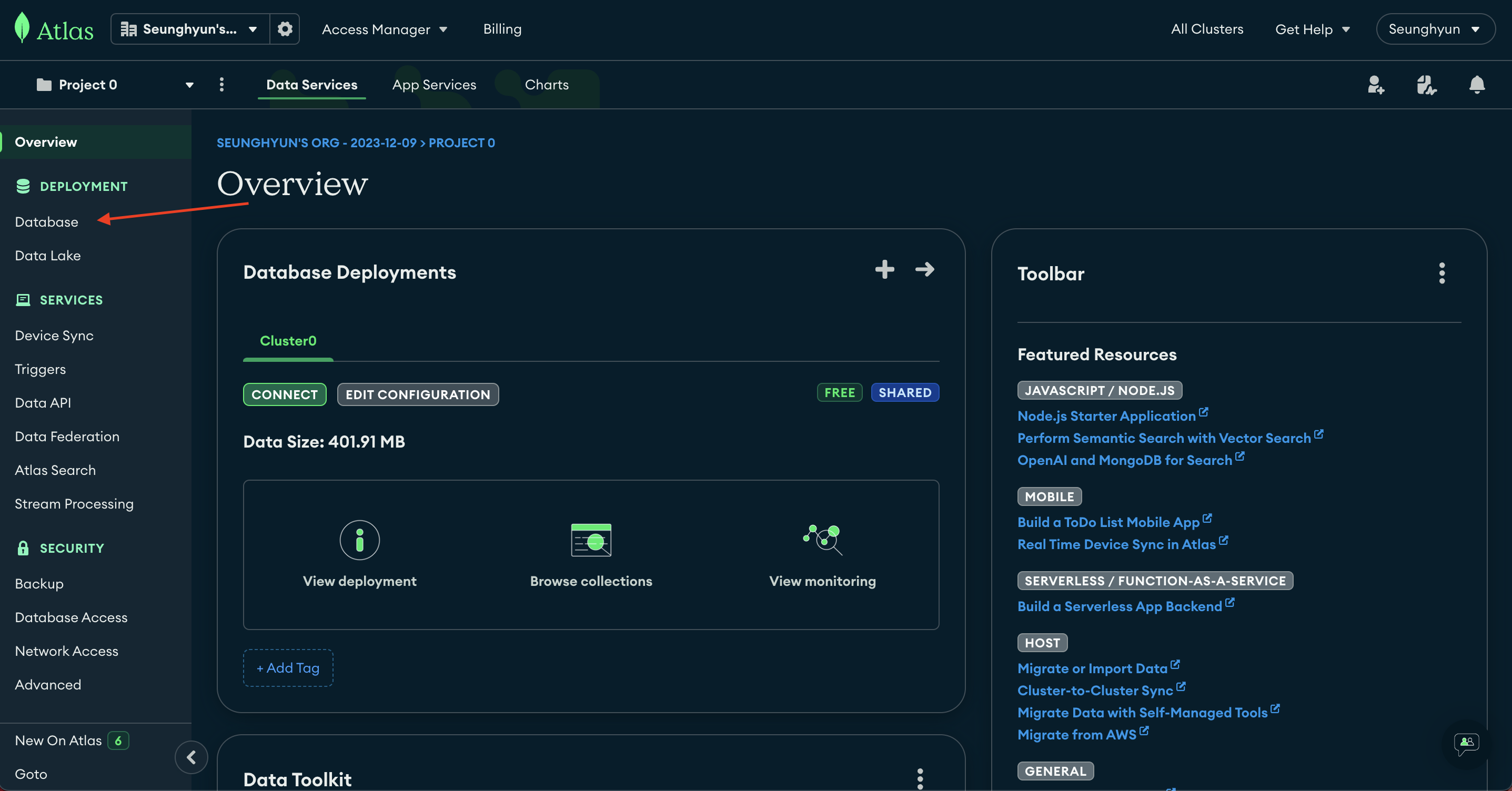
왼쪽 메뉴바에서 Database 클릭
Browse Collections 클릭
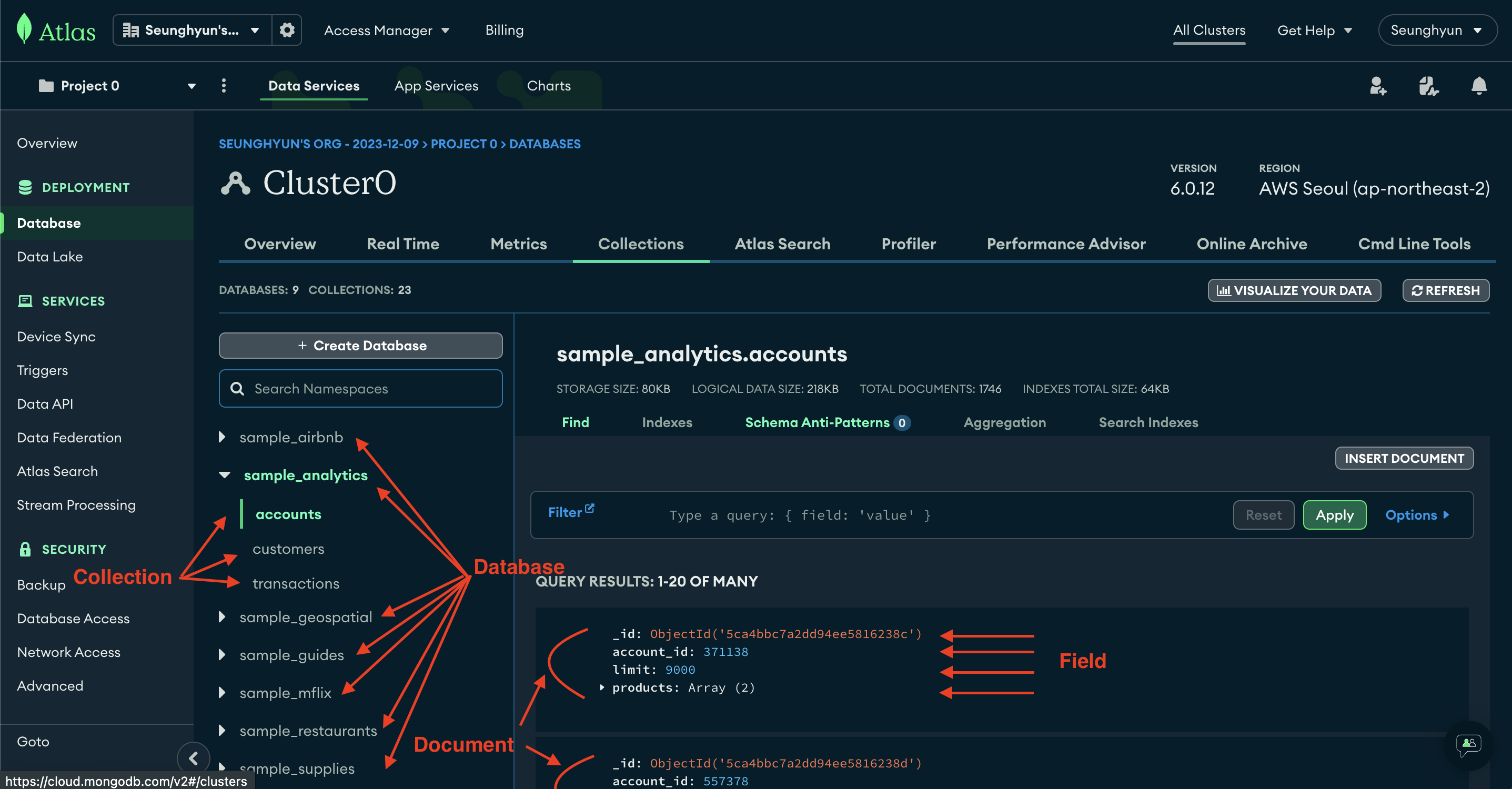
Cluster 관리 콘솔에 진입했는데요,
들어온 김에 설명드리자면
위에서 설명 드린 MongoDB 의 구조에서 Database ~ Field 가 이렇게 생겼습니다.
그리고 위에 보이는 샘플 데이터들은 MongoDB에서 기본으로 제공해주는 샘플 데이터 들입니다.
당연히 영문 데이터들이고, 어차피 사용하지 않을 것이기 때문에 기본 샘플 데이터가 없으셔도 괜찮습니다.
저희는 한글 검색을 위해 한글 데이터를 따로 넣어주겠습니다.
+ Create Database 버튼 클릭
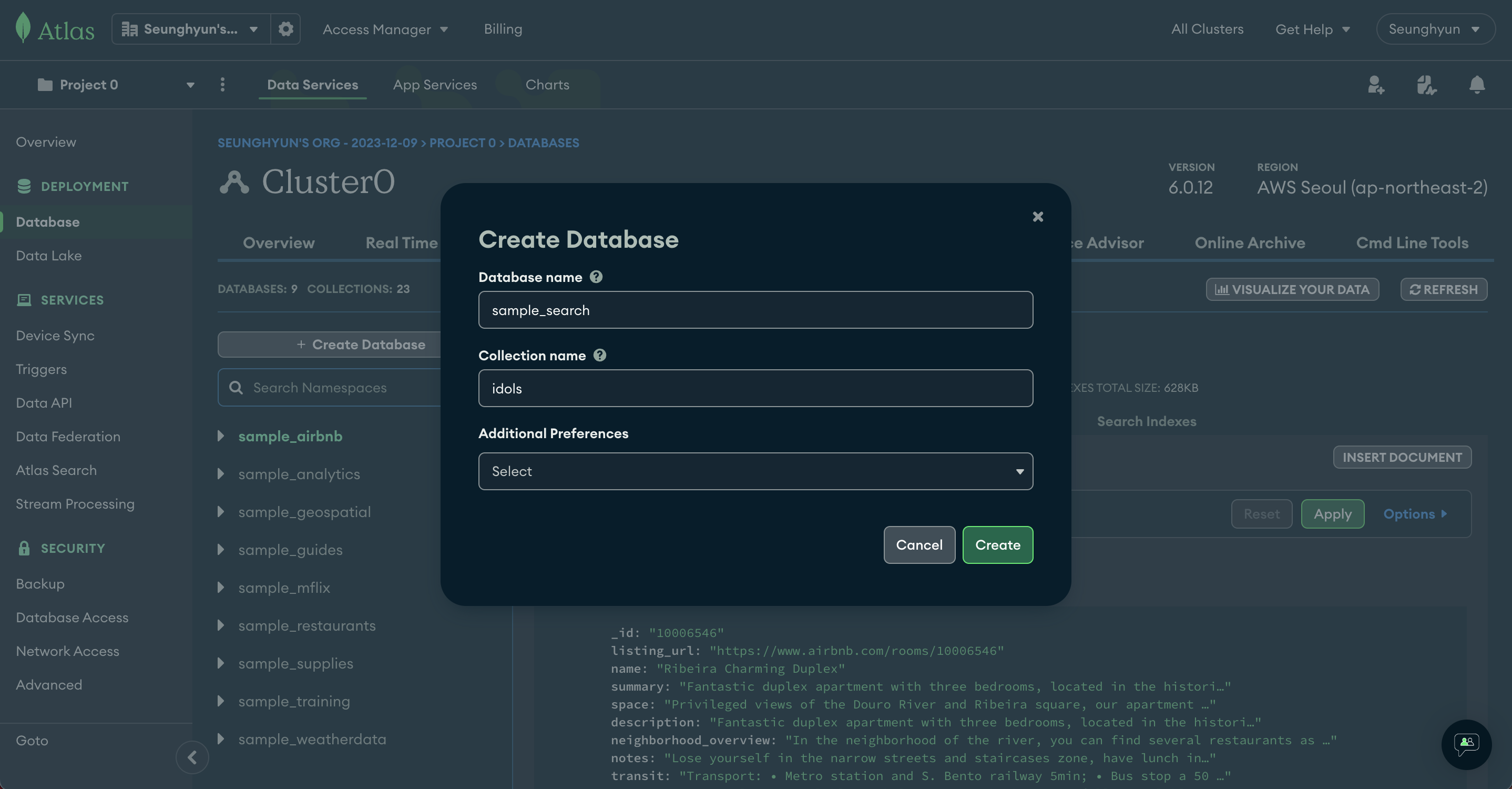
새로 만들 Database와 Collection에 이름을 지정해줍니다
저는 아이돌 그룹 멤버들의 데이터를 넣어줄 것이기 때문에 아래와 같이 이름을 지어주겠습니다.
Database name : sample_search
Collection name : idols
Additional Preferences : (그냥 냅두기)
다 적었으면 Create 버튼 클릭
sample_search 데이터베이스 안에 idol 컬렉션이 잘 생성되었고,
이제 Document들을 넣어주겠습니다.
INSERT DOCUMENT 버튼 클릭
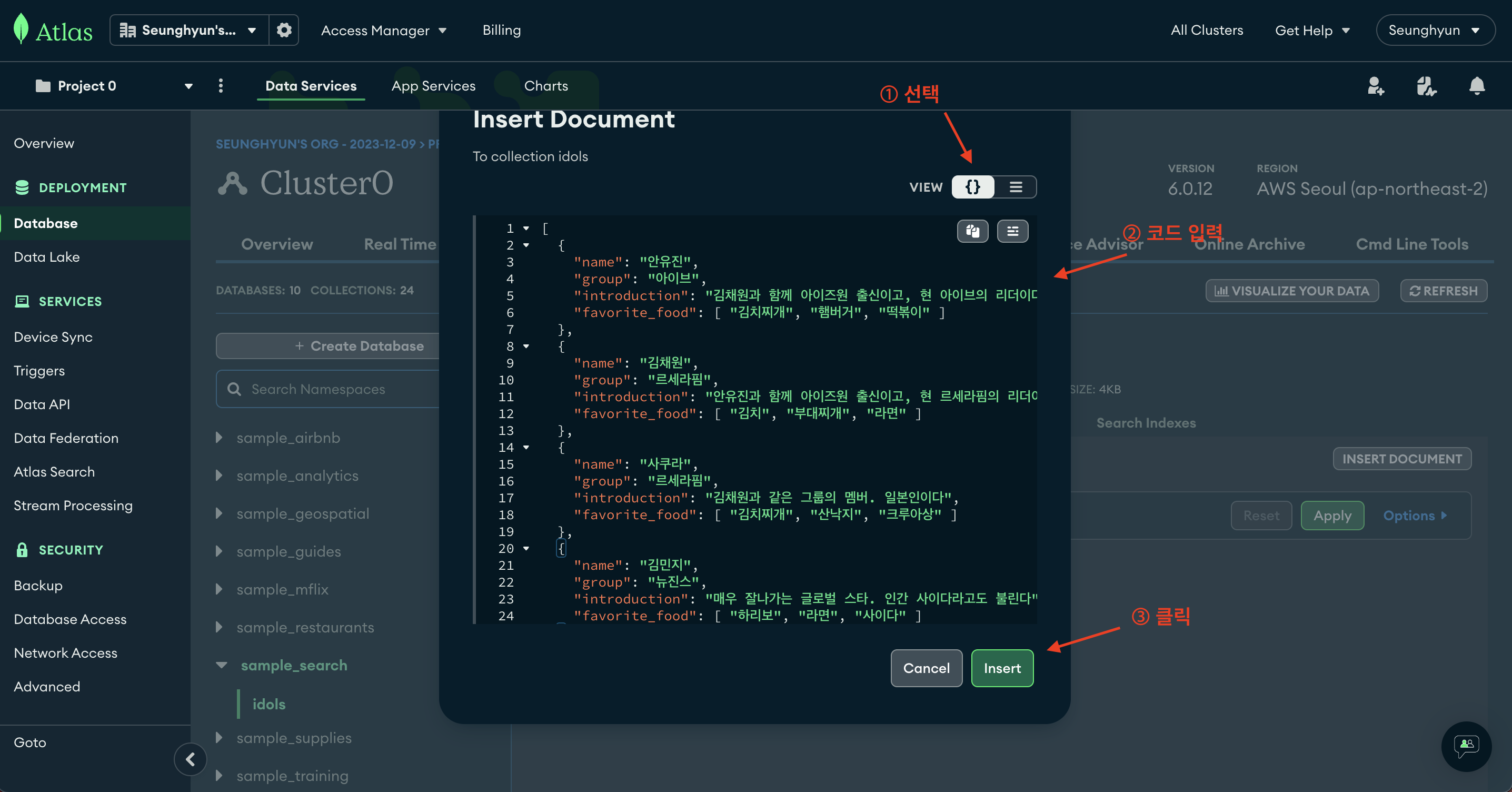
- 우측 상단에 VIEW 를
{}로 선택 - 아래 JSON 코드 입력
- INSERT 버튼 클릭
[
{
"name": "안유진",
"group": "아이브",
"introduction": "김채원과 함께 아이즈원 출신이고, 현 아이브의 리더이다. 맑은 눈의 광인",
"favorite_food": [ "김치찌개", "햄버거", "떡볶이" ]
},
{
"name": "김채원",
"group": "르세라핌",
"introduction": "안유진과 함께 아이즈원 출신이고, 현 르세라핌의 리더이다. 별명은 쌈아치",
"favorite_food": [ "김치", "부대찌개", "라면" ]
},
{
"name": "사쿠라",
"group": "르세라핌",
"introduction": "김채원과 같은 그룹의 멤버. 일본인이다",
"favorite_food": [ "김치찌개", "산낙지", "크루아상" ]
},
{
"name": "김민지",
"group": "뉴진스",
"introduction": "매우 잘나가는 글로벌 스타. 인간 사이다라고도 불린다",
"favorite_food": [ "하리보", "라면", "사이다" ]
}
]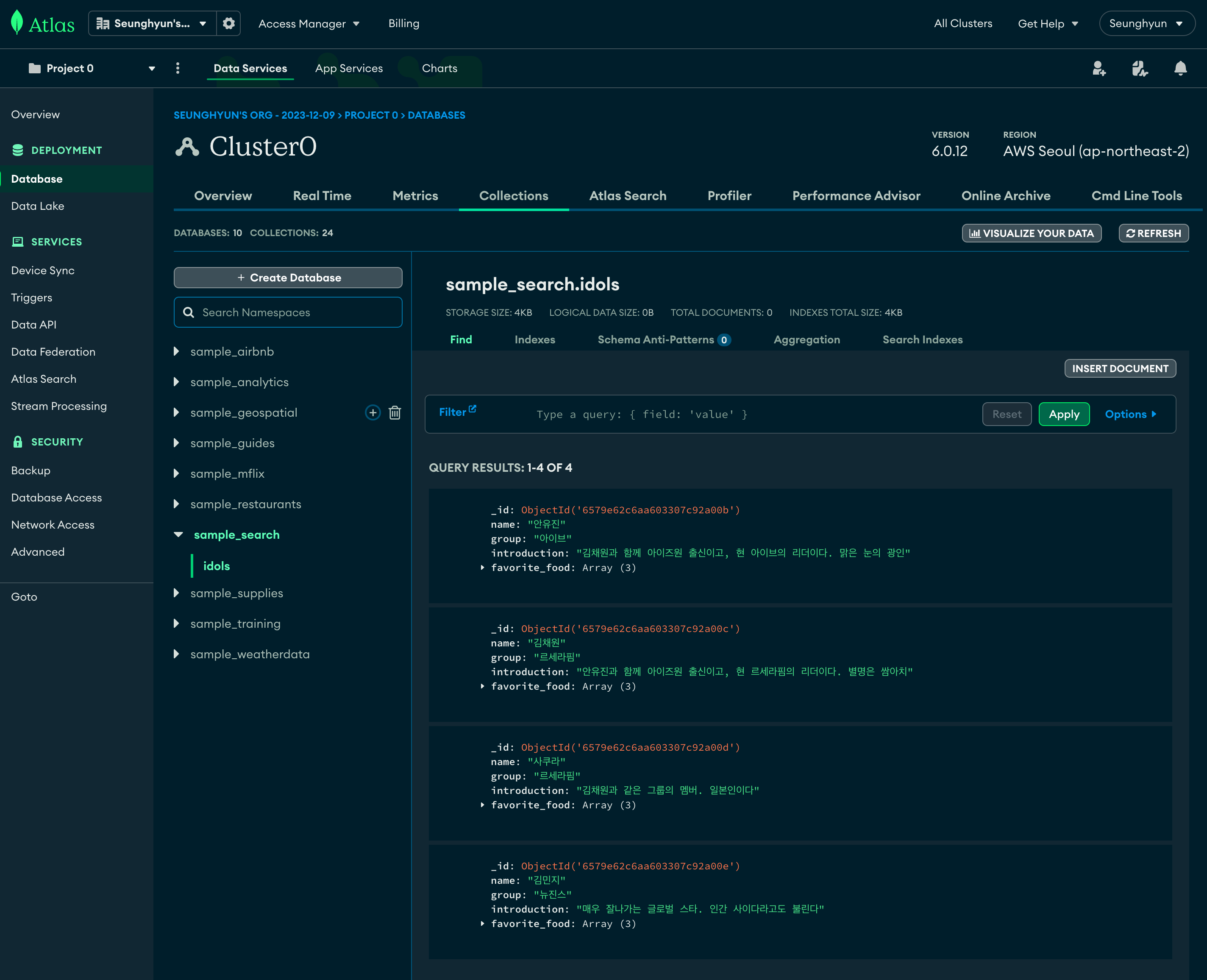
준비한 Document 들이 잘 들어갔습니다.
2. Atlas 에서 Search Index 만들기
MongoDB 에서 검색을 하려면 Search Index 를 먼저 설정해주어야 합니다.
Atlas 에서 Search Index를 설정하겠습니다.
좌측 메뉴바에서 Atlas Search를 클릭해서 설정 화면으로 진입합니다
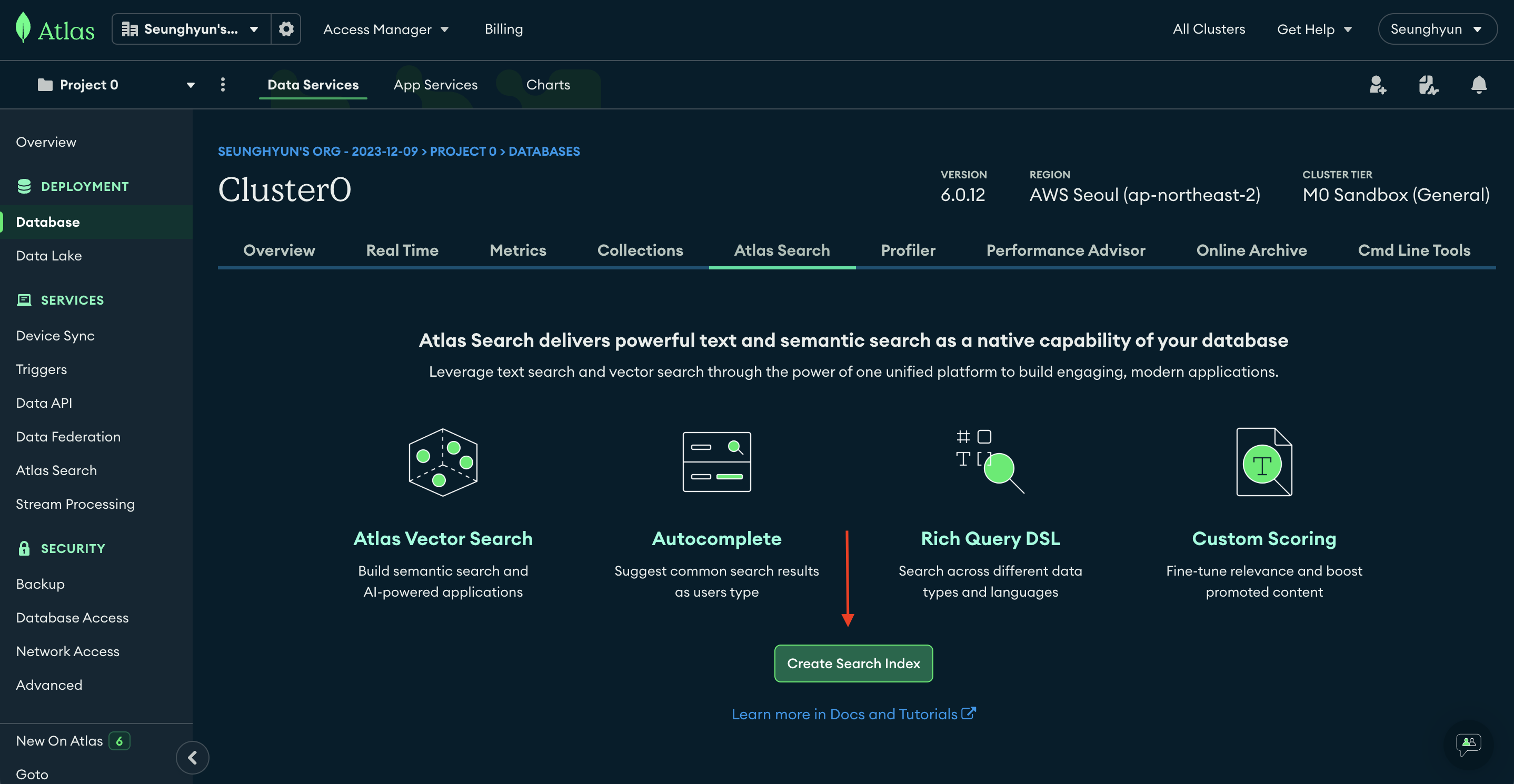
위 화면이 나오면 잘 들어오신건데요, 나중에 Search Index를 만들면 Overview 화면이 나오게 될 겁니다.
참고로 M0 tier (무료 플랜)에서는 Search Index를 최대 3개까지 만들 수 있습니다.
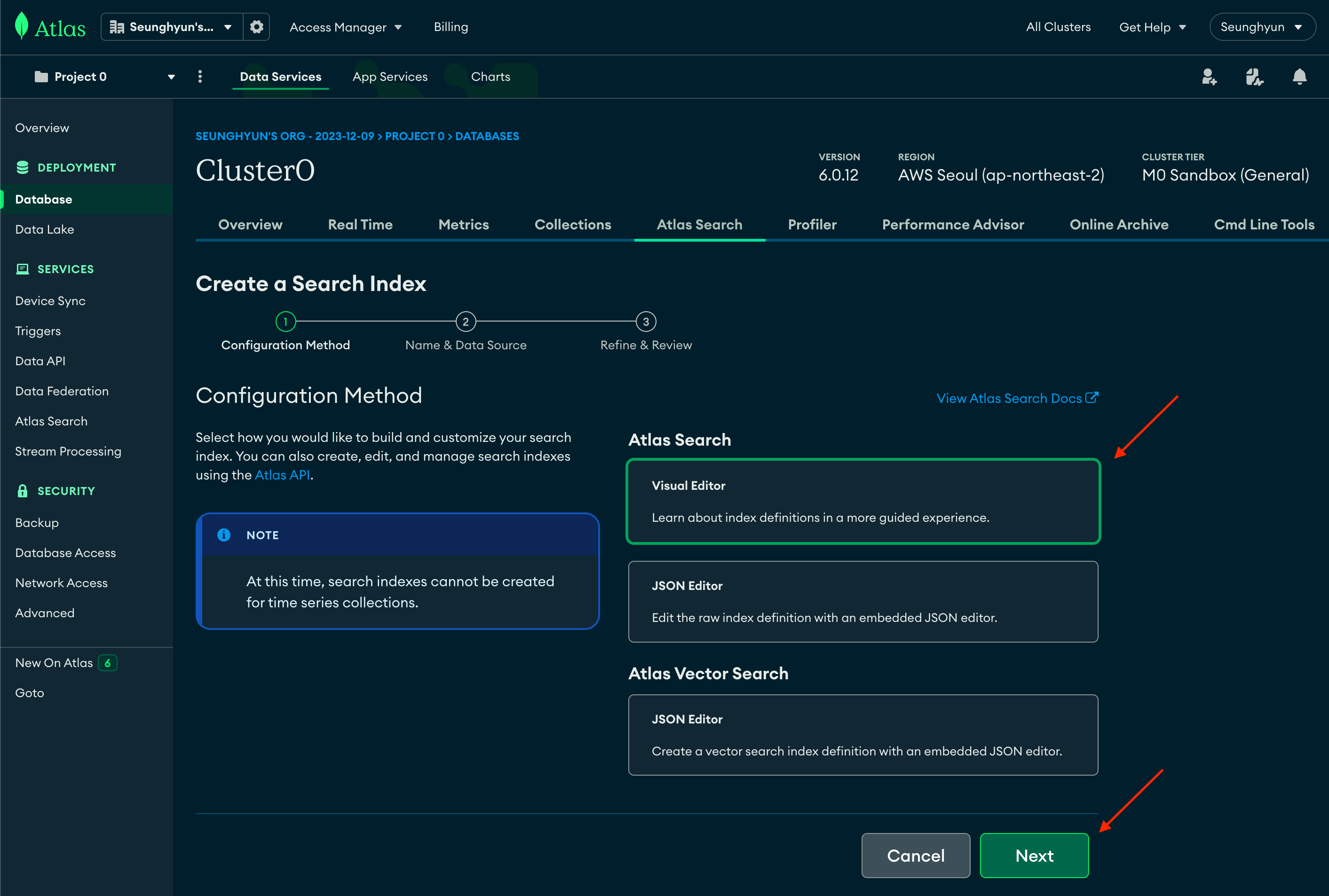
Configuration Method 설정을 해줘야 하는데 저희는 보기 편하게 Visual Editor를 선택하겠습니다.
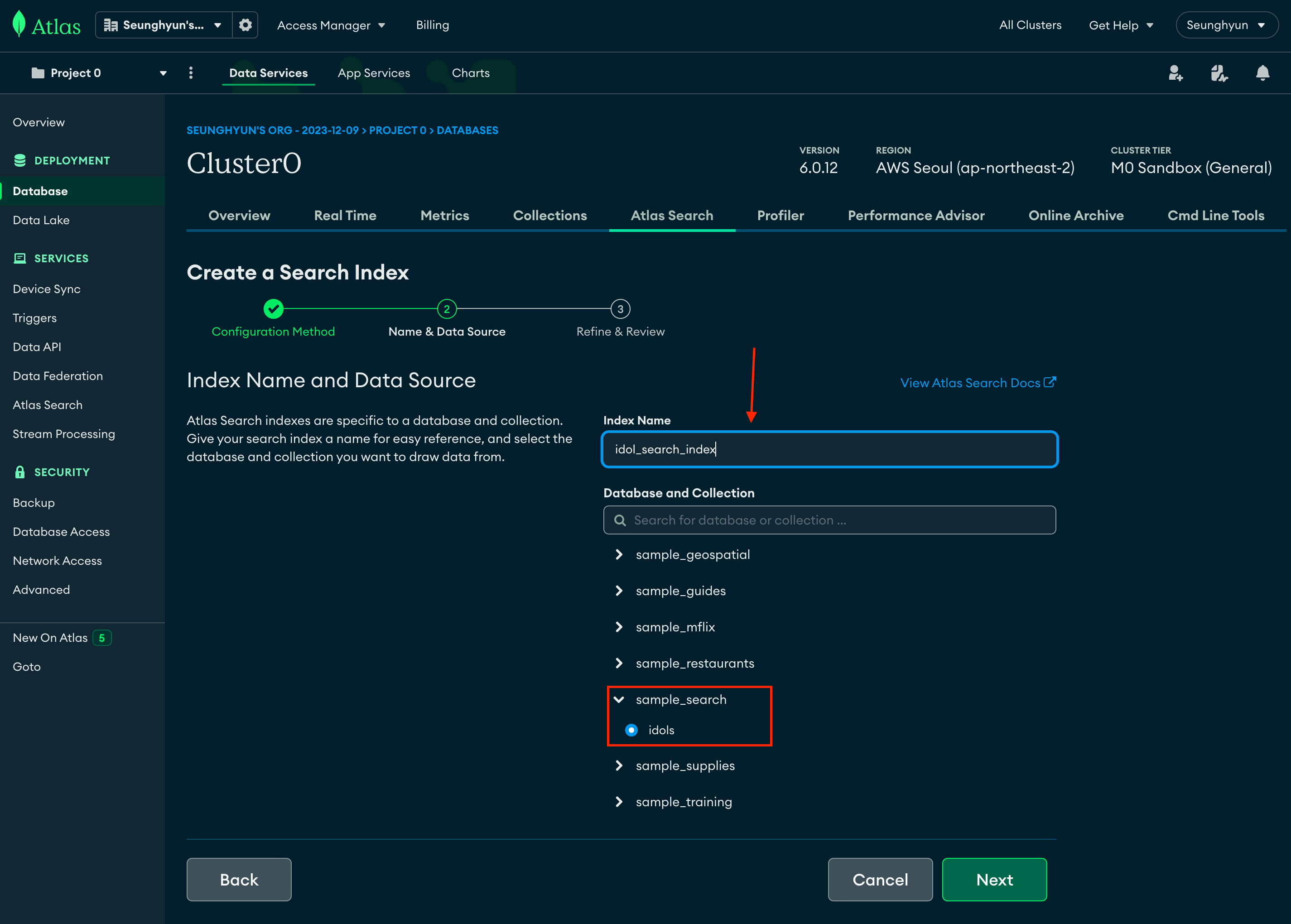
Index Name을 자유롭게 정해주시면 됩니다.
되도록이면 명칭을 보고 의미를 유추할 수 있도록 짓는 것이 좋기 때문에 저는 idol_search_index 로 짓겠습니다.
그리고, index를 적용시킬 컬렉션을 선택해주고
Next 버튼 클릭
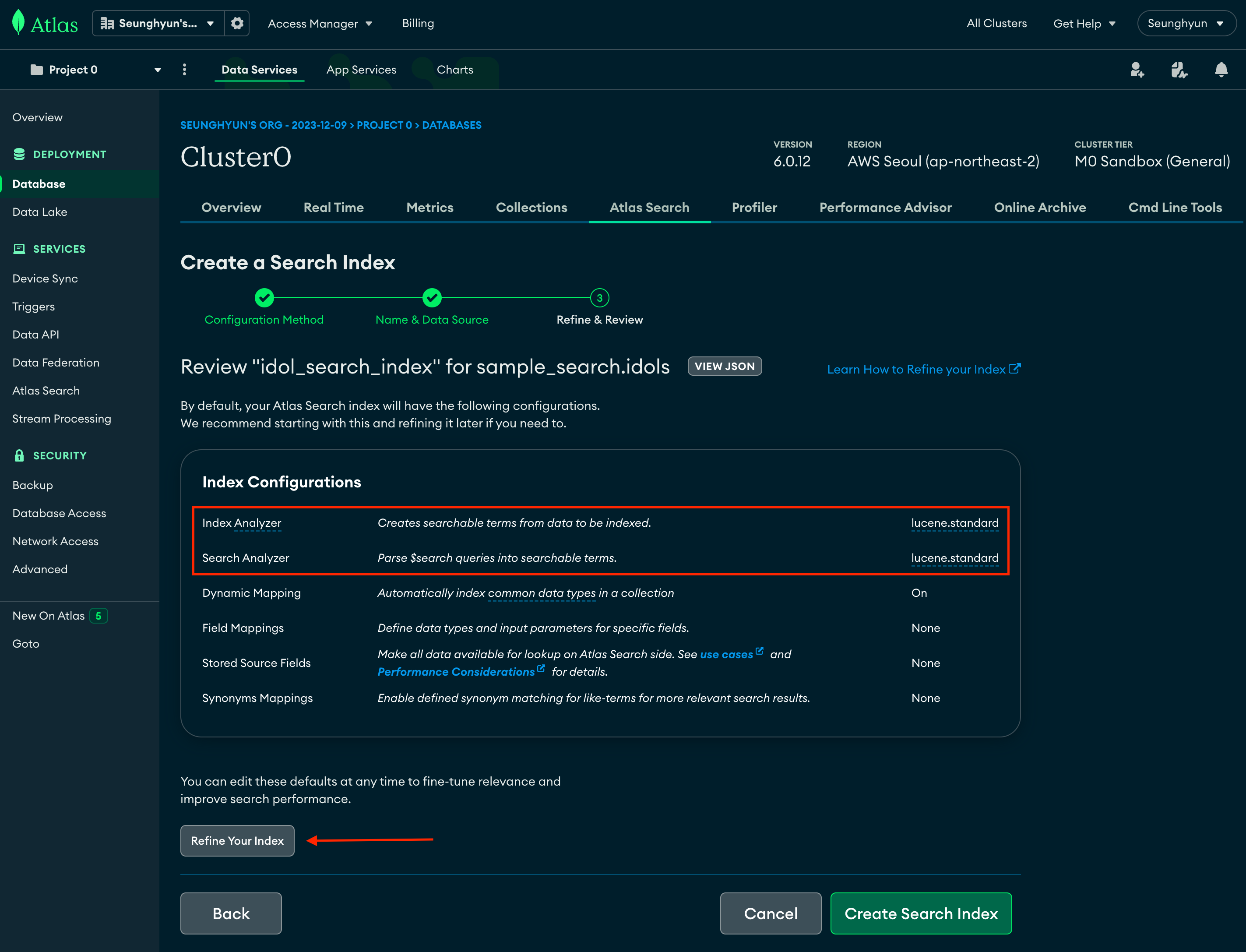
지금 보시면 default 값으로 Index Analyzer와 Search Analyzer가 lucene.standard로 되어 있는데요,
저 Analyzer가 검색어를 입력 받았을 때, 그 검색어를 분석해서 Querying 하도록 도와주는 엔진 역할입니다.
그치만 저 lucene.standard는 한글을 제대로 분석해주지 못하기 때문에 한글 전용 엔진으로 바꿔주겠습니다.
Refine Your Index 버튼을 클릭해서 설정 화면으로 이동
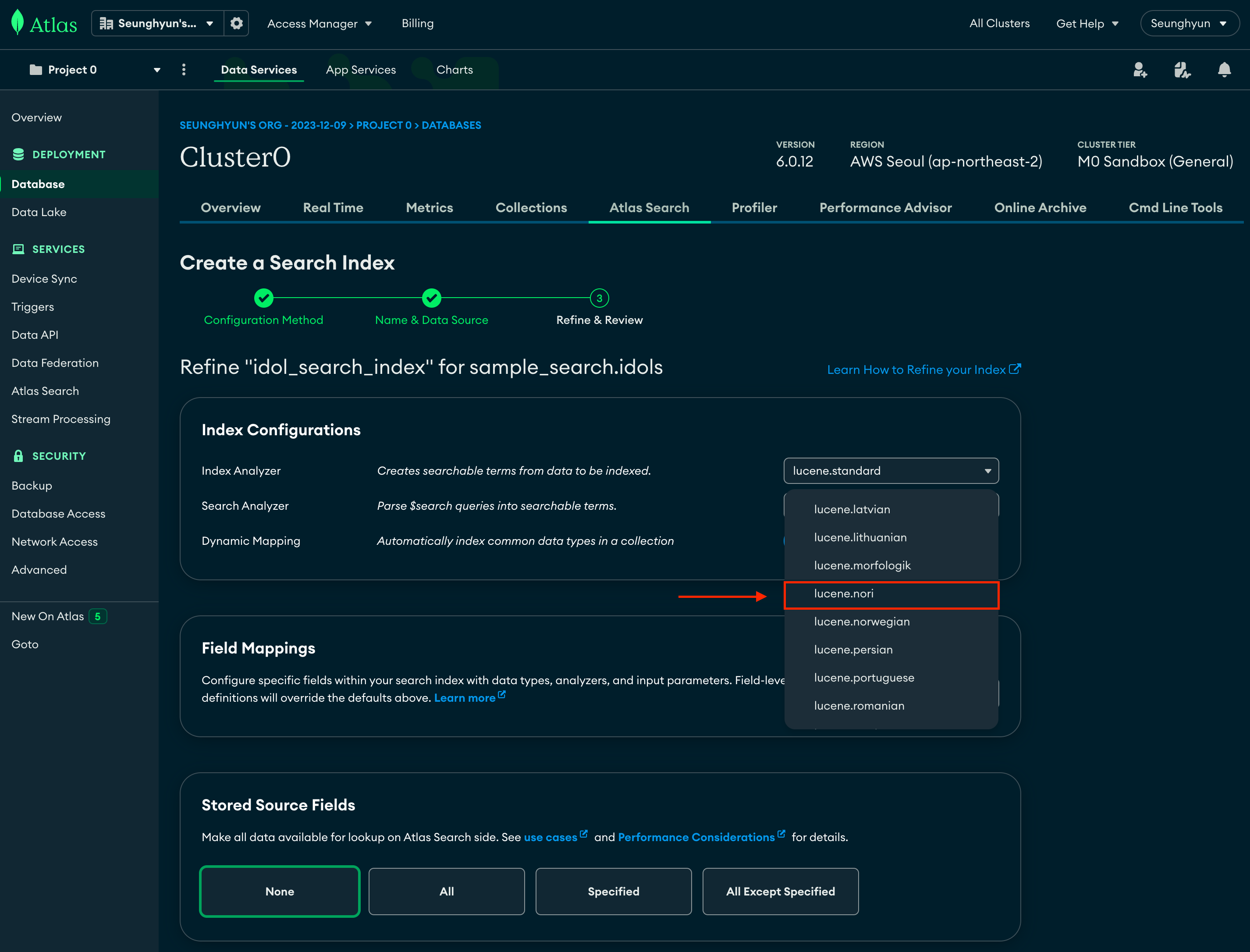
Index Analyzer와 Search Analyzer 를 lucene.nori 로 변경해 줍니다.
lucene.nori 는 한글 형태소 분석기로 현 최대의 검색엔진인 Elastic Search에서 공식적으로 개발해서 지원하고 있습니다.
lucene.standard 와의 차이점을 예시를 통해 보여드리자면,
똑같이 "동해물과 백두산이" 라고 검색을 한다면
- lucene.standard
→ "동해물과", "백두산이" - lucene.nori
→ "동해", "물", "과", "백두", "산", "이"
이렇게 형태소를 파악하고 분리해서 단어를 쪼개는데, 이때 쪼개어진 하나 하나의 객체를 "token" 이라고 하며
이 토큰으로 Querying 을 해서 데이터를 가져오게 됩니다.
나머지 Search Index 설정은 기본으로 두고, Save Changes 버튼 클릭해서 설정을 저장해주겠습니다
그리고 Create Search Index 버튼을 클릭해서 Search Index 생성
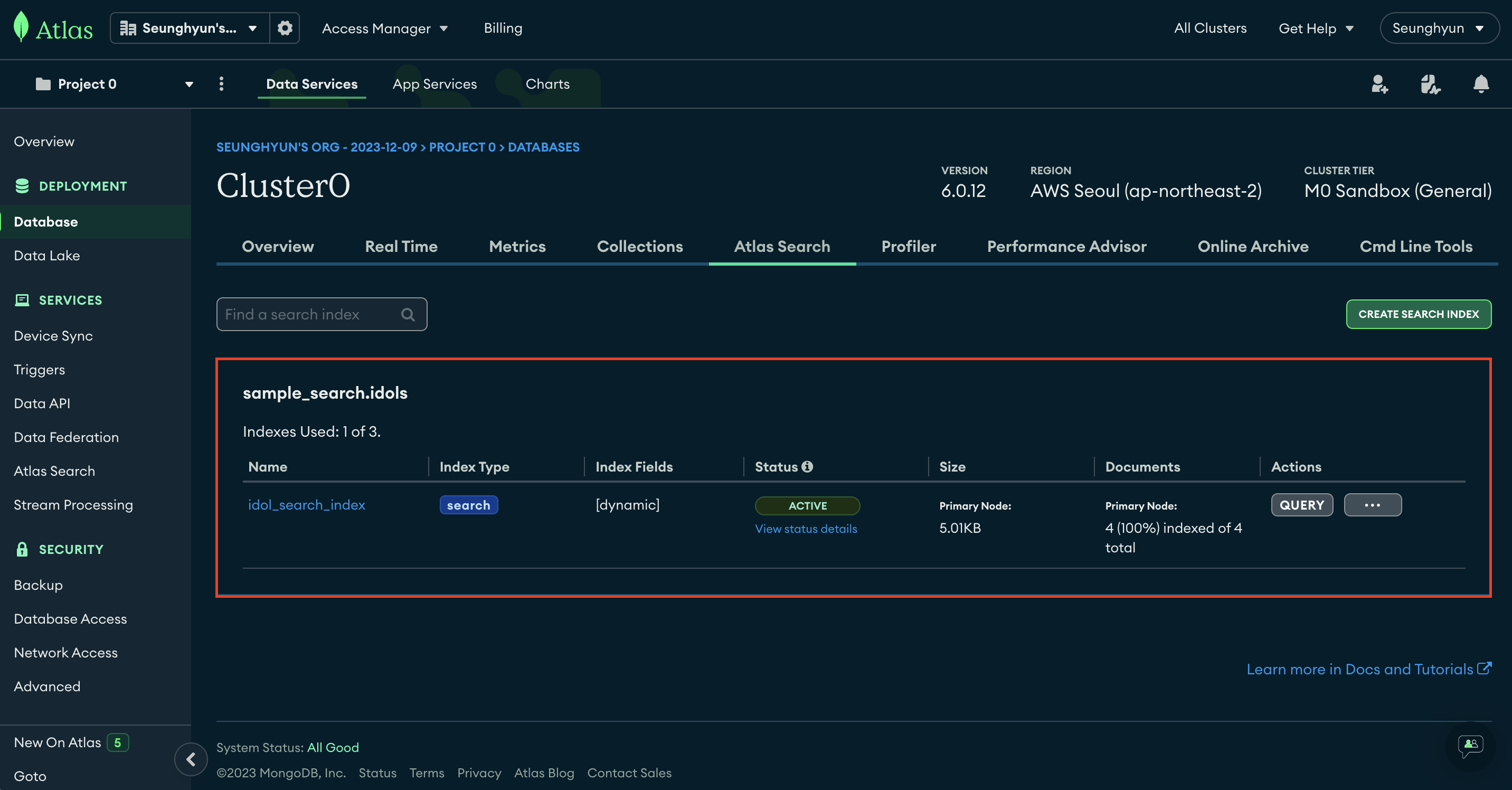
Index를 생성하는데 30초 정도 소요가 됩니다.
시간이 지나면 Search Index가 잘 생성된 것을 볼 수 있습니다.
3. NestJS 프로젝트 생성
저희는 NodeJS 환경에서 MongoDB를 연동해서 간단한 검색 API를 구축해볼건데요,
TypeScript 기반의 NestJS 프레임워크를 통해 구축해보겠습니다.
이 포스트의 주제는 MongoDB Atlas Search 이기 때문에 NestJS 에 대해서는 자세히 다루지 않겠습니다.
NestJS 를 처음 접하시거나 초보자 분들은 잘 이해가 안되시더라도 우선 따라오시길 바랍니다.
NestJS 에 대해서는 나중에 제대로 설명하는 별도의 포스트를 작성하겠습니다.
먼저 NestJS 설치를 하겠습니다.
터미널을 열고
npm i -g @nestjs/cli잘 설치가 되었는지 확인해봅니다.
아래 커맨드를 쳤을때 버전 정보가 잘 나오면 설치가 잘 된겁니다
nest -v설치가 다 되었으면, cd 커맨드로 NestJS 프로젝트를 생성할 폴더로 이동하셔서
프로젝트를 생성해줍니다.
저는 mongodb_search 라는 이름으로 NestJS 프로젝트를 생성하겠습니다.
nest new mongodb_searchpackage manager 를 선택하라는 요청이 뜨면 npm을 골라줍니다
여기까지 하시면 NestJS 프로젝트가 잘 생성이 되셨을텐데요,
새로 만드신 프로젝트에 들어가셔서 VSCode 를 띄우겠습니다
cd mongodb_search
code .제 terminal 기록을 보여드리겠습니다.
이제부터는 VSCode 에서 작업을 하겠습니다.
계속해서 터미널에서 NestJs CLI 명령어로 idol 이라는 resource를 생성해주겠습니다
nest g res idol
? What transport layer do you use? REST API
? Would you like to generate CRUD entry points? No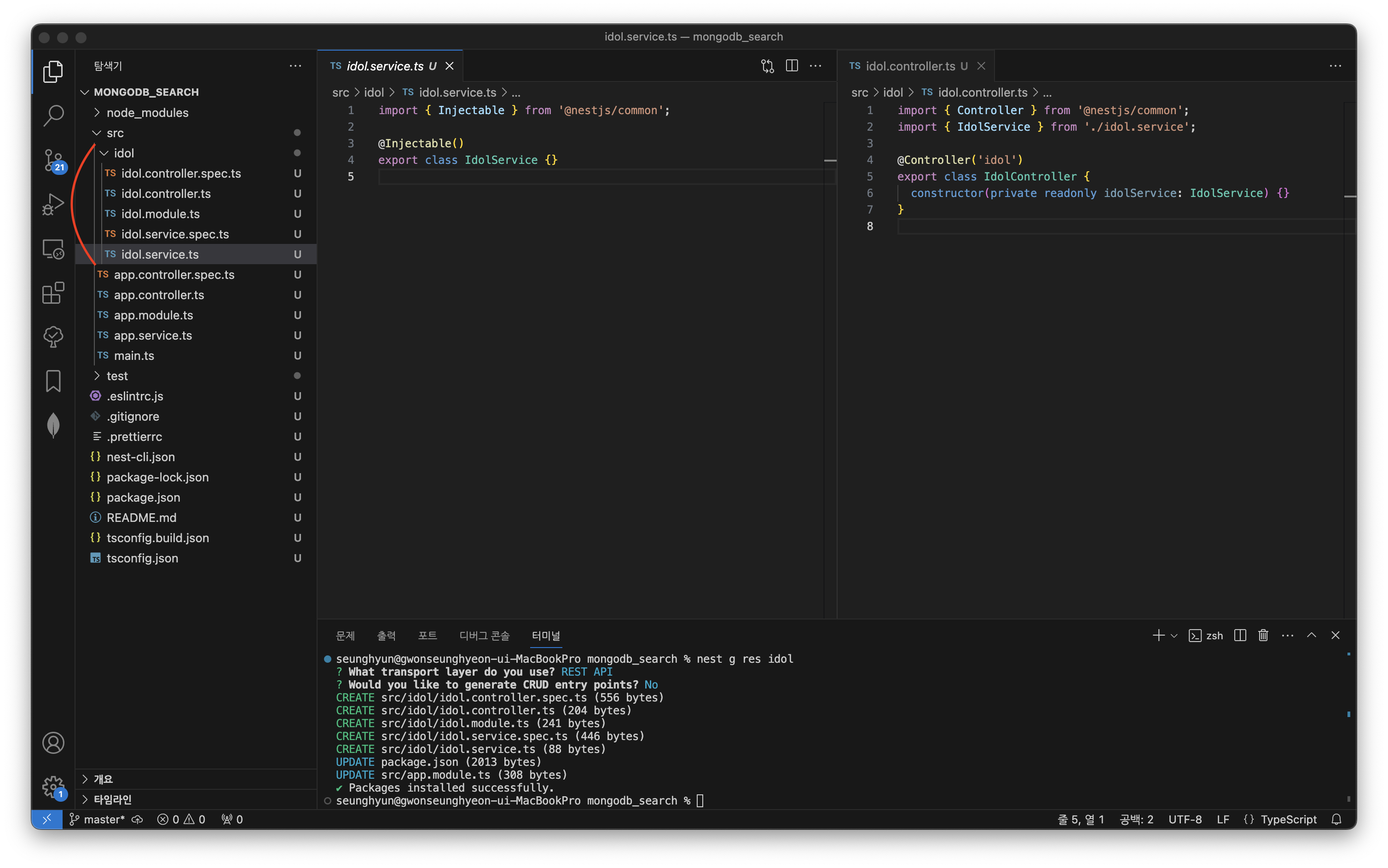
src 폴더 아래에 idol 폴더가 생성되고 그 안에 5개의 파일이 들어가 있는 것을 볼 수 있습니다. 이 하나의 구성이 한 묶음이며 resource 라 부릅니다.
controller.spec.ts : 테스트용
controller.ts : 라우팅 역할 ⭐️
module.ts : 각 파일들을 사용할 수 있게 연결해주는 역할
service.spec.ts : 테스트용
service.ts : function들 모음 ⭐️
오늘은 idol.controller.ts 와 idol.service.ts 만으로 간단하게 검색 API만 만들어보겠습니다.
4. MongoDB client 환경 구축
terminal에서 npm 으로 MongoDB의 공식 nodejs 패키지인 mongodb 패키지를 설치해주겠습니다.
npm i mongodb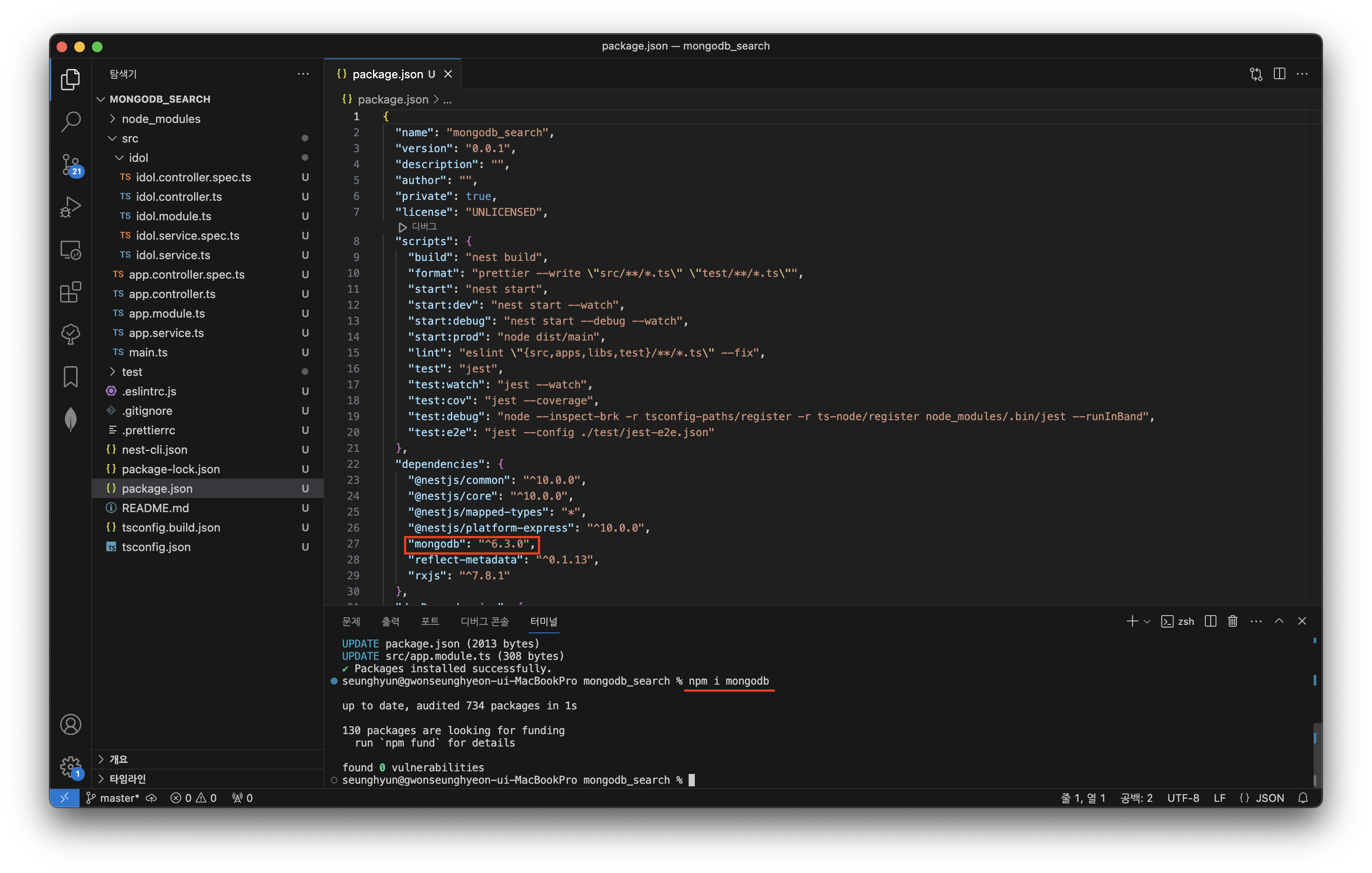
package.json 에서 잘 설치가 된 것이 확인됩니다.
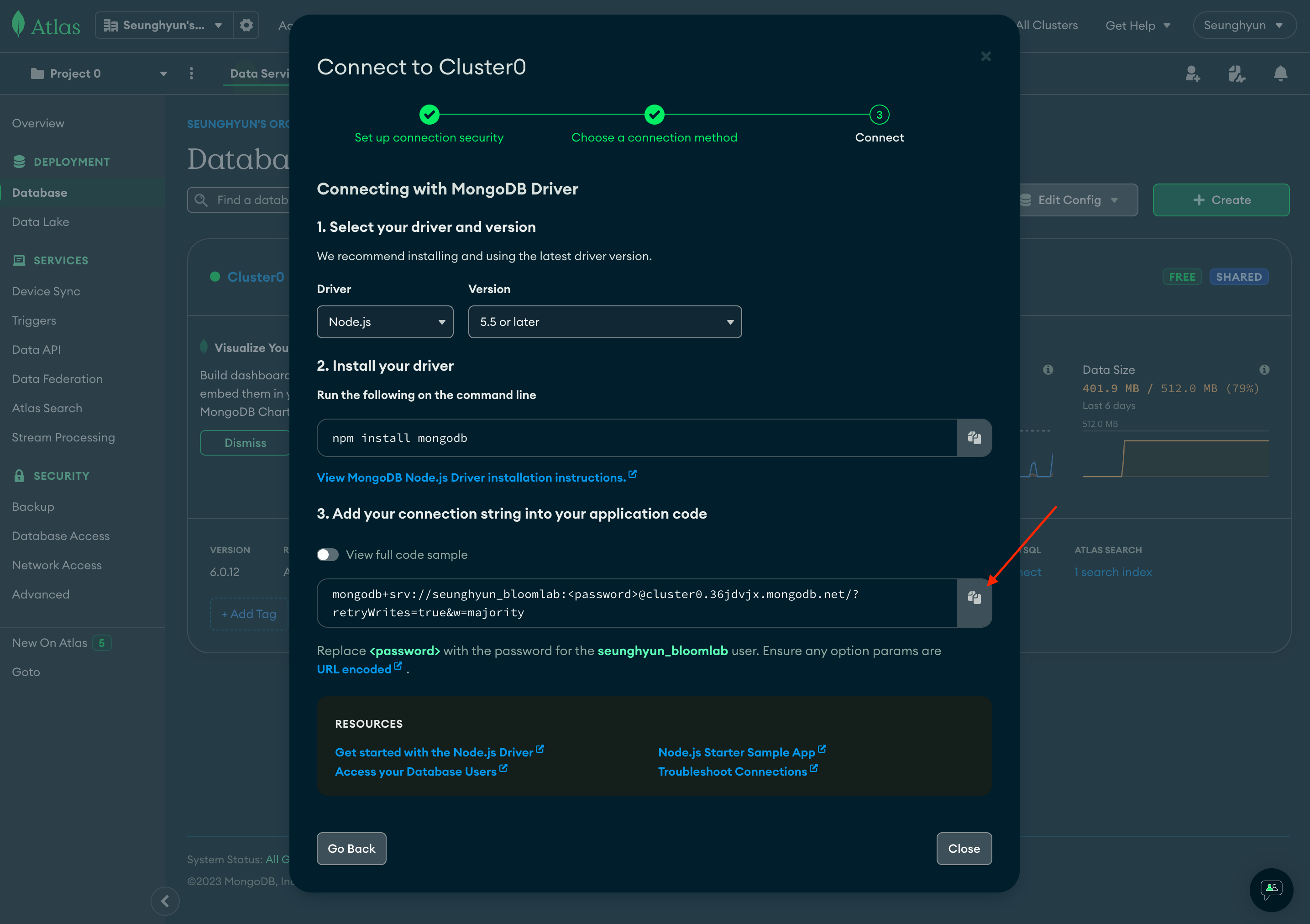
다음은 MongoDB의 Atlas로 이동하겠습니다
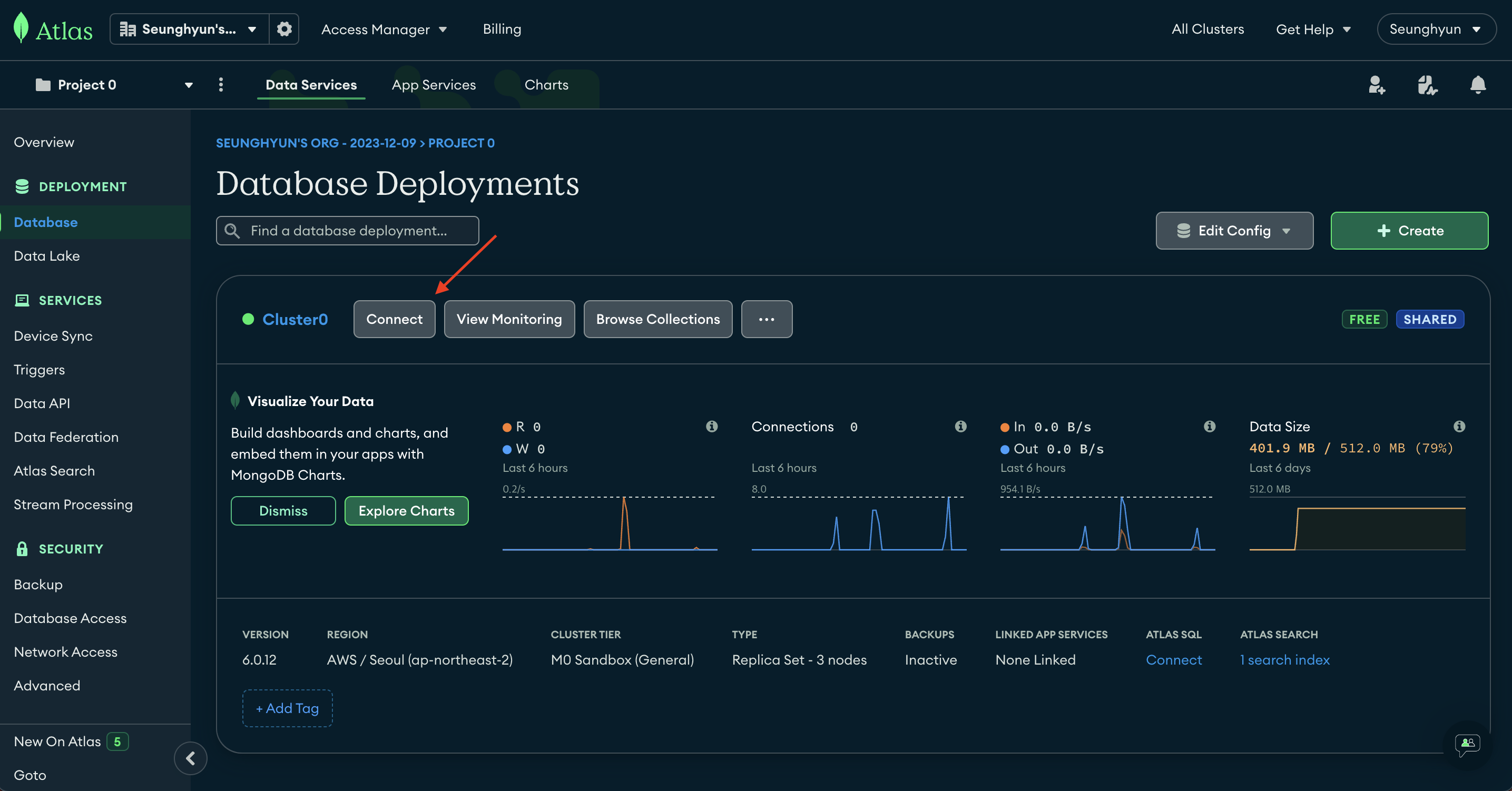
Connect 버튼 클릭
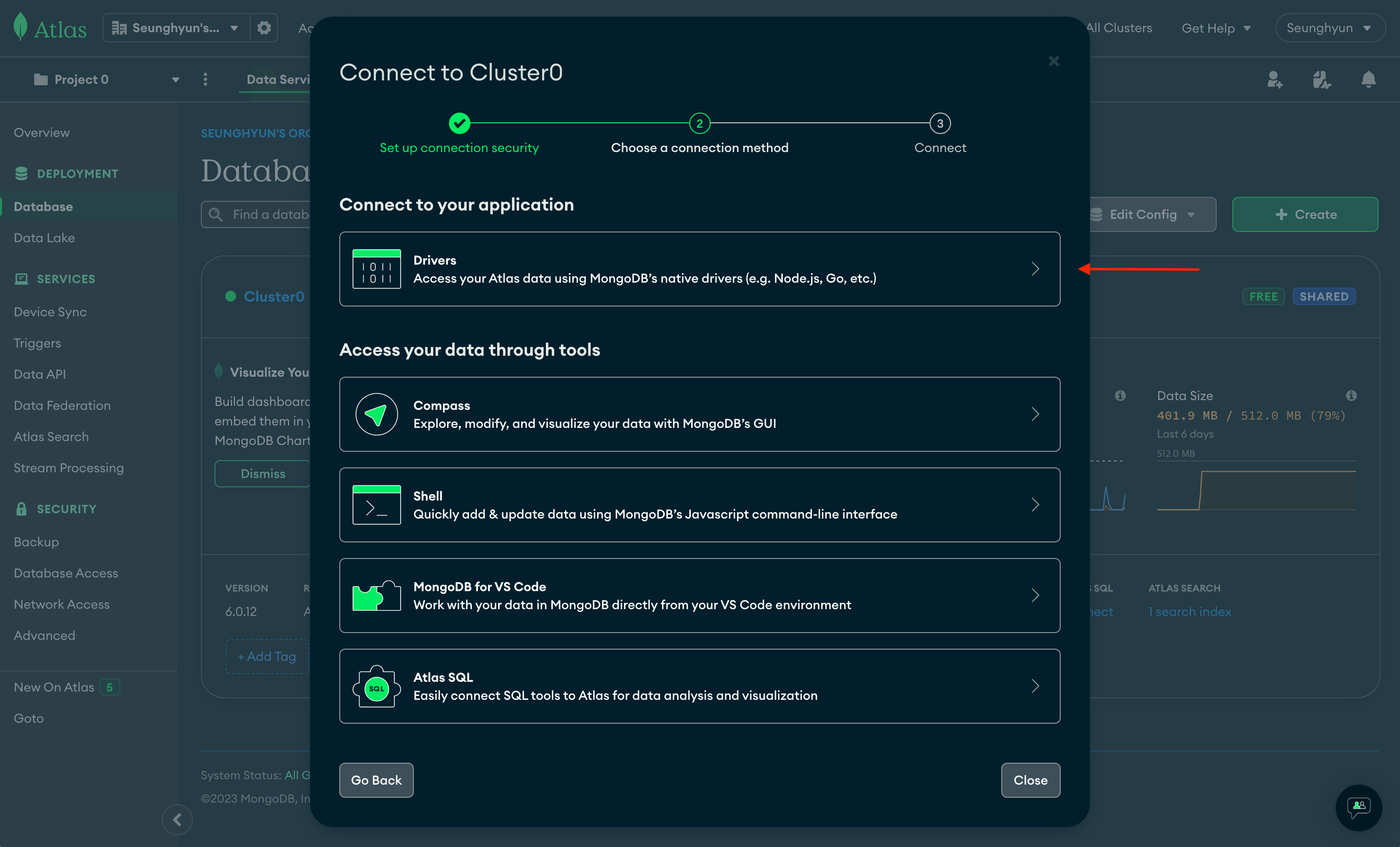
Drivers 클릭
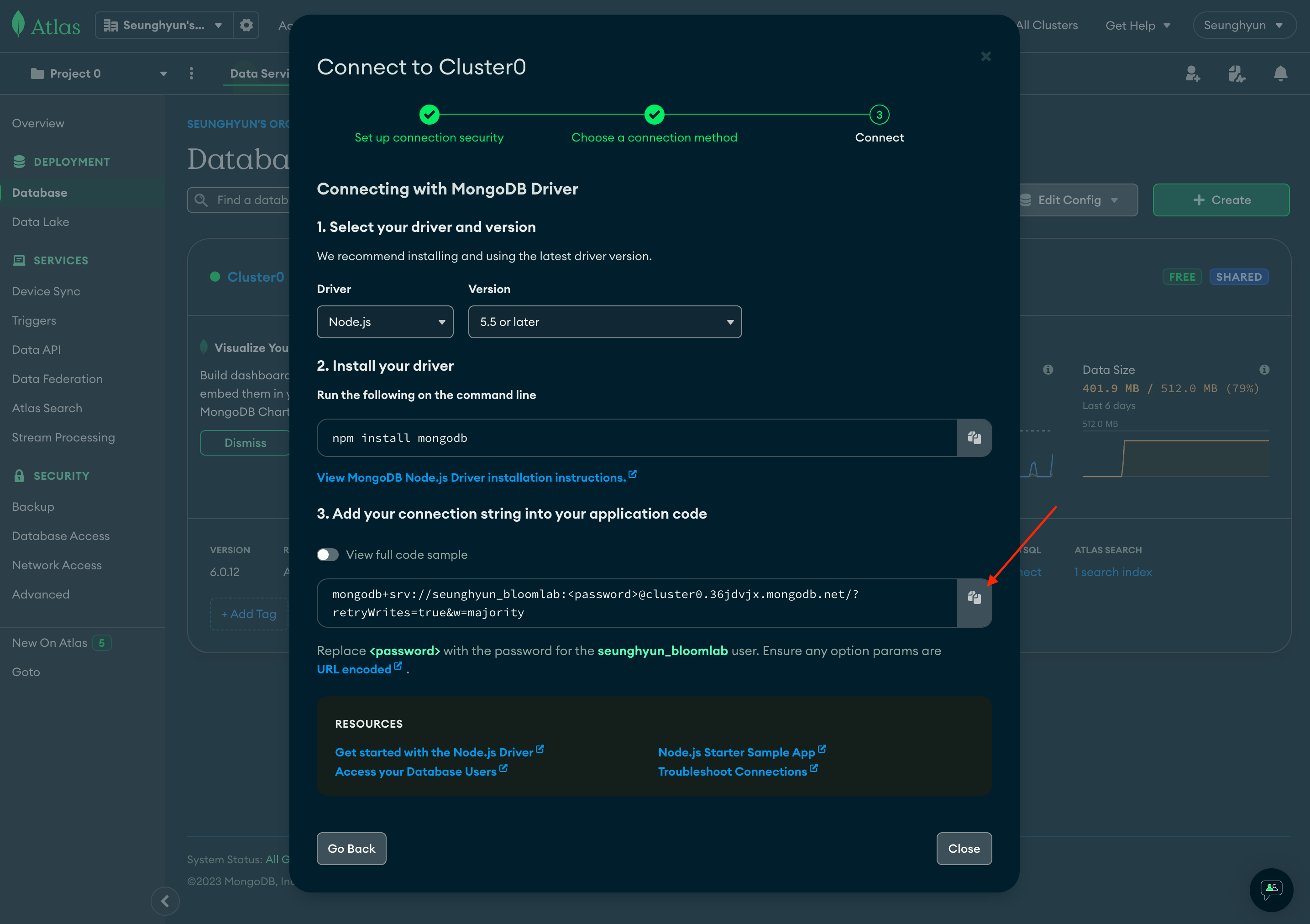
Connection String 복사하고 close 해줍니다
Connection String 이란 Atlas 외부(ex: nodejs, Compass ...)에서 MongoDB Cluster 에 연결하고자 할때
사용하는 String 형태의 연결 URI 입니다
참고: MongoDB 공식 홈페이지 - Introduction to MongoDB Connection Strings
5. aggregate search query 코드 작성
- idol.service.ts
import { Injectable } from '@nestjs/common';
import { MongoClient } from 'mongodb';
@Injectable()
export class IdolService {
searchIdols(searchValue: string): Promise<object[]> {
const connectionString = 'mongodb+srv://seunghyun_bloomlab:(여기에 비밀번호를 입력)@cluster0.36jdvjx.mongodb.net/?retryWrites=true&w=majority';
const mongoClient = new MongoClient(connectionString);
const idolCollection = mongoClient.db('sample_search').collection('idols')
return idolCollection.aggregate([
{
$search: {
index: 'idol_search_index', // 사용할 search index 의 index명 입력
compound: { // 다중 조건 Querying 할 때 쓰는 operator
should: [
{
text: {
query: searchValue,
path: "name",
score: { constant: { value: 10 } }, // 이름에 검색어가 있으면 10점
},
},
{
text: {
query: searchValue,
path: "gruop",
score: { constant: { value: 5 } }, // 그룹명에 검색어가 있으면 5점
},
},
{
text: {
query: searchValue,
path: "introduction",
score: { constant: { value: 3 } }, // 소개글에 검색어가 있으면 3점
},
},
{
text: {
query: searchValue,
path: "favorite_food",
score: { constant: { value: 1 } }, // 최애음식 목록에 검색어가 있으면 1점
},
},
],
minimumShouldMatch: 1, // 최소 하나는 일치해야 리턴
},
},
},
{
$project: { // 표시할 데이터 정의 (1 이면 보이고, 0이면 보이지 않음)
_id: 0,
name: 1,
group: 1,
introduction: 1,
favorite_food: 1,
score: { $meta: "searchScore" }
},
},
]).toArray();
}
}
제가 주석 단 부분을 집중해서 보시면 각 필드별로 검색어가 있으면 미리 정의한 점수를 부여하고 이를 합산해서 점수가 높은 순서대로 나오도록 코드를 작성했습니다.
- idol.controller.ts
import { Controller, Get, Param } from '@nestjs/common';
import { IdolService } from './idol.service';
@Controller('idol')
export class IdolController {
constructor(private readonly idolService: IdolService) { }
@Get('search/:value')
search(@Param('value') searchValue: string): Promise<object[]> {
return this.idolService.searchIdols(searchValue);
}
}controller.ts 는 NestJS 프레임워크에서 API의 라우팅을 담당합니다.
위 API의 path는 localhost:3000/idol/search/(검색어를 여기에 입력) 이렇게 형성되게 됩니다.
참고로 favorite_food 필드의 타입이 Array 라서 text operator 대신 in 을 써야 하는 것 아닌가 생각이 들 수 있는데요
그럴 필요없이 text 를 써주시면 됩니다
in 을 썼을 때에는 오히려 에러 발생 :
This analyzer is expected to produce exactly one token, but got many
6. 검색 API 테스트
이제 검색 API가 완성되었으니 서버를 run 하고 검색어를 입력해서 테스트를 해보겠습니다
npm run start:dev서버가 잘 실행이 되었다면 이제 API 테스트를 해볼건데요,
Postman 을 이용해서 테스트를 해보겠습니다
Postman 이 설치되지 않으신 분들은 크롬 브라우저에서 테스트를 하셔도 무방합니다.
자 그럼 Postman 을 열고 테스트를 시작해보겠습니다.
6-1 [테스트] 필드별 가중치 부여
[GET] http://localhost:3000/idol/search/김채원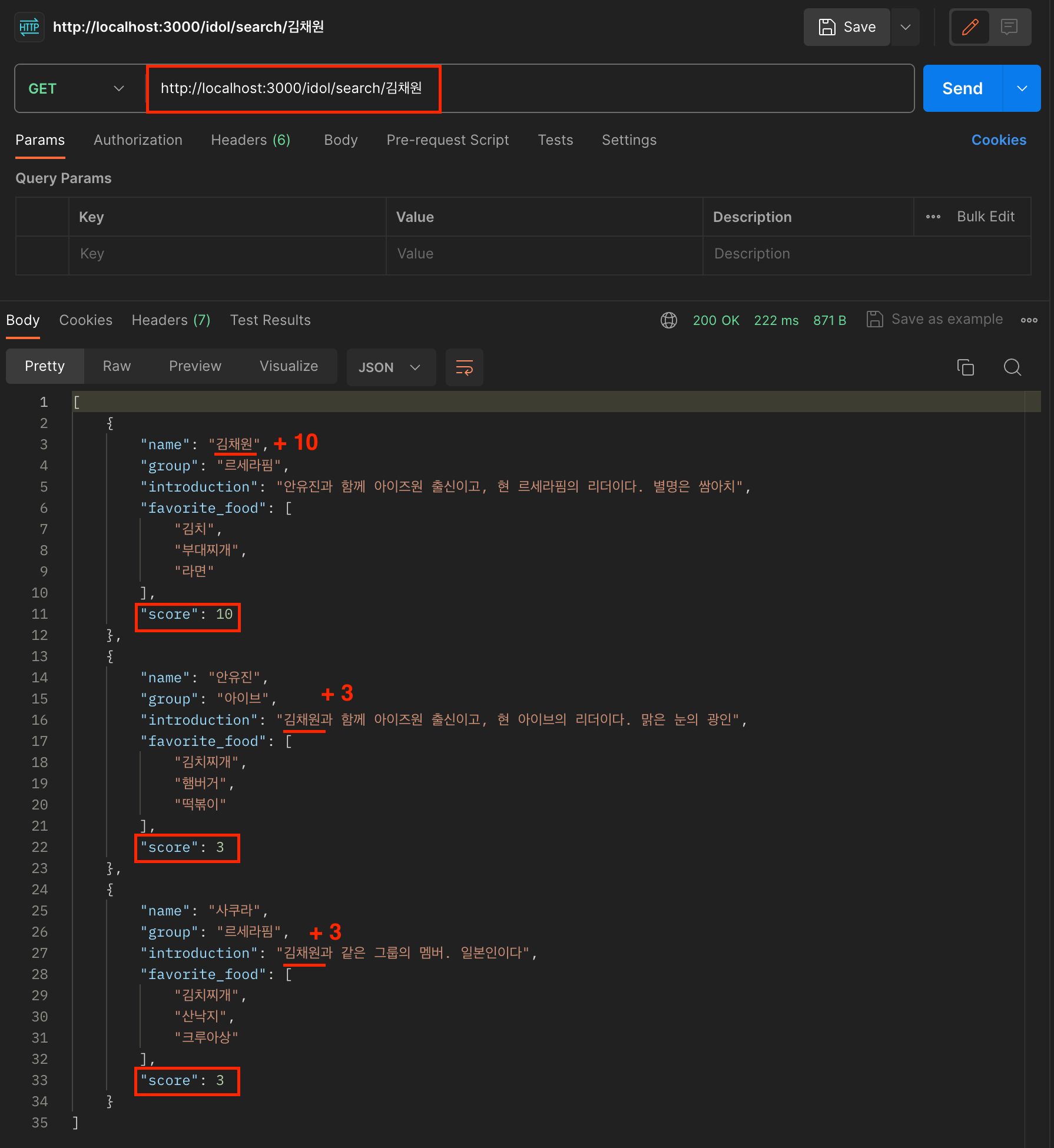
"김채원" 을 검색했더니 결과가 위와 같이 나왔습니다.
아까 idol.service.ts 에서 필드별로 스코어를 정의해서 검색 결과가 나오게끔 코드를 작성했었는데요,
name : 10 점
group : 5 점
introduction : 3 점
favorite_food : 1 점
으로 검색어가 각 필드에서 찾아지면 스코어를 부여하고 이를 합산해서 높은 순서대로 데이터를 넘겨받게 됩니다.
6-2 [테스트] 한글 형태소 분석
[GET] http://localhost:3000/idol/search/맑은김치를 좋아하는 사쿠라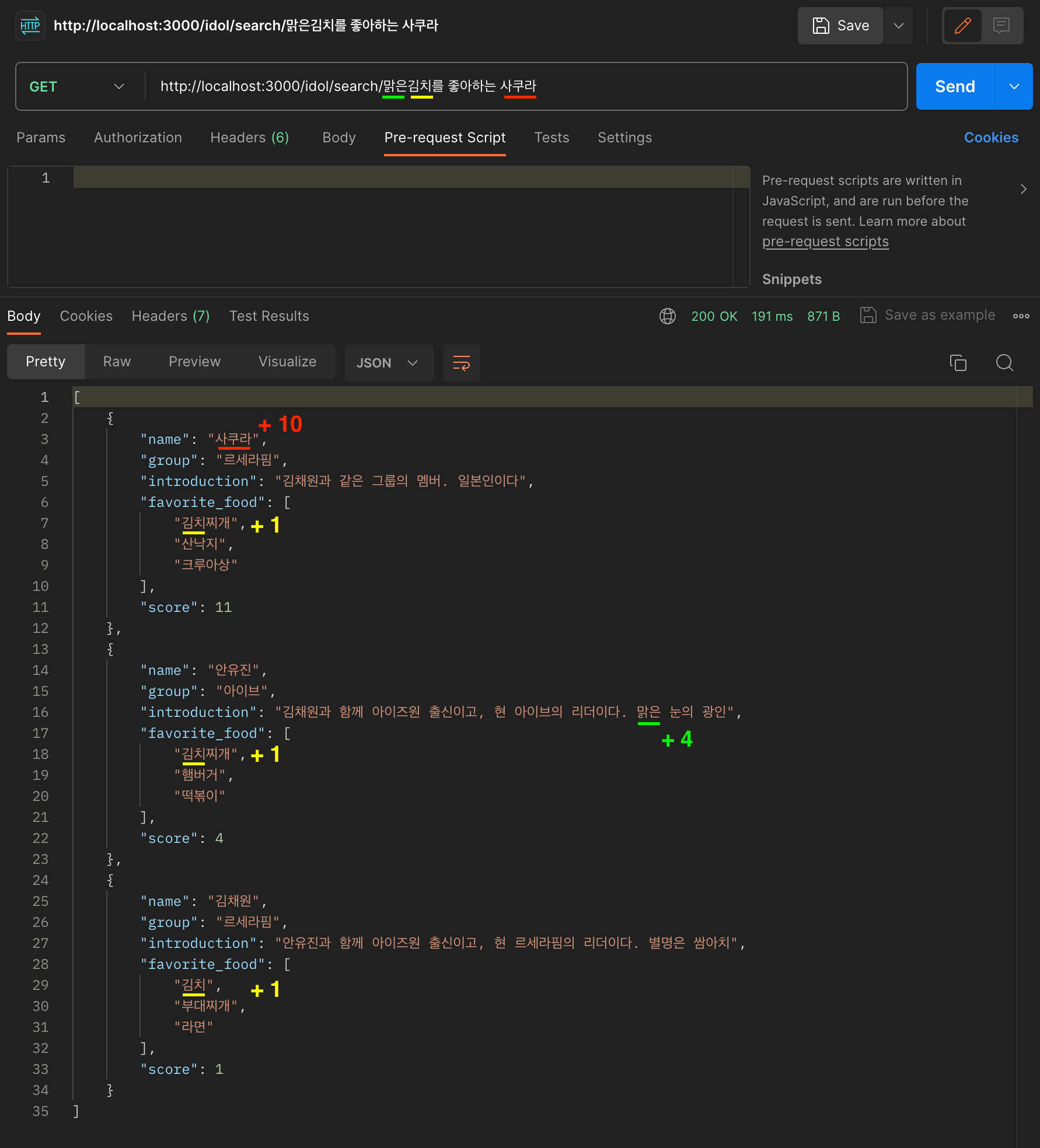
지금 첫째로 보실 포인트는 lucene.nori 가 제 검색어 "맑은김치를 좋아하는 사쿠라" 를 형태소 분석하여
여러개의 낱말(token)으로 쪼갠 뒤 색을 진행했다는 것인데요.
심지어 "맑은김치" 는 중간에 띄어쓰기도 안했는데 분석해서 토큰으로 나눴습니다
- before
"맑은김치를 좋아하는 사쿠라"- after
["맑은", "김치", "좋아", "사쿠라"]
두번째 포인트는 "김치" 라는 낱말로 "김치찌개"를 찾았다는 점입니다.
이는 검색어가 꼭 필드값에 완전히 일치하지 않아도 검색이 된다는 것을 뜻합니다.
마치며
이 포스트는 MongoDB 의 Atlas Search 가 이 정도 퀄리티의 검색 기능도 제공한다는 점을
알려주기 위해 작성되었습니다.
회사에서나 개인적으로 프로젝트를 기획하고 설계하다 보면 매번 DB를 어디에 둘까를 고민하게 되는데요
그런 고민에 있어서 제 포스트를 통해 MongoDB도 고려 선상에 들게 된다면 보람찰 것 같습니다.
저 같은 경우는 앱 개발 프로젝트를 진행하면서
비용과 관리의 효율성을 이유로 Serverless로 DB를 구축하고자 하였는데요
MongoDB의 Serverless 는 2가지의 이유로 인해 메인 DB로 쓰기엔 맞지 않았고
- Atlas Search를 제공하지 않음
- 한국 Region을 지원하지 않음 (가장 가까운 Region은 싱가포르)
결국 Firebase의 Cloud Firestore를 메인 DB 로 두고, 검색 부분만 MongoDB로 쓰고 있습니다.
이상으로 포스트를 마치겠습니다.
궁금한 점이 있거나 오류를 발견하시면 댓글로 남겨주시면 감사하겠습니다 :)

글 잘 읽었습니다. 한 가지 궁금한게 있는데 마지막에 "맑은김치를 좋아하는 사쿠라"가 어떻게 토큰화되는지는 elastic search를 통해서 확인하신건가요?