논문리뷰
1.[ 논문 리뷰 ] DETR ( DEtection TRansformer )
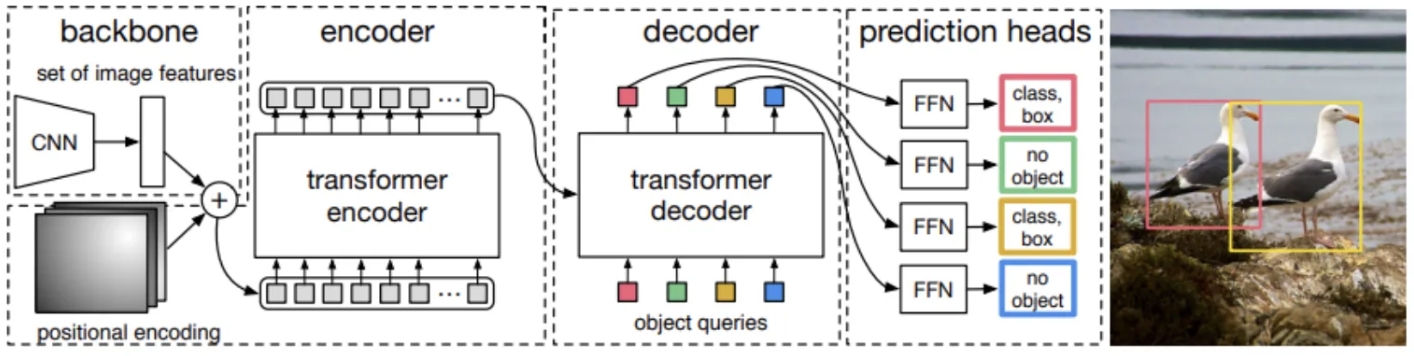
해당 논문에서는 객체탐지를 직접적인 예측 문제로 바라보는 새로운 관점을 제공합니다.이러한 관점을 통해서 NMS, Anchor box generator와 같이 사람의 수동으로 설정하는 를 제거하였다고 합니다. ( 이는 결국 Inductive bais를 제거하였다고 생각된
2.[ 논문리뷰 ] Co-DETR ( DETR with Collaborative Hybrid Assignments Training )
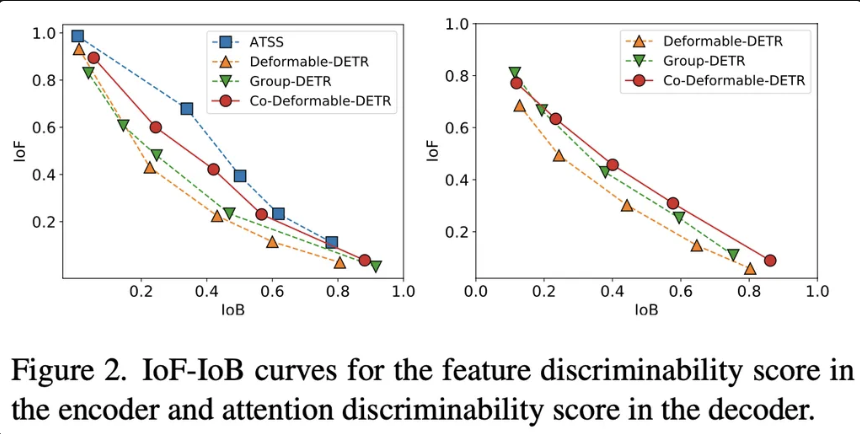
본 논문은 기존 DETR의 1:1 매칭 방식으로 인해 실제 객체를 나타내는 양성 쿼리가 극히 일부여서, Encoder의 특징 학습과 Decoder의 attention 연산이 충분히 이루어지지 않는 문제점을 지적합니다. 이를 완화하기 위해, 새로운 협력적 하이브리드 할당
3.[ 논문 리뷰 ] Attention Is All You Need
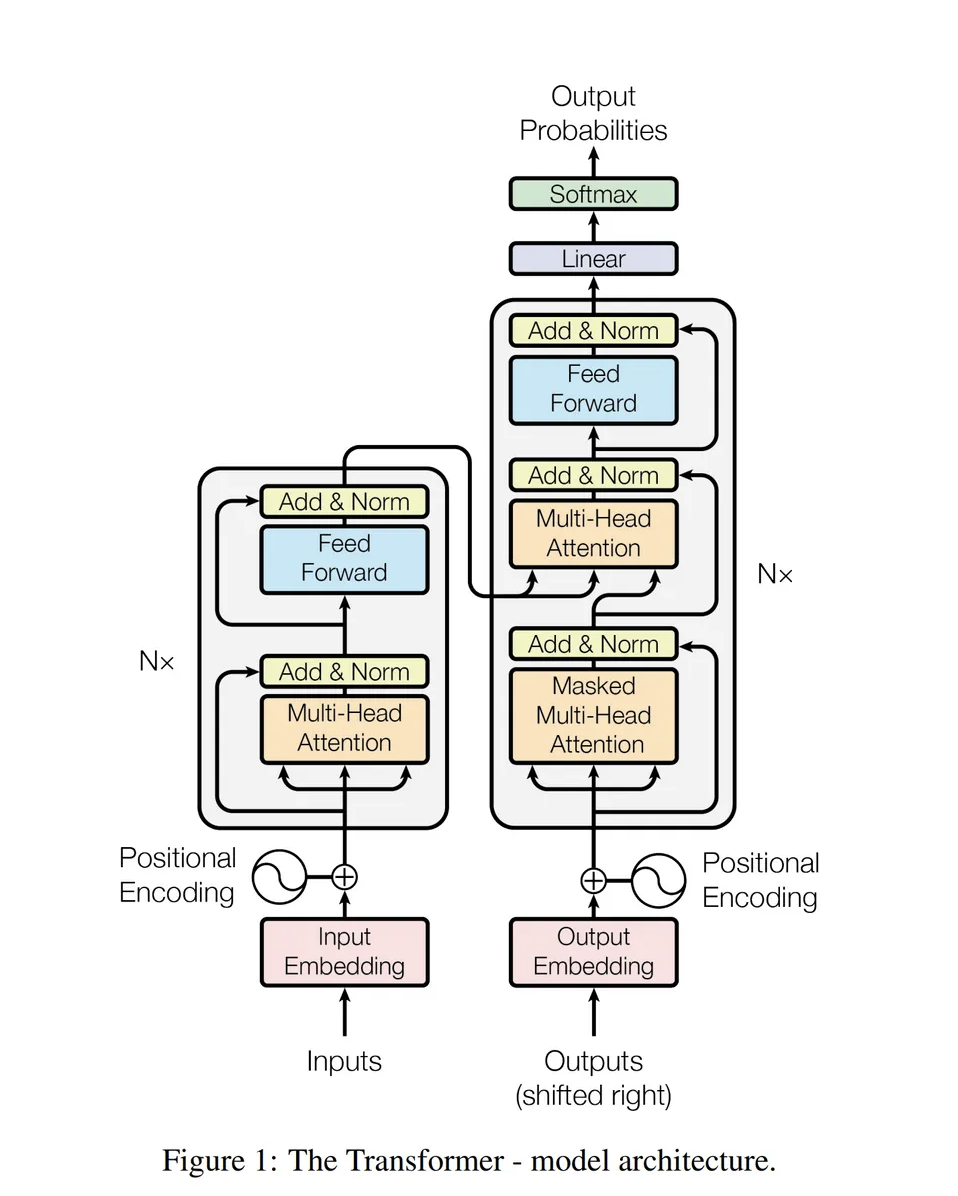
RNN과 CNN 계열의 모델에서 병렬처리의 어려움, Sequence가 긴 데이터에 대한 장거리 의존성 부족 및 기하급수적으로 증가하는 연산량을 해결하기 위해서 등장하였습니다.해당 논문에서는 최초로 Self Attention 구조만을 사용하여 기계번역을 구현하였습니다.
4.[ 논문 리뷰 ] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
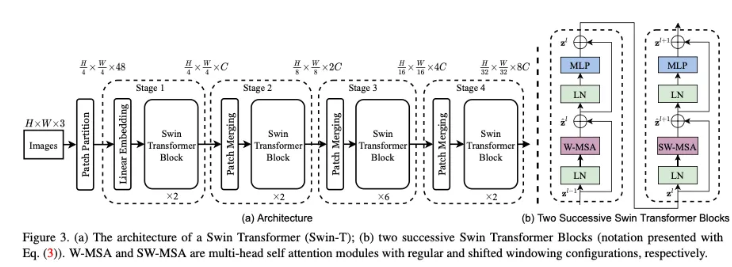
해당 논문에서는 계층적 Transformer를 제안하며 컴퓨터 비전에서 사용되는 Backbone을 구축하고자 합니다.Swin-Transformer의 경우 계층정 구조를 통해서 다양한 크기의 객체를 탐지하느데 유리하며, shifted-window 방식을 사용하여 서로 겹
5.[ 논문 리뷰 ] SA ( segment Anything )
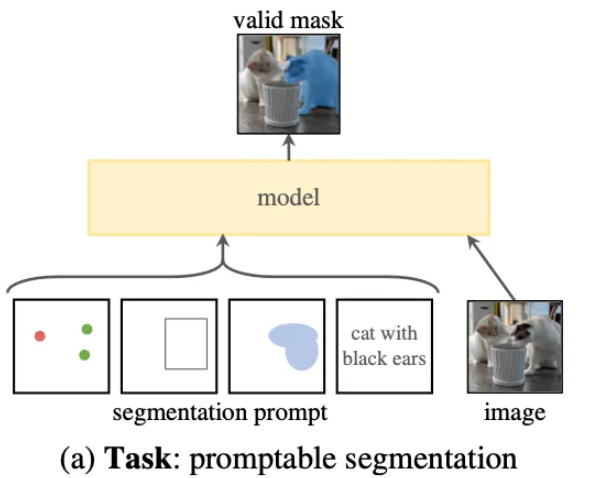
논문에서는 Segmentation 분야에서의 기초 모델(foundation model)을 목표로 하는 SA 프로젝트를 제안합니다. 이 프로젝트의 핵심 요소는 다음과 같습니다:Zero-shot Task: 추가 학습 없이 새로운 데이터와 과제에 적용할 수 있는 작업을 제안
6.[ 논문 리뷰 ] End to End Learning for Self-Driving cars
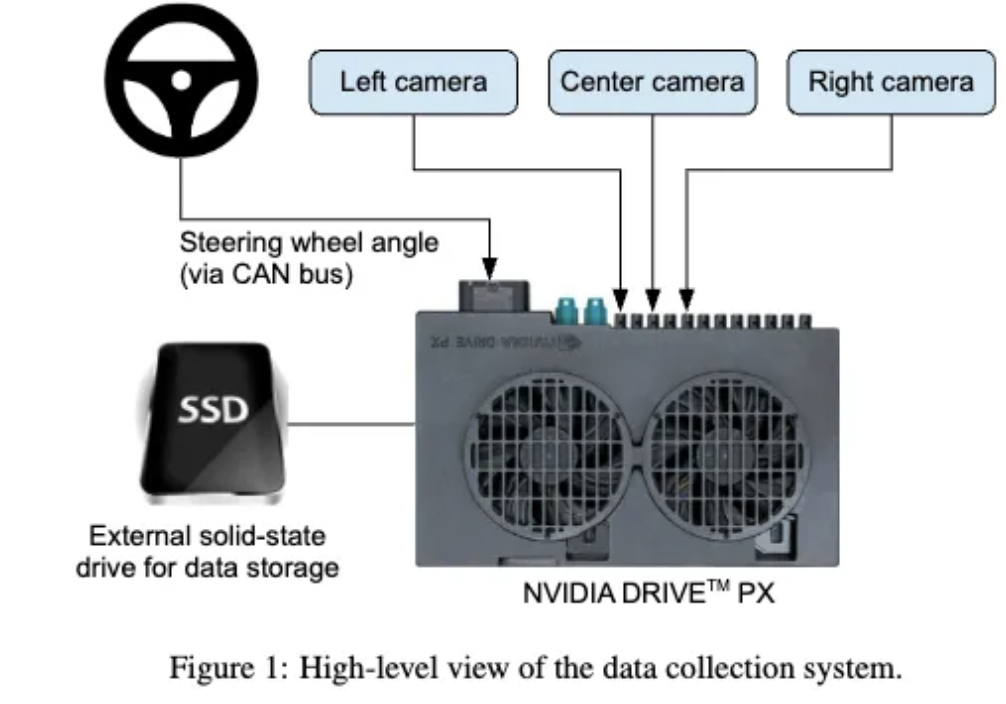
기본의 자율주행 시스템의 경우 도로의 상황, 라인 마킹 등 여러가지의 단계로 구분되어 학습되어야 했습니다. 하지만 해당 논문에서는 운전자의 Steering angle 정보만을 활용하여 End-to-End 자율주행 시스템을 개발했다고 주장하고 있습니다. 또한 특징을 명시
7.[ 논문 리뷰 ] Show and Tell: A Neural Image Caption Generator

RNN의 encoder, decoder의 매커니즘을 활용하여 encoder를 이미지 endoer로 변경하여 이미지를 설명하는 end-to-end system을 제안하였습니다.
8.[ 논문 리뷰 ] Show, Attend and Tell : Neural Image caption Generation with Visual Attention
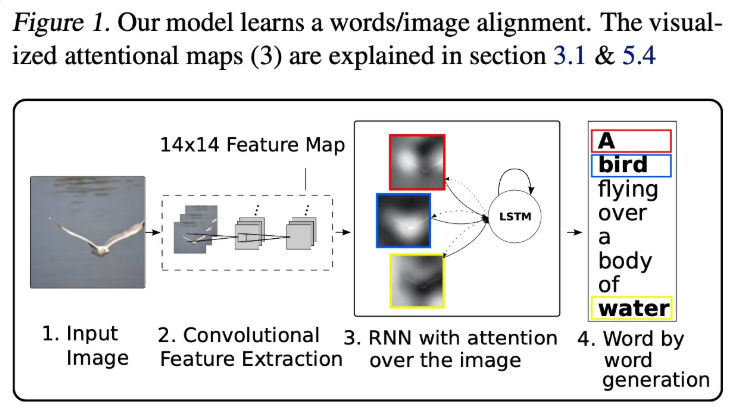
Image Caption 모델에서 이미지의 특정 부분을 단어를 예측할 때마다 강조하도록 하는 Attention 매커니즘을 적용한 모델로 모델이 단어를 예측할 떄 이미지의 어느 부분을 보고 단어를 예측하는지에 대한 인사이트를 제공합니다.
9.[ 논문 리뷰 ] ViLBERT : Pretraining Task-Agnostic Visiolinguistic Representations
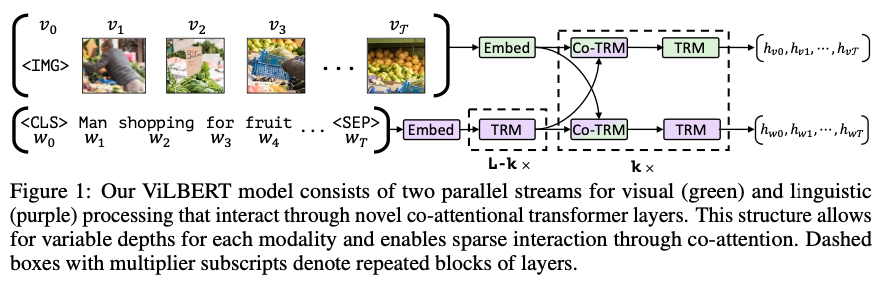
ViLBERT의 경우 2-stream + co-attention 아키텍처를 활용하여 이미지-자연어 관계를 사전학습할 수 있는 기반 모델을 제안하였습니다.
10.[ 논문 리뷰 ] CLIPSeg : Image Segmentation Using Text and Image Prompts
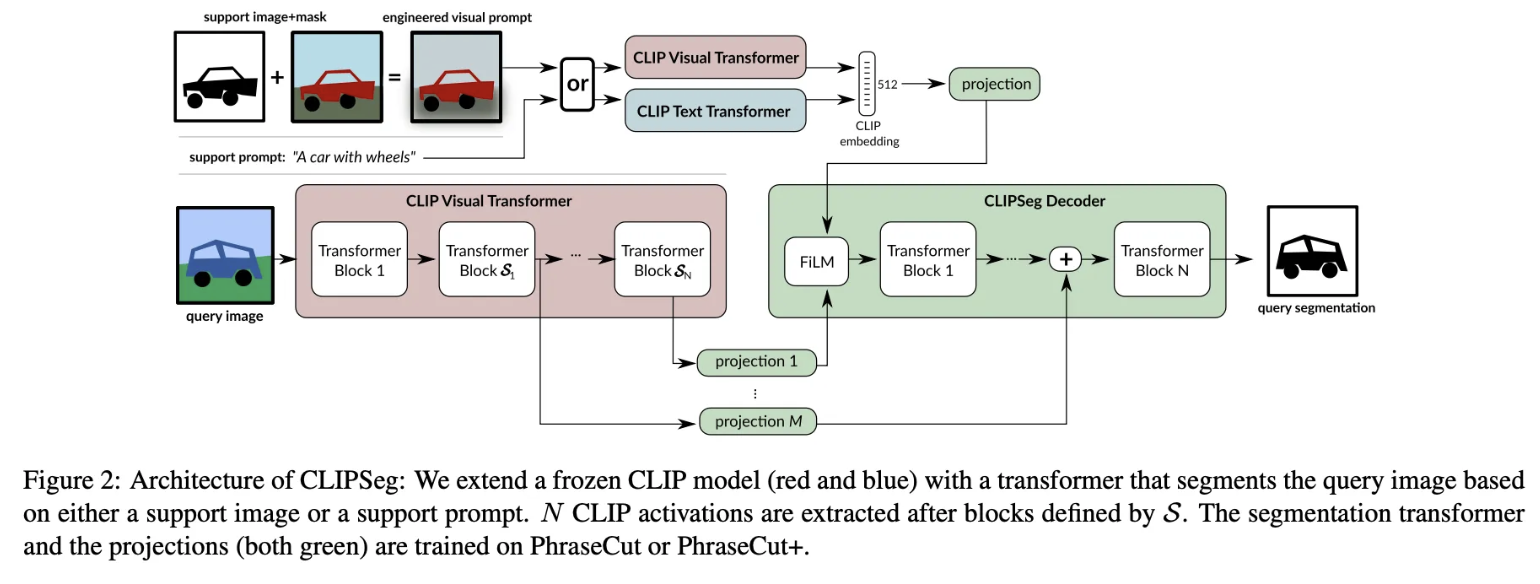
본 논문은 CLIP의 자연어-이미지 관계를 최대한 활용하되, decoder layer를 확장하여 image 혹은 text prompt를 통해서 segmantation을 할 수 있는 CLIPSeg 모델을 제안하였습니다.
11.[ 논문 리뷰 ] DeepPose : Human Pose Estimation Via Deep Neural Networks

CNN모델을 사용하여 사람의 pose를 예측하는 모델을 제안하였습니다. 특히 Cascade 방식의 학습 구조를 활용하여 각 좌표의 성능을 향상시켰습니다.
12.[ 논문 리뷰 ] Stacked Hourglass Networks for Human Pose Estimation
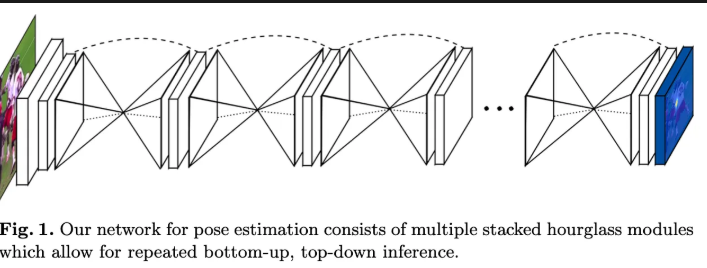
본 논문은 Residual Block과 1 X 1 conv를 사용하여 "Stacked Hourglass" 모델을 제안합니다. 이러한 구조를 통해서 지역적, 글러벌적 정보를 모두 학습할 수 있으며, 추가로 Intermediate supervision을 통해 정확도를 높힘
13.[ 논문 리뷰 ] Distilling the Knowledge in a Neural Network

거대 모델의 출력 확률 분포를 모방하는 것이 해당 모델의 지식을 배운다고 정의하였음. 이에 softmax시 T라는 값을 도입하여 확류 분포를 통해서 어떻게 지식을 배울지 조정이 가능함을 보여주였습니다. 추가로 soft label target이 높은 성능을 보임을 입증함
14.[ 논문 리뷰 ] On the Efficacy of Knowledge Distillation
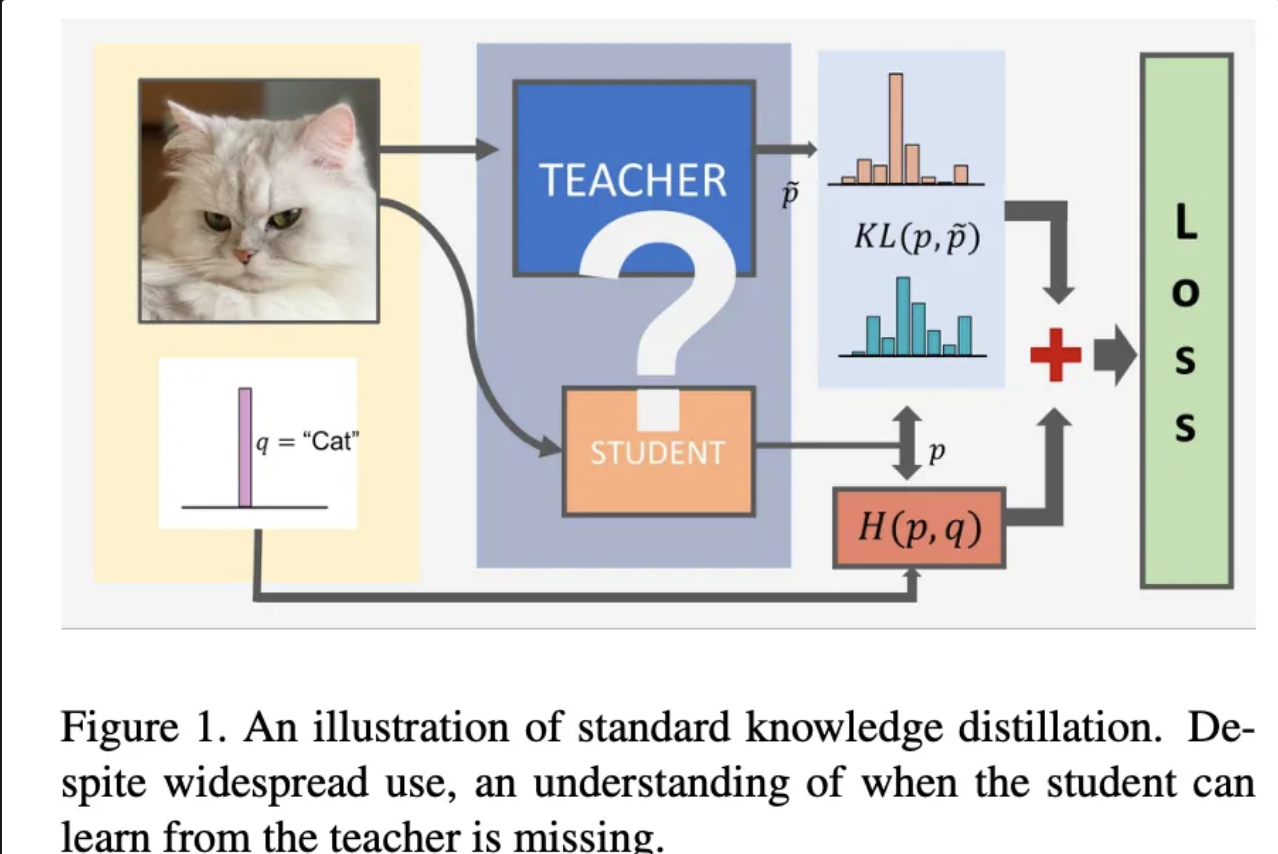
kD가 잘 작동하지 않는 경우를 Teacher 모델과 Student 모델의 용량 차이를 들었고, 이를 해결하기 위해서 Teacher 모델 학습을 일찍 중단하는 ESKD를 제안하였으며, ESKD 방법론이 효과가 있음을 실험을 통해 입증하였습니다.
15.[ 논문 리뷰 ] HRNet : Deep High-Resolution Representation Learning for Human Pose Estimation
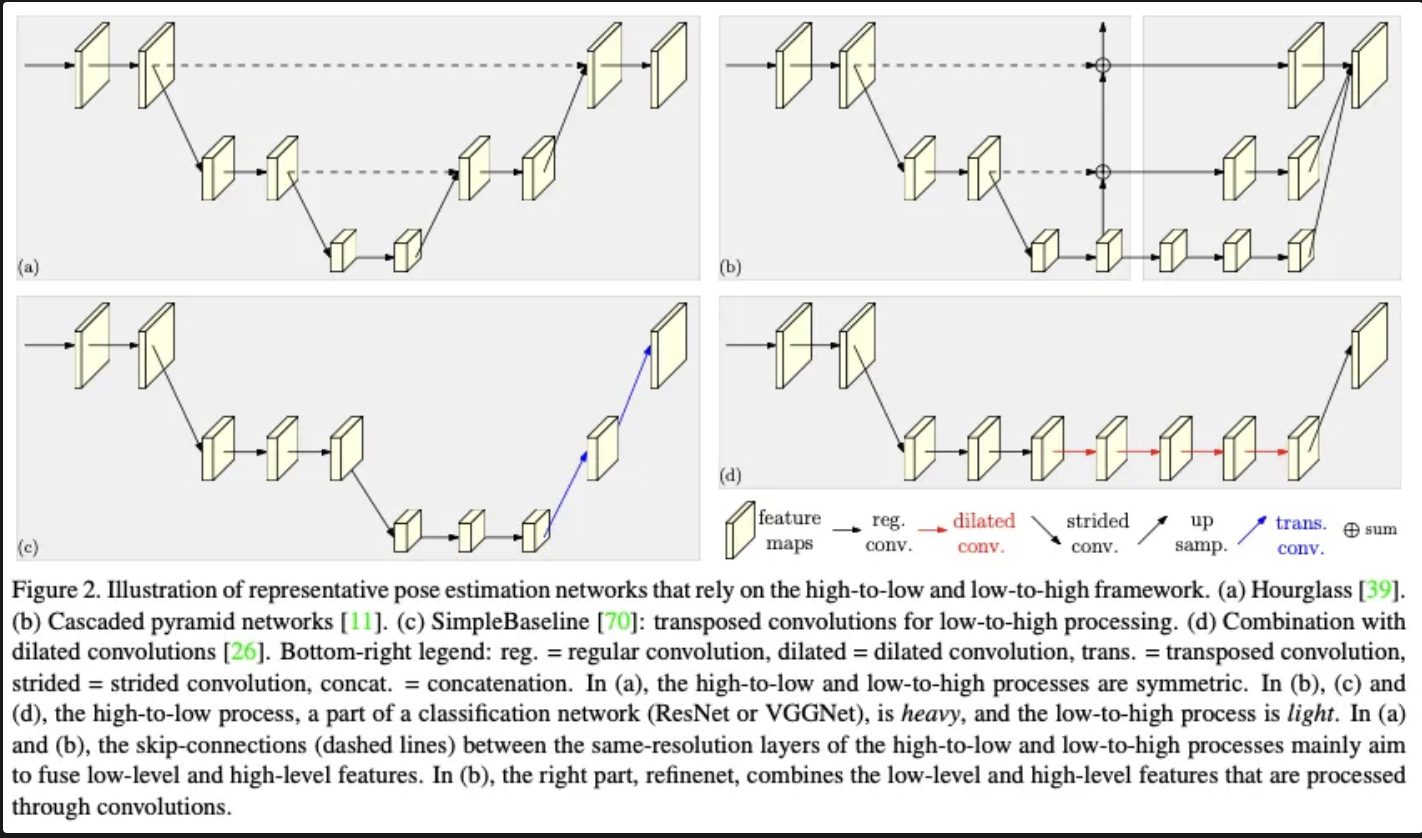
본 논문은 다양한 스케일을 병렬로 처리하여 히트맵을 추정하는 HRNet을 제안하여 다양한 밴치마크 데이터셋에서 높은 성능을 달성하였습니다.
16.[ 논문 리뷰 ] HRFormer : High-Resolution Transformer for Dense Prediction
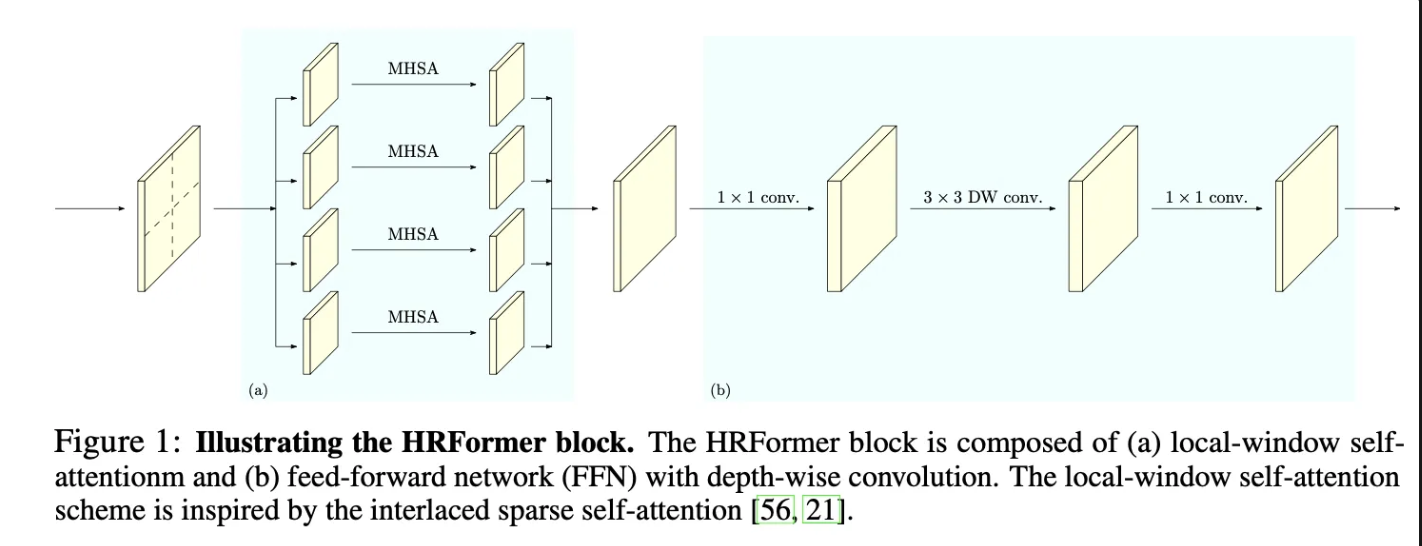
본 논문은 HRNet 모델의 블럭을 ViT와 depth wise를 포함한 FPN을 기반으로한 블럭으로 변경함으로 써 더 높은 성능을 달성하는 HRFormer를 제안하였습니다.
17.[ 논문 리뷰 ] PPT : token-Pruned Pose Transformer for monocular and multi-view human pose estimation

PPT 모델은 Transformer를 자세 추정에 도입하면서 적은 메모리로 높은 성능을 달성하였음을 보여줍니다. 추가로 Multi View PPT를 제안하여 다양한 뷰의 이미지를 융합하여 다양한 밴치마크데이터셋에서 높은 성능을 보여주었습니다.
18.[ 논문 리뷰 Renewal ] DEtection TRansformer
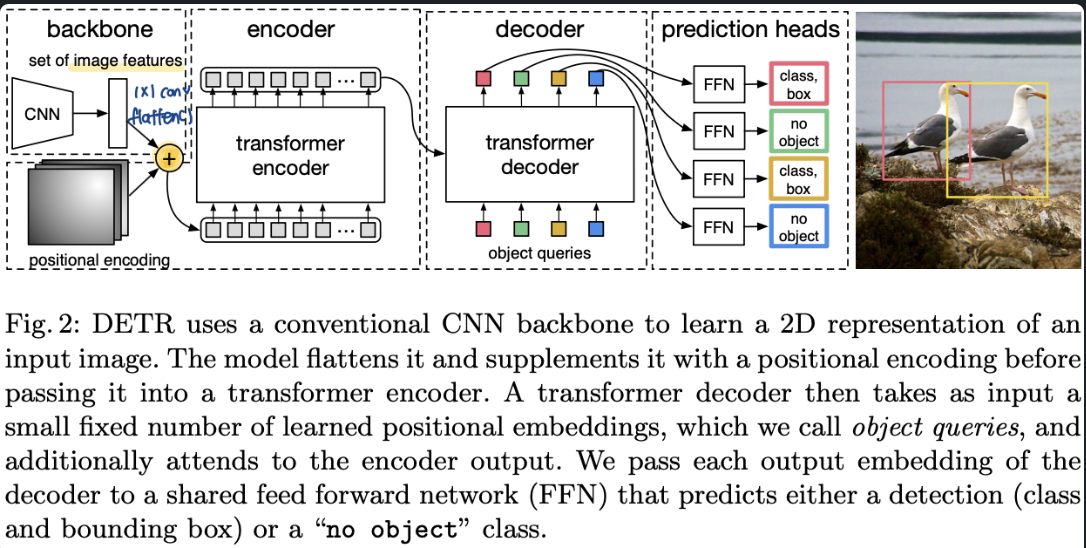
DETR 논문을 다시 읽고 다시 정리한 내용입니다. 그냥 쭉읽어도 이해가 되도록 쉽게 설명해둔 버전입니다.
19.[ 논문 리뷰 ] Diffusion Model

Diffusion 모델에서 Noise를 제거하는 과정에서 왜 노이즈 값을 학습해야하는지에 대한 의문을 풀수 있습니다.
20.BLIP-2 : Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
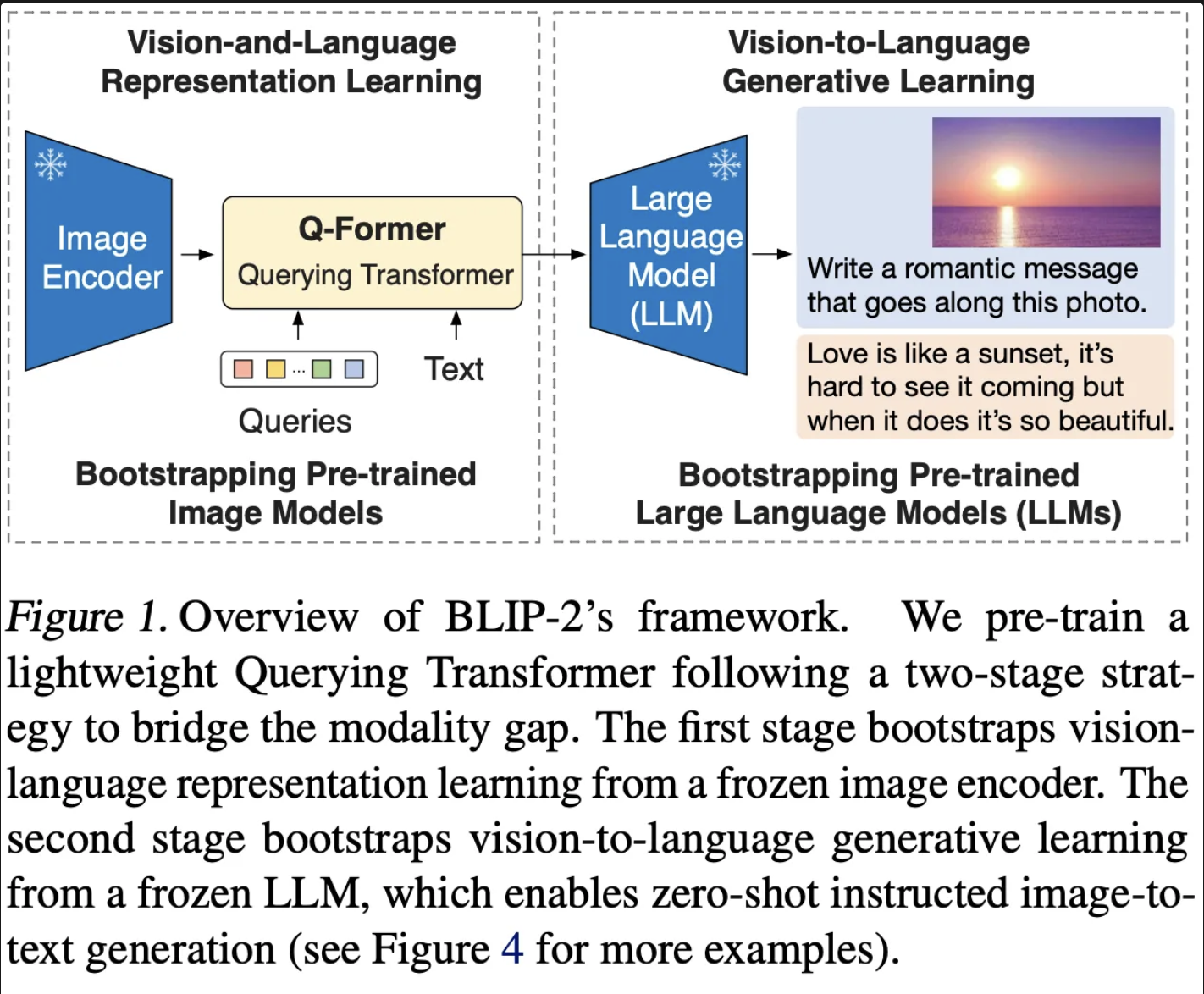
BLIP-2의 경우 상용화 되어 있는 Image Encoder와 LLM을 활용한 VLM을 제안합니다.효율적인 학습을 위해서 사용화된 Image Encoder와 LLM의 경우 학습하지 않고 Frozen 된 상태로 사용합니다. 그리고 이미지와 텍스트의 모달 차이를 최소화
21.EventVL: Understand Event Streams via Multimodal Large Language Model
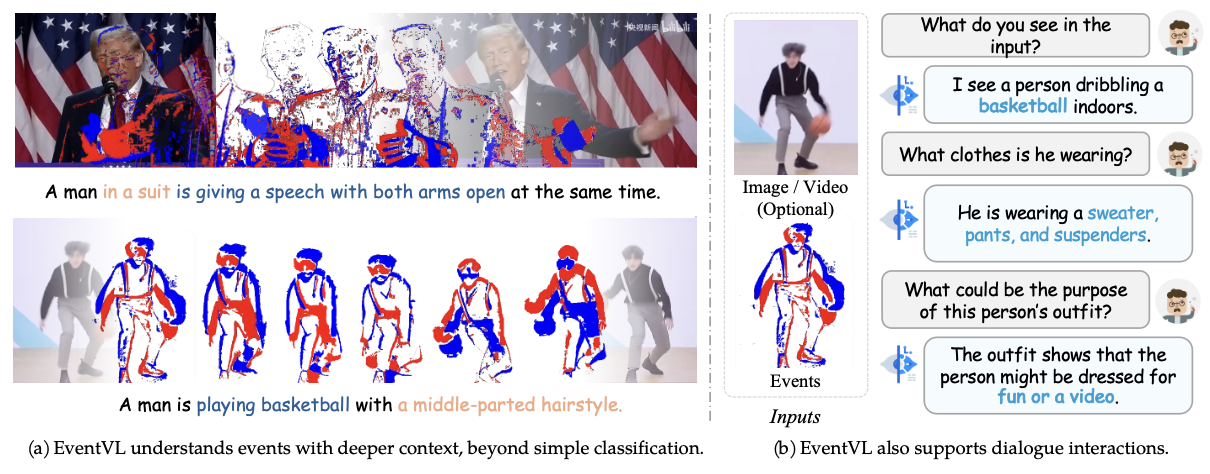
최근 Event Camera가 기존의 Camera의 단점을 보완하는 새로운 데이터로 떠오르고 있습니다. 하지만 Event 데이터를 이해하는 MLLM 모델이 존재하지 않았습니다. 이에 해당 논문에서 Event 데이터를 이해할 수 있는 MLLM 모듈인 EventVL을 제안
22.NeRF : Representing Scenes as Neural Radiance Fields for View Synthesis
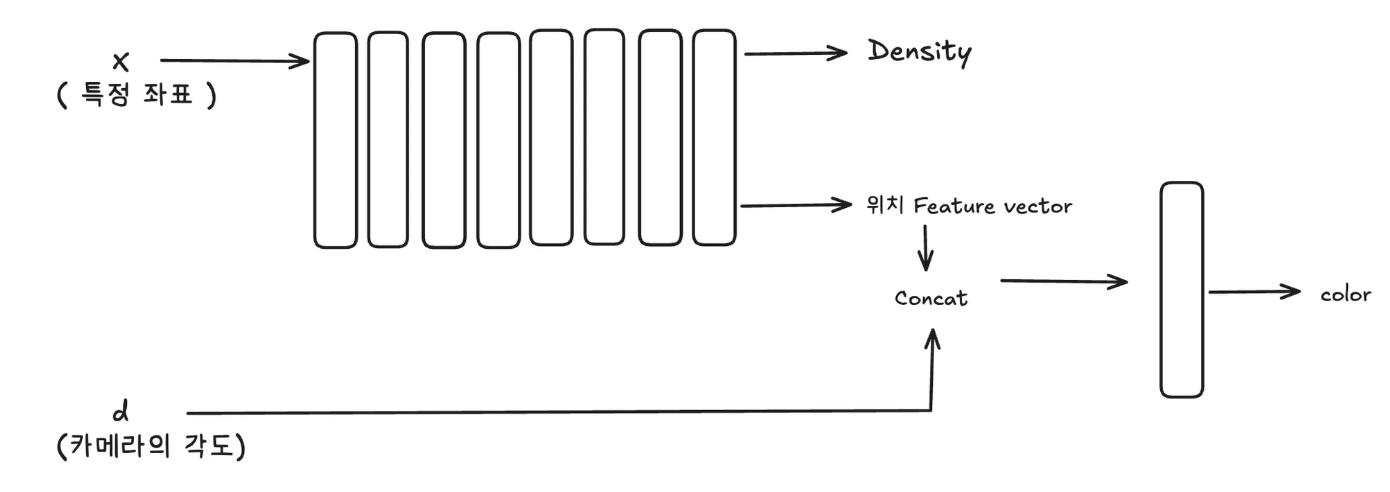
NeRF의 경우 연속적인 장면을 5개의 자표로 표현합니다. ( x,y,z) 우리가 보고싶어하면 3D 상의 특정 좌표를 의미합니다. ( $\\theta, \\phi$ ) 에서 $\\theta$ 의 경우 Z 축에서 얼마나 기울어졌는지, 그리고 $\\phi$ 의 경우 (x,
23.[computer vision] SwinTransformer
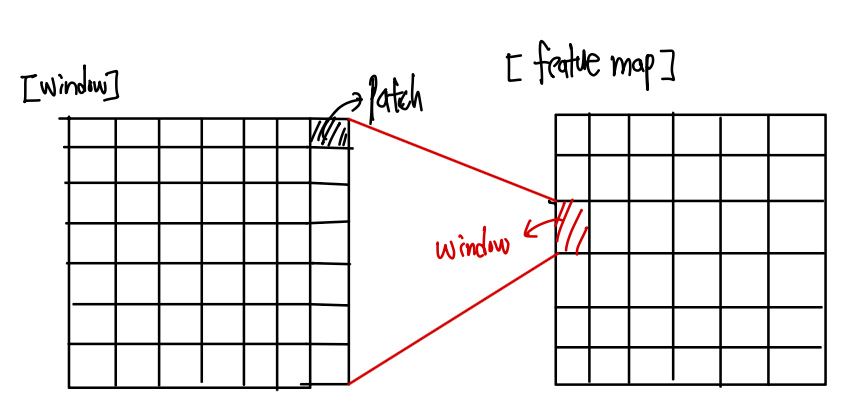
SwinTransformer의 전체적인 논문을 리뷰하기 보다 SwinTransformer의 동작 원리에 대해서 구체적으로 살펴보도록 정리하였습니다.
24.[ computer vision ] DINO : Emerging Properties in Self-Supervised Vision Transformers
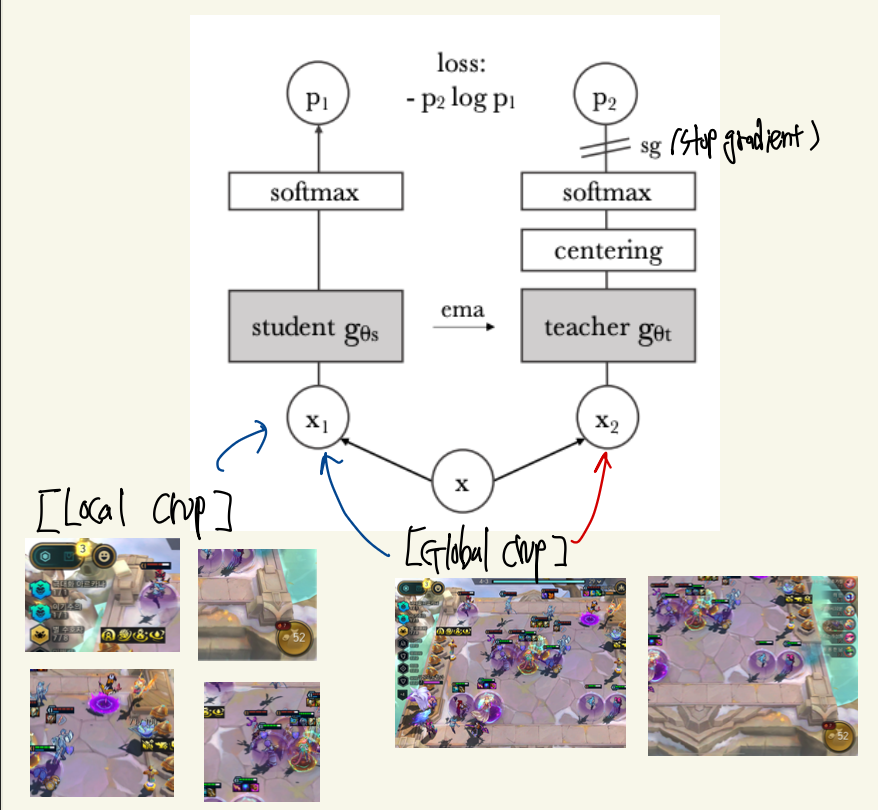
DINO로 불리는 논문에 대해 핵심을 정리해보도록 하겠습니다.DINO의 경우 특정 TASK를 풀기 위해서 나온 모델이라기 보다는 이미지의 특징을 파악하기 위한 모델이라고 생각됩니다.
25.[ Anomaly Detection ] PatchCore

정상데이터만을 활용해서 이상치를 탐지하는 강력한 방법론