Abstract
본 논문은 기존 DETR의 1:1 매칭 방식으로 인해 실제 객체를 나타내는 양성 쿼리가 극히 일부여서, Encoder의 특징 학습과 Decoder의 attention 연산이 충분히 이루어지지 않는 문제점을 지적합니다. 이를 완화하기 위해, 새로운 협력적 하이브리드 할당 학습 방식(collaborative hybrid assignments training scheme)을 제안합니다. 이 방식은 학습 시 다중 병렬 보조 헤드를 통해 1:N 매칭을 사용하고, 보조 헤드에서 양성 샘플의 좌표를 추출하여 추가 양성 쿼리를 생성함으로써 Decoder의 성능을 개선하며, 추론 시에는 추가 파라미터나 연산 비용 없이 기존 DETR과 동일한 구조를 유지합니다.
Abstact 2줄 정리
학습시 보조 병렬 헤드를 추가하여 1 : N 매칭을 사용하였고, 보조 헤드에서 양성 쿼리를 추가하여 Decoder의 성능을 개선하였습니다. 추론시에는 추가적인 파라미터와 연산을 필요로 하지 않습니다.
Introduction
객체 탐지는 본질적으로 Localization + Classification 작업으로 구성됩니다. 전통적 객체 탐지 모델(Faster R-CNN, ATSS 등)은 바운딩 박스 생성 후 GT와 1:N 매칭을 수행하며, 앵커 박스(anchor boxes), 중심 기반 할당(center-based assignment) 등의 사전 지식을 활용하고, NMS(Non-Maximum Suppression) 등의 기법으로 최종 매칭을 이룹니다. 이러한 1:N 매칭 방식은 객체 탐지에서 매우 효과적입니다.
반면, DETR은 1:1 매칭 방식을 사용하여 NMS를 필요로 하지 않는 장점을 가지지만, 기존 1:N 매칭 방식에 비해 양성 쿼리 수가 적어 학습 효율이 낮고 성능 차이가 발생하는 한계가 있습니다. 본 논문은 이러한 문제를, (1) 인코더가 생성하는 잠재 표현과 (2) 디코더의 어텐션 학습이라는 두 가지 관점에서 분석합니다.
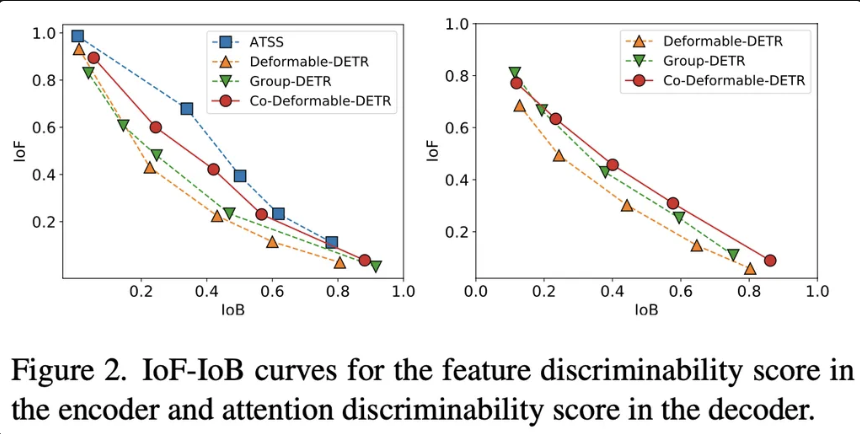

실험 결과, latent feature의 discriminability score를 비교한 결과 ATSS 모델이 전경과 배경을 더 잘 구분함을 확인했으며, 양성 쿼리 부족 문제를 보완한 Group-DETR에서는 성능이 개선되었습니다. 시각화 결과 역시 one-to-many 매칭 방식이 1:1 매칭 방식보다 세밀한 객체 정보를 잘 포착함을 보여주었습니다.
이러한 강력한 인사이트를 바탕으로, 본 논문은 보다 효과적인 학습을 위해 Transformer Encoder의 출력에 보조 헤드를 통합하는 “collaborative hybrid assignments training scheme (Co-DETR)“을 제안합니다.
그래서 정리하자만, Encoder의 출력에 추가적인 보조 헤드를 추가하여 아래와 같은 효과를 얻었습니다.
- Encoder는 다양한 라벨 할당 방식을 통해 풍부한 신호를 받아 객체와 배경을 명확히 구분하는 특징을 학습합니다.
- 보조 헤드는 양성 샘플의 좌표를 정교하게 처리하여 독립된 양성 쿼리 그룹을 생성하고, 이를 기존 Decoder에 전달합니다.
- 이러한 방식은 Decoder가 더 많은 쌍을 학습하도록 도와 학습 효율성을 높이며, 추론 시 추가 오버헤드 없이 기존 구조를 그대로 유지합니다.
Method
collaborative Hybrid Assignments Training
DETR에서는 양성 쿼리가 적다는 이유로 Encoder와 Decoder 에서 효율적인 학습을 할 수 없었습니다. 그래서 co-DETR에서는 다음과 같은 방법을 통해서 보다 효율적으로 Encoder, Decoder를 학습하게 됩니다.
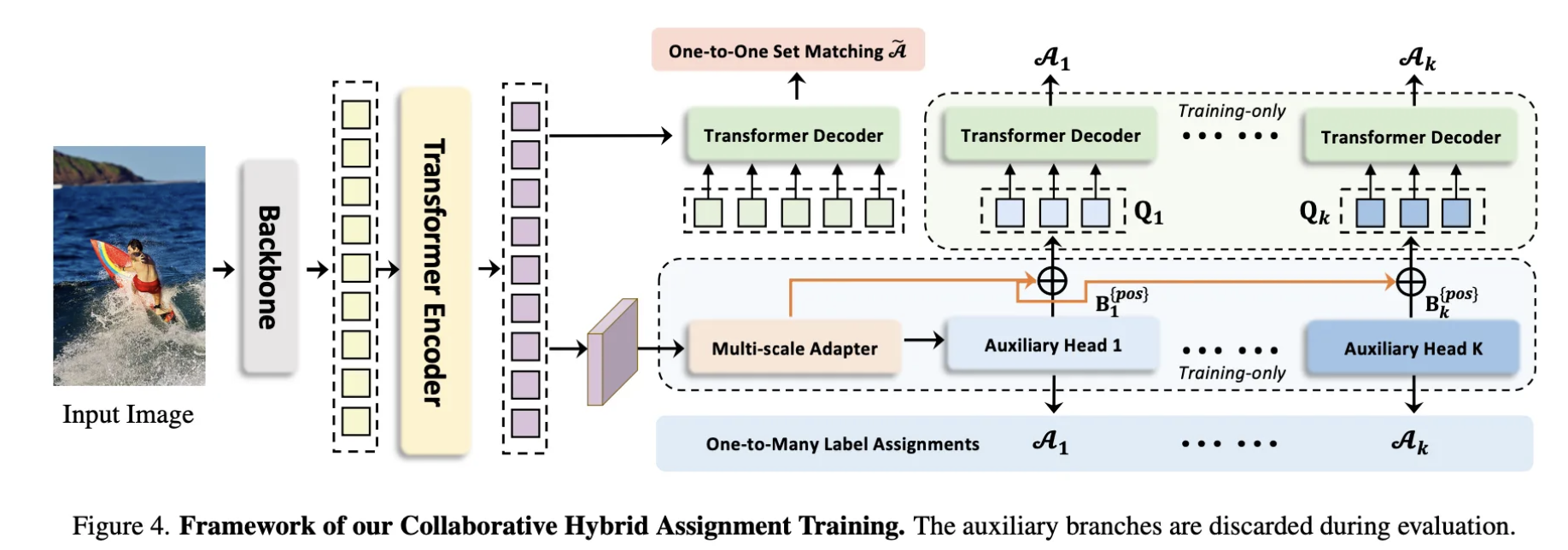
Encoder를 통과하여 latent feature를 추출한 후, (a) 일반적인 DETR과 같이 1:1 매칭을 진행하여 1:1 pair를 찾고, (b) Multi-scale Adapter를 통해 latent feature map을 여러 스케일의 feature pyramid(총 J개의 feature pyramid)로 변환합니다. 이렇게 생성된 feature pyramid는 K개의 보조 head에 각각 입력되는데, 각 보조 head는 간단한 MLP나 FC layer로 구성되어 있으며, 입력된 feature pyramid를 바탕으로 해당 위치에서 객체가 있을 확률과 바운딩 박스 조정 값을 예측합니다. 그리고 각 head는 자신만의 1: N 매칭 알고리즘 A_i를 사용하여, 예측 결과와 ground-truth를 비교함으로써 positive pair(객체가 있을 것으로 판단된 좌표와 그에 대한 타깃 정보)와 negative pair(배경에 해당하는 좌표)를 추출합니다. 마지막으로, 각 head에서 산출된 결과를 기반으로 개별 head의 손실을 계산하고, 모든 head의 손실을 합산하여 최종 loss를 구성함으로써, 이 loss를 통해 Decoder를 포함한 전체 모델을 학습시킵니다.
2줄 정리
DETR에서 양성 쿼리의 수가 부족하니깐, Encdoer의 출력에서 Feature pyramid를 생성하고, 작은 mlp를 활용하여 추가적인 양성 쿼리를 생성하여 1 : 1 매칭을 보완.
Customized Positive Queris Generation
지금까지 적은 Positive query의 수를 보완하기 위해서 여러 보조 헤드를 사용해서 양성 쿼리의 수르 늘렸습니다. 그래서 우리는 다음과 같은 쿼리를 얻을 수 있게 되었습니다.
PE는 positinal Encodding을 의미하며 E(F,pos)는 Feature pyramid에서 추출한 양성 쿼리를 의미하게 됩니다. 그래서 K개의 보조 헤드를 사용하는 경우 최종적으로 K + 1 개의 쿼리 그룹을 얻을 수 있고, 이때 1개는 1 : 1 매칭을 이루고, K개는 1 : N 매칭을 이루게 됩니다. 그리고 모든 쿼리는 파라미터가 동일한 공유되는 decoder를 통과하게 됩니다. 보조 헤드의 경우 이미 각각의 매칭 알고리즘을 통해서 모든 쿼리가 양성 쿼리이기 때문에 ‘헝가리안 알고리즘’ 과 같이 추가로 매칭을 해주는 알고리즘이 필요없게 됩니다. 그래서 보조 헤드의 손실을 공식화 해보면 아래와 같습니다.
여기서 의 경우 각 decoder를 통과한 보조 헤드의 결과입니다. 그래서 최종적으로 학습시 사용하는 co-DETR의 손실함수는 아래와 같습니다.
일반적인 1 : 1 매칭 손실 + 1 : N 손실 + Encoder 손실을 최종적인 손실로 사용하고 있습니다.
Why Co-DETR works
Enrich the encoder’s supervisions
정량적 및 정성적 평가를 통해, Co-DETR은 기존 1:1 매칭 방식의 DETR보다 Encoder가 잠재 특징을 더 풍부하게 학습할 수 있도록 함을 보여줍니다. 이는 다양한 라벨 할당 방식을 통해 Encoder가 객체와 배경을 명확히 구분하는 데 기여합니다.
Improve the cross-attention learning by reducing the instability of Ungarian matching
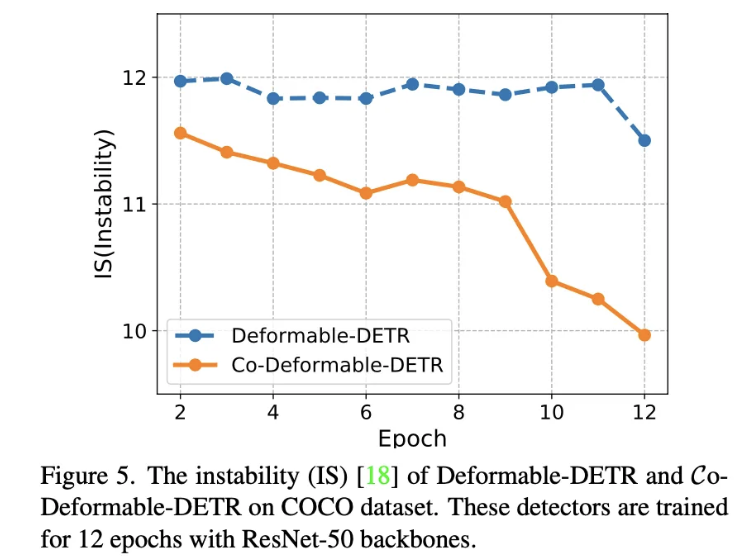
Hungarian 매칭은 학습 과정에서 매 에폭마다 매칭 쌍이 변동되어 불안정을 초래합니다. IS 그래프 등의 시각적 분석 결과, Co-DETR은 보다 안정적인 매칭 과정을 제공하며, 이로 인해 Decoder의 cross-attention 학습이 개선됩니다.
최종적으로, DETR에서 양성 쿼리 부족으로 인한 Encoder의 특징 학습 미흡과 Decoder의 불안정한 학습 문제를 Co-DETR이 1:N 매칭을 통해 보완함으로써 성능 향상을 이끌어냅니다.
