Abstract
해당 논문에서 처음으로 Deep Neural Network를 사용해서 사람의 관절을 예측하는 모델을 제안하였습니다. DNN을 계단식으로 구성하여 점진적으로 오차를 수정해가면 4가지 벤치마크에서 SOTA 성능을 보였다고 주장합니다.
Introduction

사람의 관절을 찾는 문제는 컴퓨터 비전 분야에서 관심을 갖고 있습니다. 하지만 위의 그림과 같이 많이 변할 수 있는 관절, 거의 변하지 않는 관절, 가려진 부분, 그리고 개별 관절들간의 상호작용이 주된 문제로 제기되고 있습니다.
Human pose estimation 분야의 주된 목표는 사람이 취할 수 있는 모든 자세 공간을 찾는 것 이였습니다. 하지만 초기 연구들의 경우 특정 관절이나 자세에 대한 연구가 활발했고, 모든 관절에 대한 상호작용을 하지 못했다는 한계가 존재하였습니다. 이에 해당 논문에서는 최근에 발달한 DNN 구조를 활용하여 모든 관절들이 상호작용하는 holistic human pose estimation을 제안합니다.
단순히 7계층을 갖는 신경망을 통해서 각각의 관절을 Regression 형식으로 예측하게 됩니다. 이렇게 정식화된 모델을 사용함으로 써, 이미지 전체의 문맥을 파악할 수 있으며, 기존의 모델들 보다 매우 간단하게 모델을 설계할 수 있습니다. 추가로 Cascade 방식을 체택하여 점진적으로 해상돌들 높혀 정확도를 올리는 방식을 사용하였다고 제안하고 있습니다.
이러한 방식을 통해서 가지 벤치마크에서 높은 성능을 달성했음을 제안하고 있습니다.
Deep Learning Model for Pose Estimation
본 연구에는 아래와 수식을 통해서 각 (x,y) 좌표를 수식화 하고 있습니다.
그리고 해당 는 (x,y) 로 2개의 좌표값을 가지고 있습니다. 하지만 단순히 이미지 내에서 절대 좌표를 활용하게 되면 다른 이미지와의 관계를 파악하기 불리합니다. 그래서 본 논문에서는 이미지 내 사람을 감싸는 박스를 함께 제공하게 됩니다. 그리고 박스 내 존재하는 각 관절의 좌표를 정규화 하게 됩니다. 이를 통해서 모든 좌표값은 0 ~ 1 사이의 값을 갖도록 됩니다. 이를 통해서 모든 이미지들은 상대적 좌표를 활용하기에 모델이 관절 위치 패턴을 보다 쉽게 파악할 수 있도록 유도합니다. 이를 수식화 하면 아래와 같이 나타낼 수 있습니다.
위의 수식을 보면 간단하게 박스의 중심 좌표인 좌표를 뺴고, 박스의 높이, 너이로 나눠주어 정규화를 하게 됩니다. ( 행렬의 곱으로 좌표계의 기저 벡터 값의 크기를 줄이는 느낌으로 이해도 가능하다 )
Pose Estimation as DNN-based Regression
본 논문에서는 이를 간단한 regression 문제로 치환하여 해결하고자 합니다. 그래서 간단하게 DNN 함수를 도입하고 이를 통해서 최종 결과가 2k 만큼 나오도록 합니다. 모든 값들은 0 ~ 1 사이로 매핑되어 나오고, 추가로 역정규화 과정을 통해서 최종 좌표값을 얻을 수 있게 됩니다. 이를 수식으로 표현하면 아래와 같이 표현할 수 있습니다.
본 논문에서는 당시 높은 성능을 보인 AlexNet을 활용하였다고 합니다. 이미지의 경우 3채널을 활용하였다고 합니다.
그리고 모델을 학습하는 경우 모든 이미지 마다 박스 크기가 다르고 절대 좌표가 다르기 떄문에 상대좌표를 활용하였다고 합니다. 그래서 우선 손실을 구하기 전에 GT를 상대 좌표로 변환해주어야 합니다. 아래와 같이 실제 정답 또한 box 에 맞춰 상대 좌표로 변환해주게 됩니다.
그리고 이렇게 상대 좌표로 변환되었다면, 각 좌표가 실제 좌표와 가까워지도록 하기 위해서 을 최소화 하는 손실 함수를 설정하였다고 합니다.
학습의 경우에는 backpropagation을 활용하여 가중치를 업데이트 하였다고합니다.
Cascade of Pose Regressors
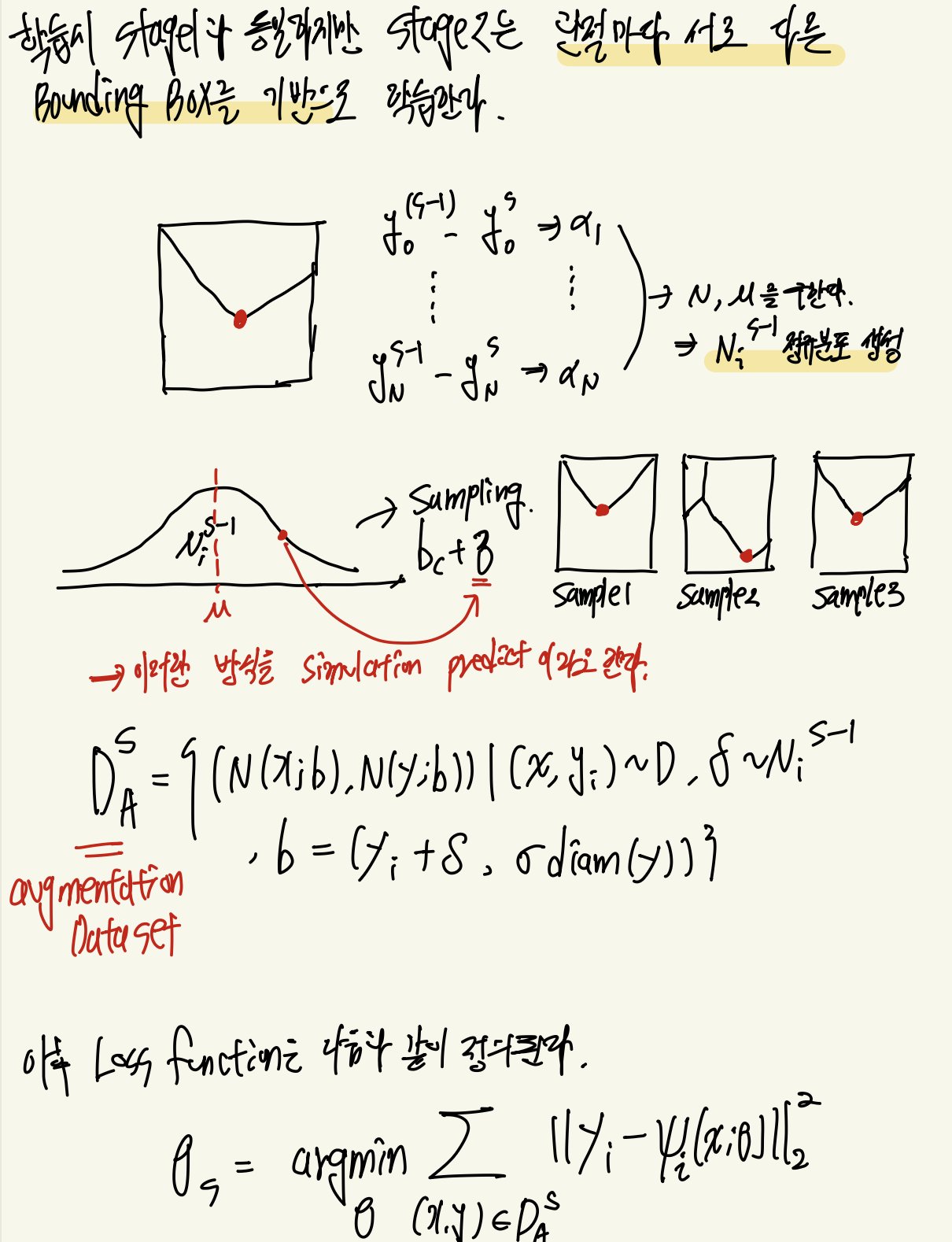
하지만 본 논문에서는 다음과 같이 간단하게 전체 이미지를 입력으로 학습을 하게 되면 각 관절의 좌표가 디테일하지 않다고 주장합니다. 그래서 각 관절에 해당 하는 좌표를 기준으로 crop image를 생성하여 좌표의 오차를 학습하는 구조를 구현합니다. 이러한 방식을 Cascade 방식이라고 합니다. 총 S 단계를 거쳐서 보정이 들어가고 각각의 모델의 파라미터는 로 표현하였습니다. 그리고 각 관절이 포함된 crop image의 박스는 아래와 같이 정의하였습니다. diam와 는 이미지 마다 최적화된 값이라고 생각하면 될것같습니다.
그래서 결국 stage1의 경우 우리가 위에서 봤던 수식을 그대로 따르고 2단게 이후로는 각각의 관절을 crop한 데이터를 다루기 떄문에 아래와 같은 수식으로 표현이 가능하게 됩니다.
즉, 각각의 좌표값은 이전 좌표값을 기반으로 오차 만큼의 값을 더해서 각각의 관절 좌표를 보정하게 됩니다.
손실 함수를 구하기전에 stage1과 stageN ( N ≥ 2 ) 의 중요한 차이가 있습니다. 이는 모든 이미지의 박스의 크기가 다르다는 것입니다. 그래서 각각의 박스로 정규화가 필요하게 됩니다. 그리고 본 논문에서는 값들을 사용하여 모든 관절의 오차를 통해서 평균과 분산을 통해서 특정 정규분포를 설정하게 됩니다. 그리고 이러한 분포에서 값들을 샘플링하게 되어 실제 정답에 더해주게 됩니다. 이를 통해서 실제 없는 데이터지만 box 자체를 조금씩 이동시켜 데이터 증강 효과를 얻었다고 합니다. 이를 수식으로 표현하면 아래와 같이 나타낼 수 있습니다.
Experiments

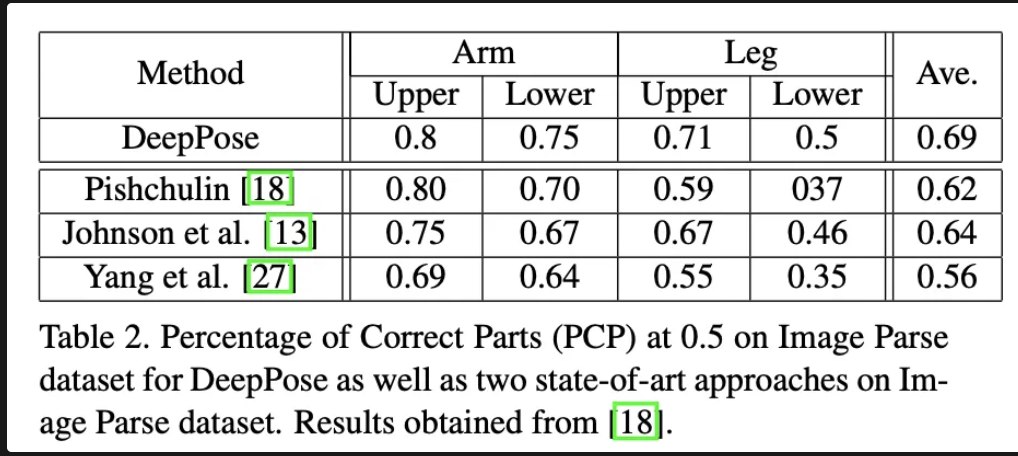
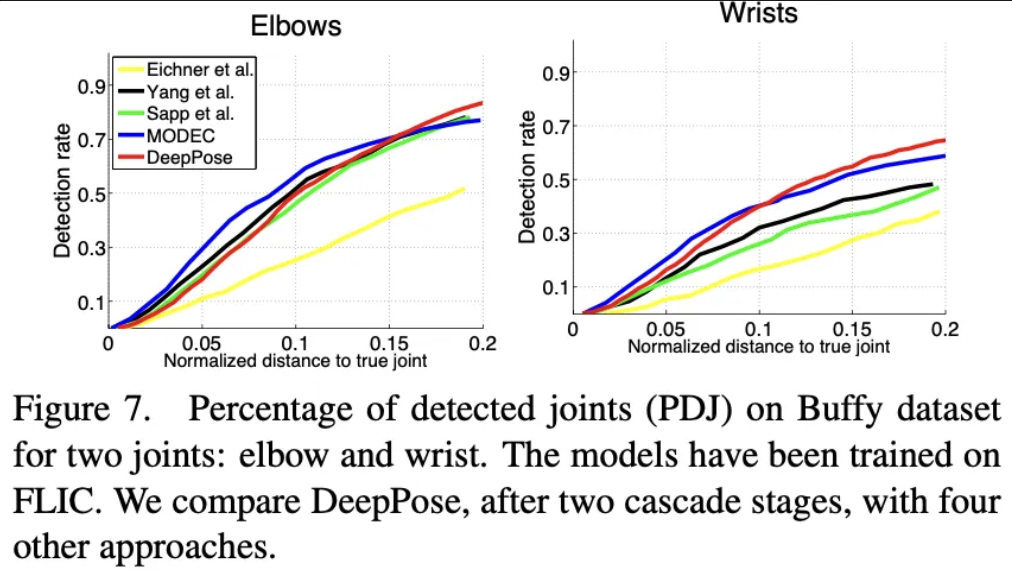

다음은 이 모든 과정을 제가 손으로 정리한 내용들입니다.
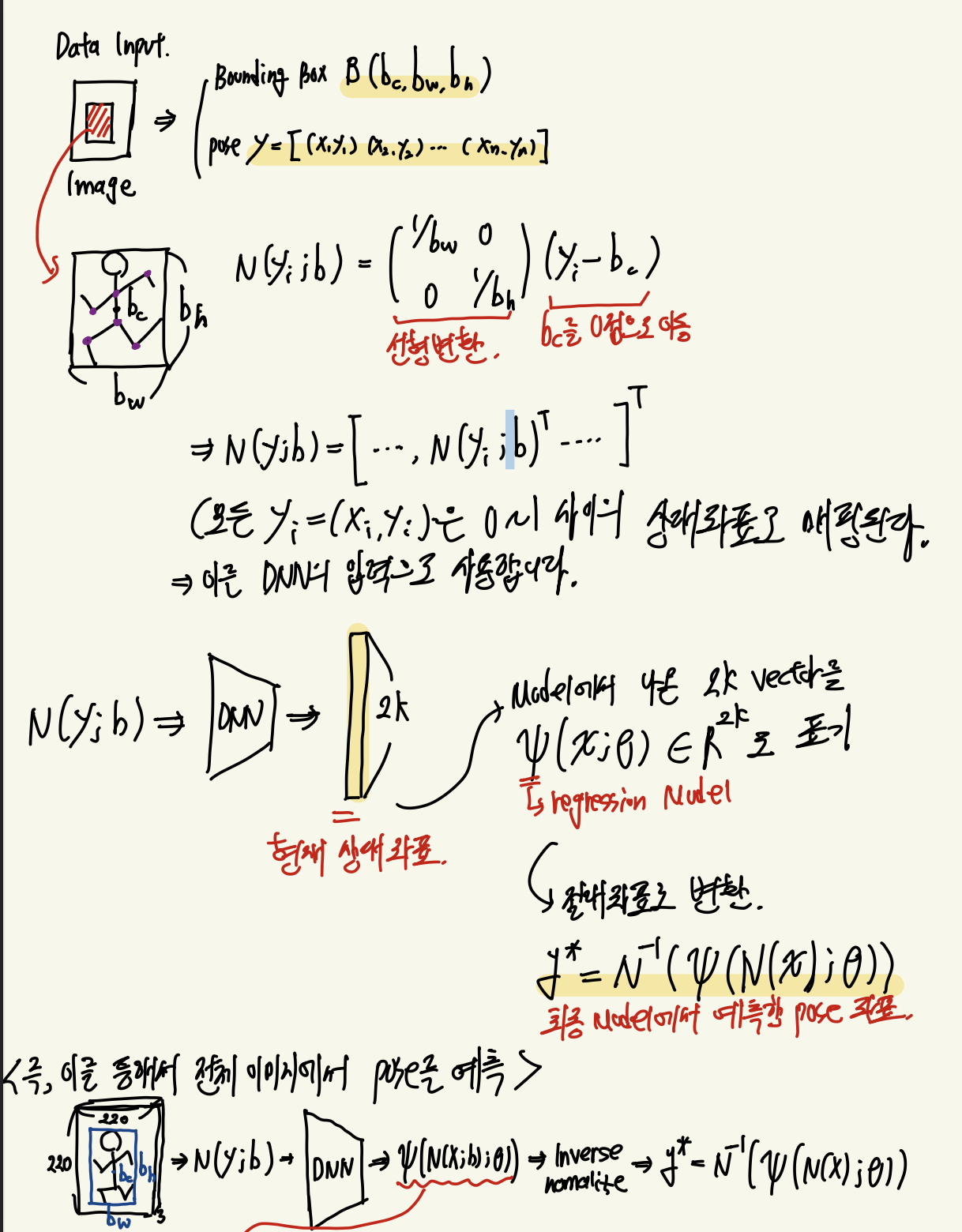

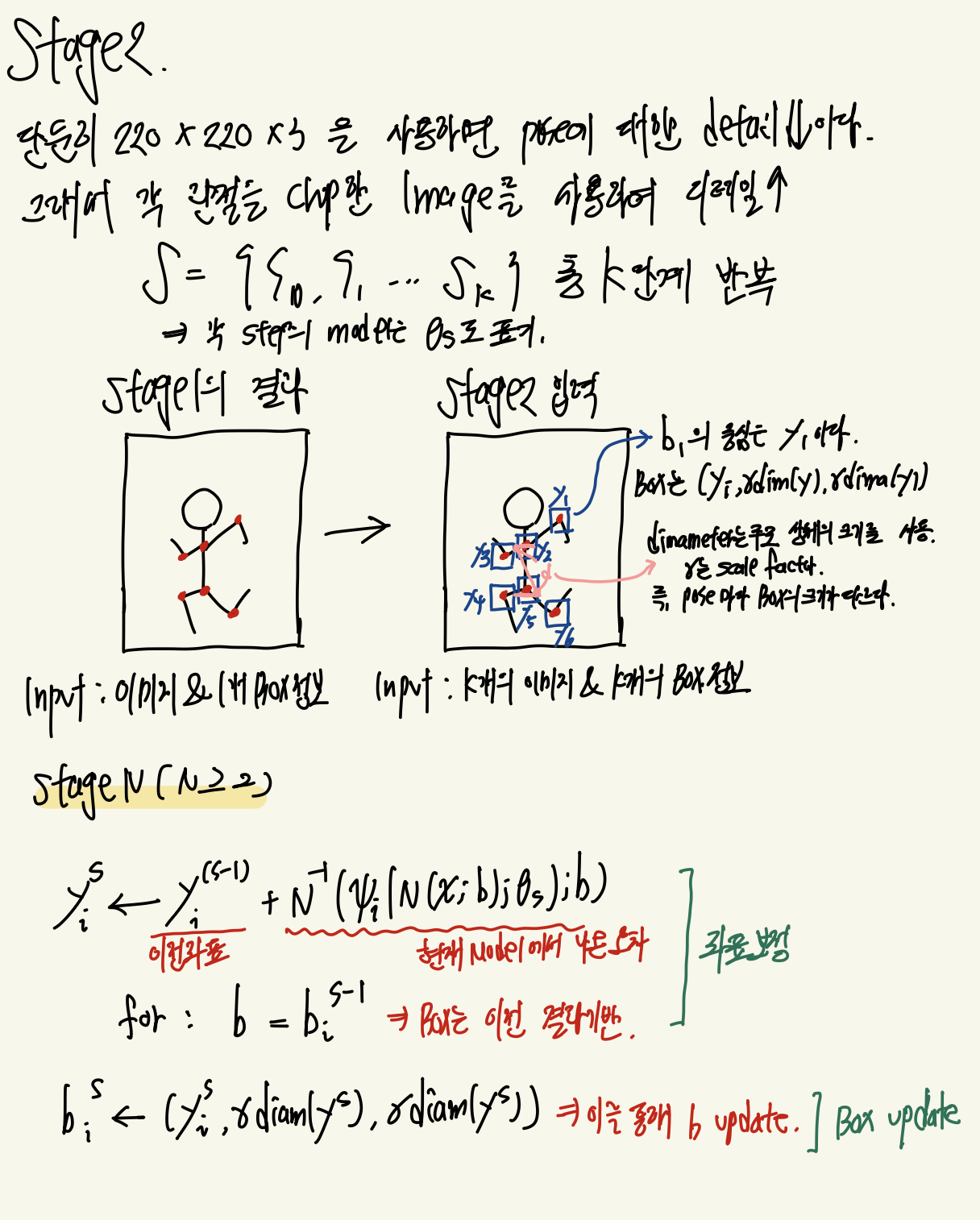
간단 정리
본 논문은 사람의 관절을 예측하는 문제를 간단한 CNN 모델을 통해서 구현하였습니다. 추가로 좌표값의 정확도를 올리기 위해서 각 관절을 기준으로 crop image들을 cascade 방식으로 학습하여 각 좌표의 정확도를 향상시켰습니다.
나의 생각
stage1에서 모든 관절에 손실을 다 더해서 평균내는 아이디어는 Noise에 취약할것같다. 특정 관절만 손실이 크더라도 모든 관절에 손실이 흘러들어가게 되어 학습이 진행되지 않을 가능성이 있어보인다. 이에 학습이 되지 않는 관절에 대해서만 높은 가중치를 두는 전략이 필요해보인다.
그리고 stage2 에서 각 관절마다 이미지를 넣어서 디테일을 잡아주는데, 이는 너무 cost가 클것으로 예상된다. 그래서 특정 범위를 설정하고 예를들어 상체 & 하체 그리고 그 다음 상체-왼쪽, 상체-오른쪽 이런식으로 점점 디테일하게 되어 각 관절의 이미지는 마지막 단게에서 1번 수행하는것이 더 효율적이면서 이미지를 디테일하게 본다는 본 논문의 아이디어를 침해하지 않는 아이디어가 될거라고 생각한다.
